博主简介:努力学习的22级本科生一枚 🌟;探索AI算法,C++,go语言的世界;在迷茫中寻找光芒🌸
博客主页:羊小猪~~-CSDN博客
内容简介:常见目标检测算法简介😕😕😕😕😕😕😕😕😕
往期内容:深度学习基础–目标检测入门简介-CSDN博客
文章目录
- 1、tow-stage
- R-CNN
- Fast R-CNN
- Faster R-CNN
- Mask R-CNN
- 2、one-stage
- 单发多宽检测(SSD)
- YOLO
- 3、参考资料
1、tow-stage
R-CNN
最早的目标检测模型。

📖 简介:
传统目标检测的思路,采用提取框,对每个提取框进行特征提取、图像分类、非极大值抑制四个步骤进行检测。
对于一张图片来说,R-CNN首先会基于启发式搜索算法生成大约2000个候选区域,然后每个区域固定大小,并且传入一个CNN模型中,最后得到一个特征向量,这个向量会传到一个SVM模型中,进行类别计算,进行分类,并且,最后运用 了一个边界框回归模型,通过边框回归模型对框的准确位置进行修正。
📚 解释一些名词:
- 启发式搜索,这个算很难,也包含很多算法,简单理解他的作用是在图片上选取物体可能出现的区域框(锚框);
- 非极大值抑制:是一种在目标检测中去除冗余边界框的后处理算法,通过保留局部得分最高的检测框并抑制与其重叠度(IoU)超过阈值的低得分框,实现检测结果的唯一性与精确性;这个在上一篇博客中已经简单介绍了(深度学习基础–目标检测入门简介-CSDN博客),就是去除多余的锚框;
🐾 算法步骤:
- 使用启发式搜索来选择锚框;
- 使用预训练模型来对每个锚框抽取特征;
- 训练一个SVM来对类别进行分类;
- 训练一个线性回归模型来预测边缘框的偏移,这一步就是将锚框来预测他真实的位置(边缘框)偏移;
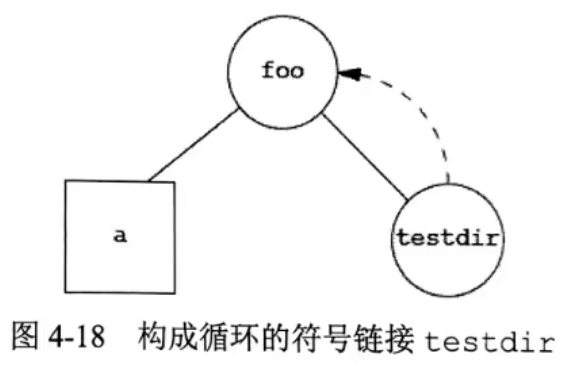
上面简介中提到每个区域固定大小,但是实际上用启发式算法进行搜索的时候,每次选择的锚框大小是不同的,将不同大小的锚框变成一个统一形状的算法就是Rol pooling;
💁♂ Rol pooling,也称感兴趣域池化层,作用是将大小不一的锚框统一形状。
📘 原理:
给定一个锚框,先将其均匀地分割成 n * m 块,然后输出每块里的最大值,这样的话,不管锚框有多大,只要给定了 n 和 m 的值,总是输出 nm 个值,达到统一形状的作用。

缺点:虽然有效提取了特征,但是速度非常慢,因为在第二个步骤用训练好的模型对每个锚框进行特征提取的时候,计算非常大(因为启发式算法大约生成2000个框)。
Fast R-CNN
🐤R-CNN:
- 对每个锚框分别进行特征提取;
- R-CNN是前向传播的,而且比如说对一张图片划分了2000张锚框,那么在进行特征提取的时候通常会有重叠部分,故导致了从重复计算。Fast R-CNN就是解决这个问题的;
🥅 Fast R-CNN网络图:

