一、引言
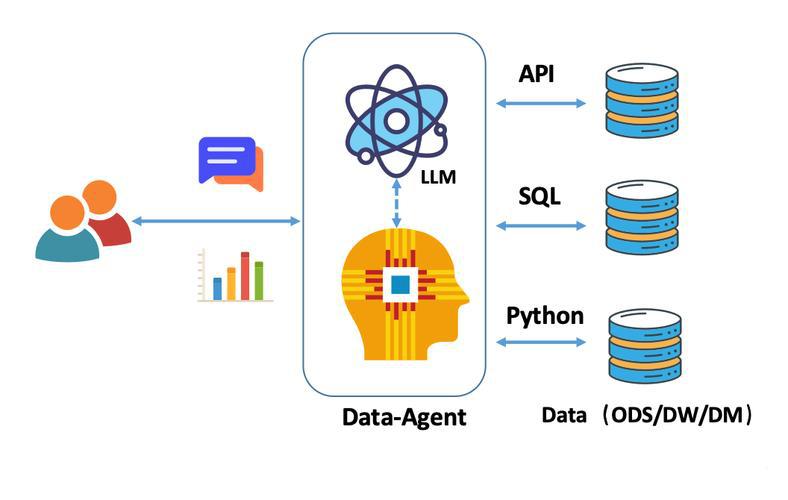
在人工智能蓬勃发展的今天,强化学习(Reinforcement Learning, RL)作为让智能体(Agent)在复杂环境中自主学习并做出最优决策的核心技术,正日益受到关注。从游戏领域中击败人类顶尖选手的 AlphaGo,到机器人控制、自动驾驶等实际应用场景,强化学习驱动的 Agent 展现出了强大的适应能力和决策智慧。本文将围绕基于强化学习的 Agent 训练框架,从核心概念、架构设计、关键技术到实战案例进行全流程拆解,帮助读者深入理解并掌握这一前沿技术。
二、强化学习核心概念与基础原理
(一)强化学习基本要素
强化学习是一种通过智能体与环境的交互来学习决策策略的技术,其核心要素包括:
- 智能体(Agent):在环境中执行动作并进行学习的主体,能够根据环境状态选择动作,并从环境中获得奖励。
- 环境(Environment):智能体所处的外部世界,它接收智能体的动作并返回新的状态和奖励。
- 状态(State):描述环境当前状况的信息集合,是智能体决策的依据。
- 动作(Action):智能体在当前状态下可以采取的行为。
- 奖励(Reward):环境对智能体动作的反馈信号,用于评估动作的好坏,引导智能体学习最优策略。
(二)强化学习目标与策略
强化学习的目标是使智能体在与环境的长期交互中,最大化累计奖励。智能体通过学习策略(Policy)来决定在不同状态下选择何种动作。策略可以分为确定性策略(给定状态输出确定的动作)和随机性策略(给定状态输出动作的概率分布)。
(三)强化学习算法分类
根据学习方式的不同,强化学习算法主要分为以下几类:
- 基于值的方法(Value - Based Methods):通过学习值函数(Value Function)来评估状态或状态 - 动作对的好坏,如 Q - Learning、Sarsa 等算法。值函数表示从某个状态或状态 - 动作对开始,遵循某种策略所能获得的累计奖励的期望。
- 基于策略的方法(Policy - Based Methods):直接学习策略函数,如策略梯度(Policy Gradient)算法。该类方法通过调整策略参数,使期望奖励最大化。
- Actor - Critic 方法:结合了基于值和基于策略的方法,通过 Actor(策略网络)生成动作,Critic(值网络)评估动作的价值,两者相互配合进行学习,如 A3C(Asynchronous Advantage Actor - Critic)、PPO(Proximal Policy Optimization)等算法。
三、强化学习 Agent 训练框架整体架构
一个完整的基于强化学习的 Agent 训练框架通常包括环境模块、智能体模块、训练模块和评估模块等部分,各模块相互协作,实现智能体的训练和优化。
(一)环境模块
环境是智能体学习的对象,环境模块的设计直接影响智能体的训练效果。环境可以分为真实环境和仿真环境。在实际应用中,由于真实环境的复杂性和安全性限制,通常会先在仿真环境中进行训练,待智能体具备一定能力后再迁移到真实环境中。
- 环境建模:需要明确环境的状态空间(State Space)、动作空间(Action Space)和奖励函数(Reward Function)。状态空间描述了环境中所有可能的状态,动作空间定义了智能体可以采取的所有动作,奖励函数则用于衡量智能体动作的优劣。
- 环境交互接口:提供智能体与环境交互的接口,使智能体能够向环境发送动作,并接收环境返回的新状态、奖励和是否结束等信息。
