一、导读
作为非AI专业技术开发者(我是小小爬虫开发工程师😋)
本系列文章将围绕《大模型微调》进行学习(也是我个人学习的笔记,所以会持续更新),最后以上手实操模型微调的目的。
(本文如若有错误的地方,欢迎批评指正)

💪 为什么要学习AI呢?
- 作为一名爬虫开发工程师,我深知技术领域的不断变革与发展
- 如今,AI 已然成为时代浪潮的核心驱动力,就如同 Windows 操作能力是从业者的基础技能,
- 我坚信未来 AI 开发应用必将成为程序员不可或缺的能力标签。
你可以阅读我下列文章
✅ 关于langchain的系列文章(相信我把Langchain全部学一遍,你能深入理解AI的开发)
01|LangChain | 从入门到实战-介绍
02|LangChain | 从入门到实战 -六大组件之Models IO
03|LangChain | 从入门到实战 -六大组件之Retrival
04|LangChain | 从入门到实战 -六大组件之Chain
05|LangChain | 从入门到实战 -六大组件之Memory
06|LangChain | 从入门到实战 -六大组件之Agent
✅关于Langchain的实战案例(自认为本地问答机器人的案例写的很好,很好理解ReAct)
Langchain-实战篇-搭建本地问答机器人-01
都2024了,还在纠结图片识别?fastapi+streamlit+langchain给你答案!
✅关于Agent智能体开发案例(MCP协议)
在dify构建mcp,结合fastapi接口,以实际业务场景理解MCP
✅ 推荐阅读一下transformer 文章,以便能更好的理解大模型
Transformer模型详解(图解最完整版)
Attention Is All You Need (Transformer) 论文精读
✅ 除了在 CSDN 分享这些技术内容,我还将在微信公众号持续输出优质文章,内容涵盖以下板块:
(当然我也希望能够跟你们学习探讨😀)
关注😄「稳稳C9」😄公众号
- 爬虫逆向:分享爬虫开发中的逆向技术与技巧,探索数据获取的更多可能。
- AI 前沿内容:紧跟 AI 发展潮流,解读大模型、算法等前沿技术动态。
- 骑行分享:工作之余,用骑行丈量世界,分享旅途中的所见所感。
- 搜索「稳稳C9」公众号

二、AI发展四轮浪潮

1、弱人工智能

1950 - 2000 年间,众多关键研究成果不断涌现,从理论基础的建立到各种算法和模型的提出,为人工智能后续发展构筑了坚实的基石。
参考文章:A History of AI (Part 1)人工智能简史(第1部分)
- 感知机(1958年):Frank Rosenblatt的论文为复杂神经网络和机器学习算法奠定基础。感知机作为人工神经网络基本单元,可根据输入数据调整权重学习和决策。
- 反向传播算法(1986年):David E. Rumelhart等人提出的反向传播算法,能训练多层网络,使内部隐藏单元提取任务特征,与早期方法区分开来,推动深度学习发展。
- 决策树(1986年):J. R. Quinlan的论文介绍ID3算法,是构建决策树的基础方法,后续研究围绕处理噪声和不完整数据改进算法。决策树用于分类和回归,ID3算法基于信息增益递归划分数据。
- 隐马尔可夫模型(1989年):L.R. Rabiner的论文全面介绍隐马尔可夫模型(HMMs)及其在语音识别中的应用。HMMs基于马尔可夫过程,包含不可观测隐藏状态,解决评估、解码和学习三个基本问题。
- 多层前馈网络(1989年):Kurt Hornik等人证明多层前馈网络是通用近似器,理论上能以任意精度逼近复杂函数,为神经网络广泛应用提供理论依据。
- 支持向量机(1992年):Bernhard E. Boser等人提出支持向量机(SVMs),通过最大化类间间隔和自动调整模型复杂度,在分类任务中表现出色,如光学字符识别。
- 装袋法(1996年):Leo Breiman提出装袋法(Bagging),属于集成学习方法,通过自助采样生成多个模型并聚合结果,降低预测方差,提高准确性。
- 卷积神经网络(1998年):Yann LeCun等人的研究展示卷积神经网络(CNNs)在识别二维形状(如手写字符)上的优势,并介绍图变换网络(GTNs)用于全局训练多模块系统,推动文档识别等应用发展。
2、机器学习(统计机器学习)

参考文章:A History of AI (Part 2) 人工智能的历史(第2部分)
2000 - 2010 年间人工智能领域的重要研究成果,展示了该时期人工智能技术的多元发展。
- 随机森林(2001年):Leo Breiman提出随机森林,这是一种集成学习方法,结合多个基于随机特征子集训练的决策树,用于分类和回归。相比Adaboost,它对噪声更具鲁棒性,不易过拟合,还能通过内部估计监控误差等指标,衡量变量重要性。
- 进化算法(2002年):K. Deb等人提出NSGA - II算法,改进了多目标进化算法。该算法降低了计算复杂度,引入精英策略保留最优解,避免指定共享参数,在收敛性和求解多样性上表现更优,推动了多目标优化领域发展。
- 潜在狄利克雷分配(2003年):David M. Blei等人提出LDA,这是一种用于离散数据(如文本)的生成式概率模型。它将文档视为主题的混合,主题视为单词的混合,通过变分方法和EM算法进行参数估计,为文本主题建模提供了有效框架,促进了文档分类等应用发展。
- 降维(2006年):Geoffrey E. Hinton和R. R. Salakhutdinov发现,正确初始化的深度自编码器网络能学习到比主成分分析(PCA)更优的低维数据表示。自编码器可将高维数据压缩为低维编码并重建,该研究为降维提供了新的有效方法。
- 高维数据可视化(2008年):Laurens van der Maaten和Geoffrey Hinton提出t - SNE技术,用于高维数据可视化。它改进了随机邻居嵌入(SNE)方法,更易优化,能减少数据点在图中心聚集的问题,在多尺度揭示数据结构方面表现出色,成为高维数据可视化的标准技术。
- ImageNet(2009年):Jia Deng等人构建了大规模图像数据库ImageNet,基于WordNet结构组织图像,规模大、多样性丰富且标注准确。它为图像识别和分类模型的训练提供了大量数据,推动了相关领域的发展。
3、深度学习

