目录
1、磁盘和内存
1.1、概念
1.2、区别
1.3、联系
2、redis基本特性
2.1、数据结构
2.2、性能
2.3、事件驱动架构
2.4、原子性
3、redis模型
3.1、单线程
3.2、事件驱动模型
3.3、epoll多路复用
4、数据持久化
4.1、RDB快照
4.2、AOF(Append Only File)
4.3、设置
5、主从复制与分片
6、功能
6.1、事务和发布/订阅
前言
在介绍redis的时候,先介绍下存储介质,磁盘和内存。通过对以下两种认识,对了解redis有着更深的理解。如下图所示:
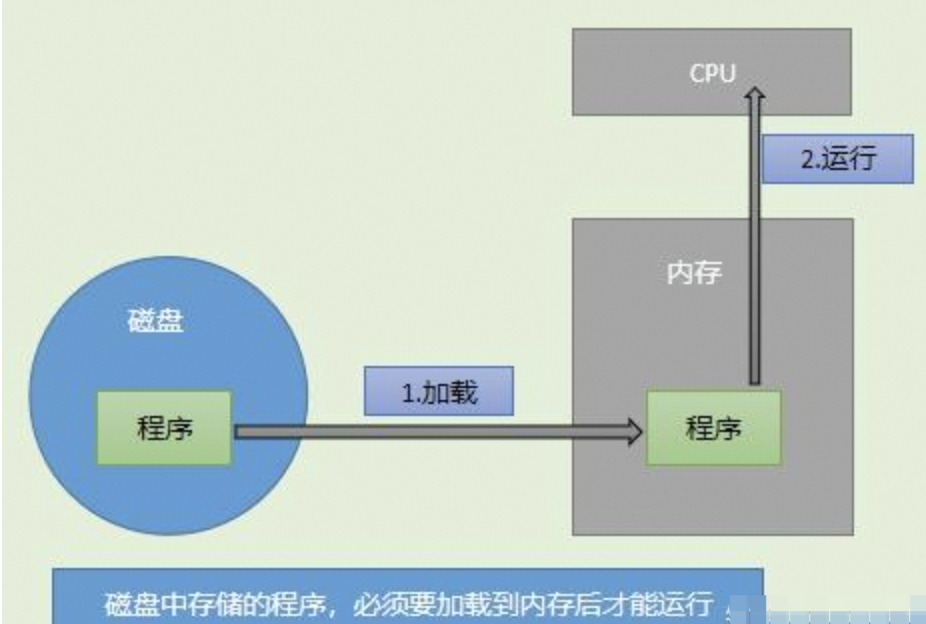
以上就是磁盘和内存的交互场景。
1、磁盘和内存
磁盘和内存是计算机系统中的两种主要存储介质,各自有不同的功能、特点和用途,同时它们之间也存在一定的联系。
下面详细论述它们的区别和联系。
1.1、概念
-
内存(RAM,随机存取存储器):
- 内存是一种高速度的临时存储设备,用于存储正在被 CPU 使用的数据和指令。
- 数据在内存中读取和写入速度非常快,但内存是易失性的,意味着一旦电源关闭,内存中的数据将丢失。
- 常见内存类型包括 DRAM(动态随机存取存储器)和 SRAM(静态随机存取存储器),使用时通常会有较低的延迟。
-
磁盘(硬盘驱动器,HDD,或固态硬盘,SSD):
- 磁盘是一种非易失性存储设备,用于长期存储数据,即使在电源关闭的情况下,数据也不会丢失。
- 磁盘的读取和写入速度通常比内存慢,尤其是传统的机械硬盘(HDD)。
- SSD 是一种相对较新的存储介质,使用闪存技术,访问速度比 HDD 快,但仍然比内存慢。
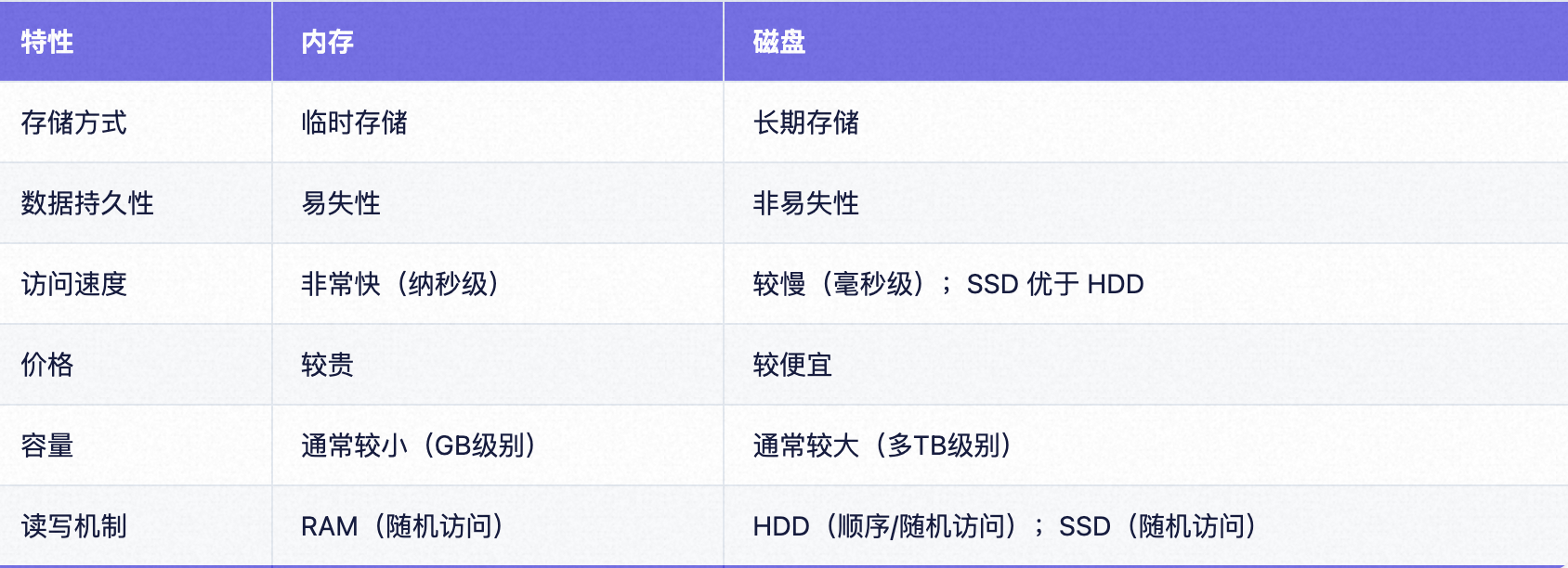
1.2、区别
1.3、联系
-
数据的转移:
- 当计算机启动时,操作系统和应用程序被加载到内存中,这样 CPU 就可以快速访问它们。此过程涉及从磁盘读取数据并将其写入内存。
- 应用程序的运行过程中,如果需要持久性数据的更改(如文件保存、数据库修改等),这些通常会被先修改在内存中,然后再写回磁盘。
-
存储层次结构:
- 在计算机系统中,内存作为缓存加速了对数据的访问,而磁盘则作为较低层级的永久存储。系统会根据访问频率和需要持久化的数据,自动在内存和磁盘间进行数据迁移。