(二)智能体模块
智能体模块是训练框架的核心,它包含了智能体的策略网络、值网络(如果使用 Actor - Critic 方法)以及相关的参数和数据结构。
- 网络结构设计:根据问题的特点和复杂度,选择合适的神经网络结构,如深度神经网络(DNN)、卷积神经网络(CNN,适用于图像等空间数据)、循环神经网络(RNN,适用于序列数据)等。网络的输入通常是环境状态,输出根据算法类型有所不同,基于值的方法输出状态 - 动作对的 Q 值,基于策略的方法输出动作的概率分布,Actor - Critic 方法中 Actor 输出动作概率分布,Critic 输出状态或状态 - 动作对的值。
- 策略与值函数表示:策略函数和值函数通过神经网络参数化,训练过程就是调整这些参数,使智能体的行为逐渐接近最优策略。
(三)训练模块
训练模块负责协调智能体与环境的交互,收集训练数据,并根据算法对智能体进行更新。
- 训练流程:
- 初始化:初始化智能体的网络参数、经验回放缓冲区(如果使用)等。
- 数据收集:智能体在环境中执行动作,收集状态、动作、奖励、下一个状态和是否结束等数据,并将这些数据存储到经验回放缓冲区(用于提高数据利用率和训练稳定性)或直接用于训练。
- 策略更新:根据收集到的数据,使用强化学习算法对智能体的网络参数进行更新。不同算法的更新方式有所不同,如 Q - Learning 通过最大化 Q 值来更新值函数,策略梯度算法通过计算梯度来更新策略参数。
- 探索与利用平衡:在训练初期,智能体需要更多地探索环境,以发现新的状态和动作组合;随着训练的进行,逐渐转向利用已有的知识,选择当前认为最优的动作。常用的探索策略包括 ε - greedy 策略(以 ε 的概率随机选择动作,以 1 - ε 的概率选择当前最优动作)、玻尔兹曼探索(根据动作的概率分布选择动作,温度参数控制探索程度)等。
- 优化器选择:常用的优化器包括随机梯度下降(SGD)、Adam、RMSprop 等,不同的优化器具有不同的特点和适用场景,需要根据具体问题进行选择。
(四)评估模块
评估模块用于检验训练后的智能体性能,判断训练是否达到预期效果。
- 评估指标:根据任务的不同,评估指标可以是累计奖励、成功率、完成任务的时间等。例如,在游戏任务中,常用累计得分作为评估指标;在机器人控制任务中,可能更关注任务完成的精度和稳定性。
- 评估方法:在固定的环境场景下,让智能体执行一定次数的测试,记录评估指标并计算平均值、标准差等统计量,以全面评估智能体的性能。
四、训练框架关键技术详解
(一)数据预处理与特征工程
在强化学习中,环境状态可能是高维的、复杂的,如图像、传感器数据等。数据预处理和特征工程可以提高数据质量,减少噪声,降低维度,从而提高模型的训练效率和效果。
- 状态归一化 / 标准化:对连续的状态变量进行归一化或标准化处理,使不同维度的状态数据具有相同的尺度,避免数值较大的维度对训练产生过大影响。
- 特征提取:对于图像等复杂数据,使用卷积神经网络等进行特征提取,自动学习具有代表性的特征;对于时序数据,可使用循环神经网络或时间卷积网络提取时间序列特征。
(二)奖励工程
奖励函数的设计是强化学习中的关键环节,直接影响智能体的学习方向和效果。
- 稀疏奖励处理:在一些任务中,奖励信号可能非常稀疏,如只有在任务成功或失败时才给予奖励,这会导致智能体学习困难。常用的解决方法包括设置中间奖励(根据任务进展给予阶段性奖励)、使用模仿学习(结合专家演示数据)等。