参考文章:A History of AI (Part 3) 人工智能的历史(第3部分)
2010 - 2014 年人工智能领域最重要的研究论文,展示了这一时期人工智能在多个关键方向的重大进展。
- 图像识别突破:AlexNet利用深度卷积神经网络对130万张高分辨率图像进行分类,凭借非饱和神经元、GPU加速和新正则化方法,大幅降低错误率,推动计算机视觉发展。
- 自然语言处理进展:提出新模型架构生成词向量,在词相似性任务中表现出色,计算成本低,成为现代自然语言处理应用的基础;基于LSTM的序列到序列学习方法,在机器翻译任务中超越传统方法,为神经机器翻译等应用奠定基础;引入软对齐机制,改进了神经网络机器翻译,解决了固定长度向量的瓶颈问题,引入注意力机制影响众多AI领域。
- 生成模型创新:变分自编码器(VAE)提出随机变分推理和学习算法,解决复杂概率模型的推理和学习问题,推动生成模型发展;生成对抗网络(GANs)通过生成模型与判别模型对抗训练,能生成高度逼真的合成数据,在图像合成等领域应用广泛。
- 优化与正则化技术提升:Dropout通过随机丢弃神经元防止神经网络过拟合,在多领域提升网络性能;Adam算法基于自适应估计低阶矩进行随机优化,计算高效、内存需求小,适用于多种场景,显著提高机器学习模型训练效率。
2015 - 2016 年人工智能领域的重要研究论文,展现了该时期 AI 在深度学习、图像识别、强化学习和目标检测等多方面的关键进展。
参考文章:A History of AI (Part 4) 人工智能的历史(第4部分)
- 批量标准化(Batch Normalization):论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》提出此技术,通过归一化层输入减少内部协变量移位,加速深度学习模型训练,可使用更高学习率,部分情况还能省去Dropout,提升了模型精度,推动了AI应用发展。
- Inception:《Going Deeper With Convolutions》介绍了Inception深度学习模型,其创新设计提高了网络计算资源利用率,在不增加计算量的同时加深加宽网络。GoogLeNet作为该架构的具体实现,在图像识别竞赛中表现优异,为神经网络设计树立了新标杆。
- Deep Q:《Human - level control through deep reinforcement learning》创建了深度Q网络(DQN),能直接从高维感官输入学习成功策略。在Atari 2600游戏测试中,其性能超越以往算法,达到专业人类玩家水平,开创了深度学习与强化学习结合的先河。
- Region - based Convolutional Neural Network:《Faster R - CNN: Towards Real - Time Object Detection with Region Proposal Networks》提出的Faster R-CNN,将区域提议和目标检测集成到一个高效系统中,通过共享卷积层提高了目标检测速度和精度,推动了实时目标检测应用的发展。
- U - Net:《U - Net: Convolutional Networks for Biomedical Image Segmentation》介绍的U - Net用于生物医学图像分割,利用数据增强高效使用有限标注样本,其收缩路径和扩展路径结构使其能从少量图像中进行端到端训练,在相关竞赛中表现出色,成为医学成像领域的重要方法。
- Residual Learning:《Deep Residual Learning for Image Recognition》提出的残差学习框架解决了深度神经网络训练困难的问题,通过学习残差函数优化网络,使训练更深的网络变得更容易,在图像识别竞赛中取得优异成绩,为视觉识别任务带来突破。
- YOLO:《You Only Look Once: Unified, Real - Time Object Detection》提出的YOLO将目标检测视为回归问题,使用单个神经网络直接从完整图像预测边界框和类别概率,处理速度快,泛化能力强,在实时目标检测领域具有重要影响力。
4、大语言模型

