文章目录
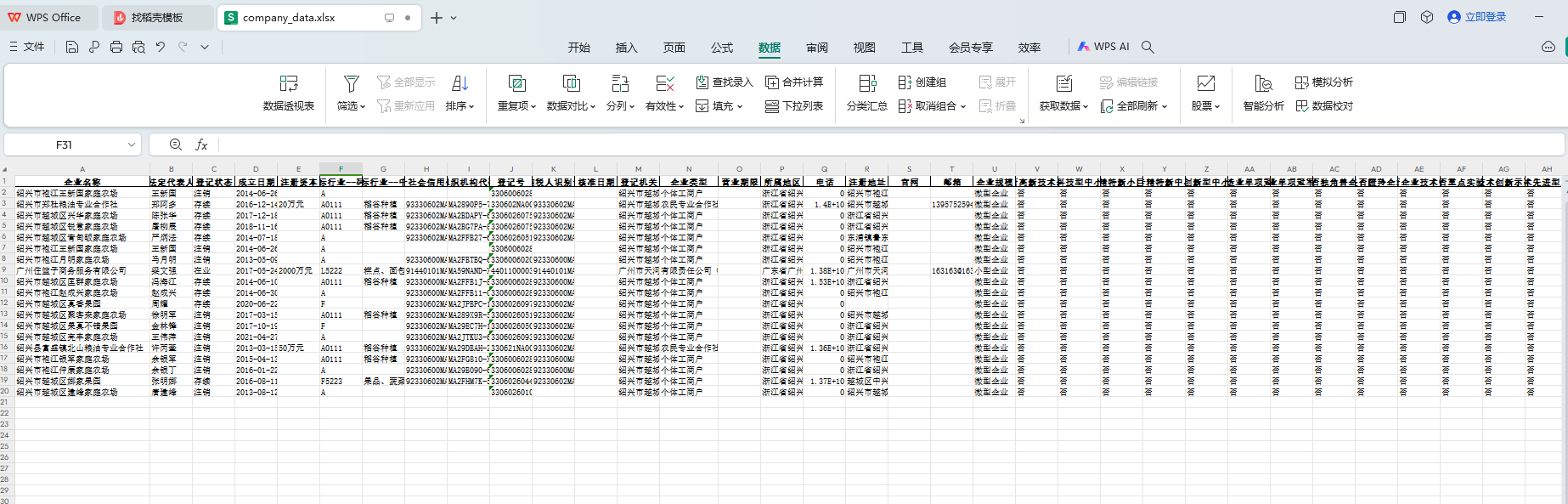
1、准备要爬取企业名称数据表 2、爬取代码 3、查看效果
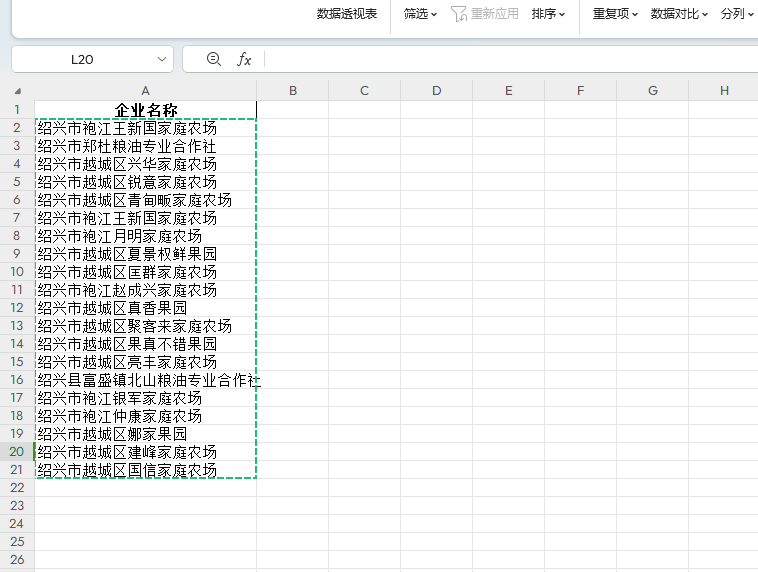
企业名称 绍兴市袍江王新国家庭农场 绍兴市郑杜粮油专业合作社 绍兴市越城区兴华家庭农场 绍兴市越城区锐意家庭农场 绍兴市越城区青甸畈家庭农场 绍兴市袍江王新国家庭农场 绍兴市袍江月明家庭农场 绍兴市越城区夏景权鲜果园 绍兴市越城区匡群家庭农场 绍兴市袍江赵成兴家庭农场 绍兴市越城区真香果园 绍兴市越城区聚客来家庭农场 绍兴市越城区果真不错果园 绍兴市越城区亮丰家庭农场 绍兴县富盛镇北山粮油专业合作社 绍兴市袍江银军家庭农场 绍兴市袍江仲康家庭农场 绍兴市越城区娜家果园 绍兴市越城区建峰家庭农场 绍兴市越城区国信家庭农场
import time
import requests
from bs4 import BeautifulSoup
import re
import json
import pandas as pd
import jsonpath
from datetime import datetime
import random
from urllib3. exceptions import ConnectTimeoutError
session = requests. Session( )
url = "https://www.qcc.com/web/search?"
header = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0" ,
"accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7" ,
"accept-encoding" : "gzip, deflate, br, zstd" ,
"accept-language" : "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6" ,
"cookie" : ""
}
proxy_url = 'http://api.89ip.cn/tqdl.html?api=1&num=60&port=&address=%E5%B9%BF%E4%B8%9C%E7%9C%81&isp='
test_url = 'http://httpbin.org/ip'
valid_proxies = [ ]
def get_valid_proxies ( ) :
try :
resp = requests. get( proxy_url, timeout= 10 )
resp. raise_for_status( )
proxy_ips = re. findall( r'\d+\.\d+\.\d+\.\d+:\d+' , resp. text)
for ip in proxy_ips:
proxy = { 'http' : f'http:// { ip} ' , 'https' : f'http:// { ip} ' }
try :
test_resp = requests. get( test_url, proxies= proxy, timeout= 5 )
if test_resp. status_code == 200 :
valid_proxies. append( proxy)
print ( {
'http' : f'http:// { ip} ' ,
'https' : f'http:// { ip} ' } )
except ( requests. exceptions. ProxyError, ConnectTimeoutError, requests. exceptions. Timeout) :
continue
return valid_proxies
except Exception as e:
print ( f"获取代理失败: { e} " )
return None
def get_proxy ( ) :
"""获取代理"""
try :
ip_port = random. choice( get_valid_proxies( ) )
print ( "选择的代理IP:" , ip_port)
except Exception as e:
print ( f"获取代理失败: { e} " )
return None
company_data = [ ]
red_execl= pd. read_excel( r"C:\Users\zzx\Desktop\浙江_绍兴_1.xlsx" )
company_names = red_execl. iloc[ : , 0 ] . tolist( )
def safe_jsonpath ( data, path, default= "" , strict_type= False ) :
"""
安全解析 JSONPath,返回第一个匹配值或默认值
- 自动处理 None、空列表、类型不匹配
- 根据 default 参数类型自动转换返回值类型
"""
result = jsonpath. jsonpath( data, path)
if not isinstance ( result, list ) or len ( result) == 0 :
return default
value = result[ 0 ]
if value is None :
return default
if strict_type:
if isinstance ( value, type ( default) ) :
return value
return default
try :
return type ( default) ( value)
except ( TypeError, ValueError, ) :
return default
TAG_LIST = [
"高新技术企业" , "科技型中小企业" , "专精特新小巨人企业" ,
"专精特新中小企业" , "创新型中小企业" , "制造业单项冠军企业" ,
"制造业单项冠军产品企业" , "独角兽企业" , "瞪羚企业" , "企业技术中心" ,
"重点实验室" , "技术创新示范企业" , "技术先进型服务企业" ,
"众创空间" , "隐形冠军企业"
]
def parse_tags ( data) :
"""解析企业标签"""
tags_info = safe_jsonpath( data, "$..TagsInfoV2" , default= [ ] )
return { f"是否 { tag} " : "是" if any ( t. get( 'Name' ) == tag for t in tags_info) else "否" for tag in TAG_LIST }
def process_company_data ( name) :
"""处理单个公司数据"""
max_retries = 3
for attempt in range ( max_retries) :
try :
proxies = get_proxy( )
'''
proxies = {
'http': 'http://120.24.73.25:8181',
'https': 'http://120.24.73.25:8181'
}
'''
params = { "key" : name}
response = session. get( url, headers= header, params= params, proxies= proxies, timeout= 10 )
if response. status_code != 200 :
raise Exception( f"状态码: { response. status_code} " )
if "验证码" in response. text:
raise Exception( "触发反爬验证码" )
soup = BeautifulSoup( response. text, 'html.parser' )
scripts = soup. find_all( 'script' )
