1 背景
为满足高效部署的需要,整合大量优化的tensor代数库和运行时做为后端成为必要之举。现在的深度学习后端可以分为两类:1)算子库(operator kernel libraries),为每个DL算子单独提供高效地低阶kernel实现。这些库一般也支持算子融合,可以将多个算子按照融合规则组合为一个kernel实现。2)图推理库(graph inference libraries),将整个DL模型作为输入并生成高效地运行时代码。除了包含优化的算子库,图推理库还可以处理跨kernel的优化如内存优化。
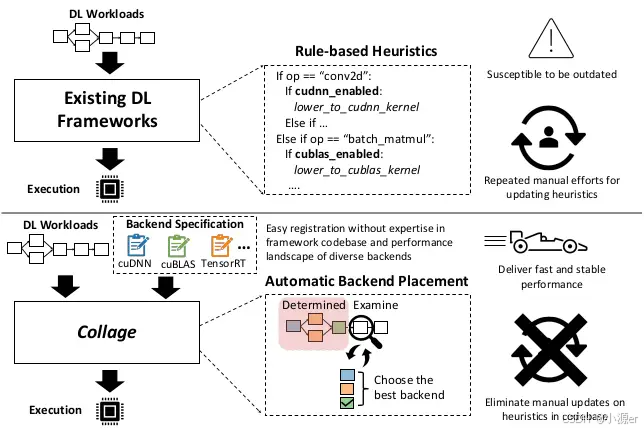
无缝整合后端面临两个挑战,一是要为不同编程模型整合多种可用后端同时保证性能问题;二是优化后端的分配策略权衡每个后端的性能优势。但是现有的框架都是基于规则的方式,按照固定的优先策略将每个算子降阶到不同后端,如上图所示。比如在Pytorch中卷积操作优先选择cuDNN,矩阵乘优先选择cuBLAS。手动地选择后端,这会降低系统潜在性能,减缓不同层之间的连续性,并且开发者需要快速改变编码规则适配新版本的代码库。并且即便对于同一类型的算子,最优后端也是依赖于硬件和算子配置的。
为解决这些问题,Collage提供了一个无缝的整合方案,通过提供有表达力的后端接口允许用户精确地指定多种后端,并且Collage可以为给定模型自动搜寻最优的后端安置策略。
2 结构
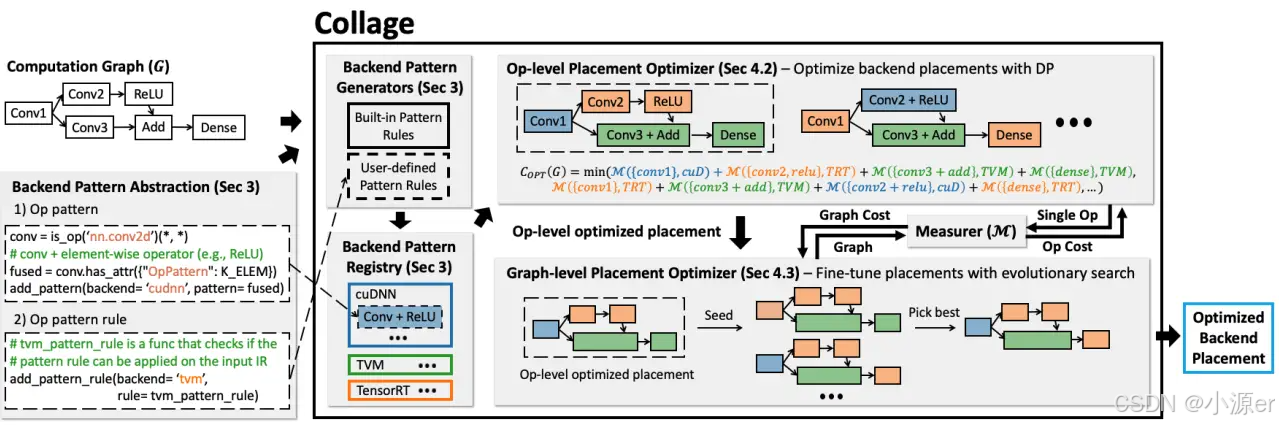
Collage包含两个关键部分,一是提供了具有表达力的后端注册接口来指定后端的能力,该能力基于支持的算子类型、配置信息和融合规则确定。该接口只需要理解提供的匹配语言即可。二是后端分配策略。Collage采用了两阶段的优化策略来处理operator kernel library 和graph inference library两种类型后端的特征。该系统会将全部后端和硬件考虑在内,自动地匹配计算图和后端算子pattern,找到最优的分配方案。
下图列举了Collage的整体结构,以DNN模型和可用的后端作为输入,然后为底层硬件优化后端分配策略。这里考虑的是对于给定目标硬件选择不同组后端,通过度量组件M来评估性能特点。
2.1 Backend pattern abstraction
准确的指定执行平台对于发挥后端全部能力至关重要。后端模板(backend pattern)定义了一组算子和可以直接部署在各个后端的算子组合。然后Collage提供了一个两阶段的抽象,对于简单的pattern,直接列举出全部支持的算子pattern。对于复杂情况,用户可以指定pattern创建规则,如指定简单算子类型和复杂算子融合规则。当融合规则给定,整个计算图上的满足条件的模板都会被保存在后端模板注册表中。

Collage的pattern是Relay Pattern Language的拓展,为所有支持的算子直接指定pattern。对于复杂情况难以直接指定的,可以通过pattern rule指定一组算子的融合规则。该规则可以通过python语法特性来表示。
对于每一个后端,用户可以通过直接指定pattern和pattern rule来提供编程接口。如上图所示,如果后端支持的算子有限,可以将所有pattern枚举出来如3-12行代码;对于复杂pattern,Collage的pattern生成器可以指定复杂规则如14-53行所示。生成器内部可以指定检查器判断约束条件(20-30行),可以以python代码的形式指定融合规则(32-49行)。
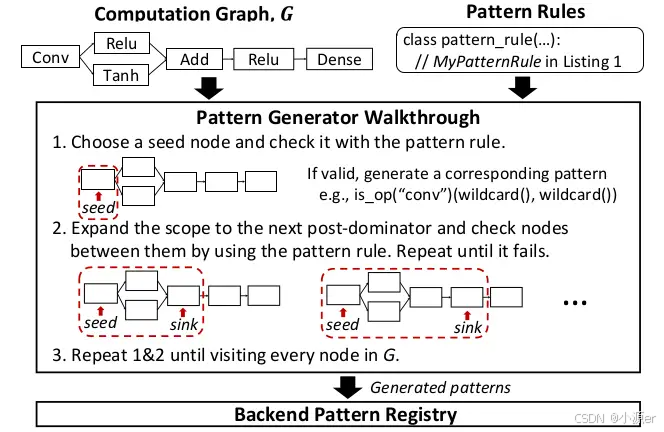
在确定好pattern后,Collage会搜索所有满足条件的规则,并将这些规则实例添加到backend pattern registry中。上图展示了搜索逻辑,pattern generator会按照pattern rule贪心地搜索。对于每个算子首先判断是否可在后端执行,然后进一步向外扩展一步判断是否满足融合规则,一旦条件满足则将对应pattern添加至pattern注册表,然后进一步扩大一步匹配范围。
2.2 Backend placement optimizer
当可用的模板注册好后,Collage会采用一个两阶段的优化方法为当前执行环境找到一个最优的后端安置策略。首先,算子库级的分配优化器会采用动态规划算法为每个算子寻找最优的后端平台,不需要考虑跨内核优化问题。其次,图级分配优化器通过演化搜索算法找最优后端。该部分会考虑跨内核的优化,并作为算子级优化的补充。
2.2.1 问题定义
