文章目录
- 一、实验目的
- 实验内容
- 设计思路
- 三、实验代码实现
- 四、总结
一、实验目的
理解linux文件系统的内部技术,掌握linux与文件有关的系统调用命令,并在此基础上建立面向随机检索的散列结构文件;## 二、实验内容与设计思想
实验内容
1.设计一组散列文件函数,包括散列文件的创建,打开,关闭,读,写等;
2.编写一个测试程序,通过记录保存,查找,删除等操作,检查上述散列文件是否实现相关功能;
设计思路
- 设计散列文件函数
我设计了一组散列文件函数,涵盖了散列文件的创建、打开、关闭、读和写等操作。这些函数是构建散列结构文件的基础,通过合理的设计和实现,确保了文件操作的高效性和正确性。 - 编写测试程序
为了验证散列文件的功能,我编写了一个测试程序,通过记录的保存、查找和删除等操作,检查散列文件是否能正常工作。这个测试程序就像是一个 “质检员”,帮助我发现并解决代码中可能存在的问题。
三、实验代码实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define HASH_TABLE_SIZE 10 // 散列表大小
#define MAX_RECORD_LENGTH 100 // 记录最大长度
typedef struct Record {
char key[20]; // 记录的关键字
char data[MAX_RECORD_LENGTH]; // 记录的数据
struct Record* next; // 链接到下一个记录(用于处理冲突)
} Record;
typedef struct HashTable {
Record* table[HASH_TABLE_SIZE]; // 散列表
} HashTable;
// 哈希函数
unsigned int hash(const char* key) {
unsigned int hashValue = 0;
while (*key) {
hashValue = (hashValue << 5) + *key; // 左移 5 位并加上当前字符的 ASCII 值
key++;
}
return hashValue % HASH_TABLE_SIZE;
}
// 创建散列文件
HashTable* createHashTable() {
HashTable* ht = (HashTable*)malloc(sizeof(HashTable));
memset(ht, 0, sizeof(HashTable)); // 初始化散列表
return ht;
}
// 插入记录
void insertRecord(HashTable* ht, const char* key, const char* data) {
unsigned int index = hash(key);
Record* newRecord = (Record*)malloc(sizeof(Record));
strcpy(newRecord->key, key);
strncpy(newRecord->data, data, MAX_RECORD_LENGTH);
newRecord->next = ht->table[index]; // 插入链表的头部
ht->table[index] = newRecord;
}
// 查找记录
Record* findRecord(HashTable* ht, const char* key) {
unsigned int index = hash(key);
Record* record = ht->table[index];
while (record != NULL) {
if (strcmp(record->key, key) == 0) {
return record; // 找到记录
}
record = record->next;
}
return NULL; // 未找到记录
}
// 删除记录
void deleteRecord(HashTable* ht, const char* key) {
unsigned int index = hash(key);
Record* record = ht->table[index];
Record* prev = NULL;
while (record != NULL) {
if (strcmp(record->key, key) == 0) {