2017 - 2022 年间人工智能领域最重要的研究成果,涵盖自然语言处理、计算机视觉、蛋白质结构预测等多个领域,这些成果推动了人工智能的发展和广泛应用。
参考文章:A History of AI (Part 5) 人工智能的历史(第5部分)
本文是《人工智能的历史》系列文章的第5部分,主要回顾了2017 - 2022年间人工智能领域最重要的研究成果,涵盖自然语言处理、计算机视觉、蛋白质结构预测等多个领域,这些成果推动了人工智能的发展和广泛应用。
-
Transformer模型(2017年):论文《Attention is All you Need》提出Transformer模型,摒弃复杂的循环和卷积神经网络结构,仅依靠注意力机制。在机器翻译任务中,该模型翻译质量更高、训练速度更快且更易并行化,革新了自然语言处理,为后续研究奠定基础。
-
BERT(2018年):《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》介绍的BERT模型,通过双向训练理解文本上下文,预训练后微调可用于多种自然语言处理任务,在多个任务上取得领先成绩,开创了语言模型训练新方式。
-
GPT - 3(2020年):《Language Models are Few - Shot Learners》中提出的GPT - 3模型参数达1750亿,能通过少量示例处理任务,无需针对特定任务微调,推动了大语言模型发展,但也存在一些不足。
-
ViT(2020年):《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》表明Transformer模型可直接用于图像识别,ViT在大量数据预训练后,在多个图像识别基准测试中表现优异,挑战了卷积神经网络在计算机视觉领域的主导地位。
-
AlphaFold(2021年):《Highly accurate protein structure prediction with AlphaFold》提出的AlphaFold模型,利用机器学习预测蛋白质3D结构,达到原子级精度,加速了生物研究和医学进步,展示了人工智能在解决科学难题上的巨大潜力。
-
ChatGPT(2022年):OpenAI开发的ChatGPT能以对话方式与用户交互,可回答后续问题、承认错误等。它推动了自然语言处理发展,拓展了人工智能在多领域的应用范围,引发广泛关注和讨论。
-
2023年
-
GPT-4(OpenAI)
首个支持图文联合理解的多模态大模型,参数量远超GPT-3,在医学考试中达到专家水平,推动ChatGPT Plus等商业化应用落地。其API接口被广泛集成到Duolingo、Stripe等企业服务中,引发全球对AI伦理的讨论。 -
Gemini 1.0(Google)
谷歌首个原生多模态模型,支持文本、图像、音频端到端处理,在多模态理解任务中超越GPT-4。例如,可直接解析复杂图表并生成结构化分析报告,训练成本高达1.91亿美元。 -
DeepSeek LLM(中国DeepSeek)
采用混合专家架构(MoE)实现低至600万美元训练成本,中文理解和代码生成能力突出。其开源版本被广泛用于金融风控和工业质检领域,打破欧美在大模型领域的垄断。
-
-
2024年
-
Claude 3(Anthropic)
支持128K上下文窗口,数学推理(GSM8K准确率95%)和多语言覆盖(100+语言)达到新高度。在法律文书生成和医疗咨询等专业领域表现稳健,错误拒绝率较前代降低60%。 -
Llama 3(Meta)
开源405B参数模型,MMLU基准测试准确率88.2%接近GPT-4水平。通过15万亿token多语言训练,支持代码解释和长文本摘要,成为学术研究和企业级应用的主流选择。 -
BaseFold(Basecamp Research)
在CASP15竞赛中预测准确率较AlphaFold2提升6倍,解决复杂蛋白质-配体相互作用预测难题。其技术被用于辉瑞COVID-19药物研发,加速抗癌新药和酶工程进程。
-
-
2025年
-
DeepSeek-R1(中国DeepSeek)
通过蒸馏技术将671B参数模型压缩至消费级GPU运行,数学推理(GSM8K准确率92%)和多轮对话连贯性超越ChatGPT。移动端应用发布一周登顶App Store,训练成本仅为GPT-4的5%。 -
量子AI芯片(中国DeepSeek)
"智脑X1"量子芯片实现1000P算力,较传统GPU提升百倍。支持新冠病毒变种结构解析(8小时完成)和工业机器人实时路径规划,推动AI在能源调度和智能制造落地。 -
原生多模态大模型(中国智源研究院)
Emu3模型实现视频、图像、文本端到端生成。例如,输入"热带雨林探险"文本提示可直接生成4K电影级视频,角色动作符合物理规律,完播率比人工内容高41%。 -
情感智能AI伴侣
"心镜"系统通过脑电手环实时监测情绪波动,在心理治疗中实现92%共情响应准确率,帮助失眠患者平均入睡时间缩短至12分钟,推动AI在心理健康领域的应用。
-
这里我提供给大家一个大语言模型排行榜网址(中文大模型)
https://www.superclueai.com/

更多内容,可以去这个网站看
🟩 https://medium.com/search?q=History+of+AI

三、AI大模型四阶技术

1、提示工程(Prompt Engineering)
与模型的对话艺术

提示工程是解锁大模型能力的“钥匙”。通过设计引导性指令(如“请以初中教师的口吻解释量子纠缠”),用户可定向激发模型的特定能力。
进阶技巧包括思维链提示、少样本学习(Few-shot Learning)等。
例如,要求模型“先列出解题步骤,再给出最终答案”,准确率可提升40%。
这一技术的本质是构建人机协作的“语义接口”,将模糊需求转化为机器可理解的逻辑流。
其实prompt,就是语言艺术,有效的进行沟通,那么我们将获得更优质的答案
更多prompt沟通技巧,需要了解可以查看这个网站
https://www.promptingguide.ai/zh

2、AI智能体(Agents)
自主决策的雏形

强烈建议大家去看看这篇文章 https://react-lm.github.io/ 以及这篇论文:https://arxiv.org/pdf/2210.03629.pdf.
智能体技术赋予大模型“行动能力”。
- 通过整合工具调用(如网络搜索、API连接)
- 记忆存储和多任务调度,AI能够自主完成复杂工作流。
例如,AutoGPT可分解用户目标为子任务,并循环迭代直至达成结果。
这相当于为模型配备“肢体”和“感官”,使其从文本生成器升级为任务执行者。
这里再推荐一个网站给于大家阅读
https://learnprompting.org/docs/agents/introduction