对于多个后端,Collage的目的是最大化利用可用后端发挥性能最大化。对于后端选择问题,可以将计算图记作G,后端pattern记作B,是一个算子和pattern对儿,p表示具体pattern,d表示后端的标识。p和d都不是唯一对应的,一个p可以在多个d中被满足,一个d可以包含多个p,这样p和d的组合可以唯一确定一个后端和pattern。
对于M个匹配的子图和后端patern
,集合
可以表示计算图G上的后端分配策略即将子图
放置在
上,其中Cost(P(G))表示函数P(G)的执行时间。Collage的目的是通过最小化Cost(P(G))找到一个分配策略
。
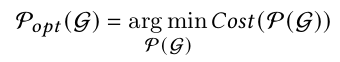
2.2.2 Op_level Placement Optimizer
首先,第一步是算子级的分配优化。其目的是将所有算子映射到可用后端的kernel实现集合上,不需要考虑cross-kernel的优化。通过这种简化,在执行过程中,kernel的执行彼此是独立的。
假设s1和s2是两个不相交,互补的子图,那么执行时间cost可以表示为
![]()
其中表示上下文的切换时间。
Collage采用动态规划算法来优化算子级后端分配策略。根据上面的cost分解公式,可以将在整个计算图上寻找最优分配策略缩小为在一系列子图中找最优策略P(S)的总和。
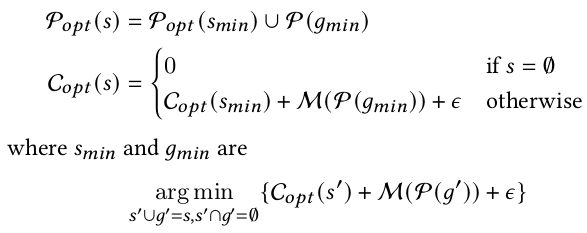
其中,s'表示已经评估过的子图,g'表示待评估的子图, M是评估方法。这里子图的粒度是一个后端pattern,可以是一个单个算子,也可以是复合算子(多个算子)。因为算子都会降阶为单个kernel,该方法就可以每次只评估单个kernel并将结果加到之前的评估结果中。
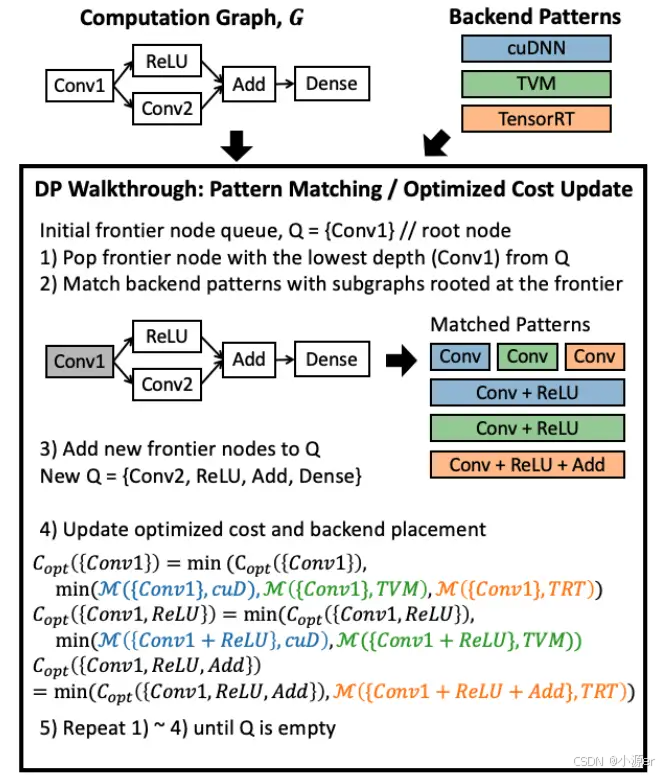
下图展示了整个DP算法的流程。首先,将根节点添加进优先队列并将该节点作为初始的前驱节点,前驱节点是指从所有根节点可达的未访问的节点中路径最短的那个节点。然后将该节点出队,判断是否有以该节点为根节点的pattern,一旦匹配上,则评估该子图并添加新的前驱节点到队列。当确定了最优安置策略后,按照优化公式更新cost。
具体来讲,对于一个计算图,输入节点是root,作为队列第一个元素。然后出队,在所有注册的pattern实例中,找以该节点为根节点的子图组成集合S,元素形式是(si, bj),是一种分配策略,并将当前节点的前驱节点集合中所有没有加入优先队列的节点都加入队列。然后利用cost函数一次评估所有S中的子图策略,找到损失最小的的子图策略。
下图中3)步不对,应该是Q={Conv2, ReLU}。

2.2.3 Graph-level Placement Optimizer
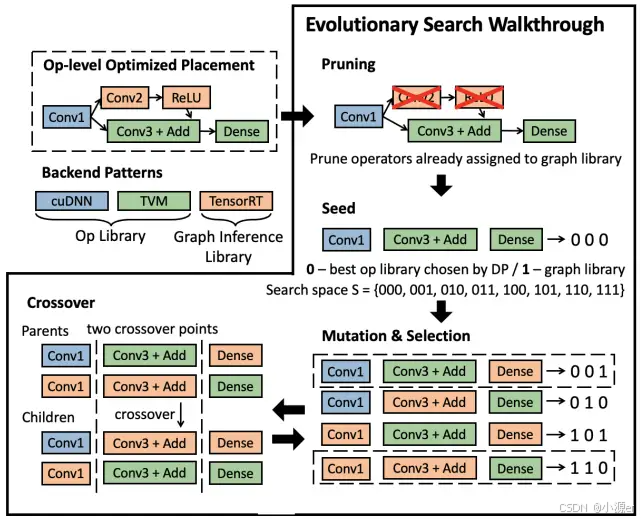
op-level分配策略优化是将kernel视作独立的,忽视了图推理库中的cross-kernel优化如调度优化、内存优化等。因此,Collage引入了graph-level优化,在op-level基础上进一步微调优化,其目的是识别没有分配到图推理库,但是可以进行cross-kernel优化的算子,将这些算子放在图推理库中进行cross-kernel优化。
操作的难点在于找到这些算子。Collage首先在op-level优化的基础上将已经分配到图推理库的算子进行剪枝,然后对于剩下的节点进行尝试分配。为减少复杂性,这里对是否分配到图推理库进行区分,用0/1标注,1表示分配到图推理库中,0表示放在算子级推理库中。然后采用的演化算法,多次的尝试不同的策略调优结果。
3 工程细节
注意!!!由于本人目前还没有彻底搞懂Collage的代码实现逻辑,这里先简单翻译以下github上的解释,等把源码搞清楚了再回来填坑吧。
3.1 相关前导工作
1)[Cascading Scheduler](https://github.com/apache/tvm-rfcs/blob/main/rfcs/0037-arm-ethosu-cascading-scheduler.md)采用动态规划找到TE子表达式最优的组合;引入了损失分析模型引导搜索;逐级调度TE子表达式,降低内存瓶颈。相较之Collage也采用了动态规划,但找的是Relay子表达式的最优组合,然后用了更慢的评估方式引导搜索并且对TVM或BYOC工具链如何降级子图没有任何影响。
2)Universal modular Accelerator Interface 在现有和单独的TVM BYOC、算子策略、算子调度、特定目标Pass和特定目标代码生成扩展点的基础上增加了一层。Collage目前仅依赖于全局模式注册表和全局relay.ext.<toolchain>函数来与BYOC集成。