- 日常数据的临时处理和计算推都在内存中完成,然后将最终结果持久化到磁盘。
-
I/O 操作:
- I/O 操作涉及读取或写入数据,是内存和磁盘之间的交互。磁盘的 I/O 操作通常较慢,因此操作系统会通过缓存来减少磁盘 I/O 频率,尽可能多地利用内存。
-
减少瓶颈:
- 数据库、文件系统等高性能应用常常会利用内存缓存技术,以提升对数据的处理速度,减轻磁盘的负担。例如,Redis、Memcached 等内存数据库可以快速处理并存储经常访问的数据,从而改善整体性能。
总结
内存与磁盘在数据存储和处理上扮演着互补的角色。内存提供了快速的访问速度,适合临时处理数据,而磁盘则提供持久化存储,适合长期存储数据。
在设计系统时,理解这两者之间的区别与联系对于提升系统性能、优化存储架构是非常重要的。
2、redis基本特性
所有数据均存储在内存中,提供快速的读写性能。虽然 Redis 主要作为内存数据库,但它也支持数据的持久化。
2.1、数据结构
-
Redis 主要支持以下数据结构:
- 字符串(String):最基本的数据结构,可以存储文本、数字、二进制数据等。
- 哈希(Hash):键值对的集合,适合于存储对象类型数据。
- 列表(List):双向链表,可以存储有序的字符串序列,支持按索引访问。
- 集合(Set):无序的字符串集合,不允许重复元素,支持集合运算。
- 有序集合(Sorted Set):集合中的每个元素都有一个分数,按分数排序,自动支持排名。
- 位图(Bitmap):可以通过位操作支持大规模的统计问题。
- 超日志(HyperLogLog):用于统计唯一元素的近似数,消耗极少的内存。
2.2、性能
本质上是一个Key-Value类型的内存数据库,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。
因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。
Redis最大的魅力是支持保存多种数据结构,此外单个value的最大限制是1GB。
2.3、事件驱动架构
1.单线程模型:
Redis使用单线程事件驱动模型来处理请求,避免了上下文切换的问题。这种设计使得它可以非常高效地处理并发请求。
2.IO多路复用:
Redis使用IO多路复用机制(如epoll),有效地处理大量并发连接。
关于redis为什么要使用单线程。不应该多线程快吗?