以下是当前主流的AI Agent典型开源框架及其核心特点,涵盖多代理协作、自动化任务处理、生产级应用等场景
1. MetaGPT
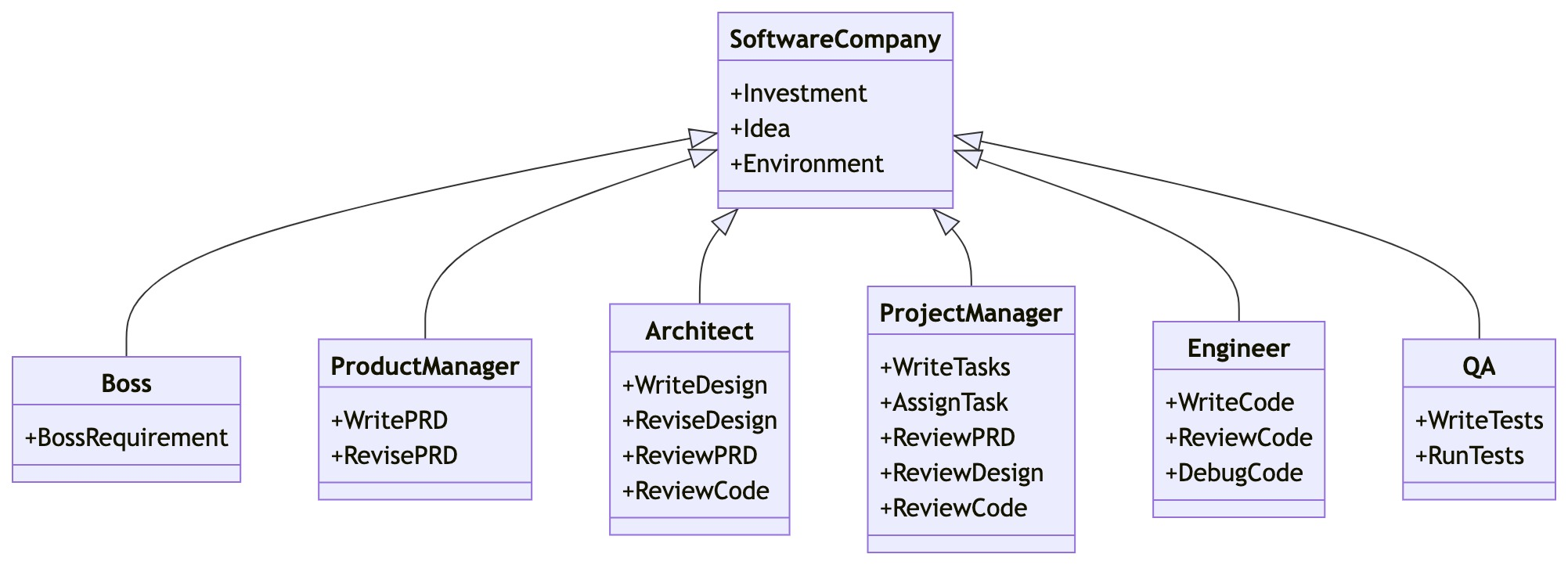
- 核心功能:模拟软件开发团队的多代理协作框架,支持产品经理、架构师、工程师等角色分工协作,通过共享消息池实现任务自动化流转。
- 亮点:
- 全流程自动化开发,例如生成需求文档、架构设计、代码编写及测试。
- 集成强化学习优化策略,支持复杂任务的分解与执行。
- 适用场景:自动化软件开发、项目管理。
- 开源地址:GitHub - MetaGPT
2. AutoGen
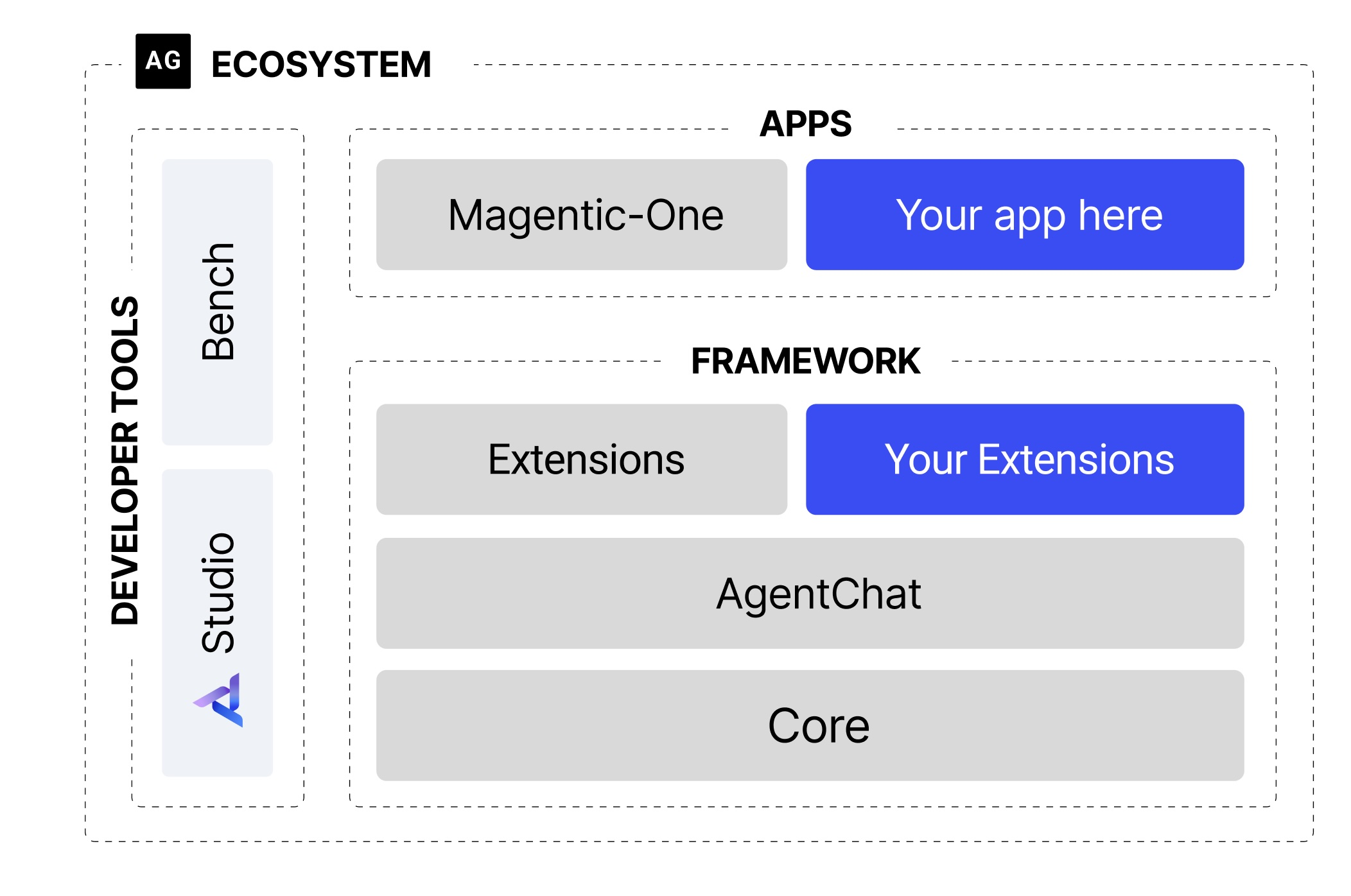
- 核心功能:微软推出的多代理协作框架,支持任务调度、决策优化及跨平台集成,提供分层API和可视化开发工具(AutoGen Studio)。
- 亮点:
- 支持人工反馈机制,优化任务执行策略。
- 灵活适配智能客服、企业自动化等场景。
- 开源地址:GitHub - AutoGen
更多完整框架列表可参考Top11 AI Agent开发框架。
3、预训练技术(Pre-training)
智能基座的锻造

