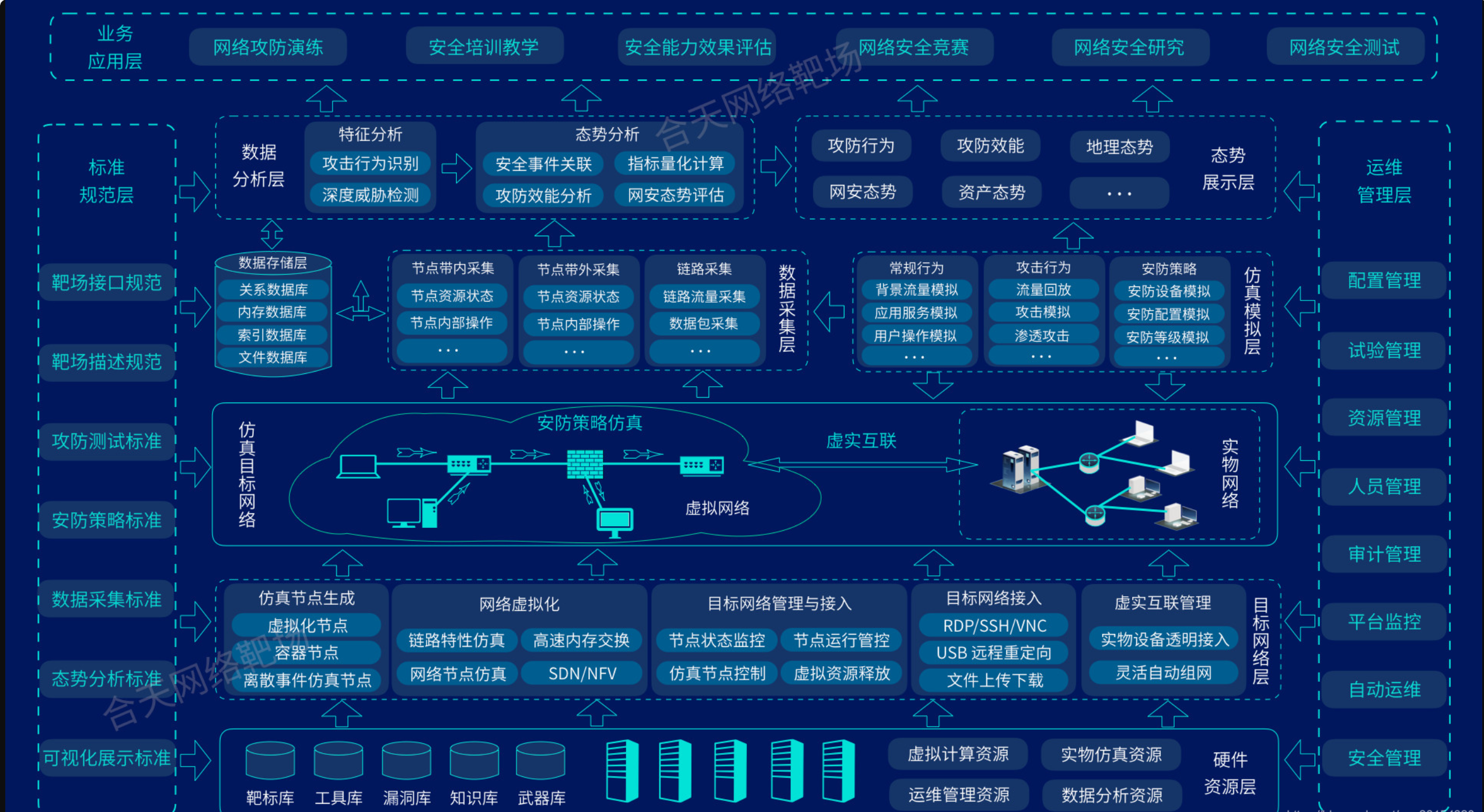
视频链接
numpy
numpy是基于一个矩阵的运算
矩阵的属性
import numpy as np
# 把一个列表转换成矩阵的方法
array = np.array([[1,2,3],[3,4,5]])
# 打印矩阵
print(array)
# 维度
print('number of dim:',array.ndim)
# 行数和列数
print('shape:',array.shape)
# 总共有多少个元素在里面
print('size:',array.size)
生成矩阵
import numpy as np
array = np.array([[1,2,3],[3,4,5]],dtype=np.int)
# 矩阵里的元素的数据类型
print(a.dtype)
# 生成一个0矩阵
a1 = np.zeros((3,4))
print(a)
# 生成一个全是1的矩阵
a2 = np.ones((1,4),dtpye=np.int16)
# 生成一个空矩阵
a3 = np.empty((3,4))
# 生成一个有序的矩阵
a4 = np.arange(10,20,2)
# 有序和矩阵形状结合
a5 = np.arange(12).reshape((3,4))
# 一个线段
a6 = np.linspace(1,10,6).reshape(2,3)
numpy的基础运算
import numpy as np
a1 = np.array([10,20,30,40])
b1 = np.arange(4)
# 减法
c1 = a1 - b1
print(c1)
# 加法
c2 = a1 - b1
print(c2)
# 乘法
c3 = a1 * b1
print(c3)
# 次方
c4 = a1**2
print(c4)
# 三角运算
# 注:这里的sin 可以换成cos,tan
c5 = 10*np.sin(a1)
print(c5)
# 列表中的大小关系
a2 = np.arange(1,5)
print(a2)
print(a2>3)
# [1 2 3 4]
# [False False False True]
# 乘法
a3 = np.array([[1,1],[0,1]])
b3 = np.arange(4).reshape((2,2))
c = a*b # 逐一相乘
c_dot = np.dot(a,b) # 矩阵乘法
c_dot_2 = a.dot(b) # 矩阵乘法的另外一种形式
print(c)
print(c_dot)
print(c_dot_2)
# [[0 1]
# [0 3]]
# [[2 4]
# [2 3]]
# 随机生成一些值
a = np.random.random(2,3)
print(a)
print(np.sum(a,axis=1))
print(np.min(a,axis=0))
print(np.max(a,axis=1))
# 注:axis=1 是在每一行中进行处理,最后返回是一个矩阵
# 注:axis=0 是在每一列中进行处理,最后返回是一个矩阵
# 注:axis 对矩阵的大多数指令都有用
numpy的基础运算2
import numpy as np
A = np.arange(2,14).reshape((3,4))
# 整个矩阵的最大值和最小值
print(np.argmin(A))
print(np.argmax(A))
#平均值
print(np.mean(A))
print(A.mean())
print(np.average(A))
# 求中位数
print(np.median(A))
# 求和
print(A)
print(np.cumsum(A))
print(np.diff(A)) # 累差
# [[ 2 3 4 5]
[ 6 7 8 9]
[10 11 12 13]]
#[ 2 5 9 14 20 27 35 44 54 65 77 90]
# 排序
print(np,.sort(A)) # 逐行排序
# 转置
print(A)
print(np.transpose(A))
print(A.T)
# 让所有小于5的数字变成5,让所有大于9的数字,变成9
print(np.clip(A,5,9))
np的索引
矩阵合并
有些不是很懂,先这样
A = np.array([1,1,1])
B = np.array([2,2,2])
# vertical stack 向下的合并
C1 = np.vstack((A,B))
print(A.shape,C.shape)
# horizontal 左右合并
C2 = np.hstack((A,B))
print(C2)
# 这里将A,B转了一个方向
A = A[:,np.newaxis]
B = B[:,np.newaxis]
# 多矩阵,可要求方向的合并
C3 = np.concatenate((A,B,B,A),axis=0)
分隔矩阵
import numpy as np
A = np.arange(12),reshape((3,4))
# 分隔
print(np.split(A,2,axis=1))
# 不等分隔
print(np.array_split(A,3,axis=1))
# 分隔
print(np.vsplit(A,3))
print(np.hsplit(A,2))
赋值和复制
import numpy as py
a = np.arrange(4)
b = a
c = a
d = b
a[0] = 11
print(b) # b 也会变,因为a和b,c,d都指向一个实体
# deep copy
b1 = a.copy()
Pandas
创建一个DataFrame
import pandas as pd
import numpy as np
# 创建pandas的一个序列
s = pd.Series([1,2,3,np.nan,44,1])
print(s)
0 1.0