3.2 Collage的优缺点
1)Collage的优点:
- 延迟:与TVM原生、具有单个partition_for_<toolchain>调用的TVM或TensorRT等非TVM独立编译器相比,整体模型延迟可能会减少。
- 自动化:可以自动选择启用哪些BYOC工具链。
- 实现的经济性和模块化:以前分割需要MergeComposite/AnnotateTarget/MergeCompilerRegions/ PartitionGraph四个Pass,现在可以用一个CollagePartitioner替代
- Collage在标准ONNX和NVIDIA硬件选择延迟上做到了10%的提升
- Collage不需要独立于BYOC单独为每个新硬件或模型创建pattern
- 相较于直接使用现有的partition_for_<toolchain>函数,多BYOC工具链,多Target的Collage效果不会太差。
2)Collage的缺点:
- 需要一些BYOC模板上的改变:TVM当前的BYOC集成接口将需要“lowering/codegen”函数注册到全局函数名,其他的就取决于BYOC开发者了。而Collage要求基于pattern的BYOC集成将他们自己的pattern注册到全局pattern表中。并且Collage要求BYOC lowering函数能生成一个可用的runtime::Module并且不需要任何额外的Pass。Collage还需要BYOC集成能正确判断那些算子是pattern支持的或者在候选kernel中遇到不支持的算子能优雅地传播错误而非简单检查错误。
- 非组合的BYOC工具链:BYOC分割函数通常运行全局pass将Relay计算图转化为一个更好对齐工具链的状态。一般假设这些分割pass是专属的,可以划归为全局配置或者划归为BYOC lowering/codegen函数或者划归为运行在CollagePartitioner之前的标准Relay优化pass。
- 较高的调优损失:很明显,Collage需要评估分割结果的延时。因为TVM会对新的kernel触发调度调优过程,这会尝试上千次试验,花费近几个小时,因此需要调优日志减缓时间开销。
- 任务提取VS调优:传统TVM有三个阶段,1)提取任务,即找到融合的子图以调优,2)调优,即为这些子图找到好的调度,3)编译,重新编译模型,从缓存中为所有选择的子图检索调度。但在Collage的第二版实现中将三个阶段进行折叠,把重点放在了评估候选项和调优的损失上,因为这些会影响最终的分割结果。
- 没有非局部的优化:尽管Collage可以左右子图或者工具链的选择,但他无法影响子图的参数或者结果,也无法改动IRModule。比如,Collage无法用来搜索layout的参数,内存的范围以及量化范式的选择。
- 依赖管理:目前,BYOC集成倾向于假设它们是唯一使用的非TVM工具链。因此,两个工具链可能会引入无法满足的运行时依赖关系。Collage没有依赖或不兼容的概念,并且可能会试图融合在生产中无法支持的候选内核。
- 可加性损失假设:根据这种设计,Collage假设运行候选分区的成本是累加的,再加上一个小的转换损失。然而,缓存耗时可能会主导测量的延迟,特别是对于“轻量级”内核。
- 搜索空间受限:遍历所有子图的复杂度是O(n!),所以需要限制搜索。最简单的方法就是将候选对象限制在只有几个运算符的子图中。这可能意味着在没有探索到更快的候选者时已经产生了具有高最优性损失的分区。
- 脆弱的工具链:一些BYOC工具链本身就是独立的编译器,已经针对常见模型进行了调整,并包含全局标志来指导降低精度等优化。然而,Collage只会为这些工具链提供较小的子图,从而使有限的搜索空间问题更加严重。
- 轻量级内核中的高方差:小内核可能具有高方差,因此使用哪个工具链的选择可以是任意的。我们可能想i)验证我们的方差估计器是否准确,ii)为估计的候选内核延迟选择一个略高于50%的百分位数,iii)当测量的方差太高时,退回到硬编码的优先级。
- 可解释性:向用户显示每个内核的最终分区和估计时间很容易,但很难说明为什么在搜索过程中分区会胜过其他所有分区。
- 不包含partition_for_<toolchain>:我们没有任何计划来弃用每个提供partiion_for_<toolchain>函数的BYOC集成的现有模式。如果用户心中有一个特定的工具链,那么显式地创建分区既可以加快编译速度,又可以包含Collage目前无法解释的全局优化过程(例如强制执行特定的布局)。
3)TVM目前的特点:
- 贪心:只支持分割尽可能最大的子图,不考虑时间代价。而Collage可以探索更多子图,在混合工具链中,两个小子图可能比一个大子图整体时延更低。