pattern = re. compile ( r'window\.__INITIAL_STATE__\s*=\s*({.*?});' , re. DOTALL)
for script in soup. find_all( 'script' ) :
if script. string and ( match : = pattern. search( script. string) ) :
data = json. loads( match. group( 1 ) )
credit_code = safe_jsonpath( data, "$..CreditCode" , default= "" )
org_code = f" { credit_code[ 8 : -2] } - { credit_code[ - 2 ] } " if credit_code else ""
start_date = safe_jsonpath( data, "$..StartDate" , default= 0 )
formatted_date = datetime. fromtimestamp( start_date / 1000 ) . strftime( "%Y-%m-%d" ) if start_date else ""
allottedSpan = safe_jsonpath( data, "$..allottedSpan" , default= 0 )
formatted_allottedSpan = datetime. fromtimestamp( allottedSpan / 1000 ) . strftime( "%Y-%m-%d" ) if allottedSpan else ""
company_info = {
"企业名称" : re. sub( r'<[^>]+>' , '' , safe_jsonpath( data, "$..Name" , default= "" ) ) ,
"法定代表人" : safe_jsonpath( data, "$..OperName" , default= "" ) ,
"登记状态" : safe_jsonpath( data, "$..ShortStatus" , default= "" ) ,
"成立日期" : formatted_date,
"注册资本" : safe_jsonpath( data, "$..RegistCapi" , default= "" ) ,
"国标行业--码值" : safe_jsonpath( data, "$..IndustryCode" , default= "" ) + safe_jsonpath( data, "$..SmallCategoryCode" , default= "" ) ,
"国标行业--中文" : safe_jsonpath( data, "$..SmallCategory" , default= "" ) ,
"统一社会信用代码" : safe_jsonpath( data, "$..CreditCode" , default= "" ) ,
"组织机构代码" : org_code,
"登记号" : safe_jsonpath( data, "$..No" , default= "" ) ,
"纳税人识别号" : safe_jsonpath( data, "$..CreditCode" , default= "" ) ,
"核准日期" : safe_jsonpath( data, "$..CheckDate" , default= "" ) ,
"登记机关" : safe_jsonpath( data, "$..City" , default= "" ) + safe_jsonpath( data, "$..County" , default= "" ) + "市场监督管理局" ,
"企业类型" : safe_jsonpath( data, "$..EconKind" , default= "" ) ,
"所属地区" : safe_jsonpath( data, "$..Province" , default= "" ) + safe_jsonpath( data, "$..City" , default= "" ) + safe_jsonpath( data, "$..County" , default= "" ) ,
"电话" : safe_jsonpath( data, "$..ContactNumber" , default= 0 ) ,
"注册地址" : safe_jsonpath( data, "$..Address" , default= "" ) ,
"官网" : safe_jsonpath( data, "$..GW" , default= "" ) ,
"邮箱" : safe_jsonpath( data, "$..Email" , default= "" ) ,
"企业规模" : safe_jsonpath( data, "$..Scale" , default= "" )
}
print ( company_info)
return { ** company_info, ** parse_tags( data) }
break
except Exception as e:
print ( f"尝试 { attempt + 1 } / { max_retries} 失败: { e} " )
time. sleep( 10 )
return None
BATCH_SIZE = 10
for index, name in enumerate ( company_names) :
print ( f"处理第 { index + 1 } 家公司: { name} " )
info = process_company_data( name)
if info:
company_data. append( info)
else :
print ( f"警告: { name} 数据为空" )
if ( index+ 1 ) % BATCH_SIZE == 0 :
pd. DataFrame( company_data) . to_excel( "temp_result.xlsx" , index= False )
time. sleep( 30 + random. randint( 5 , 15 ) )
if company_data:
df = pd. DataFrame( company_data)
df. to_excel( r"C:\Users\zzx\Desktop\company_data.xlsx" , index= False )
print ( "数据添加成功" )
else :
print ( "所有公司数据获取失败" )