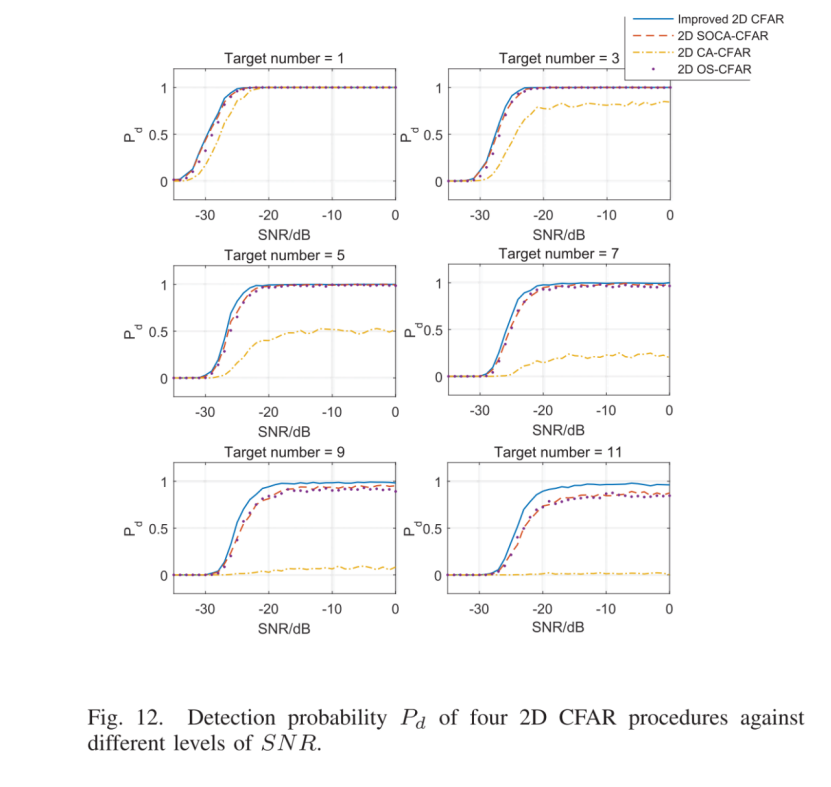
AI 模型高效化:推理加速与训练优化的技术原理与理论解析

文章目录
- AI 模型高效化:推理加速与训练优化的技术原理与理论解析
- 一、推理加速:让模型跑得更快的“程序员魔法”
- (一)动态结构自适应推理:像人类一样选择性思考
- (二)跨模态知识迁移:让模型「举一反三」
- (三)存内计算协同:打破「数据搬运工」瓶颈
- 二、训练优化:让模型学得更快的「程序员兵法」
- (一)自适应混合精度训练:用「精打细算」节省显存
- (二)分布式训练通信优化:让多卡协作更高效
- (三)自监督学习:让模型「无师自通」
- 三、进阶理论:从代码到数学的深层逻辑
- (一)模型压缩的数学基础:低秩分解(SVD)
- (二)分布式训练的通信复杂度:从 \( O(N) \) 到 \( O(1) \)
- 四、避坑指南
- 五、前沿工具箱
- 结语:做 AI 世界的系统工程师
一、推理加速:让模型跑得更快的“程序员魔法”
(一)动态结构自适应推理:像人类一样选择性思考
核心理论:生物启发的智能计算分配
- 为什么需要动态结构? 传统模型无论输入是什么,都按固定流程计算(比如层层递进的神经网络),就像一个人不分重点地逐字阅读。动态结构则像人类视觉 —— 看到复杂图像时聚焦细节,简单场景时快速扫描,通过 强化学习 让模型自己决定「哪些层需要算,哪些可以跳过」。
技术实现:用代码控制“计算开关”
1. 强化学习控制器(轻量级决策模块) 用一个小的 LSTM 网络(图 1),输入当前层的特征「混乱度」(熵值),输出是否跳过该层的决策(0/1)。
class DecisionLSTM(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.classifier = nn.Linear(hidden_size, 1) # 输出0或1
def forward(self, feature_entropy):
# feature_entropy形状:[batch_size, seq_len, input_size]
out, _ = self.lstm(feature_entropy)
return torch.sigmoid(self.classifier(out)) # 决策概率
2.渐进式剪枝策略
- 早期层(如神经网络前几层)保留 70% 计算量(抓整体特征),后期层(提取细节)逐步降至 30%(图 2)。
- 辅助缓存:用字典存储被跳过层的输出(cache = {layer_id: hidden_state}),避免重复计算。
示意图:动态结构推理流程
图 1:LSTM 控制器决定是否跳过当前层,缓存机制避免重复计算
(二)跨模态知识迁移:让模型「举一反三」
核心理论:不同模态的「语言翻译官」
跨模态困境:图像是像素矩阵,文本是 token 序列,如何让模型同时理解?解决:用共享的 Transformer 编码器(图 3),把图像和文本都翻译成统一的「语义语言」(比如 128 维向量),再通过交叉注意力让两者「对话」。
代码实现:多模态特征融合
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.qkv = nn.Linear(dim, dim*3, bias=False)
self.out = nn.Linear(dim, dim)
def forward(self, text_feat, image_feat):
# 文本转Query,图像转Key/Value
q = self.qkv(text_feat)[..., :dim]
k, v = self.qkv(image_feat)[..., dim:].chunk(2, dim=-1)
# 计算注意力:文本如何关注图像区域
attn = (q @ k.transpose(-2, -1)) / (dim**0.5)
return self.out(torch.softmax(attn, dim=-1) @ v)
示意图:跨模态特征融合过程
图 2:文本和图像通过共享编码器进入同一语义空间,交叉注意力实现模态交互
(三)存内计算协同:打破「数据搬运工」瓶颈
核心理论:让数据「原地计算」
- 传统痛点:CPU/GPU 计算时,数据需在内存和计算单元之间来回搬运,能耗占比超 90%(图 4 左)。