- 手动:目前,TVM用户必须提交到BYOC工具链,并在主TVM编译流开始之前调用相应的partition_for_<toolchain>函数。使用Collage,可以根据测量的延迟自动选择工具链。Collage还将探索多个BYOC工具链以及TVM原生后端之间的混合和匹配。
3.3 早期的函数库集成
TVM有两种不同的方式使用外部内核库即pattrn-based的BYOC方法和TVM的te.extern方法。
基于pattern的方法允许函数库中的实现匹配一个或多个relay算子。比如在dnnl的实现中,pattern标签与对应的dnnl函数实现相匹配,代码位于python/tvm/relay/op/contrib/dnnl.py,用户只需要调用MergeComposite/AnnotateTarget/PartitionGraph实现分割即可。注意,这里没有方便的parition_for_dnnl函数。src/relay/backend/contrib/dnnl/codegen.cc中的BYOC函数relay.ext.dnnl会在全部的“Primitive”函数中调用“Composite”函数并基于“Composite”标签分发函数。C代码会映射到DNNL库中并调用标准C编译器生成runtime::Module。
对于TVM生成的内核函数是无法按照上述方法调用库函数的。事实上每个库函数都会具体调用到某个库中单个具体的kernel上,这些kernel也可以被多个库函数组合方式的调用。换句话说,TVM调用的外部库可以是直接调用单个kernel实现功能,也可以是将外部库的kernel作为TVM调用的函数的一部分。
te.extern方法只允许库函数实现和relay 算子一一对应。但是这些库可以作为TVM生成的大的kernel的一部分,常规的TVM调优策略可能会基于性能选择库。举个例子,算子batch_matmul可以采用python/tvm/contrib/cublas.py中的策略,通过CuBLAS实现。当Target的libs属性中出现cublas,代码python/tvm/relay/op/strategy/cuda.py中的策略batch_matmul_stategy_cuda就会被激活,该策略会简单调用src/runtime/contrib/cublas/cublas.cc中的PackedFunc函数tvm.contrib.cublas.batch_matmul作为TVM runtime的一部分。te.extern方法也支持集成微内核作为大relay算子TVM调度的一部分。
Collage可以和上述任何一种方法搭配。对于基于pattern的BYOC方法,Collage只需要带有匹配编译器属性的Target即可。对于te.extern方法,Collage同样不需要了解TVM分割会生成一个调度中包含链接库调用的内核,只需要确保Target有适当的libs属性即可。
为了确保Collage能无缝集成库函数,需要满足几点:
需要支持匹配子图的库函数同时也要支持单个relay算子且允许在TVM生成的kernel中被调用的库函数
- 避免对全量BYOC模板的需求,但保留BYOC类似的pattern机制
- 用选择分割方式相同的方式选择外部函数库
一种可能的方式:
- 类似于te.extern,函数库可以通过注册PackedFunc方式在TVM runtime中使用
- 类似于pattern-based BYOC,标记的pattern可用于指定;relay算子如何映射到注册的PackedFunc中
- 类似于BYOC自定义降阶策略,当外部函数库可用时通过编译器名按照不同路径降阶
- 不同于BYOC自定义降阶策略,对外部函数调用的重写可以在TE或者TIR中进行,这样可以整合到更大的TVM kernel中。
3.4 引导级解释
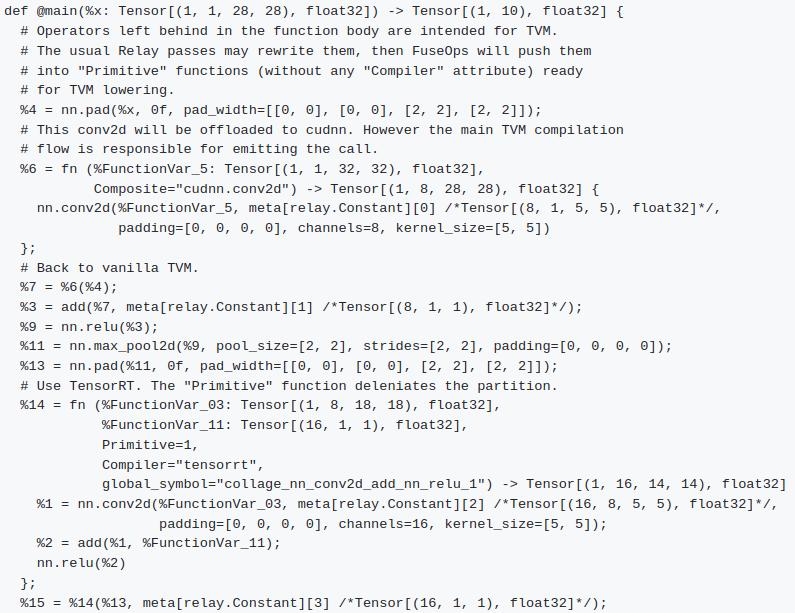
Collage允许自动选择BYOC工具链的分割以减小整体模型执行延迟。为了在编译过程中使用Collage,需要在PassContext中添加标签并在构建过程中引入Collage感知的target参数。如下,可以在编译时用一系列NVIDIA的工具链或者库。

对于模型

经过CollagePartitioner Pass后,原来的全局函数main变为如下形式

3.5 引用级解释