🚂 原理简介,与R-CNN对比着看:
-
首先由两进行两部计算,分别是锚框生成、图片特征提取,对应着上图中两条分支:
-
锚框生成:和R-CNN一样;
-
特征提取(CNN):对于一张图片,首先使用CNN对整张图片进行特征提取;
-
-
Rol pooling这里有两步:
- 1️⃣映射:锚框(selective search)按照一定比例映射到特征提取(CNN)的输出上;
- 2️⃣ Rol pooing:这一步和R-CNN一样,统一锚框大小。
-
之后采用一个全连接层进行分类(R-CNN用的是SVM),输出类别。
🚅比R-CNN快的原因:最核心的原因就是只需要对整体图片进行一次特征提取就行了,不需要分别对每个锚框进行特征提取。
Faster R-CNN
这个算法的改进是提出来RPN(区域建议网络)来代替selective search;

🔖 RPN简介:
这个网络学习的时候理解起来还是有难度的😢
🎡 作用:生成大量很差的锚框,然后进行预测,最终输出比较好的锚框供后面网络使用(预测效果好的会进入Rol Pooing);
😿 原理简介:
-
CNN特征提取后,再次运用一次卷积操作,然后用启发式算法搜索来初始化锚框;
-
然后判断锚框是否包含物体,这里分为两步:
- 1️⃣ 分类:RPN对每个锚框进行分类,判断他是否包含目标物体,这里输出的是一个概率值;
- 2️⃣ 回归:调整锚框位置和大小;
-
最后采用NMS对锚框进行筛选。
🉐 特点:精度高,但是计算量巨大,慢。
Mask R-CNN
这个算法是对Faster R-CNN基础上修改而来,他的作用是:解决传统目标检测,即只输出边界框无法提供像素级分割信息的问题。
像素级分割:生成每个物体的精确轮廓掩码.

从图像看的话,对比Fast R-CNN,有两个不同:
- 用Rol align代替Rol pooling;
- 在Rol align上新增一个分支;
这个难度我学的时候也很蒙,感觉好难😢
在学这个网络前,先学一下什么叫做二值掩码:
- 二值掩码是一种由0和1(或255)组成的二值图像,用于标记原始图像中需要关注或操作的区域。上图的右下部分图。
🔬 难度大,梳理一下网络:
- 特征提取
- 输入图像通过卷积神经网络生成特征图。
- 区域建议网络(RPN)
- 在特征图上生成锚框,通过分类和回归生成候选区域,这部分和Fast R-CNN一样。
- RoI Align
- 将候选区域映射到特征图上,使用双线性插值提取固定大小的特征(如 7×77×7 或 14×1414×14),与Rol pooling不同的是映射算法不同。
- 分类与回归分支
- 对每个 RoI 进行分类和边界框修正,这部分和Fast R-CNN一样。
- 掩码分支
- 对每个 RoI 生成二值掩码,最终通过阈值化得到像素级分割结果,先理解为对不同物体分别进行不同颜色可视化即可😭,由于是像素级别的,故大概轮廓也能显示出来。
- 全连接层
- 进行图片分类。
2、one-stage
单发多宽检测(SSD)
👀 先看网络结构:

初看网络结构,可以观察到他也是前向传播的,而且在传播的时候一直进行预测。
👀再看

👓 特点:
-
对给定的锚框直接进行预测,不需要进行两个阶段,这也是为什么比Faster R-CNN快的原因;
-
SSD 通过做不同分辨率下的预测来提升最终的效果,越到底层的 feature map,就越大,越往上,feature map 越少,因此底层更加有利于小物体的检测,而上层更有利于大物体的检测)
😢 缺点:
- 速度快,但是精度不好。
YOLO
➿ 用最多的模型。

📚 解释:
-
尽量让锚框不重叠—–》将图片均匀分成S X S个锚框。
-
每个锚框预测B个边缘框,这个意思是一个锚框可能有多个物体,故在他身边预测多个锚框进行特征提取、分类,如上图中的蓝色圆圈。
YOLO有很多版本,也非常值得学习的。
3、参考资料
- 【44 物体检测算法:R-CNN,SSD,YOLO【动手学深度学习v2】】https://www.bilibili.com/video/BV1Db4y1C71g?vd_source=1fd424333dd77a7d3e2e741f7d6fd4ee
- R-CNN_百度百科
- 李沐动手学深度学习V2-目标检测SSD_深度学习与目标检测 第2版第二版-CSDN博客