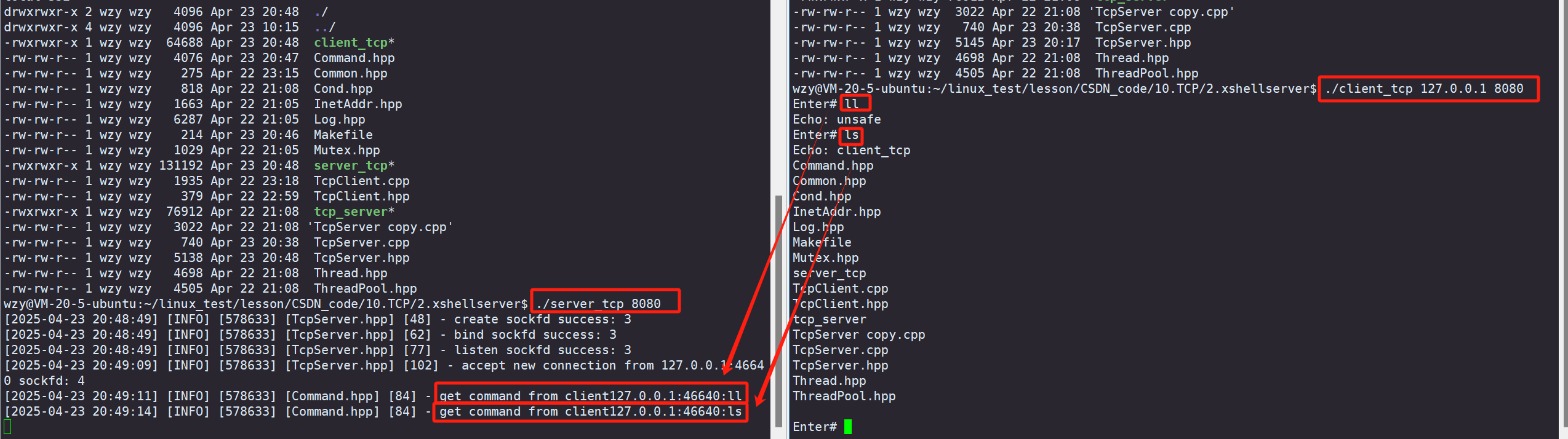
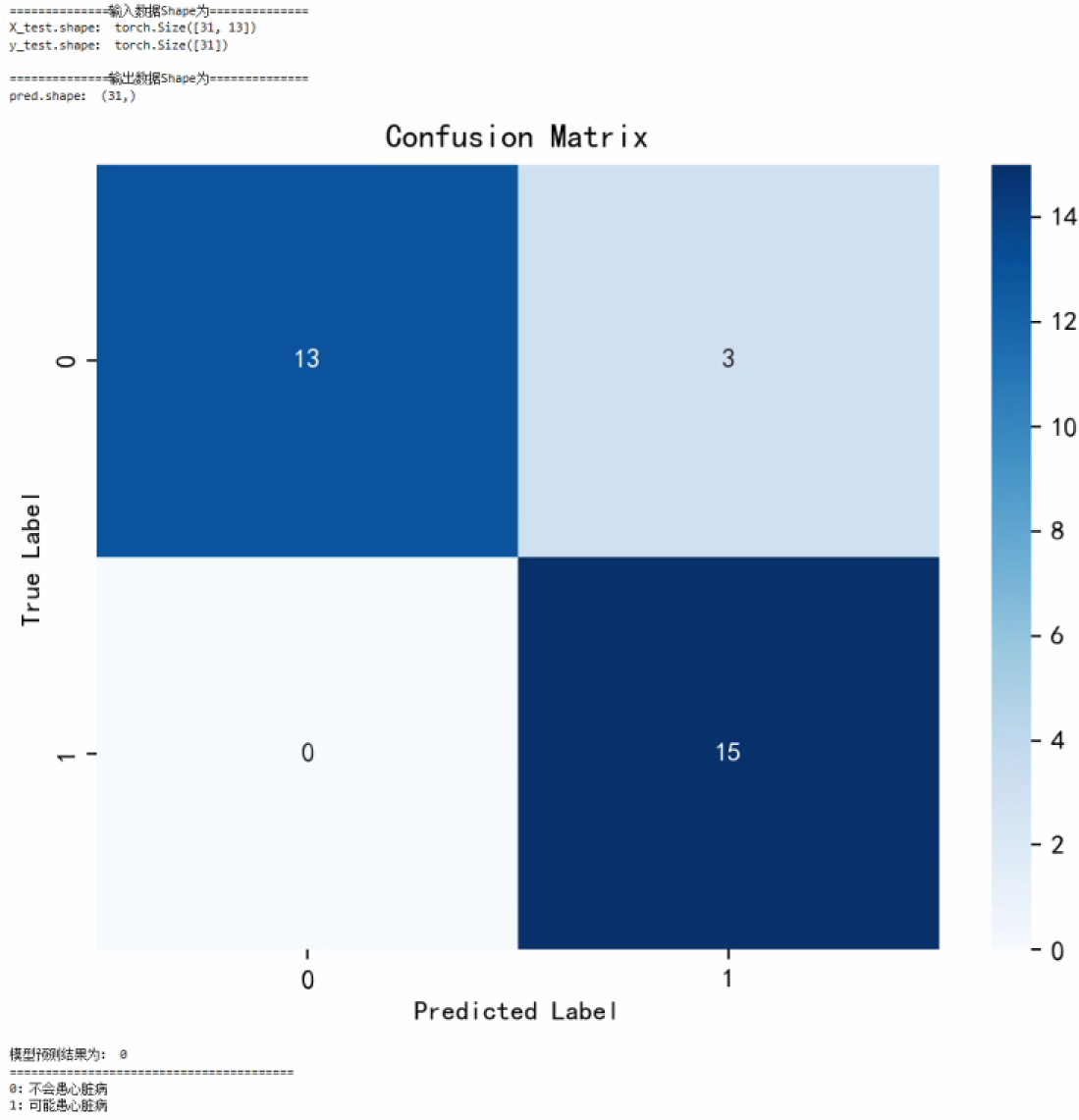
完全二叉树 CBT
设二叉树的深度为 h , 若非最底层的其他各层的节点数都达到最大个数 , 最底层 h 的所有节点都连续集中在左侧的二叉树叫做 完全二叉树 .