Collage的实现主要在src/relay/collage/目录下,tvm::relay::collage命名空间下,一小部分python帮助函数在python/tvm/relay/collage目录下。如果PassConfig的relay.collage.enable_collage属性为true,在所有Pass之前使用CollagePartitioner Pass,最终结果是所有全局函数中所有要在BYOC工具链处理的Relay子图会被一个内联的、带有Compiler和global_symbol属性的Primitive函数调用所替换。对于要传递到特定库或者BYOC支持的函数上的Relay算子或者算子组,会被一个内联的Composite函数调用替换掉。
CollagePartitioner四个阶段:
阶段一:扫描可用Target,构建一组可以描述如何找到可能分区的规则。涉及类:PartitionSpec和PartitionRule。
阶段二:为全局函数构建数据流图(对应类IndexedGraph<Expr>)。阶段一中的规则会在数据流图中匹配一遍,为每个target生成一组候选分割方案(对应类CandidatePartition),每个候选方案都可以高效描述全局函数中的一个子图。
阶段三:在搜索图中寻找最短损失路径。该搜索图中每个搜索节点对应数据流图中的一组被“覆盖”的数据流节点,这些节点被分配到了从起始节点到当前节点的每条路径上的候选分区中。起始节点是指“覆盖”集是空的的搜索节点。结束节点是指“覆盖”集合中包含所有数据流节点的搜索节点。
搜索边X->Y:候选分区P与X的“覆盖”节点没有交集,Y的“覆盖”节点是X和P的并集。为避免不必要的搜索空间拓展,后选集必须包含X中下一个还未被覆盖的数据流节点。
边损失:候选分区的评估延时加分区传输延迟。需要注意的是,尽管需要能够提取候选子图构建函数以评估,但是没必要分割整个函数表达式。
阶段四:根据最短路径上的候选kernel分割函数体。该步骤和前三个阶段是独立的,也就是说可以在中间插入其他的优化过程。
3.5.1 核心数据结构
接下来先介绍重要的数据类型,然后再解释这些阶段。
Util Datatypes
PostDfsIndex:在整个Relay表达式后序dfs遍历中,Relay子表达式的整型索引。如果索引i小于索引j,则表示索引j表示的子表达式不能影响到索引i对应子表达式的值。
DataflowGraph:IndexedGraph<Expr>的别名,用于管理Relay ExprNode到PostDfsIndex到DataflowGraph::Node的三路双射关系。每个DataflowGraph::Node描述了子表达式的数据流输入、输出、指示器和反指示器。
IndexSet:PostDfsIndex索引的bit向量。用作数据流图中任意数据流节点集合的压缩表示。
Cost:一个双精度浮点数,表示候选分区的损失,平均执行延迟的秒数。Cost可以是Unkown(NaN)表示一些启发信息可以用于比较kernel损失。Cost可以是Invalid(inf)表示工具链不能编译,运行候选kernel。
SubGraph
一个SubGraph是整个数据流图的的任意子图内的所有数据流节点的PostDfsIndex的IndexSet。SubGraph和PartitionRule是Collage的核心数据类型。下图展示了数据流图、索引和一个微型MNIST的子图。
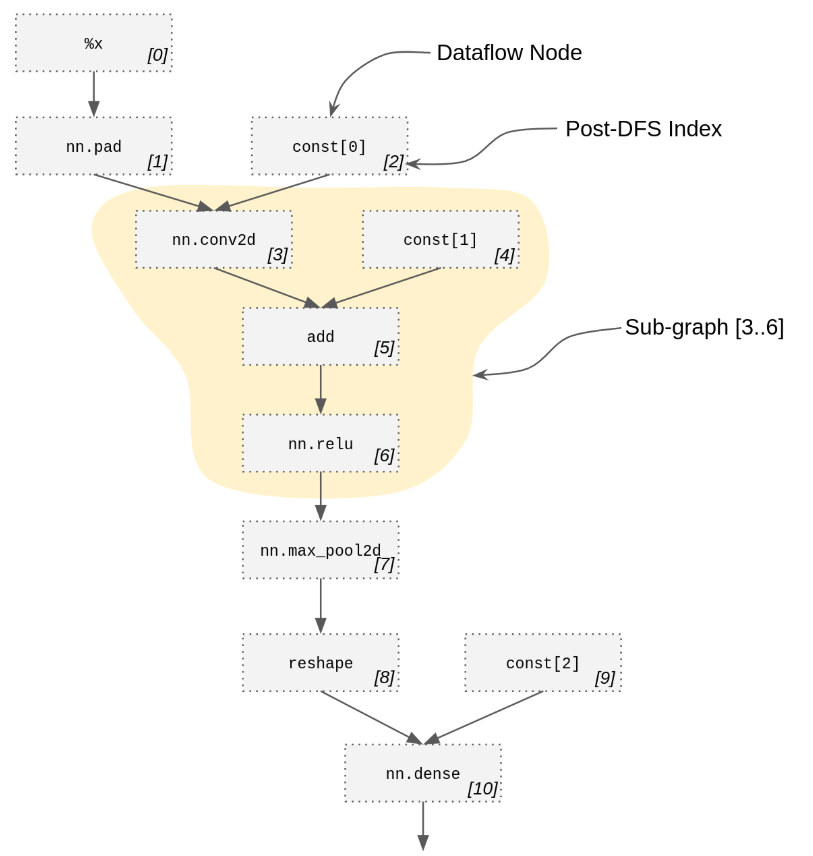
子图可以用于表示分区/内核/组合函数,不需要承担构建或者重写表达式的代价。我们需要提取一个函数用于从重写的整个Relay表达式中独立地评估一个分区或者内核的延迟,因为在Collage完成搜索后只需要一个小的候选分区子集。
一个子图会把整个表达式的每个数据流节点分类为子图内或子图外。很明显,不是所有分割都是对的,比如一个内部节点无法通过一个外部节点到达另一个内部节点。所以我们提供了IsValid方法用于检查合法性,提供SubGraphConfig用于控制使用那个合法的规则。
我们一般使用的是整个Relay表达式的DataflowGraph表示而不是表达式本身。我们使用后序深度优先遍历索引唯一地引用表达式节点。
除了“内部”和“外部”,我们还有四种其他类型的数据流节点,它们都是由“内部”节点唯一确定的:
“入口”节点是指内部至少有一个外部数据流输入的节点。
“退出”节点是指内部至少有一个外部数据流输出的节点,或者在底层数据流图中被视为“外部”的节点(例如,因为它们代表了整个函数的结果)。
“输入”节点是指外部至少有一个数据流输出的节点。
“输出”节点是指外部至少有一个数据流输入的节点。
有多个入口节点是有效的(我们可以为每个节点绑定一个参数)。有多个出口节点可能是有效的(我们可以构建一个所有这些出口节点的元组)。对于有助于其他内部节点的出口节点(即表示对中间结果的“点击”)可能是有效的。
子图会在如下条件下关闭:
- 不相交的并集