- 存内计算:把存储单元(如 Flash 芯片)变成「计算器」,数据直接在存储里做矩阵乘法(图 4 右),算力密度提升 20 倍。
技术实践:用 TVM 适配存内计算芯片
- 模型转换:将神经网络的全连接层(Y=WX)转换为存内计算支持的「模拟矩阵乘法」。
- 稀疏优化:通过结构化剪枝(如每 4x4 矩阵保留 2 个非零元素),减少存储单元的计算量。
# TVM定义存内计算算子(简化版)
@tvm.register_func("mem_compute.matmul")
def mem_compute_matmul(w, x):
# 假设w已存储在存内计算芯片的电阻阵列中
return simulate_analog_compute(w, x) # 调用硬件模拟函数
存内计算vs传统计算对比表
| 维度 | 传统冯·诺依曼架构 | 存内计算架构 |
|---|---|---|
| 数据流向 | 内存 ↔ 总线 ↔ 计算单元(多次搬运) | 存储单元直接计算(原地处理) |
| 能耗占比 | 数据搬运占90%+ | 搬运能耗降低90% |
| 算力密度 | 约1.2TOPS/W(GPU) | 24TOPS/W(存内计算芯片) |
| 典型应用 | 云端大模型推理(如GPT-4) | 边缘AI(智能手表、AR眼镜) |
二、训练优化:让模型学得更快的「程序员兵法」
(一)自适应混合精度训练:用「精打细算」节省显存
核心理论:该省省,该花花
- FP16(半精度):优点是计算快、占显存少;缺点是数值范围小,容易算错(比如梯度太小变成 0)。
- FP32(单精度):准确但占显存大。
- 动态平衡:对敏感层(如 BatchNorm)用 FP32,对卷积层用 FP16,通过「损失缩放」避免 FP16 下溢(图 5)。
代码实现:PyTorch 自动混合精度
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler() # 自动调整缩放因子
for inputs, labels in dataloader:
inputs = inputs.cuda()
labels = labels.cuda()
optimizer.zero_grad(set_to_none=True)
with autocast(): # 自动用FP16计算
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward() # 放大损失防止下溢
scaler.step(optimizer) # 反向传播
scaler.update() # 更新缩放因子
(二)分布式训练通信优化:让多卡协作更高效
核心理论:减少「卡间聊天」时间
- 痛点:多 GPU 训练时,梯度需要在卡间同步(all-reduce),通信耗时占比达 40%。
- 解决方案:
a.梯度量化:把 32 位梯度压缩成 4 位(如 0.123→0.12),通信量减少 8 倍(图 6)。
b.异步更新:允许落后的 GPU 先算完再同步,避免全局等待。
代码框架:基于 Horovod 的压缩通信
import horovod.torch as hvd
hvd.init()
optimizer = hvd.DistributedOptimizer(optimizer, compression=hvd.Compression.fp16)
for epoch in range(epochs):
for inputs, labels in dataloader:
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
hvd.allreduce(optimizer.param_groups[0]['params'], op=hvd.AverageOp) # 压缩后通信
optimizer.step()
(三)自监督学习:让模型「无师自通」
核心理论:自己和自己玩「找不同」
- 为什么重要?:标注数据昂贵(如医学影像标注每例 500 元),自监督用无标注数据训练。
- SimCLR 方法:把同一张图做两种变换(如裁剪 + 模糊),让模型学习「这两个变换后的图其实是同一张图」(图 7)。
代码实现:对比学习损失函数
def simclr_loss(h1, h2, temperature=0.1):