特点
- 对任意节点 , 其右分支下的叶子节点的最底层为 L , 则其左分支下的叶子节点的最低层一定是 L 或 L + 1 .
- 完全二叉树度为 1 的点只有 1 个或 0 个 .
- 按层序遍历的顺序访问 , 度为 1 或 0 的节点的后续节点的度均为 0 .
二叉树的层序遍历
层序遍历是一种广度优先搜索 , 要借助 队列 数据结构实现 , 核心逻辑如下 :
- 初始化队列 , 把根节点加入队列 .
- 从队列取出一个节点 , 将该节点的左右节点加入队列 , 重复处理至队列为空 .
class TreeNode{
int val;
TreeNode left;
TreeNode right;
TreeNode(int val){this.val = val;}
public static List<Integer> levelOrderTraversal(TreeNode root){
Queue<TreeNode> queue = new LinkedList<>();
List<Integer> list = new ArrayList<>();
if (root == null) {
return list;
}
queue.offer(root);
while(!queue.isEmpty()){
TreeNode node = queue.poll();
list.add(node.val);
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
return list;
}
}
Queue 的 offer 方法会将 null 加入队列 , 因此我们要加入条件语句避免产生空指针异常 .
判断二叉树是否为完全二叉树
因为完全二叉树最底层 h 的所有节点都连续集中在左侧 , 且按层序遍历的顺序访问 , 度为 1 或 0 的节点的后续节点的度均为 0 ( 特点 3 ) , 判断是否为完全二叉树较常用的方法要借助 二叉树的层序遍历 , 核心逻辑如下 :
- 对二叉树进行层序遍历 , 使用队列保存节点 .
- 遍历过程中维护标识符 end , 其表示是否遇到过度为 1 或 0 的节点 .
- end 标识符翻转后如果再次遇到有左右任一子节点的节点 , 直接返回 .
class TreeNode{
int val;
TreeNode left;
TreeNode right;
TreeNode(int val){this.val = val;}
public static Boolean isCBTorNot(TreeNode root){
Queue<TreeNode> queue = new LinkedList<>();
if (root == null) {
return true;
}
queue.offer(root);
boolean end = false;
while(!queue.isEmpty()){
TreeNode node = queue.poll();
if(node.left != null){
if(end) return false;
queue.offer(node.left);
}else end = true;
if(node.right != null){
if(end) return false;
queue.offer(node.right);
}else end = true;
}
return true;
}
}
完全二叉树的数组表示
为什么可以使用数组表示 ?
完全二叉树非最底层的其他各层的节点数都达到最大个数 , 最底层 h 的所有节点都连续集中在左侧 , 使得使用数组存储时能够紧密排列 , 避免空间浪费 .
父子节点的索引关系
推导过程如图 , 结论 :
- 父节点的数组索引为 n , 则左子节点的数组索引为 2 * n + 1 , 右子节点的数组索引为 2 * n + 2 , 祖父节点的数组索引为 ( n - 1 ) / 2 .

值得注意的是 , 叶子节点在数组表示的堆中分布在 (n / 2) - 1 到 n - 1 中 ( n 是堆的节点数量 ) , 证明如下 :
- 对于任意节点 i , 若存在左子节点 , 则左子节点索引 left = 2 * i + 1 .
- 当 left >= n 时 , 意味着该节点没有左子节点 . 由于完全二叉树的节点是靠左排列的 , 没有左子节点也就意味着没有右子节点 , 所以该节点一定是叶子节点 .