- 由具有给定属性的函数包装。这可用于对“Composite”函数进行编码,或在“Primitive”函数中表示候选内核。(通过将“包装”和“联合”结合起来,我们可以进行编码,例如,“这个子图应该放在一个原始函数内,这个原始函数本身可能会调用复合函数)。
- 替换,它允许一个子图相对于一个数据流图进行转换,以匹配另一个(通常较小)数据流图。
CandidatePartition
一个CandidatePartition对应一个SubGraph和Target。Collage的所有搜索和管理都是针对候选分区而言的。
PartitionRule
一个PartitionRule描述了如何为一个DataflowGraph找到一组CandidatePartitions。PartitionRule和SubGraph是Collage的核心数据类型。所有的分割规则都实现了如下方法:
virtual std::vector<CandidatePartition> AllCandidates(const DataflowGraph& dataflow_graph,const PartitionSpec& spec) const;
候选分区是允许折叠的,然后由Collage的搜索器找到一组可以覆盖完整Relay表达式但没有重叠的后选集。
目前有三种不同风格的分区:
- 对于基于pattern的BYOC集成,使用独立的DFPattern来选择Composite复合函数来卸载,这些函数会被分组到一个带有Complier属性的Primitive Relay函数中。
- 对于基于算子的BYOC集成,每个运算符名字表示要卸载的运算符,这些运算符又被分组到具有“Compiler”属性的“Primitive”Relay函数中。
- 对于TVM,显然所有Relay都可以进入一个分区,但是为了搜索效率,分区应该大致模仿Relay FuseOps。该过程在所有Relay运算符上使用“TOpPattern”(类型为OPPatternKind)属性,以及一种运算符何时可以折叠到另一种运算符的规则(通常是通过将标量运算符从元素运算符移动到较早运算符的输出位置)。这是作为一个独立的分析来实现的,它使用“Primitive”函数对结果进行编码。
为了便于外部库集成,我们想从基于模式的BYOC集成中借用DFPattern和复合函数方法。但是我们想把这些复合函数放在任何“Primitive”函数之外,这样库调用就可以在更大的TVM内核中结束。
类似于DFPattern提供的基础pattern规则和组合pattern规则,PartitionRule寻求相同的机制。新的基础pattern规则可以直接在数据流图上生成候选集;新的组合规则将找到的子规则组合为一组新的后选集合。下图展示了数据流图中一些base和combinator pattern。
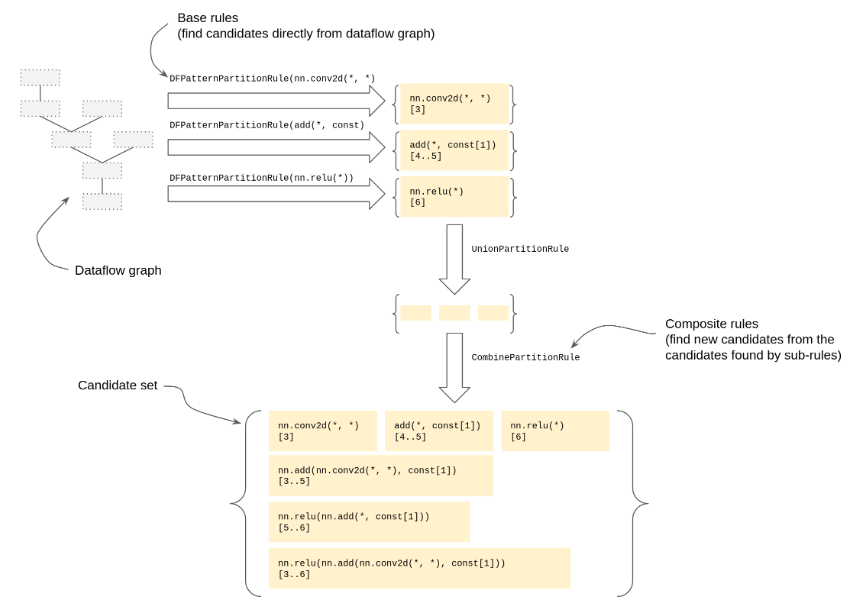
base rules是:
- DFPatternPartitionRule:给定一个DFPattern和表达式指示器,为每个匹配pattern和指示器的子图生成一个候选结果。不同于PatternRewriter,候选结果可以重叠。
- OpPredicatePartitionRule:给定一个属性名,为每个私有Relay算子生成一个候选结果。该算子要有匹配的属性并为给定的子表达式返回true。
- OpCallByKindPartitionRule:为每个Relay算子提供TOpPattern属性用于为每个对fusable Relay operator的调用生成候选结果。
combinator rules是:
- CompositePartitionRule:指示所有匹配子规则的子候选结果需要被一个"Composite"函数包裹。Composite的名字是rule的名字。用于指示Relay算子或算子组需要被映射到目标指定的算子上。
- PrimitivePartitionRule:指示所有匹配子规则的子候选结果需要被一个"Primitive"函数包裹,可能会带一个额外的"Compiler"属性。用于描述分区或内核。
- UnionPartitionRule:简单地合并来自所有sub-rules的子候选结果。用于组合单独的DFPatternPartitionRules。
- CombinePartitionRule:给定一个sub-rule和一组combiner rules,找到所有可能组合子候选结果的方式,生成更大的候选结果。需要注意的是子候选结果可能直接包含于结果中。combiner rules允许通过OpPatternKinds组合,将Relay算子调用的参数组合为元组。该规则旨在模拟TVM的FuseOps Pass,通过1)所有的候选结果都会被找到而非只有最大的那个;2)起始的候选结果可以被任何其他规则提供,3)依靠子图有效性检查来剔除不可行的候选者。