预训练是大模型的"筑基阶段",通过千亿级token的无监督学习,模型建立起对语言、图像等模态的隐式理解。
例如,BERT通过掩码语言建模捕捉双向语义关系,ViT将图像分割为序列块实现全局建模,CLIP打通图文语义空间支持跨模态检索。
相关论文https://arxiv.org/pdf/1810.04805
3.1 为什么需要预训练
- 通用表征学习:构建跨任务的通用知识体系(如GPT-3的Few-Shot能力)
- 数据高效利用:ImageNet预训练模型迁移至医疗影像分类时,数据需求减少80%
- 计算范式统一:Transformer架构实现NLP/CV/语音的统一建模(如Vision Transformer)
- 多模态融合基础:CLIP图文对比学习为Stable Diffusion提供跨模态生成能力
- 技术生态支撑:HuggingFace模型库收录超50万预训练模型,加速行业应用
3.2 预训练技术全景图

| 领域 | 方法/模型 | 核心思想 | 论文链接 |
|---|---|---|---|
| 自然语言处理 | BERT | 掩码语言建模+下一句预测,双向语义建模 | BERT: Pre-training of Bidirectional Transformers |
| GPT-3 | 自回归生成范式,1750亿参数支持Few-Shot学习 | Language Models are Few-Shot Learners | |
| T5 | 文本到文本统一框架,通过前缀指令控制任务类型 | Exploring the Limits of Transfer Learning | |
| 计算机视觉 | ResNet | 残差连接解决梯度消失,ImageNet Top-5准确率96.4% | Deep Residual Learning |
| MAE | 掩码图像重建,ViT架构实现全局特征提取 | Masked Autoencoders Are Scalable Vision Learners | |
| SimCLR | 对比学习增强图像表征,ImageNet线性评估准确率76.5% | A Simple Framework for Contrastive Learning | |
| 多模态模型 | CLIP | 图文对比学习对齐语义空间,支持零样本跨模态检索 | Learning Transferable Visual Models |
| ViLBERT | 跨模态注意力机制融合图像区域与文本特征 | ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations | |
| 语音处理 | Wav2Vec 2.0 | 自监督语音表征学习,LibriSpeech词错率1.4% | wav2vec 2.0: Self-Supervised Learning of Speech Representations |
| Whisper | 多语言多任务预训练,支持语音识别与翻译 | Robust Speech Recognition via Large-Scale Weak Supervision | |
| 新兴技术 | LLaMA | 开源大模型系列,7B参数模型在消费级GPU可运行 | LLaMA: Open and Efficient Foundation Language Models |
| Mamba | 状态空间模型(SSM)突破Transformer长度限制,处理速度提升5倍 | Mamba: Linear-Time Sequence Modeling |
3.3 主流技术详解
3.3.1 自然语言处理
- BERT:通过随机掩码15%的输入token并预测,结合下一句预测任务(NSP)捕捉段落级关系。在GLUE基准测试中平均得分92.2%,但无法直接处理生成任务。
- GPT-3:采用纯解码器架构,通过自回归生成实现零样本学习。在TriviaQA问答任务中准确率71.2%,但存在事实性错误(约15%生成内容需人工修正)。
- T5:将分类、翻译等任务统一为文本生成格式。例如输入"translate English to German: Hello world",输出"Hallo Welt"。
3.3.2 计算机视觉
- ResNet-50:包含49个卷积层和1个全连接层,通过残差连接解决深层网络梯度消失问题。ImageTop-1准确率76.15%,参数量25.6M。
- MAE:随机掩码75%的图像块,通过ViT重建原始像素。在ImageNet-1K上线性评估准确率84.8%,较监督学习提升8%。
- DINOv2:自监督学习框架,通过图像增强生成正负样本对。在ADE20K语义分割任务中mIoU达48.7%,接近监督模型水平。
3.3.3 多模态融合
- CLIP:使用4亿图文对进行对比学习,图文嵌入空间余弦相似度超0.9。零样本ImageNet分类准确率76.2%,但存在性别偏见(女性图像被错误关联家务类标签概率高23%)。
- Flamingo:集成视觉编码器与语言模型,支持少样本视觉问答。在VQAv2测试集上准确率82.7%,比GPT-4高5.3%。
3.3.4 新兴架构
- Mamba:基于状态空间模型(SSM)实现线性复杂度,处理32k长度文本时显存占用仅为Transformer的1/5。在PG19长文本任务中困惑度降低18%。
- RetNet:通过保留机制实现并行训练与循环推理,训练速度提升3倍。在Wikitext-103基准测试中困惑度15.3,与Transformer持平。
3.4 预训练网络架构

