文章目录
- 一、引言
- 二、全景架构回顾
- 三、潜在问题
- 问题1:Binlog 延迟——理想 vs 实际
- 问题2:Binlog 格式解析
- 问题3:高可靠消费
- 1. 串行 ACK 消费
- 2. 并行消费+乱序风险
- 3. 解决方案
- 问题4:缓存数据结构设计
- 1. Key–Value 冗余
- 2. Hash 结构局部更新
- 3. 组合方案
- 四、数据一致性校验与兜底
- 1. 定期对比
- 2. 主动写入兜底
- 五、总结

一、引言
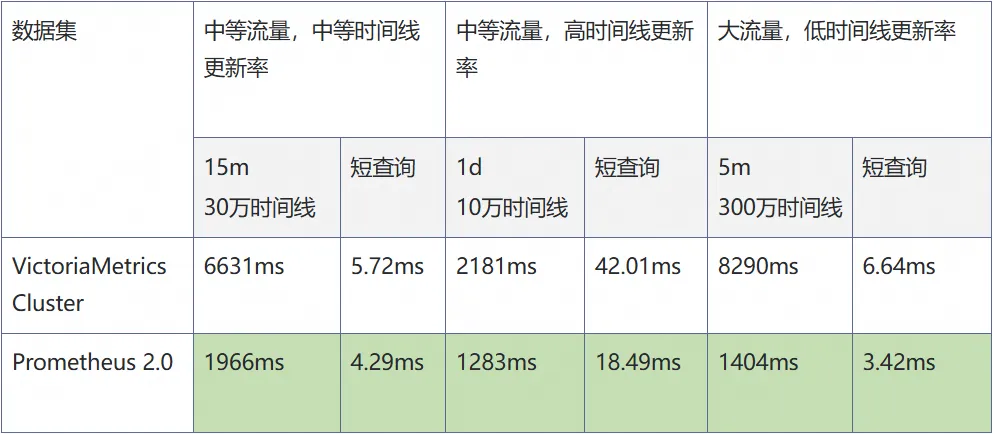
在架构思维:利用全量缓存架构构建毫秒级的读服务中,我们提出了基于 Binlog 的全量缓存读服务架构,能够满足百毫秒级平均延迟、实时性与最终一致性。
‘’但要将此方案落地,仍需攻克一系列细节难题:
- Binlog 真正的端到端延迟有多大?
- 如何解析和处理 Binlog 的多种格式?