- OnlyValidPartitionRule:给定一个SubGraphConfig,忽略具有“无效”子图的候选者。用于限制最大候选深度、独立输出的数量以及是否允许中间“taps”。
- HostPartitionRule:为所有Relay表达式生成候选表达式,这些表达式可以“留下”供主机执行(例如在VM上)。这条规则让我们将特殊情况处理从核心搜索算法中转移到一条简单的规则中。
对于不同的分割场景,有一些经典的PartitionRules组合方式(这些组合可能是在phase1,检查Target和BYOC注册时生成的):
- 基于经典算子标识符的BYOC,联合AnnotateTarget/MergeCompilerRegions/PartitionGraph这些Pass(如tensorrt.py)。
PrimitivePartitionRule
OnlyValidPartitionRule
CombinePartitionRule (with a join-anything combiner rule)
OpPredicatePartitionRule- 经典基于pattern的BYOC,联合MergeComposite/AnnotateTarget/PartitionGraph passes (如cutlass.py)
PrimitivePartitionRule
OnlyValidPartitionRule
CombinePartitionRule (with join-anything combiner rule)
UnionPartitionRule
CompositePartitionRule(label1)
DFPatternPartitionRule(pattern1)
:
CompositePartitionRule(labeln)
DFPatternPartitionRule(patternn)
- CompositePartitionRule/DFPatternPartitionRule组合在pattern表中为每个实体重复出现
CompositePartitionRule(
rule_name="cutlass.conv2d_bias_residual_multiply_relu"
sub_rule=DFPatternPartitionRule(
pattern=CallPatternNode(Op(nn.relu),
[AltPattern(CallPatternNode(Op(multiply),
[CallPatternNode(AltPattern(Op(add) | Op(nn.bias_add)),
[CallPatternNode(Op(nn.conv2d), [*, *]), *]),
*]) |
CallPatternNode(Op(multiply),
[*,
CallPatternNode(AltPattern(Op(add) | Op(nn.bias_add)),
[CallPatternNode(Op(nn.conv2d), [*, *]), *])
]))
])))
- 考虑这些子表达式的库实现”,使用DFPatterns来挑选支持哪些Relay运算符
OnlyValidPartitionRule
CombinePartitionRule (with default TVM combiner rules)
UnionPartitionRule
OpCallByKindPartitionRule
CompositePartitionRule(lable1)
DFPatternPartitionRule(pattern1)
:
CompositePartitionRule(lablen)
DFPatternPartitionRule(patternn)- 经典TVM FuseOps
PrimitivePartitionRule
OnlyValidPartitionRule
CombinePartitionRule (with default TVM combiner rules)
OpCallByKindPartitionRule- 仅仅融合我让你融合的,使用DFPattern直接选择候选结果
PrimitivePartitionRule
OnlyValidPartitionRule
UnionPartitionRule
DFPatternPartitionRule(pattern1)
:
DFPatternPartitionRule(patternn)
PartitionSpec