有以下几点原因:
1. 避免上下文切换
多线程模型中,线程间的上下文切换会带来额外的开销。这种切换不仅需要保存和恢复线程的状态,还涉及到 CPU 缓存的失效。对于 Redis 这样的高性能数据存储,避免不必要的上下文切换能够显著降低延迟。
2. 简单性和一致性
多个线程需要实现复杂的线程同步机制(如锁)。在 Redis 中,所有操作都是原子的,因为每个客户端的请求被依次处理。这种设计减少了数据竞争的风险,避免了由于多线程导致的一致性问题。
3. CPU的I/O瓶颈
Redis 的主要工作是处理内存中的数据,通常 I/O 操作(例如网络请求)是性能瓶颈而不是计算资源。因此,单线程模型可以有效地处理大量的 I/O 操作,而不会因为线程的过度创建和调度增加额外的开销。
4. 高并发处理
通过使用 I/O 多路复用(如 epoll),Redis 可以在单个线程内同时处理多个客户端的请求。当一个请求在等待 I/O 时(例如,网络延迟),线程可以去处理其他请求,这使得 Redis 能够高效地处理并发连接。
5. 内存访问模式
Redis 使用内存存储数据,对于内存访问来说,单线程可以保证 CPU 处理速度很快且没有额外的竞争。所有操作都在内存中完成,因此不需要多线程来提高并行性。
6. 应对多个 CPU 核心
虽然 Redis 是单线程,但你可以使用多个 Redis 实例(每个实例在不同的 CPU 核心上运行),或者使用 Redis 集群和分片,来同时处理更多的请求。这种横向扩展可以充分利用多核 CPU 的优势。
7、lua脚本
还支持使用 Lua 脚本来执行原子操作,允许将多个命令合并为单个操作,减少网络延迟和命令执行的时间,提高整体性能。
2.4、原子性
在 Redis 中,单个命令是原子的,但多个命令在并发情况下并不自动保证整体原子性。
要确保多个命令的原子性,可以使用事务(
MULTI和EXEC)或 Lua 脚本(EVAL)来组合它们,这样可以避免由于并发导致的竞态条件和数据不一致性。
1.简单的命令模型
- Redis 提供了一组简单的命令来操作数据,每个命令通常都是原子的。这些命令要么成功执行,要么失败,不会出现部分成功的情况。
当两个客户端同时尝试设置同一个键的值:
# 客户端 1
SET mykey "value1"
# 客户端 2
SET mykey "value2"
由于 Redis 是单线程的,以上两个命令会被顺序执行。假设客户端 1 先请求,后发生的客户端 2 的请求不会影响客户端 1 的请求。最终 mykey 的值会是 "value2" 或 "value1",但不会出现中间状态。