- 在高并发和快速迭代下,如何保证消费链路零丢失、零乱序?
- 缓存中数据该如何设计,才能兼顾读写性能与业务灵活性?
接下来我们将一一拆解并给出最佳实践
二、全景架构回顾
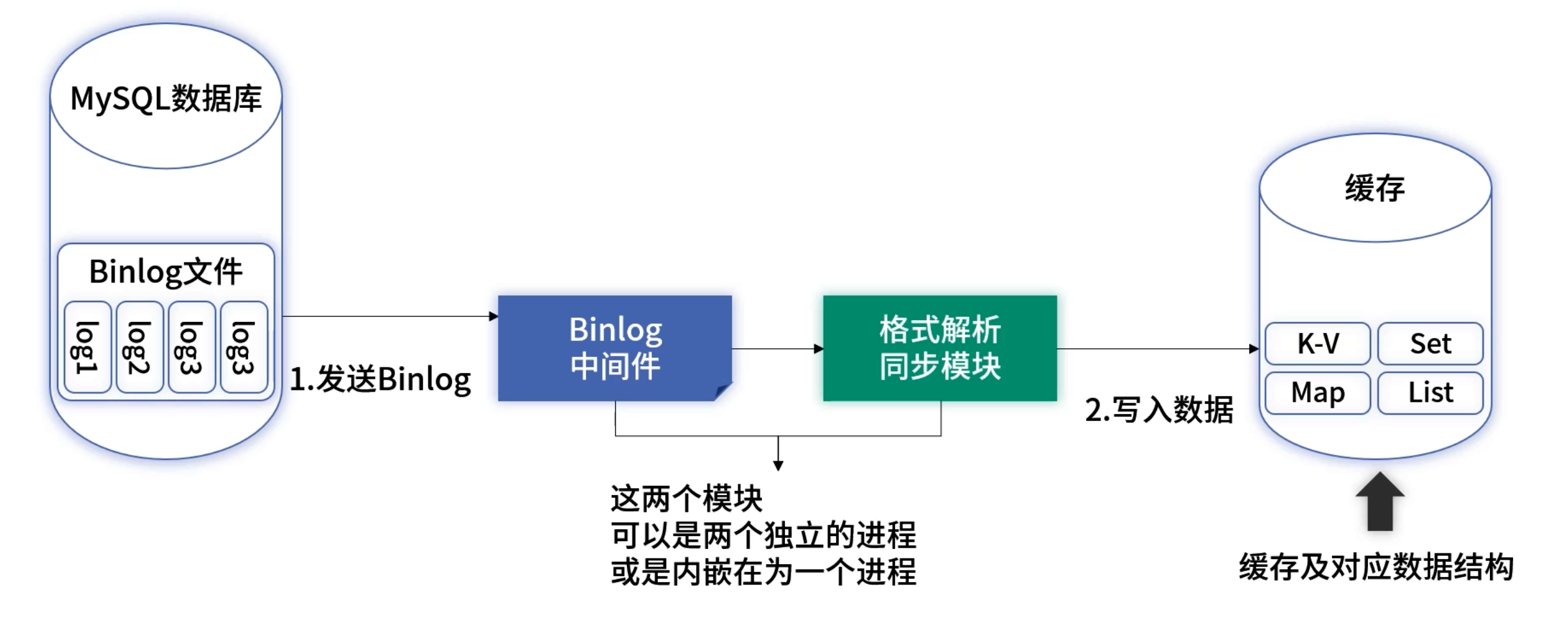
该架构核心组件:
- 主库写入 → 2. Binlog 生成 → 3. 订阅中间件(Canal/Maxwell 等) → 4. 消费 & 转码 → 5. 缓存写入 → 6. 读服务调用
我们将在此全景图基础上,聚焦四大问题并给出对策。
三、潜在问题
问题1:Binlog 延迟——理想 vs 实际
MySQL 主从同步延迟通常在毫秒级,但自研 Binlog 同步引入了:
- 协议转换:从 MySQL 协议到中间件协议,多了 CPU 与网络开销;
- 额外组件:多了中间件与消费服务,链路更长;
- 从库读取:为保护主库,一般从从库订阅 Binlog,增加一跳延迟;