一个PartitionSpec是由一个PartitionRule和一个或多个Target组成的。
1)Phase1:
我们基于TVM构建以支持异构设备。可用的Targets是使用CompilationConfig从编译配置信息中提取的。分析每个Target以确定如何构造一个PartitionRule,该规则会引导Collage为目标target选择候选kernels。
- 如果Target有“partition_rule”属性,直接使用即可。该方法允许用户直接控制分区或融合。
- 如果Target有“compiler”属性,并且全局pattern表中有该属性值对应实体,假设Target表示要对应pattern-based BYOC集成。PartitionRule会导入所有BYOC pattern并自动对应起来。如果全局pattern中没有对应实体,假设Target表示predicate-based BYOC集成如tensorrt,PartitionRule会搜索并分析谓词和所有Relay算子的“target.<compiler>”属性。
- 假设Target表示TVM原生target,PartitionRule会模仿Fuseps,但目前泛化到探索多个候选结果为可能的BYOC候选结果流出空间。
注意,为了确保该方法有效,我们需要多个Targets可以对应相同的DLDeviceKind。对于虚拟机,简单将target参数从字典结构转化为list并移除掉冗余的python预处理代码。用户可以使用on_device注释约束子图到具体的设备上。当Collage选择候选分区时,需要确保选择的候选Target是被PlanDevicesPass发掘的每条子表达式提纯过的Target。比如,给定targets T和U,我们定义如果T有“compiler”或/且“partition_rule”属性,U没有这些属性并且T和U在其他方面一致,则称T提纯(refine)U。
2)Phase2:
该阶段最难的工作是PartitionRule的实现AllCandidates。主驱动程序只需按最小“内部”PostDfsIndex对所有找到的CandidatePartitions进行索引,以便在最短路径搜索期间快速检索。
3)Phase3:
最自然的方法就是通过Dijkstra算法找到最优分区。一个SearchState就是搜索图上的一个节点,包含:
- 覆盖到当前状态的每条路径上的候选结果的数据流节点的一个IndexSet。这是识别状态的关键。
- 到当前状态的最优路径上的前一个SearchState
- 到当前状态最优路径的Cost,是Dijkstra优先队列的顺序
- 从上一个最优状态到当前状态转化的CandidatePartition
起始状态没有覆盖的节点,最终状态包含所有覆盖的节点。下图为mini MNIST搜索图中的一段:
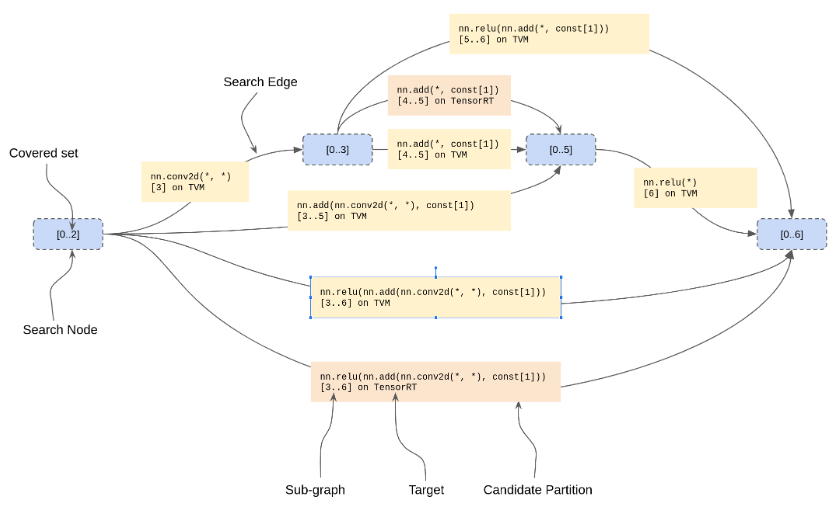
在扩展状态时,我们可以选择从Phase 2收集的任何CandidatePartition,只要它不与状态的覆盖集重叠。然而,应用候选C然后D的搜索路径等价于应用D然后C的搜索路径,因此我们只考虑与下一个尚未覆盖的数据流节点相交的候选。对于每个这样的候选,我们使用CostEstimator(带有假定的缓存)来获取候选的成本,构建后继状态,并以通常的方式“放松”后继状态。
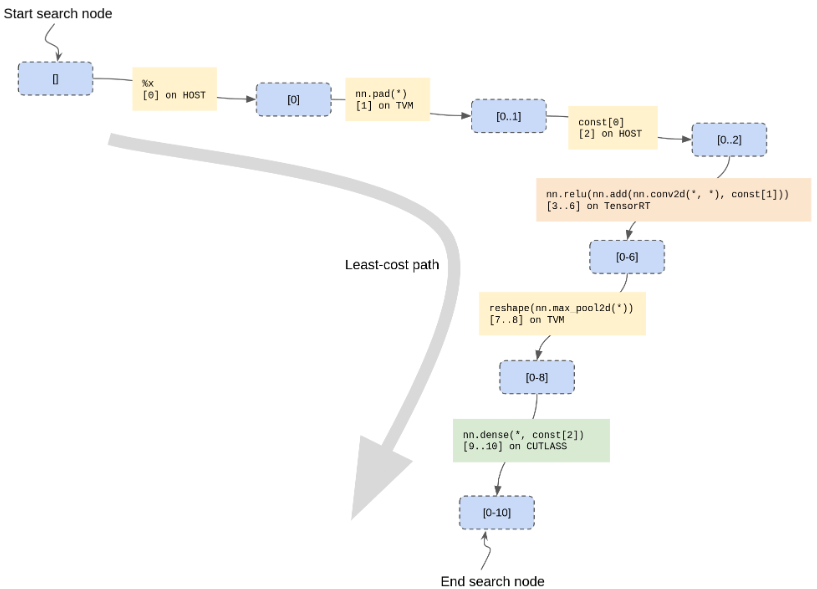
HostPartitionRule用于允许某些数据流节点“留下”供主机执行。此阶段的结果是一个Array<CandidatePartition>,如果需要,可以使用标准的TVM对象图机制对其进行物化和恢复。mini-MNIST示例的最低成本路径示例如下
4)Phase4:
整个Relay表达式在最低成本路径上的所有CandidatePartitions上“并行”分区。由于所有候选对象都是使用相对于原始数据流图的子图表示的,因此我们必须小心,不要在进行时使尚未分区的候选对象无效。按数据流顺序反向工作可以避免这个问题。
4 参考
[2111.00655] Collage: Seamless Integration of Deep Learning Backends with Automatic Placement
https://github.com/apache/tvm-rfcs/blob/main/rfcs/0062-collage.md




![Warcraft Logs [Classic] [WCL] BOSS ID query](https://i-blog.csdnimg.cn/direct/e0c3e10e590b44c8b94b0d5cac4131ce.png)