2. 数据结构的设计
- Redis 提供的数据结构(如字符串、哈希、列表、集合等)在操作时都是原子的。例如,
SET操作在成功执行时,会立即对指定键进行更新,而不会出现未更新的状态。
对哈希字段执行 HSET 操作:
HSET myhash field1 "value1"
该操作是原子的,要么成功设置 field1 的值为 "value1",要么不做任何改变。这允许多个客户端可以安全地进行读写操作,而不会出现数据的不一致情况。
3. 支持事务
- Redis 中还有一个事务机制,通过使用
MULTI、EXEC和WATCH命令,可以将多个操作组合在一起形成一个事务,redis中的事务不可被回滚。 - 在事务执行时,Redis 会保证这些命令的原子性:
- MULTI 命令开始一个事务,命令会被排队。
- EXEC 命令提交事务,所有被队列的命令会被原子地执行。
- 如果在事务执行期间任何命令失败,整个事务会被视为失败。
一个简单的事务示例:
MULTI
SET mykey "value"
INCR mycounter
EXEC
在执行 EXEC 命令之前,所有的命令都会被排队。当 EXEC 被调用时,所有这些命令会作为一个原子操作执行。如果在这个过程中有任何命令失败,整个事务将被视为失败,并且不会修改任何数据。
4. Lua 脚本
- Redis 允许客户端使用 Lua 脚本执行一系列命令,脚本的执行也是原子的。在调用
EVAL命令时,整个 Lua 脚本是原子执行的,其他命令不会干扰该脚本的执行,这样可以确保脚本内的多条命令以一致的状态顺序执行。
5. 数据一致性
- Redis 在设计上确保了数据的一致性,对于同一键的赋值和操作都是不可分割的。例如,一个
INCR命令会确保该键的值在执行期间不被其他命令改变。
使用 INCR 命令自增一个键的值:
INCR mycounter
如果 mycounter 初始值是 0,那么执行后它将变为 1。整个过程是原子的:即使有其他操作同时发生,INCR 命令的结果不会受到其他命令的干扰。
通过以上多个机制,Redis 能够确保其操作的原子性。单线程模型、简单命令模型和事务机制共同作用,使得 Redis 成为一个高效且易于理解的解决方案,适合在需要高性能和一致性的数据存储场景中使用。
3、redis模型
3.1、单线程
避免并发冲突:Redis 使用单线程事件驱动的模型来处理所有客户端的请求。这意味着在任何时候,只会有一个请求在被处理。由于不存在并发操作,Redis 能够保证命令的执行是原子的。