- 串行吞吐瓶颈:Binlog 文件串行读写限制了吞吐。
优化思路
- 精简协议:保持中间件与 MySQL 协议兼容度,减少解析开销;
- 链路监控:端到端打点,定位各环节耗时;
- 并行读写(详见问题三)。
问题2:Binlog 格式解析
MySQL 支持三种格式:
-
statement:记录 SQL 文本,体积小,但需复杂 SQL 解析,易出错。
statement格式是把每次执行的 SQL 语句记录到 Binlog 文件里,在主从复制时,基于 Binlog 里的 SQL 语句进行回放来完成主从复制。比如执行了如下 SQL 成功后:update demo_table set status='无效' where id =1Binlog 中记录的便是上述这条具体的 SQL。采用 SQL 格式的 Binlog 的好处是内容太少,传输速度快。但存在一个问题,在基于 Binlog 进行数据同步时,需要解析上述的 SQL 获取变更的字段,存在一定的开发成本。
- row:记录行级前后镜像及变更字段,数据量大但解析简单。
{
"before":{
"id":1,
"message":"文本",
"status":"有效",
"created":"xxxx-xx-xx",
"modified":"xxxx-xx-xx"
},
"after":{
"id":1,
"message":"文本",
"status":"无效",
"created":"xxxx-xx-xx",
"modified":"xxxx-xx-xx"
},
"change_fields":["status"]
}
- mixed:自动在前两者间切换,兼顾性能与兼容。
推荐:使用 row 或 mixed
- row 模式解析逻辑最简单,无需 SQL 引擎;
- mixed 针对 DDL 保留 statement,节约空间。
问题3:高可靠消费
1. 串行 ACK 消费