- 2 * i + 1 >= n 得到 i >= (n / 2) - 1 , 得证 .
堆 Heap
堆是满足特定条件的完全二叉树 , 主要分为 大顶堆 和 小顶堆 两种类型 , 大顶堆指 任意节点值 >= 其子节点值 , 小顶堆指 任意节点值 <= 其子节点值 .
堆化
堆化是将无序数组转化为堆的过程 . 添加元素入堆时执行上浮操作 :
- 给定元素 val , 我们首先将该元素添加到堆底 .
- val 可能大于堆中其他元素 , 此时堆被暂时破坏 , 我们要从堆底至顶进行堆化 .
- 比较 val 节点与其节点的值 , 若插入节点更大则交换二者 , 重复执行操作直到节点上升到根节点或其父节点更大时结束 .
初始化无序数组为堆时执行下沉操作 :
- 自下而上对每个非叶子节点执行下沉操作 : 比较该节点与左右子节点 , 若该节点值小于子节点最大值 , 则交换该节点与最大值子节点 .
- 重复操作直到节点下沉到叶子节点或该节点值大于或等于左右子节点值的最大值 .
上浮操作常用于向堆中添加元素 , 下沉操作常用于初始化无序数组为堆和删除堆中元素等场景 .
堆的节点总数为 n , 树的层数为 log n , 堆化操作的迭代次数至多为 log n , 知初始化无序数组为堆的时间复杂度是 O(n log n) .
class Heap {
public static void heapify(int[] arr, int n, int i) {
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < n && arr[left] > arr[largest]) largest = left;
if (right < n && arr[right] > arr[largest]) largest = right;
if (largest != i) {
int swap = arr[i];
arr[i] = arr[largest];
arr[largest] = swap;
heapify(arr, n, largest);
}
}
public static void buildMaxHeap(int[] arr) {
int n = arr.length;
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
} // 我们不需要对叶子节点进行下沉操作.
堆排序
堆排序基于顶堆的特性 , 重复将堆顶元素与堆尾元素交换 , 堆化非队尾元素的剩余元素 直至数组有序 . 堆的节点数为 n , 堆化操作的时间复杂度为 log n , 因此堆排序的时间复杂度是 O(n log n) , 堆排序基于原地交换 , 空间复杂度为常数级 , 是性能良好的排序方法 .
class Heap{
public static void heapSort(int[] arr) {
int n = arr.length;
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
for (int i = n - 1; i > 0; i--) {
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
heapify(arr, i, 0);
}
}
}
优先队列 PriorityQueue
优先队列是特殊的队列数据结构 , 在 Java PriorityQueue 类中 , 默认优先级为从小到大的自然排序 , 可以通过 lambda 表达式自定义比较器 Comparator 函数类型 .
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(); // 默认为自然顺序
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(Comparator.reverseOrder()); // 更改比较器为降序
如果要储存自定义引用数据类型时 , 有两种方式定义元素优先级 :
- 引用类实现
Comparable接口 : 在类中实现compareTo()方法 . - 在初始化 PriorityQueue 时传入比较器对象 .
class Person{
private String name;
private int age;
Person(String name, int age){
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person person){
retutn Integer.compare(this.age, person.age);
}
}
public class Main{
public static void main(String[] args){
PriorityQueue<Person> pq = new PriorityQueue<>();
// 或
PriorityQueue<Person> pq = new PriorityQueue<>((p1, p2) -> Integer.compare(p2.getAge(), p1.getAge()));
}
}
底层实现
Java 使用小顶堆实现优先队列 .
- 初始化 : 对无序集合对应的非子叶节点逐个进行下沉操作 .
- 插入元素
offer(): 在优先队列中插入元素通常插入到堆底 , 对堆底元素进行堆化的上浮操作 . - 删除元素
poll(): 在优先队列中删除元素通常删除的是堆顶元素 , 先保存堆顶元素 , 再将堆底元素推到堆顶 , 对更新后的堆顶元素进行堆化的下沉操作 .
堆是一种具体的数据结构 , 优先队列是基于堆实现的抽象数据类型 , 堆除了实现优先队列外还可以应用到堆排序等场景 .
23. 合并 K 个升序链表

我们维护一个按节点值自然排序的优先队列 , 将链表数组内的所有非空数组加入队列 , 每次出堆堆顶节点 , 定义返回节点指向出堆节点 , 入堆出堆节点的后继节点 , 返回节点指针后移 , 重复操作直到堆为空即可 .
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
PriorityQueue<ListNode> pq = new PriorityQueue<>((a, b) -> a.val - b.val);
for (ListNode head : lists) {
if (head != null) {
pq.offer(head);
}
}
ListNode dummy = new ListNode();
ListNode cur = dummy;
while (!pq.isEmpty()) {
ListNode node = pq.poll();
if (node.next != null) {
pq.offer(node.next);
}
cur.next = node;
cur = cur.next;
}
return dummy.next;
}
}