- 奖励塑形(Reward Shaping):通过设计额外的奖励函数来引导智能体学习期望的行为,帮助智能体更快地收敛到最优策略。例如,在机器人导航任务中,可以给予智能体靠近目标的正向奖励,远离目标的负向奖励。
(三)经验回放(Experience Replay)
经验回放是强化学习中常用的技术,它将智能体与环境交互产生的数据存储在回放缓冲区中,然后随机抽取样本进行训练。这样可以打破数据之间的相关性,提高数据的利用率,稳定训练过程。
- 回放缓冲区设计:需要考虑缓冲区的大小(过大的缓冲区会占用更多内存,过小的缓冲区可能导致数据不足)、数据存储格式(通常存储状态、动作、奖励、下一个状态和是否结束等信息)以及数据采样策略(如均匀采样、优先经验回放,优先回放重要的样本,提高训练效率)。
(四)分布式训练技术
随着强化学习任务的复杂度不断提高,单节点训练往往难以满足需求,分布式训练技术应运而生。分布式训练可以利用多个计算节点并行处理,加快训练速度,提高模型的规模和性能。
- 分布式架构:主要包括数据并行(将训练数据分配到多个节点,每个节点运行相同的模型,同步更新模型参数)、模型并行(将模型的不同部分分配到多个节点,适用于大型模型)和混合并行(结合数据并行和模型并行)。
- 通信与同步:分布式训练中需要解决节点之间的数据通信和模型参数同步问题,常用的方法包括异步更新(节点之间无需等待,提高训练速度,但可能导致训练不稳定)和同步更新(节点之间同步参数,训练更稳定,但速度较慢)。
五、实战案例:基于 PPO 算法的 Atari 游戏 Agent 训练
(一)环境选择与搭建
选择经典的 Atari 游戏环境,如 Pong、Breakout 等。使用 OpenAI Gym 库中的 Atari 环境,该库提供了丰富的游戏环境接口,方便智能体与环境的交互。
(二)智能体设计
采用 Actor - Critic 架构,Actor 网络和 Critic 网络均使用卷积神经网络。Actor 网络输入为游戏画面(预处理为灰度图像并调整尺寸),输出各动作的概率分布;Critic 网络输入同样为游戏画面,输出当前状态的值。
(三)训练过程
- 初始化:设置训练参数,如学习率、折扣因子 γ、批量大小、训练轮数等;初始化 Actor 和 Critic 网络参数。
- 数据收集:智能体在 Atari 环境中根据当前策略执行动作,收集游戏画面、动作、奖励、下一个画面和是否结束等数据,存储到经验回放缓冲区。
- 策略更新:使用 PPO 算法对 Actor 和 Critic 网络进行更新。PPO 通过限制新旧策略之间的差异,保证训练的稳定性和收敛性。具体来说,计算优势函数(Advantage Function),然后优化目标函数,其中包含策略梯度项和值函数误差项。
- 探索策略:在训练初期使用 ε - greedy 策略进行探索,随着训练的进行,逐渐减小 ε 的值,降低探索比例。
(四)评估与优化
定期对训练中的智能体进行评估,记录在固定游戏场景下的得分。根据评估结果调整训练参数,如学习率、网络结构等,优化训练过程。经过一定轮数的训练后,智能体能够在 Atari 游戏中取得较高的得分,表现出良好的决策能力。
六、总结
本文详细拆解了基于强化学习的 Agent 训练框架全流程,从核心概念、架构设计到关键技术和实战案例进行了全面介绍。强化学习在 Agent 训练中展现出了强大的潜力,但也面临着许多挑战,如样本效率低、训练稳定性差、复杂环境下的泛化能力等。未来,随着技术的不断发展,强化学习与深度学习、迁移学习、多智能体系统等技术的结合将更加紧密,有望在更多领域取得突破性应用。