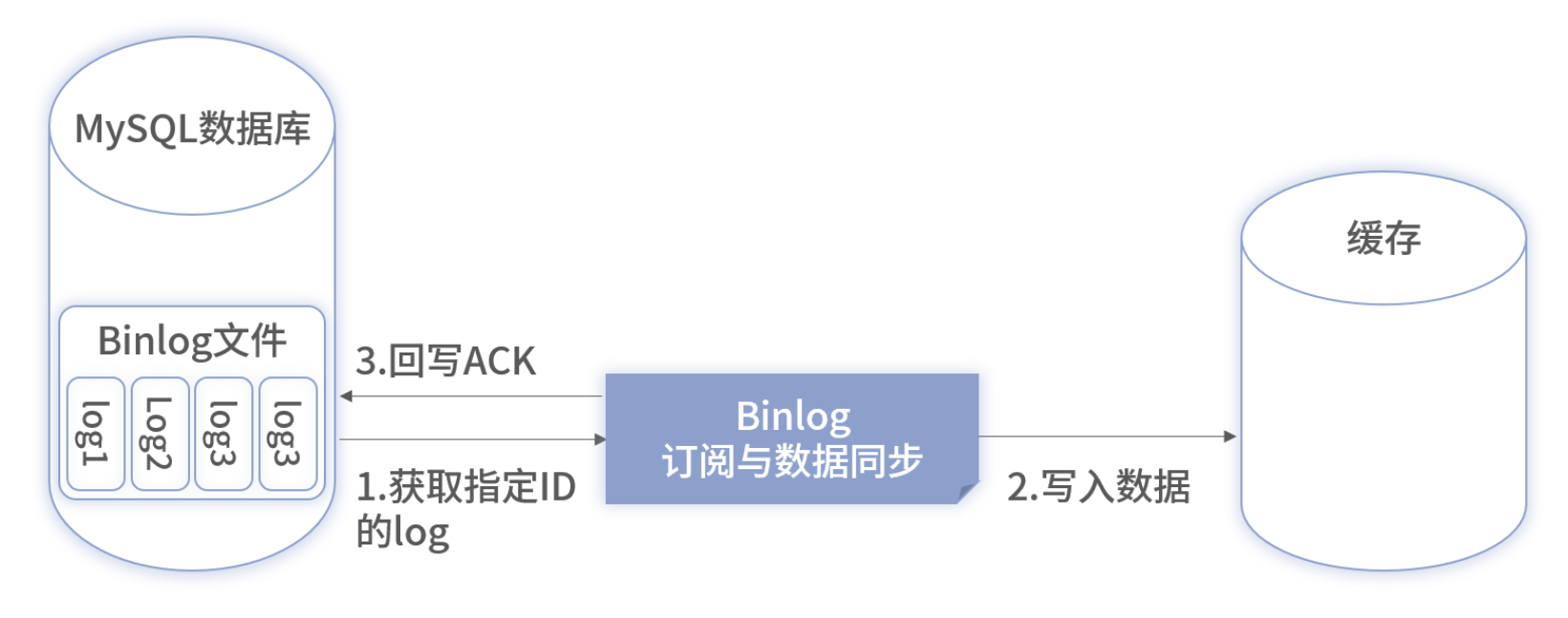
- 优点:天然有序、易保证一致性;
- 缺点:单线程瓶颈,延迟随数据量急剧上升。
2. 并行消费+乱序风险
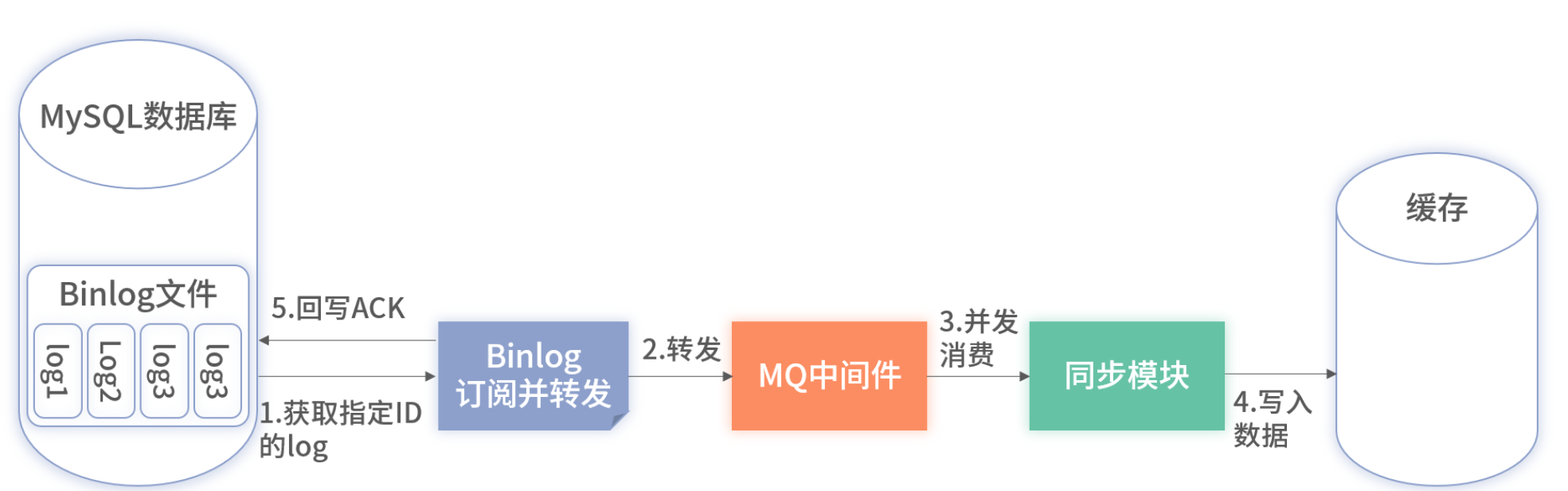
-
利用 MQ 拆分到多消费者组,提高吞吐;
借用了 MQ 进行拆分。在 Binlog 处仍然进行串行消费,但只是 ACK 数据。ACK 后数据直接发送到 MQ 的某一个 Topic 里即可。因为只做 ACK 并转发至 MQ,不涉及业务逻辑,所以性能消耗非常小,大概只有几毫秒或纳秒
-
乱序会导致后写数据被覆盖。
3. 解决方案
- 分布式锁细粒度串行:按业务维度(如订单号)加锁,串行同一键写入;
- MQ 分区/串行通道:比如 Kafka Partition,将同一 key 的消息路由到同一分区,自然串行。
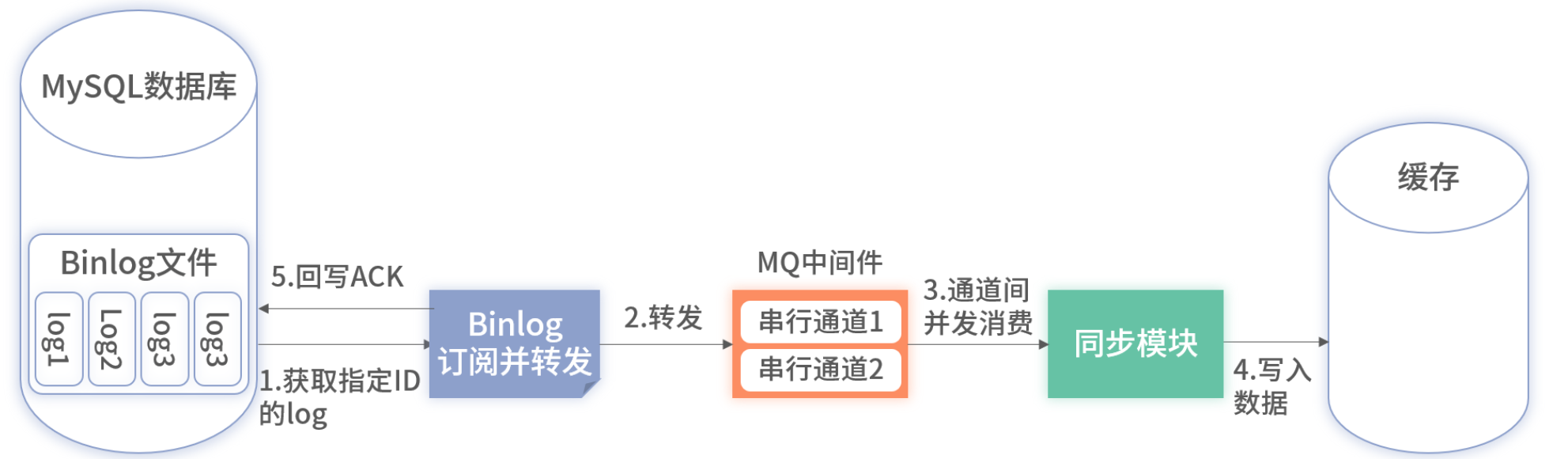