顺序执行:所有请求都被依次放入队列中处理,这样一来,某个请求的执行不会被其他请求的执行打断。
使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
因此redis的单线程速度比较快。
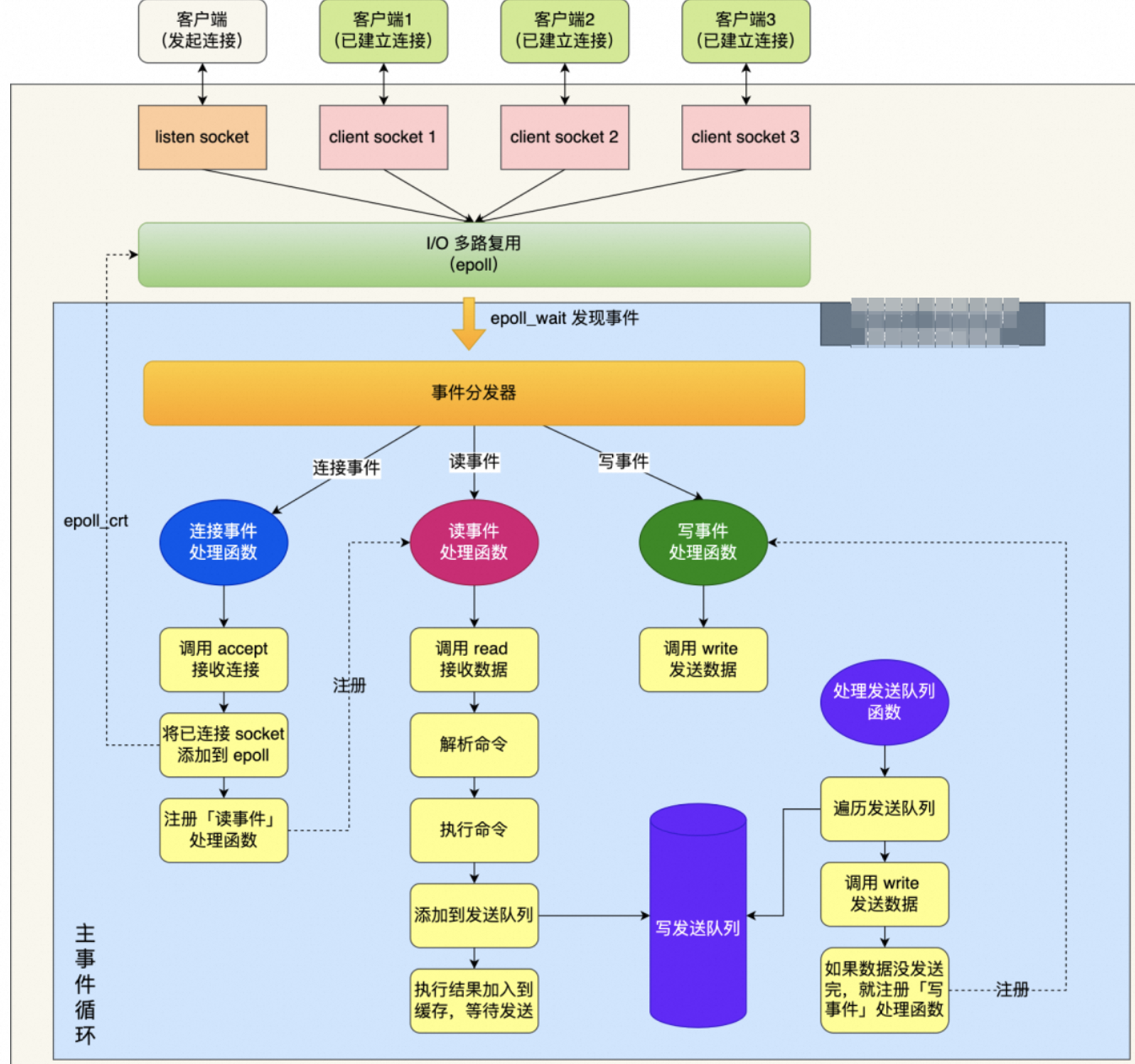
3.2、事件驱动模型
Redis 使用了事件驱动模型,特别是 I/O 多路复用(如
epoll、select、poll三种类型)来处理客户端的连接和请求。这意味着 Redis 可以同时处理多个连接,而不需要为每个连接创建一个新的线程。
当客户端在等待 I/O 操作时(如网络延迟),Redis 的事件循环可以有效地分配 CPU 时间来处理其他请求。
由下图可知模型的结构图:
3.3、epoll多路复用
epoll是 Linux 特有的 I/O 多路复用机制,比前两者(poll、select)更加高效。它使用事件驱动的方式,提供高效的通知机制,允许一次性注册多个文件描述符,并在文件描述符状态变化时进行通知。
先进行一下文件描述符和事件描述符的介绍:
事件描述符(File Descriptor)
事件描述符 通常是指在操作系统中用来表示打开的文件、网络连接或其他 I/O 资源的非负整数。简单来说,它是一个用于标识 I/O 资源的句柄,程序可以通过这个描述符进行读���等操作。
1. 基本概念
- 文件描述符:在 Unix/Linux 操作系统中,文件描述符是一个整数,指向进程打开的文件、套接字或其他 I/O 资源。每个打开的资源都有一个唯一的文件描述符,通常从 0 开始递增。
- 标准输入:文件描述符 0
- 标准输出:文件描述符 1
- 标准错误:文件描述符 2
2. 用途
在事件驱动的网络编程中,程序会对多个事件描述符进行监听,以便在这些资源变得可读、可写或有错误时得到通知。
以下是事件描述符在 I/O 多路复用中使用的典型流程:
-
创建描述符:当程序创建一个网络连接(例如,使用
socket()函数)或打开一个文件(使用open()函数)时,会返回一个文件描述符。 -
注册描述符:在使用 I/O 多路复用(如
select()、poll()、epoll())时,可以将这些文件描述符注册到相应的多路复用器中。注册后,程序可以监视这些描述符以检测 I/O 事件。 -