1 2.0
2 3.0
3 NaN
4 44.0
5 1.0
dtype: float64
# 创建一个dataform
dates = pd.date_range('20250507',periods=6)
print(dates)
DatetimeIndex(['2025-05-07', '2025-05-08', '2025-05-09', '2025-05-10','2025-05-11', '2025-05-12'],
dtype='datetime64[ns]', freq='D')
df1 = pd.DataFrame(np.random.randn(6,4),index=dates,columns=['a','b','c','d'])
a b c d
2025-05-07 1.707762 1.067165 -0.030727 -0.501342
2025-05-08 -0.743115 -0.543604 0.591870 -1.422352
2025-05-09 0.418383 -1.863935 -1.131557 -0.529528
2025-05-10 1.242757 -0.054061 1.878575 1.810151
2025-05-11 -0.392040 -0.467716 -1.235588 0.007852
2025-05-12 -1.293517 0.573971 0.913581 -0.293789
# 默认状态下的DataFrame的(第一)横竖栏
df2 = pf.DataFrame(np.arange(12).reshape((3,4)))
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
# 用字典生成DataFrame
df3 = pd.DataFrame({
'A':1,
'B':pd.Timestamp('20252507'),
'C':pd.Series(1,index=list(range(4)),dtype='float32')
'D':np.array([3]*4,dtype='int32'),
'E':pd.Categorical(["test","train","test","train"]),
'F':'foo'
})
A B C D E F
0 1 2025-05-07 1.0 3 test foo
1 1 2025-05-07 1.0 3 train foo
2 1 2025-05-07 1.0 3 test foo
3 1 2025-05-07 1.0 3 train foo
DataFrame的属性
# 输出每一列的属性
print(df3.dtypes)
A int64
B datetime64[s]
C float32
D int32
E category
F object
dtype: object
# 输出所有行的名字
print(df2.index)
RangeIndex(start=0, stop=3, step=1)
# 输出所有的列的名字
print(df2.columns)
RangeIndex(start=0, stop=4, step=1)
# 输出所有的values
print(df2.values)
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
# 处理表中的一些数学运算
print(df2.describe())
0 1 2 3
count 3.0 3.0 3.0 3.0
mean 4.0 5.0 6.0 7.0
std 4.0 4.0 4.0 4.0
min 0.0 1.0 2.0 3.0
25% 2.0 3.0 4.0 5.0
50% 4.0 5.0 6.0 7.0
75% 6.0 7.0 8.0 9.0
max 8.0 9.0 10.0 11.0
# 转置
print(df2.T)
0 1 2
0 0 4 8
1 1 5 9
2 2 6 10
3 3 7 11
# 排序
print(df2.sort_index(axis=1,ascending=False))
>>> df2.sort_index(axis=1,ascending=False)
3 2 1 0
0 3 2 1 0
1 7 6 5 4
2 11 10 9 8
>>> df2
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
>>> df2.sort_index(axis=0,ascending=False)
0 1 2 3
2 8 9 10 11
1 4 5 6 7
0 0 1 2 3
>>> df2
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
# 排序value
print(df3.sort_values(by='E))
A B C D E F
0 1 2025-05-07 1.0 3 test foo
2 1 2025-05-07 1.0 3 test foo
1 1 2025-05-07 1.0 3 train foo
3 1 2025-05-07 1.0 3 train foo
选择数据
import pandas as pd
import numpy as np
dates = pd.date_range('20250507',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
# 直接索引(列)
print(df["A"])
print(df.A)
2025-05-07 0
2025-05-08 4
2025-05-09 8
2025-05-10 12
2025-05-11 16
2025-05-12 20
Freq: D, Name: A, dtype: int64
# 切片 (行)
print(df[0:3])
print(df['20250507':'202505010']) # 左闭右闭