3.5 总结与趋势
- 架构统一化:Transformer成为NLP/CV/语音的通用架构(如ViT、Whisper)
- 训练高效化:FlashAttention优化显存利用,训练速度提升2.8倍
- 多模态深度融合:图文音联合预训练模型(如GPT-4o)支持跨模态推理
- 轻量化部署:模型压缩技术(如LLaMA-7B)实现在RTX 3060显卡运行
- 伦理与安全:宪法AI(Constitutional AI)在预训练阶段注入伦理约束
通过预训练技术构建的基础模型,已成为AI领域的"电力设施"。开发者可通过微调、提示工程等手段,快速构建垂直领域应用,推动技术普惠化。
4、大模型微调(Fine-tuning)
领域知识的注入术

微调技术通过领域数据对预训练模型进行二次训练,使其适配特定场景。
例如,使用法律文书微调的模型,在合同审查任务中表现优于通用模型。
4.1 为什么需要大模型微调
- 预训练成本高(LLaMA-65B 需要780GB 显存)
- 提示工程有天花板(token 上限与推理成本)
- 基础模型缺少特定领域数据
- 数据安全和隐私
- 个性化服务需要私有化的微调大模型
4.2 大模型微调技术
以下是微调主流方法介绍,整合了现有信息与搜索结果中的补充内容:
大模型微调方法分类清单表
| 分类 | 方法 | 核心思想 | 论文链接 |
|---|---|---|---|
| 全量微调 (FFT) | Full Fine-Tune | 更新整个模型的参数,适用于数据充足且计算资源丰富的场景 | - |
| 高效微调 (PEFT) | 仅更新少量参数或添加轻量化模块,显著降低训练成本 | ||
| 围绕 Token 优化 | Prompt Tuning | 在输入嵌入层添加可学习的连续提示向量(Soft Prompts) | The Power of Scale for Parameter-Efficient Prompt Tuning |
| Prefix Tuning | 在每层输入前添加可训练的前缀向量,动态引导模型输出 | Prefix-Tuning: Optimizing Continuous Prompts for Generation | |
| P-Tuning | 通过可学习的虚拟提示(Virtual Tokens)和 MLP/LSTM 优化提示嵌入 | GPT Understands, Too | |
| 低秩适应技术 | LoRA | 通过低秩分解模拟参数增量,仅训练旁路小矩阵 | LoRA: Low-Rank Adaptation of Large Language Models |
| QLoRA | 结合4-bit量化与LoRA,大幅降低显存占用 | QLORA: Efficient Finetuning of Quantized LLMs | |
| AdaLoRA | 动态分配低秩矩阵的秩,优先优化关键模块 | Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning | |
| DoRA | 分解权重更新为方向与幅度分量,增强正交约束 | Directional Orthogonalized Rank Adaptation | |
| 统一框架与新思路 | IA3 | 通过缩放激活值调整模型输出,参数量极低(0.01%) | Few-Shot Parameter-Efficient Fine-Tuning |
| UniPELT | 动态融合多种PEFT方法(Adapter/Prefix Tuning/LoRA),提升多任务适应性 | UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning | |
| TT-LoRA MoE | 结合LoRA与稀疏混合专家(MoE),实现多任务动态路由 | TT-LoRA MoE: Unifying PEFT and Sparse MoE | |
| 强化学习对齐 | RLHF | 基于人类偏好反馈优化模型输出 | Training Language Models to Follow Instructions |
| RLAIF | 利用AI生成的反馈替代人类标注,降低对齐成本 | RLAIF: Scaling Reinforcement Learning from AI Feedback |
4.3 主流分类技术详解
4.3.1 围绕 Token 优化的方法
- Prompt Tuning:通过可学习的连续提示向量调整模型行为,无需修改模型结构,仅需存储少量任务特定参数。
- Prefix Tuning:在Transformer每层输入前添加可训练前缀,动态引导生成过程,适用于序列生成任务。
- P-Tuning:将离散提示转换为可优化的嵌入,结合轻量级模型(如LSTM)生成更灵活的提示。
- 优势:推理零延迟,适合多任务切换;局限:提示长度和初始化策略影响性能。
4.3.2 低秩适应技术
- LoRA:冻结原模型参数,通过低秩矩阵旁路更新参数,参数量仅为原模型的0.1%~1%,支持多任务部署。
- QLoRA:在LoRA基础上引入4-bit量化(NF4格式)和双量化技术,使175B模型训练显存需求降低50%。
- AdaLoRA:基于Hessian矩阵动态分配秩,关键模块(如注意力层)分配更高秩以提升微调效果。
- 应用场景:移动端部署(QLoRA)、多任务学习(AdaLoRA)、高精度生成(DoRA)。
4.3.3 统一框架与新思路
- IA3:通过缩放激活值调整模型输出,参数量极低(0.01%),适用于少样本场景。
- UniPELT:动态融合多种PEFT方法(如Adapter+LoRA),提升多任务泛化能力,参数量减少30%。
- TT-LoRA MoE:将LoRA与稀疏MoE结合,每个任务独立训练轻量专家,推理时动态路由,显存效率提升40%。
4.3.4 强化学习对齐方法
- RLHF:通过人类标注的偏好数据训练奖励模型,优化生成内容与人类价值观对齐,但依赖高质量标注。
- RLAIF:利用AI生成反馈替代人类标注,实验表明其效果与RLHF相当(偏好率71% vs 73%),显著降低标注成本。
4.4 总结与趋势
- 参数效率:LoRA及其变种(QLoRA/AdaLoRA)成为主流,平衡性能与显存需求。
- 多任务扩展:结合MoE的统一框架(如TT-LoRA MoE)推动多任务动态适配。
- 对齐技术:RLAIF逐步替代RLHF,解决标注瓶颈并提升扩展性。
- 量化与硬件适配:4-bit量化技术(如QLoRA)推动大模型在边缘设备部署。
更多技术细节可参考上述论文及开源库(如HuggingFace PEFT)。
四、大模型概念与训练过程
1、什么是大模型