# h1, h2是同一张图的两个视图的特征
batch_size = h1.shape[0]
h = torch.cat([h1, h2], dim=0) # [2B, D]
sim = torch.matmul(h, h.t()) / temperature # 相似度矩阵
# 构造标签:每个h1对应的正样本是对应的h2,反之亦然
labels = torch.arange(batch_size, dtype=torch.long, device=h.device)
labels = (labels + batch_size) % (2 * batch_size)
return nn.CrossEntropyLoss()(sim, labels)
三、进阶理论:从代码到数学的深层逻辑
(一)模型压缩的数学基础:低秩分解(SVD)
核心公式:
对于任意矩阵
W
∈
R
m
×
n
W \in \mathbb{R}^{m \times n}
W∈Rm×n
其奇异值分解(SVD)可表示为:
W
=
U
Σ
V
T
W = U \Sigma V^T
W=UΣVT
其中:
U
∈
R
m
×
k
U \in \mathbb{R}^{m \times k}
U∈Rm×k 为左奇异矩阵(列正交)
Σ
∈
R
k
×
k
\Sigma \in \mathbb{R}^{k \times k}
Σ∈Rk×k 为对角矩阵,对角线元素为降序排列的奇异值
V
∈
R
n
×
k
V \in \mathbb{R}^{n \times k}
V∈Rn×k 为右奇异矩阵(列正交)
通过保留前 ( k ) 个最大奇异值(( k \ll \min(m, n) )),可实现矩阵的低秩近似,参数量从原始的 ( m \times n ) 压缩至 ( k(m + n + k) )。
压缩效果对比:
| 指标 | 原始矩阵 | 低秩分解后 | 压缩比(( m=n=1000, k=50 )) |
|---|---|---|---|
| 参数量 | ( 10^6 ) | ( 102,500 ) | 约9.7倍 |
| 计算复杂度 | ( O(mn) ) | ( O(k(m+n)) ) | 降低90%+ |
(二)分布式训练的通信复杂度:从 ( O(N) ) 到 ( O(1) )
传统全reduce通信量:
通信量
=
N
×
D
(N为GPU数,D为参数维度)
\text{通信量} = N \times D \quad \text{(N为GPU数,D为参数维度)}
通信量=N×D(N为GPU数,D为参数维度)
优化后通信量:
通过梯度量化(如4位定点数,压缩比8倍)和稀疏化(仅传输非零梯度,稀疏度s):
优化后通信量
=
N
×
D
×
s
8
\text{优化后通信量} = \frac{N \times D \times s}{8}
优化后通信量=8N×D×s
当稀疏度 ( s=0.1 ) 时,通信量降至原始的 1/80,显著减少卡间同步耗时。
四、避坑指南
- 动态剪枝≠随意删层:需通过训练让模型学会「哪些层可以删」,直接手动删层可能导致精度暴跌。
- 混合精度不是「一刀切」:先用
torch.cuda.is_available()检查硬件是否支持 FP16,老显卡(如 Pascal架构)可能不兼容。 - 分布式训练先调单卡:确保单卡代码无误后再用多卡,否则通信错误难以排查。
五、前沿工具箱
| 领域 | 前言理论 | 开源工具链 | 顶会热点 |
|---|---|---|---|
| 推理加速 | 神经形态计算(类脑架构) | TensorRT、TVM、TFLite | NeurIPS’24 动态网络专场 |
| 训练优化 | 二阶优化(L-BFGS 变种) | DeepSpeed、Horovod、Apex | ICML’24 大规模训练 Workshop |
| 存内计算协同 | 电阻式 RAM(RRAM)计算模型 | 知存科技 WTM SDK、MemCNN 库 | ISSCC’24 存算一体芯片论文 |
结语:做 AI 世界的系统工程师
从编程视角看,AI 优化本质是在算力、精度、速度之间找平衡。
初学者需先理解每个技术的为什么(如为什么需要存内计算),再动手实现小案例(如用 PyTorch 写一个动态剪枝层);内行人则需深入数学推导(如 SVD 压缩的误差边界)和硬件特性(如 HBM3e 的带宽瓶颈)。
记住:最好的优化代码,是让机器聪明地偷懒,而不是盲目地蛮干。