A B C D
2025-05-07 0 1 2 3
2025-05-08 4 5 6 7
2025-05-09 8 9 10 11
# select by loc
# , 前面挑选行,‘,’后面挑选列
print(df.loc['20250507']) #打印一行
print(df.loc[:,'A']) # 打印一列
print(df.loc['20250507','B'])
# select by position:iloc
# 这里的用法和上面差不多,只不过将索引变成了数字
print(df.iloc[1,2])
# mixed selection:ix
# 上面两种的混合使用
# Boolean indexing
print(df)
print(df[df.A > 8])
>>> df
A B C D
2025-05-07 0 1 2 3
2025-05-08 4 5 6 7
2025-05-09 8 9 10 11
2025-05-10 12 13 14 15
2025-05-11 16 17 18 19
2025-05-12 20 21 22 23
>>> df[df.A >8]
A B C D
2025-05-10 12 13 14 15
2025-05-11 16 17 18 19
2025-05-12 20 21 22 23
>>>
设置值
import pandas as pd
import numpy as np
dates = pd.date_range('20250507',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
# 使用数据的选择来改变
df.iloc[2,2] = 1111
df.loc['20250506','B'] = 22222
# 这样是更改一行
df[df.A>0] = 0
# 更改一个,A这一列符合条件的元素将会被更改
df.A[df.A>4] = 0
# 定义一个空列
df['F'] = np.nan
# 添加一个列
df['E'] = pd.Series([1,2,3,4,5,6],index=pd.date_range('20250507',periods=6))
A B C D (1, 1) F E
2025-05-07 0 1 2 3 1111 NaN 1
2025-05-08 4 100 6 7 1111 NaN 2
2025-05-09 8 9 10 11 1111 NaN 3
2025-05-10 12 13 14 15 1111 NaN 4
2025-05-11 16 17 18 19 1111 NaN 5
2025-05-12 20 21 22 23 1111 NaN 6
处理丢失数据
import pandas as pd
import numpy as np
dates = pd.date_range('20250507',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
>>> df.iloc[0,1] = np.nan
>>> df.iloc[1,2] = np.nan
>>> df
A B C D
2025-05-07 0 NaN 2.0 3
2025-05-08 4 5.0 NaN 7
2025-05-09 8 9.0 10.0 11
2025-05-10 12 13.0 14.0 15
2025-05-11 16 17.0 18.0 19
2025-05-12 20 21.0 22.0 23
# dropna 的使用(丢掉)
print(df.dropna(axis=1,how='any'))
>>> df.dropna(axis=1,how='any')
A D
2025-05-07 0 3
2025-05-08 4 7
2025-05-09 8 11
2025-05-10 12 15
2025-05-11 16 19
2025-05-12 20 23
# axis=1 丢失含nan的列
# how={'any','all'}
# 将没有数据的位置填上默认
print(df.fillna(value=0))
>>> df.fillna(value=0)
A B C D
2025-05-07 0 0.0 2.0 3
2025-05-08 4 5.0 0.0 7
2025-05-09 8 9.0 10.0 11
2025-05-10 12 13.0 14.0 15
2025-05-11 16 17.0 18.0 19
2025-05-12 20 21.0 22.0 23
# 检查有没有丢失数据
print(df,.isnull())
>>> df.isnull()
A B C D
2025-05-07 False True False False
2025-05-08 False False True False
2025-05-09 False False False False
2025-05-10 False False False False
2025-05-11 False False False False
2025-05-12 False False False False
print(np.any(df.isnull()) == True)
pandas的导入导出
读取文件
- read_csv
- read_excel
- read_hdf
- read_sql
- read_json
- read_msgpack
- read_html
- read_gbq
- read_stata
- read_sas
- read_clipboard
- read_pickle
保存数据
- to_csv
- to_excel
- to_hdf
- to_sql
- to_json
- to_msgpack
- to_html
- to_gbq
- to_stata
- to_clipboard
- to_pickle
import pandas as pd