最终既保留高吞吐,又能保证单键顺序。
在采用了 MQ 进行纯串行转并行时,将 Binlog 发送到 MQ 可以根据情况进行调整,当数据量很大或者未来很大时,可以将 Binlog 的数据按表维度发送到不同的 Topic。一是能够实现扩展性;二是可以提升性能;三是通过不同表使用不同的 Topic,可以起到隔离的作用,减少表之间的相互影响
问题4:缓存数据结构设计
Redis 常见几种存储模式:
1. Key–Value 冗余
将多表数据合并序列化为一个大 JSON 存储,优点简单,缺点全量更新和查询开销大。
2. Hash 结构局部更新
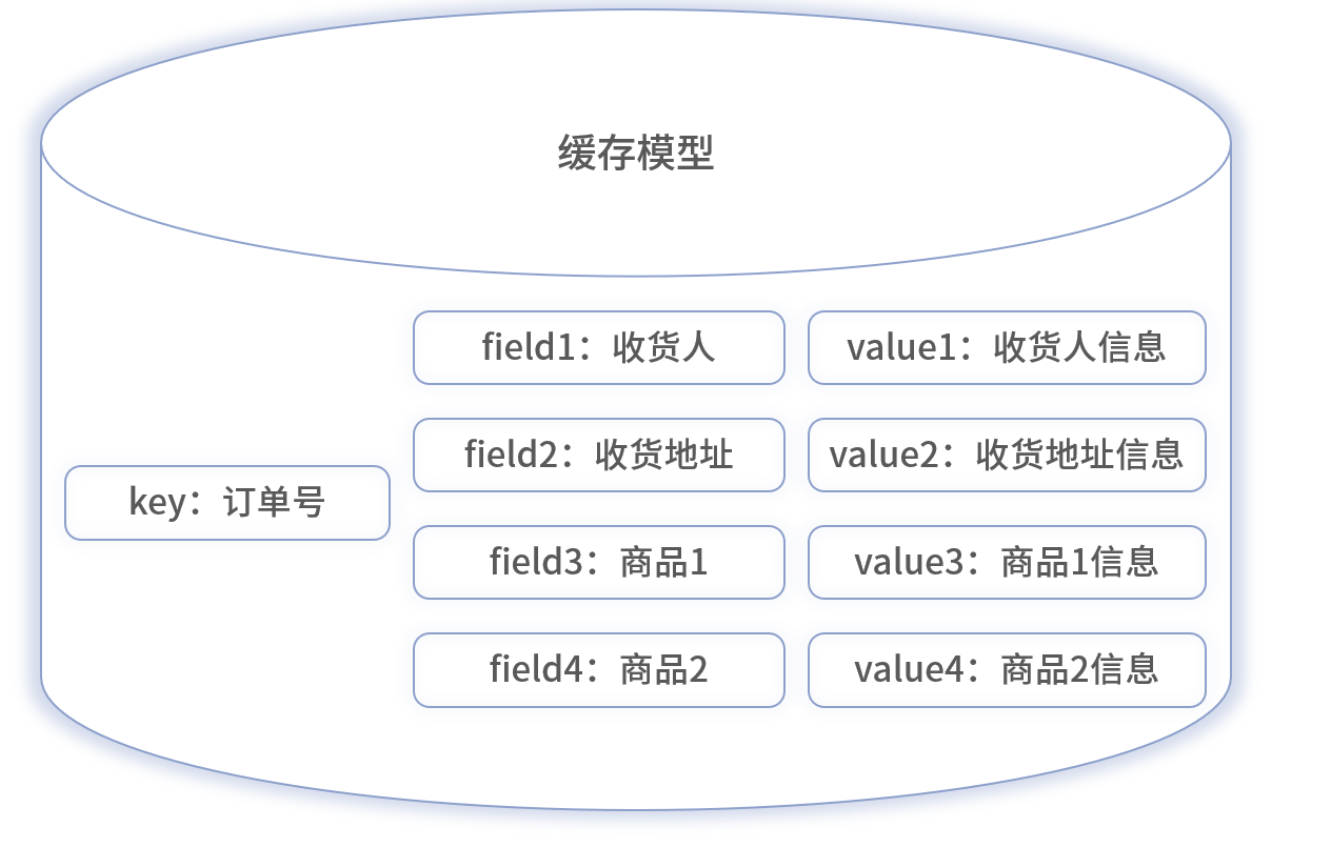
- 各业务实体字段映射到 Hash 的不同 field,可单字段更新;
- 保证同一 hash slot,避免跨分片查询;
3. 组合方案
- 反查全量覆盖:针对偶发大变更,消费端反查数据库,重建整个缓存对象;