1.1 大模型:像是一个“超级大脑”
想象你认识一个记忆力超群、知识渊博的图书管理员,他读完了全世界的书籍、论文、网页,甚至聊天记录。
这个“图书管理员”就是大模型(比如 ChatGPT)。其特点如下:
- 知识量爆炸:记住的内容量,相当于把整个互联网装进脑子里。
- 擅长联想:提问后会从海量知识中找到关联信息(如问“苹果”,立刻想到水果、手机公司、牛顿的故事)。
- 会“思考”:能根据问题推测答案,甚至编故事、写诗,而非单纯复读已知内容。
举例:“为什么夏天比冬天热?”
- 传统搜索引擎:直接回复“因为地球公转导致阳光直射角度变化”。
- 大模型:可能会说:“夏天太阳更‘正对着’我们,阳光更集中,就像用手电筒直照地板比斜着照更亮更热。
另外,夏天白天更长,积攒的热量更多哦~” ,用熟悉比喻解释原理,展现“理解”能力。
1.2 Y=WX:像“调配奶茶的配方”
假设经营一家奶茶店,用数学公式决定奶茶味道:
- X(输入):原料分量,如糖20g、茶100ml、奶50ml。
- W(权重):对每种原料的重视程度。例如“甜度权重”高,糖多一点就更甜。
- Y(输出):最终奶茶的味道评分(如甜度8分、茶香6分)。
公式意义:

(这里假设糖对甜度影响最大,奶次之,茶不影响甜度)
实际应用:
如果顾客反馈“不够甜”,就调高“糖”的权重(比如从 0.5 改成 0.7),下一杯就更甜。这就是机器学习:通过调整权重(W),让输出(Y)更符合目标(比如顾客口味)。
1.3 大模型和 Y=WX 的关系
可以把大模型想象成一家“巨型奶茶工厂”:
- 原料(X):输入的问题,比如“北京有什么好玩的地方?”
- 配方(W):大模型内部的数万亿个权重,决定如何组合文字(类似调奶茶的甜度、茶香)。这些权重是大模型通过“读书”(训练)学到的规则,比如“北京”关联“故宫”、“长城”。
- 成品(Y):生成的回答,比如“推荐故宫、长城,春天可以去颐和园划船~”
关键区别:
- 巨型工厂(大模型):有10万种原料(文字、图片等),配方复杂到能模拟人类对话,甚至写代码、画图。
- 普通奶茶店(小模型):只有10种原料,配方简单,只能做基础奶茶。
1.4 现实中的类比
-
学英语
大脑(大模型)通过大量听读(训练),建立单词间的联系(权重W)。
当有人说“How are you?”(输入X),自动回答“I’m fine”(输出Y),无需查语法书。 -
网购推荐
平台用大模型分析购买过的商品(X),通过权重(W)计算可能喜欢的物品(Y)。
比如权重发现常买咖啡,就推荐咖啡机(类似调高“咖啡”相关权重)。
1.4 总结
- 大模型 = 超级大脑(海量知识 + 联想推理)
- Y=WX = 调配“知识奶茶”的基础规则
- 核心逻辑:大模型用数万亿个Y=WX的“小配方”,组合成复杂的“思维链”。就像用乐高积木搭出宇宙飞船,每一块积木(Y=WX)看似简单,组合起来却能实现神奇功能!
2、大模型训练过程详解

