问题
提到【注册中心】,我们对它的基本功能,肯定可以顺手拈来,比如:【服务注册】【服务发现】【健康检查】【变更通知】等。
透过这些基本功能,一个普适的注册中心的数据结构应该如何设计呢?
可以结合着具体的业务场景来进行描述。
解析
【注册中心】除了【服务注册】、【服务发现】、【健康检查】和【变更通知】基本功能之外,还有一个很关键的功能,即:【服务订阅】。我们围绕着这些基本功能来设计一个普适的注册中心的数据结构,如下图:
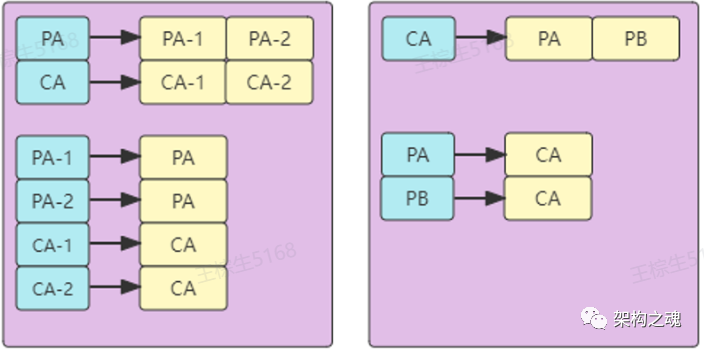
【注册中心】一种非常普适的数据结构是 【KList】,即 一个键值 Key 与一个列表 List 进行映射。
按图中举例:PA 和 PB 是服务提供方的服务名称,CA 是服务消费方的服务名称;PA 有两个服务节点,即 PA-1 和 PA-2, CA 有两个服务节点,即 CA-1 和 CA-2。
在【注册中心】的数据结构中,共包括四类【KList】结构:
-
服务与节点的映射关系,如:PA—>[PA-1, PA-2],CA—>[CA-1, CA-2];
-
节点与服务的映射关系,如:PA-1—>[PA],PA-2—>[PA],CA-1—>[CA],CA-2—>[CA];(此类数据的List的长度是1)
-
订阅关系映射,如:服务CA订阅了服务PA和PB, CA—>[PA, PB];
-
被订阅关系映射,如:PA—>[CA], PB—>[CA]。
此四类【KList】数据可以完成【注册中心】所有功能:
1. 服务节点注册:在服务节点启动时,需要将自己的信息注册到【注册中心】,此时需要对 “服务与节点的映射关系” 结构 和 “节点与服务的映射关系”结构进行维护;可能有同学会疑惑,为什么要维护 “节点与服务的映射关系” 呢?这是因为在 服务节点注销的时候,没有这类数据的话很难定位到此节点是哪一个服务。
2. 服务发现:在服务调用方节点 询问【注册中心】目标服务有哪些服务节点在运行时,此时【注册中心】直接对 “服务与节点的映射关系” 进行遍历即可。
3. 服务订阅:服务调用方在对服务提供方发起 RPC 调用之前,需要进行订阅,此时需要对 “订阅关系映射” 结构和 “被订阅关系映射” 结构进行维护;“订阅关系映射” 为 【服务发现】提供了基础元数据;“被订阅关系映射” 为变更通知提供了数据查询的桥梁。
举一个例子:当服务提供方节点 PA-2 宕机之后,注册中心是如何基于这个底层的数据结构采取一系列动作呢?
-
首先,注册中心通过心跳算法,判断 PA-2节点已经失活;
-
然后,根据 “节点与服务的映射关系” PA-2—>[PA],获取失活节点属于 PA服务;
-
继续,根据 “被订阅关系映射”,PA—>[CA],获取 PA 服务的订阅服务是 CA 服务;
-
之后,根据 “服务与节点的映射关系”,CA—>[CA-1, CA-2],获取 CA 服务有两个服务节点,即:CA-1 和 CA-2;
-
最后,注册中心将 变更通知数据 发送给 CA-1 节点 和 CA-2 节点。
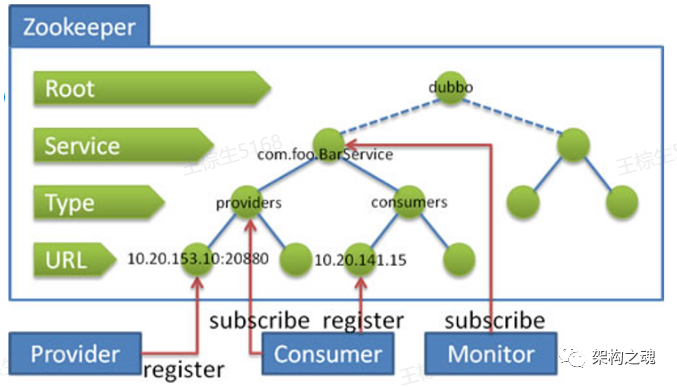
【KList】是 根据注册中心抽象出来的一个非常普适性的 数据结构,在具体落地时,可以通过 MySQL关系表实现,也可以通过 Redis 的 List实现,也可以在内存中根据不同的业务场景具体落地成不同的数据结构进行实现。比如大名鼎鼎的 Zookeeper 是通过 【Tree】的方式进行的实现,如下图;大家可以自行分析一下,Zookeeper是如何通过【Tree】结构实现的【KList】的所有基础功能。