- 分布式锁协调:多表变更时,对同一业务 ID 加锁,串行更新 Hash。
四、数据一致性校验与兜底
1. 定期对比
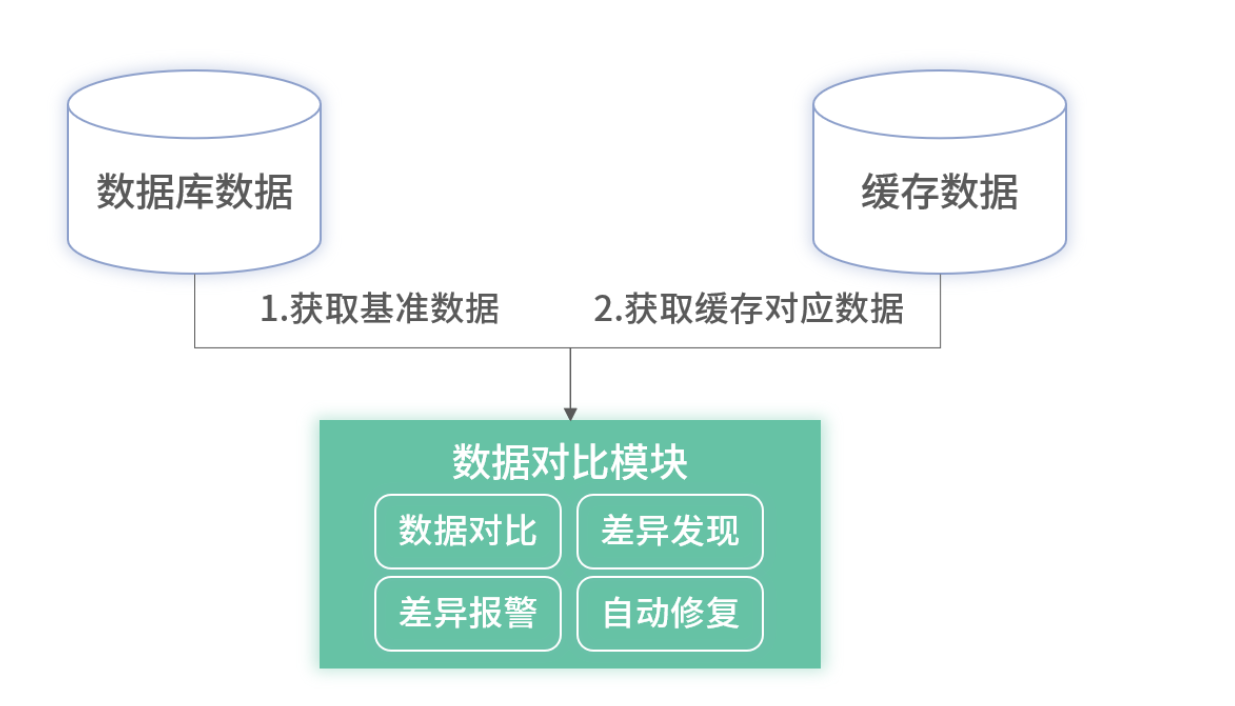
- 选用数据库从库作比对源,定时扫描与缓存做比对;
- 异常重试 + 告警 + 现场记录。
2. 主动写入兜底
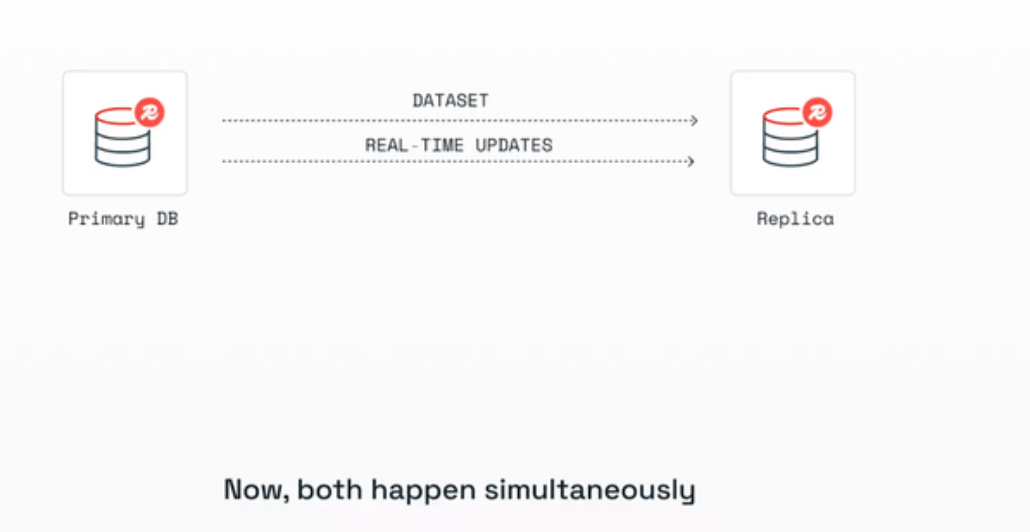
虽然上述在提升同步吞吐量上做了非常多地设计,但不可否认延迟总是存在的,即使是纯数据库主从同步间也会因为网络抖动和写入量大的情况出现毫秒或者秒级延迟,我们这里基于 Binlog 的改良方案自然不例外。
绝大部分的业务和场景,对于毫秒或秒级延迟无感知。但为了方案的完整性和极端场景的应对,可以在异步同步的基础上,增加主动同步。方案如下图所示:
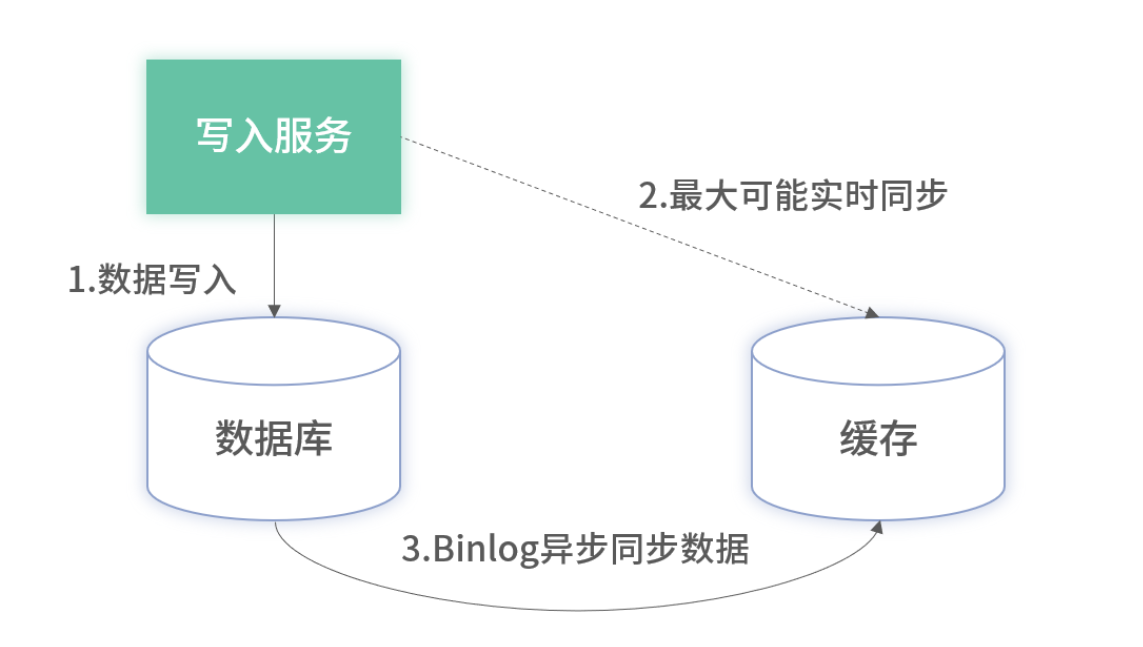
- 在关键写事务提交后,异步或同步写入缓存;
- 失败不回滚,由 Binlog 保底最终一致;
上述的架构是对一些关键场景在写完数据库后,主动将数据写入缓存中去。但对于写入缓存可能出现的失败可以不处理,因为主动写入是为了解决缓存延迟的问题,主动写入导致的丢失数据由 Binlog 保障最终一致性。此架构是一个技术互补的策略,Binlog 保证最终一致性但可能存在延迟,主动写入保障无延迟但存在丢数据。在架构中,也可以采用此思路。一个单项技术无法完美解决问题时,可以对短板寻找增量方案,而不是整个方案完全替换。
此「主动 + 被动」组合,兼顾实时性与可靠性。
五、总结
- 延迟——链路中的每一跳都要监控与优化;
- 格式——row/mixed 模式下解析最简单可靠;
- 消费——利用 MQ 分区或锁机制保证“高吞吐+强有序”;
- 结构——Hash 优于 KV,可局部更新、同分片;
- 一致性——数据对比与主动写入互补兜底。