data = pd.read_csv('文件名')
data.to_csv('文件名')
合并
import pandas as pd
import numpy as np
# concatenating 以及它的参数
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])
# concat
>>> res = pd.concat([df1,df2,df3],axis=0,ignore_index=True)
>>> res
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 2.0 2.0 2.0 2.0
7 2.0 2.0 2.0 2.0
8 2.0 2.0 2.0 2.0
# join,[inner','outer']
df4 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df5 = pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index=[2,3,4])
# 如果直接合并,join默认是 outer
res1 = pd.conct([df1,df2])
>>> res1 = pd.concat([df4,df5])
>>> res1
a b c d e
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 0.0 0.0 0.0 0.0 NaN
2 NaN 1.0 1.0 1.0 1.0
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0
>>> res2 = pd.concat([df4,df5],join='inner',ignore_index=True)
>>> res2
b c d
0 0.0 0.0 0.0
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 1.0 1.0 1.0
4 1.0 1.0 1.0
5 1.0 1.0 1.0
# _append
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'],index=[2,3,4])
>>> res = df1._append(df2,ignore_index=True)
>>> res
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
merge
>>> import pandas as pd
>> left = pd.DataFrame({'key':['K0','K1','K2','K3'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})
>> right = pd.DataFrame({'key':['K0','K1','K2','K3'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})
# merging two df by key/keys
>>> res = pd.merge(left,right,on='key')
>>> res
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3
# consider two keys
left1 = pd.DataFrame({'key1':['K0','K0','K1','K2'],'key2':['K0','K1','K0','K1'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})
right1 = pd.DataFrame({'key1':['K0','K1','K1','K2'],'key2':['K0','K0','K0','K0'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})
>>> res = pd.merge(left1,right1,on=['key1','key2'])
>>> res
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
>>> left1
key1 key2 A B
0 K0 K0 A0 B0
1 K0 K1 A1 B1
2 K1 K0 A2 B2
3 K2 K1 A3 B3
>>> right1
key1 key2 C D
0 K0 K0 C0 D0
1 K1 K0 C1 D1
2 K1 K0 C2 D2
3 K2 K0 C3 D3
# how=['left','right','out','inner']
# left ---> 基于left 的key来填充
# indicator -----> 显示怎么合并的
# left_index and right_index
>>> res1 = pd.merge(left,right,left_index=True,right_index=True,how='outer')
>>> res1
key_x A B key_y C D
0 K0 A0 B0 K0 C0 D0
1 K1 A1 B1 K1 C1 D1
2 K2 A2 B2 K2 C2 D2
3 K3 A3 B3 K3 C3 D3
plot
>>> import pandas as pd
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> data = pd.Series(np.random.randn(1000),index=np.arange(1000))
>>> data = data.cumsum()
>>> data.plot()
>>> plt.show()