if (prev == NULL) {
ht->table[index] = record->next; // 删除链表头部元素
} else {
prev->next = record->next; // 删除中间或尾部元素
}
free(record); // 释放内存
return;
}
prev = record;
record = record->next;
}
}
// 关闭散列文件(释放内存)
void closeHashTable(HashTable* ht) {
for (int i = 0; i < HASH_TABLE_SIZE; i++) {
Record* record = ht->table[i];
while (record != NULL) {
Record* temp = record;
record = record->next;
free(temp); // 释放每个记录
}
}
free(ht); // 释放哈希表
}
// 测试程序
int main() {
HashTable* ht = createHashTable();
// 插入记录
insertRecord(ht, "key1", "data1");
insertRecord(ht, "key2", "data2");
insertRecord(ht, "key3", "data3");
// 查找记录
Record* found = findRecord(ht, "key2");
if (found) {
printf("找到记录: %s -> %s\n", found->key, found->data);
} else {
printf("未找到记录\n");
}
// 删除记录
deleteRecord(ht, "key2");
found = findRecord(ht, "key2");
if (found) {
printf("找到记录: %s -> %s\n", found->key, found->data);
} else {
printf("未找到记录\n");
}
// 关闭哈希表
closeHashTable(ht);
return 0;
}
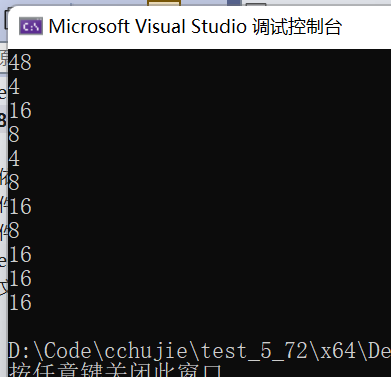
结果:
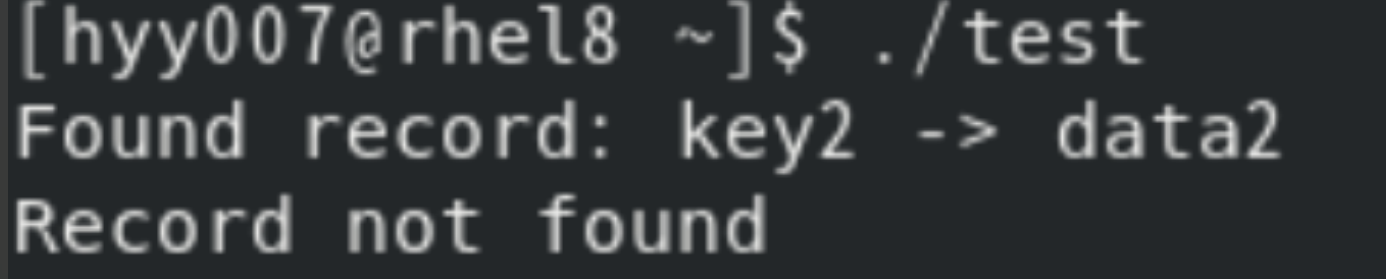
结果分析:
程序首先插入三条记录:
key1 -> data1
key2 -> data2
key3 -> data3
当程序尝试查找key2时,程序找到了该记录,因此输出:Found record: key2 -> data2
接下来,程序删除了key2记录。
再次查key2 时,记录已经被删除,因此输出:Record not found
四、总结
- 遇到的问题
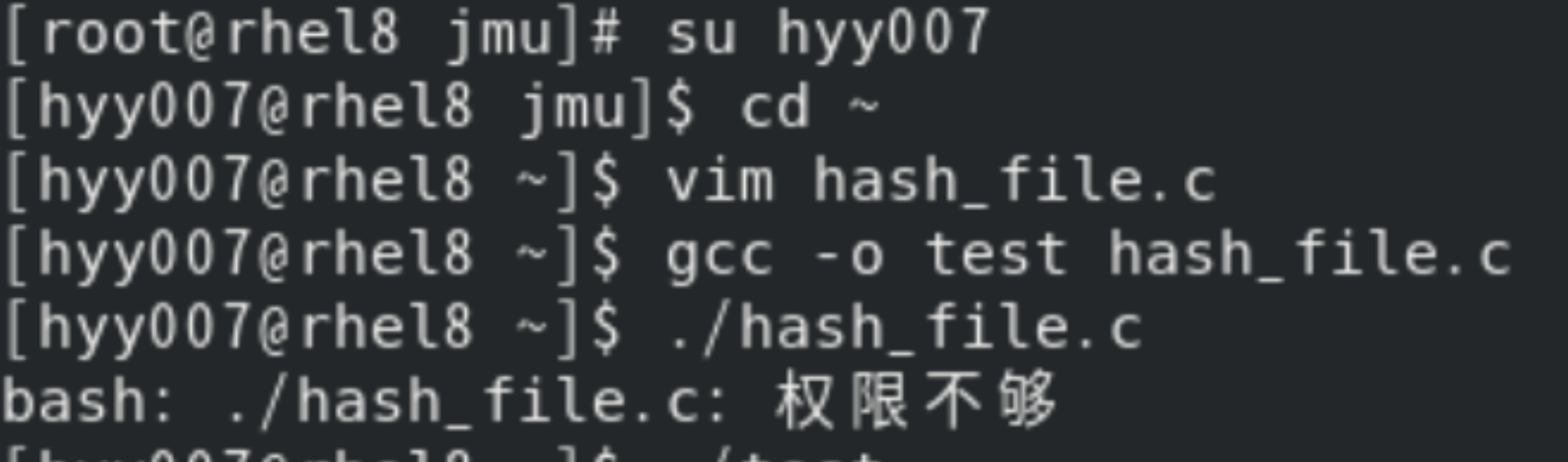
第一次运行时,我输错了编译文件的名字,结果提示权限不够。这让我意识到在操作过程中一定要细心,一个小小的失误都可能导致程序无法正常运行。经过修正后,程序的运行结果符合预期。程序先插入了三条记录,然后成功查找到了 key2 对应的记录,接着删除了该记录,再次查找时就显示未找到记录,这表明散列文件的基本功能已经实现。
为了处理哈希冲突,我使用了链式法。通过链表存储多个记录,保证了散列表的完整性。这让我认识到在设计数据结构时,不仅要考虑基本功能的实现,还要考虑可能出现的异常情况,并采取有效的处理方法。
在实现散列表的过程中,我更加深入地理解了指针和内存管理的重要性。正确地分配和释放内存是保证程序稳定运行的关键,稍有不慎就可能导致内存泄漏或悬空指针等问题。这也提醒我在今后的编程中要养成良好的内存管理习惯。
这次实验让我对 Linux 文件系统和散列结构文件有了更深入的理解,也提升了我的编程能力和问题解决能力。在今后的学习和工作中,我将继续探索数据结构和算法的奥秘,不断提升自己的技术水平。同时,我也会更加注重细节,避免因为粗心而导致的错误。我相信,通过不断的实践和学习,我能够更好地应对各种编程挑战。
![World of Warcraft [CLASSIC][80][Deluyia] [Fragment of Val‘anyr]](https://i-blog.csdnimg.cn/direct/09efa6e00f52422e8bf89b7ec6781833.jpeg)