监视事件:主线程进入事件循环,其中轮询(或等待)已注册的描述符,检查它们的状态。每当某个描述符发生变化(例如有数据可读、连接已关闭等),主线程就会被通知。
-
处理事件:主程序根据活动的描述符来执行相应的读/写操作。
结合上面事件描述符和文件描述符的理解,可以得出事件处理流程如下:
-
连接建立:
- Redis 在启动时会创建一个主线程,并在此线程中运行事件循环。
- 当一个客户端连接到 Redis 时,会将其文件描述符注册到 I/O 多路复用器中。
-
事件循环:
- Redis 进入事件循环,使用所选的 I/O 多路复用机制(如
epoll)。 - 在循环中,Redis 监视所有注册的文件描述符,等待 I/O 事件(如读取数据或连接关闭)的发生。
- Redis 进入事件循环,使用所选的 I/O 多路复用机制(如
-
事件处理:
- 当某个文件描述符准备好进行读或写操作时,Redis 将处理该事件。
- Redis 从连接中读取请求,处理命令,并将响应发送回客户端。
-
响应处理:
- 一旦事件被处理,Redis 将返回到事件循环,继续处理其他尚未完成的请求。
4、数据持久化
默认情况下:默认持久化是rdb,aof的值需要去设置为yes。
RDB(快照持久化)和 AOF(追加文件持久化)都是用于持久化数据到磁盘的方式。
4.1、RDB快照
Redis可以周期性地将数据快照保存在磁盘上,以便在重启时恢复。
RDB 通过将 Redis 当前的内存状态序列化为二进制格式的快照文件,并将其存储到磁盘中。RDB 文件通常命名为
dump.rdb,可以在 Redis 的工作目录中找到。
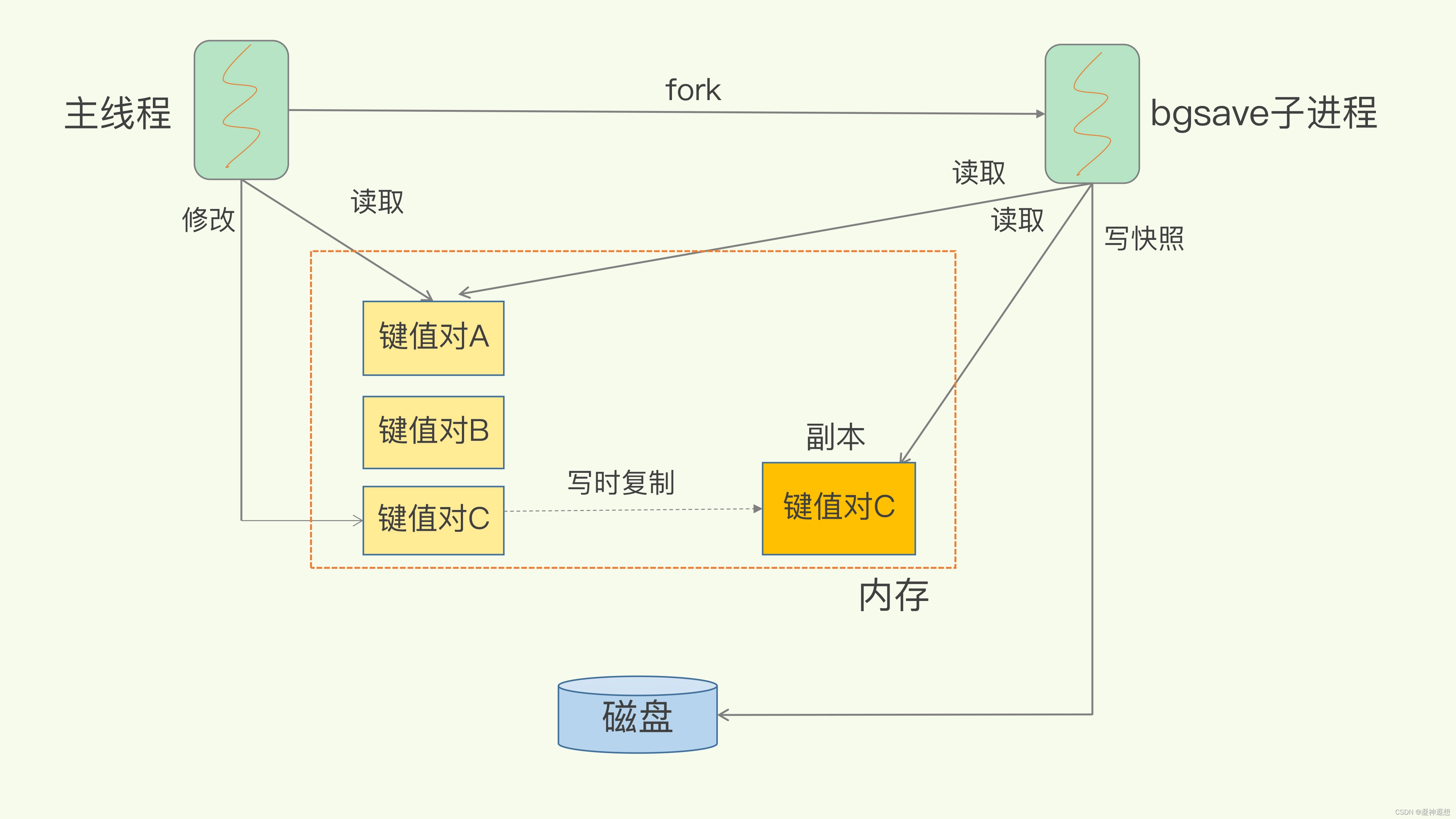
1.创建快照的过程
-
阻塞写操作:
- 在执行
SAVE命令时,Redis 会阻塞写请求,直到快照完成。 - 使用
BGSAVE命令则允许 Redis 在后台创建快照,不影响其他命令的执行。
- 在执行
-
快照生成:
当条件满足时,Redis 按以下步骤生成快照:- 子进程在创建快照时,会将内存中的所有数据序列化,这个数据会被写入到一个临时的 RDB 文件中。
- 父进程继续服务于客户端请求。
- Redis 会 fork(分叉)出一个子进程。这个子进程会负责创建快照,以避免阻塞主进程,保持 Redis 的高并发性能。
-
写入磁盘:
- 一旦快照生成完成,子进程会将临时生成的 RDB 文件重命名为
dump.rdb,覆盖旧的快照文件。 - 这通常是一个原子操作,以确保不会出现文件损坏的风险。
- 一旦快照生成完成,子进程会将临时生成的 RDB 文件重命名为