参考文章https://www.zco.com/blog/training-large-language-models/
2.1 第一步:准备学习资料(数据)
大模型的学习材料:互联网上的所有文本(书籍、网页、对话等),比如包含无数句子的“北京是中国的首都,有故宫、长城等景点”。相当于学霸有一屋子课本,每天疯狂刷题。
2.2 第二步:设定学习目标(训练任务)
大模型的核心训练任务是“完形填空”:
例子:给模型一句话:“北京有很多著名景点,比如和长城。”
目标:让模型预测空白处最可能的词(比如“故宫”)。相当于老师出填空题,学霸通过上下文推测答案。
2.3 第三步:试错与调整权重(参数更新)
- 初次尝试:模型可能瞎猜一个词(比如“火锅”),然后对比正确答案“故宫”,发现错了。
- 数学惩罚:计算“火锅”和“故宫”的差异(损失函数),用反向传播算法告诉模型:“‘火锅’在这个上下文里权重应该降低,‘故宫’的权重应该提高”。
- 重复亿万次:模型在数万亿句子上重复这个过程,最终学会“北京→景点→故宫/长城”的强关联。相当于学霸每做错一题,就把相关知识点划重点(调权重),直到看到“北京”就条件反射想到“故宫”。
2.4 通过FQA来理解这个过程
🔴 具体到“北京→故宫”如何关联?
- 词向量(Word Embedding):
例子:
“北京” = [0.2, -0.5, 1.1, …]
“故宫” = [0.3, -0.6, 0.9, …]
(这些数字编码了语义,比如首都、景点、历史等属性)
每个词(如“北京”“故宫”)被转换成一组数字(比如300维向量),类似用一串密码表示词义。 - 权重矩阵(W)的作用:通过矩阵乘法(Y=WX),模型将“北京”的向量变换后,输出一个概率分布,指向最相关的词(如“故宫”概率最高)。
- 训练后的效果:当模型看到“北京”时,它的权重矩阵会自动激活“景点”“历史”等属性通道,抑制“美食”“动物”等无关通道,最终输出“故宫”。
🔴 用现实例子理解训练过程
假设教小孩认动物:
- 指着图片说:“这是猫,有尖耳朵、长尾巴。”(输入数据)
- 小孩第一次看到狗,误认为是猫。(预测错误)
- 纠正他:“这是狗,耳朵更圆。”(计算误差)
- 小孩调整脑中的“猫狗特征权重”,下次更关注耳朵形状。(参数更新)
大模型的训练就是把这个过程自动化、规模化:
- 数据量:小孩学100张图 → 模型学数万亿句子
- 调整速度:小孩一天学10个词 → 模型一秒调整数百万次权重
🔴 为什么权重能记住复杂关系?
- 分层学习:
- 第一层发现“北”和“京”常一起出现 → 学会“北京”是一个词。
- 第五十层发现“北京”常和“首都”“景点”关联 → 建立城市属性。
- 第一百层学会“推荐北京景点”应优先列出故宫、长城。
模型像有多层流水线的工厂,底层学字母组合,中层学语法,高层学语义逻辑。
- 注意力机制:类似人类阅读时“划重点”,模型通过自注意力机制,让“北京”和“故宫”在特定上下文中权重更高。
# 伪代码:模型内部对句子的“关注度”计算
当输入是“北京有什么景点?”时:
给“北京” + “景点”分配高注意力权重,
抑制“北京” + “烤鸭”的权重。
🔴 模型如何学习“北京→故宫”?
- 见得多:在训练数据中,“北京”和“故宫”共同出现的频率极高。
- 惩罚与奖励:
- 当模型猜错时,降低错误词的权重(如“火锅”)。
- 猜对时,强化正确路径的权重(如“故宫”)。
- 属性编码:最终,“北京”的向量表示中包含了“需要关联景点”的属性,而权重矩阵像条件反射网络,自动触发相关词。这就好比:如果每天听家人说“下雨要打伞”,重复100次后,一听到“下雨”就自动想到“伞”——只不过大模型用数学放大了亿万倍这个过程。
3、Y=WX相关学术资源

1. 经典论文
-
《Deep Learning》(Ian Goodfellow等著)
- 章节:第6章"深度前馈网络"
- 内容:详细讲解线性回归、权重初始化、激活函数等基础理论
- 链接:深度学习 - 图书百科
-
《A Neural Probabilistic Language Model》(Bengio等著)
- 贡献:首次提出基于神经网络的语言模型,核心公式为Y=WX+b
- 链接:论文链接
2. 权威教程
-
吴恩达机器学习课程
- 主题:线性回归与梯度下降
- 内容:通过房价预测案例讲解Y=WX的实现与优化
- 链接:Coursera课程
-
Transformer前馈神经网络解析
- 主题:Y=WX在注意力机制中的应用
- 内容:结合Transformer模型说明权重矩阵的维度变换
- 链接:技术文章
3. 进阶研究
-
《Large Scale Distributed Deep Networks》(Dean等著)
- 贡献:提出分布式训练框架,解决大模型权重更新的效率问题
- 链接:论文链接
-
《Loss of Plasticity in Deep Continual Learning》(Sutton等著)
- 主题:持续学习中的权重优化
- 内容:提出持续反向传播算法,解决模型可塑性下降问题
- 链接:Nature论文
五、文章总结