2. 使用 RDB 文件进行数据恢复
当 Redis 重启时,它会检查是否存在有效的 RDB 文件:
- 加载 RDB 文件:
- 如果
dump.rdb文件存在且有效,Redis 会读取该文件,将数据反序列化并恢复到内存中。 - 这一过程是及时的,能够迅速恢复到最后一次持久化时的状态。
- 如果
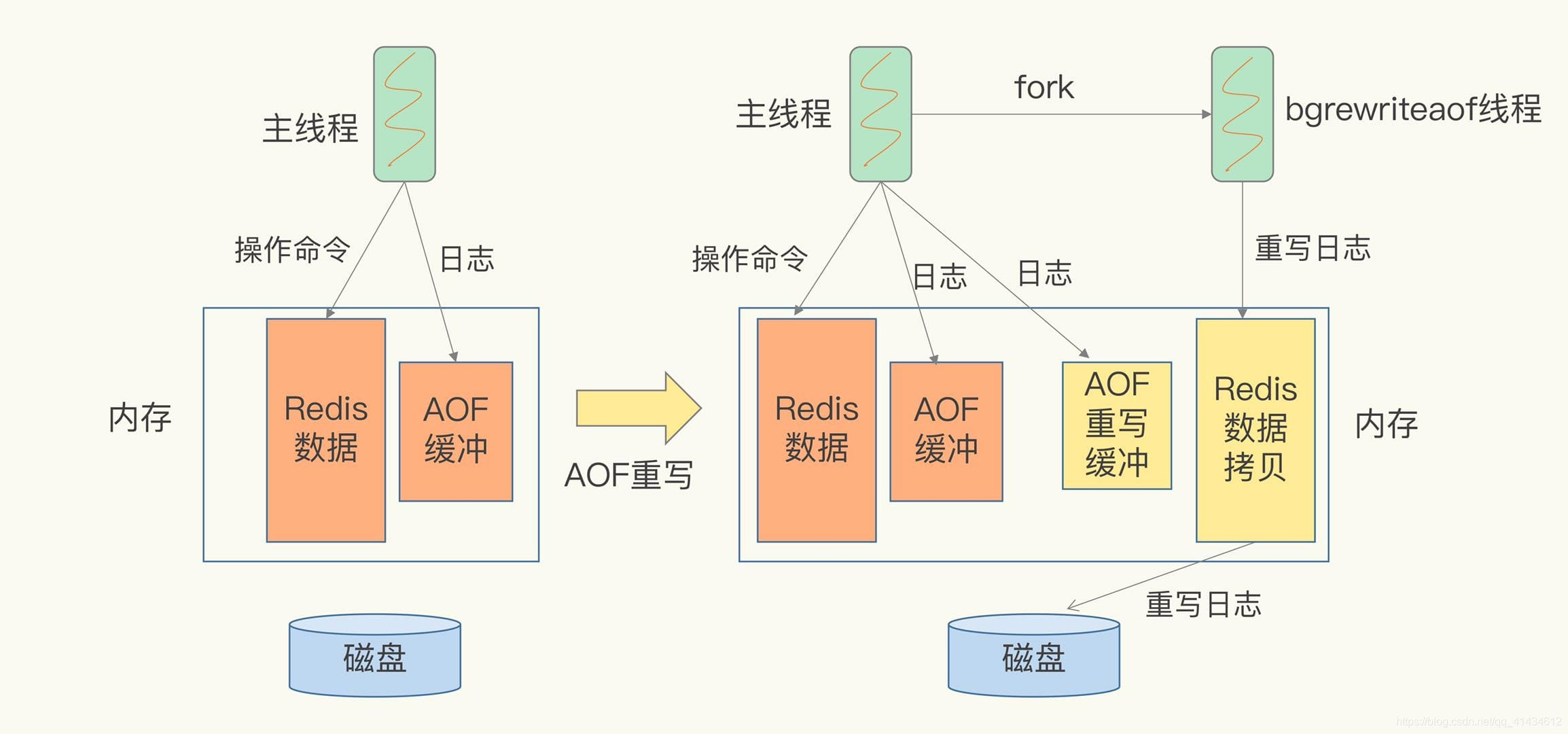
4.2、AOF(Append Only File)
当开启 AOF 持久化时,Redis 会将每个写操作以“追加”的方式写入 AOF 文件。AOF 文件以一种简单的文本格式存储所有写命令,以便可以在重启时重放这些命令来恢复数据。
1.重写的过程
启动 Redis
-
检查 AOF 文件:
- Redis 启动时会查看 AOF 文件(通常命名为
appendonly.aof)。如果文件存在且完整(未损坏),Redis 将尝试从中恢复数据。
- Redis 启动时会查看 AOF 文件(通常命名为
-
读取命令:
- Redis 会逐行读取 AOF 文件中的所有命令。AOF 文件中的每条记录都是一个之前执行的写操作。
-
执行命令:
- Redis 按照 AOF 文件的顺序逐条重放这些命令。在这个过程中,每个命令会更新 Redis 的内存状态,以确保所有数据最终与文件中的记录一致。
- 通过执行这些命令,Redis 完成数据的恢复。
-
恢复完成:
- 一旦所有命令被重放,Redis 将显示其内存状态与 AOF 文件内容一致,此时 Redis 就可以开始处理新的客户端请求。
2、文件回收
为了降低 AOF 文件的大小,Redis 会定期自动重写 AOF 文件。可以手动或根据策略设置:
auto-aof-rewrite-percentage 100 # 当 AOF 文件大小是上次重写后大小的 100% 时进行重写
auto-aof-rewrite-min-size 64mb # AOF 文件大小至少为 64MB 进行重写
4.3、设置
在 redis.conf 配置文件中,您可以找到以下选项:
# RDB 持久化
save 900 1 # 如果在900秒(15分钟)内至少有1个key发生变化
save 300 10 # 如果在300秒(5分钟)内至少有10个key发生变化
save 60 10000 # 如果在60秒内至少有10000个key发生变化
# AOF 持久化
appendonly no # 默认情况下是关闭的,要启用AOF需要将这个设置为 yes
#同步策略
appendfsync always # 每个写命令都同步,性能影响大,但数据安全高
appendfsync everysec # 每秒同步一次,性能与安全的折中
appendfsync no # 不进行同步,最高性能,最低数据安全
appendfsync everysec # 每秒同步到磁盘
当然也可以手动rdb进行。
SAVE # 阻塞当前 Redis 实例,直到快照完成
BGSAVE # 在后台异步创建快照,允许继续处理其他请求
不同版本的持久化可能不同。
可以同时开启两种持久化方式,在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
5、主从复制与分片
- 主从复制:Redis支持主从复制,可以将数据从主节点同步到多个从节点,提高读取性能。
- 分片:可以将数据分布到多个Redis实例中,以水平扩展存储和处理能力。
6、功能
6.1、事务和发布/订阅
- 事务支持:Redis提供了简单的事务支持,允许将多个操作原子地执行。
- 发布/订阅模式:Redis支持发布/订阅功能,适合实时消息传递和通知。
6.2、 性能优化技巧
- 使用Lua脚本:通过使用Lua脚本,可以将多个Redis命令合并为一个原子操作,从而提高性能。
- 客户端持久连接:使用持久连接减少连接开销,尤其是在高并发场景下。
- 合理的键命名:使用简单且一致的键命名约定可以提高可维护性和操作效率。
7. 监控和调优
- 命令统计:使用
MONITOR命令查看实时请求,分析性能瓶颈。 - 内存使用分析:使用
INFO命令和其他工具(如Redis Desktop Manager或Redis Insight)监控和分析内存使用情况。 - Redis集群:在处理大量数据或高并发请求时,考虑使用Redis集群来分散负载和提高可用性。
8. 版本和更新
- 使用稳定版本:确保使用最新的稳定版本,以利用最新的性能改进和功能。
通过合理利用Redis的特性和优化策略,可以在需求高的应用中实现极高的性能。但重要的是要根据应用的具体情况进行测试和调整,以获得最佳的性能表现。
数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。



![[SSM]-Spring介绍](https://i-blog.csdnimg.cn/img_convert/058e34fb47c5328befb126cfd8155ec3.png)