#记录工作
CosyVoice 是由 FunAudioLLM 团队开发的一个开源多语言大规模语音生成模型,提供了从推理、训练到部署的全栈解决方案。
项目地址:
https://github.com/FunAudioLLM/CosyVoice.git
该项目目前从v1.0版本迭代到v2.0版本,但是在Windows中的部署多半情况下并不会顺利。因为项目依赖的很多包在windows系统上的适配性并不好,比如:
pynini
ttsfrd
Matcha-TTS
WeTextProcessing等包,我分别通过python310、python311、python312三种虚拟环境部署,效果不是很满意,
所以,建议还是使用WSL或者Docker部署,
因为这起码在网络通畅的情况下不会遭遇一些奇怪的报错输出。
先上结果:
以下是通过Docker部署CosyVoice V2.0的记录:
(.venv) F:\PythonProjects\CosyVoice\runtime\python git:[main] docker build -t cosyvoice:v2.0 .
[+] Building 1158.5s (13/13) FINISHED docker:desktop-linux
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 768B 0.0s
=> [internal] load metadata for docker.io/pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime 0.3s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/9] FROM docker.io/pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime@sha256:82e0d379a5dedd6303c89eda57bcc434c40be11f249ddfadfd5673b84351e806 0.0s
=> => resolve docker.io/pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime@sha256:82e0d379a5dedd6303c89eda57bcc434c40be11f249ddfadfd5673b84351e806 0.0s
=> CACHED [2/9] WORKDIR /opt/CosyVoice 0.0s
=> CACHED [3/9] RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list 0.0s
=> CACHED [4/9] RUN apt-get update -y 0.0s
=> CACHED [5/9] RUN apt-get -y install git unzip git-lfs g++ 0.0s
=> CACHED [6/9] RUN git lfs install 0.0s
=> [7/9] RUN git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git 32.0s
=> [8/9] RUN cd CosyVoice && pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com 779.2s
=> [9/9] RUN cd CosyVoice/runtime/python/grpc && python3 -m grpc_tools.protoc -I. --python_out=. --grpc_python_out=. cosyvoice.proto 0.6s
=> exporting to image 343.6s
=> => exporting layers 302.9s
=> => exporting manifest sha256:06b7276ad763946f8db509d077a1475916067228c8b61f244cc20a5ef876f341 0.0s
=> => exporting config sha256:d72dd119f99b66b0ce4e0325cc653b143e3001a5a7496c3666de8cf44d7b71c4 0.0s
=> => exporting attestation manifest sha256:8e195ae249a98138698b38b9d4284b5d0797e74782287fefa459d868be056791 0.0s
=> => exporting manifest list sha256:9be1dd1c1b03e833be844595847b6d59df3e63853713f04f8a9cd0db5a303b0a 0.0s
=> => naming to docker.io/library/cosyvoice:v2.0 0.0s
=> => unpacking to docker.io/library/cosyvoice:v2.0 40.6s
View build details: docker-desktop://dashboard/build/desktop-linux/desktop-linux/uifq2oi2pl4uuxr7sosu7nnqs 
(.venv) F:\PythonProjects\CosyVoice\runtime\python git:[main] docker run -d --runtime=nvidia -p 50000:50000 cosyvoice:v2.0 /bin/bash -c "cd /opt/CosyVoice/CosyVoice/runtime/python/grpc && python3 server.py --port 50000 --max_conc 4 --model_dir iic/CosyVoice-300M && sleep infinity"
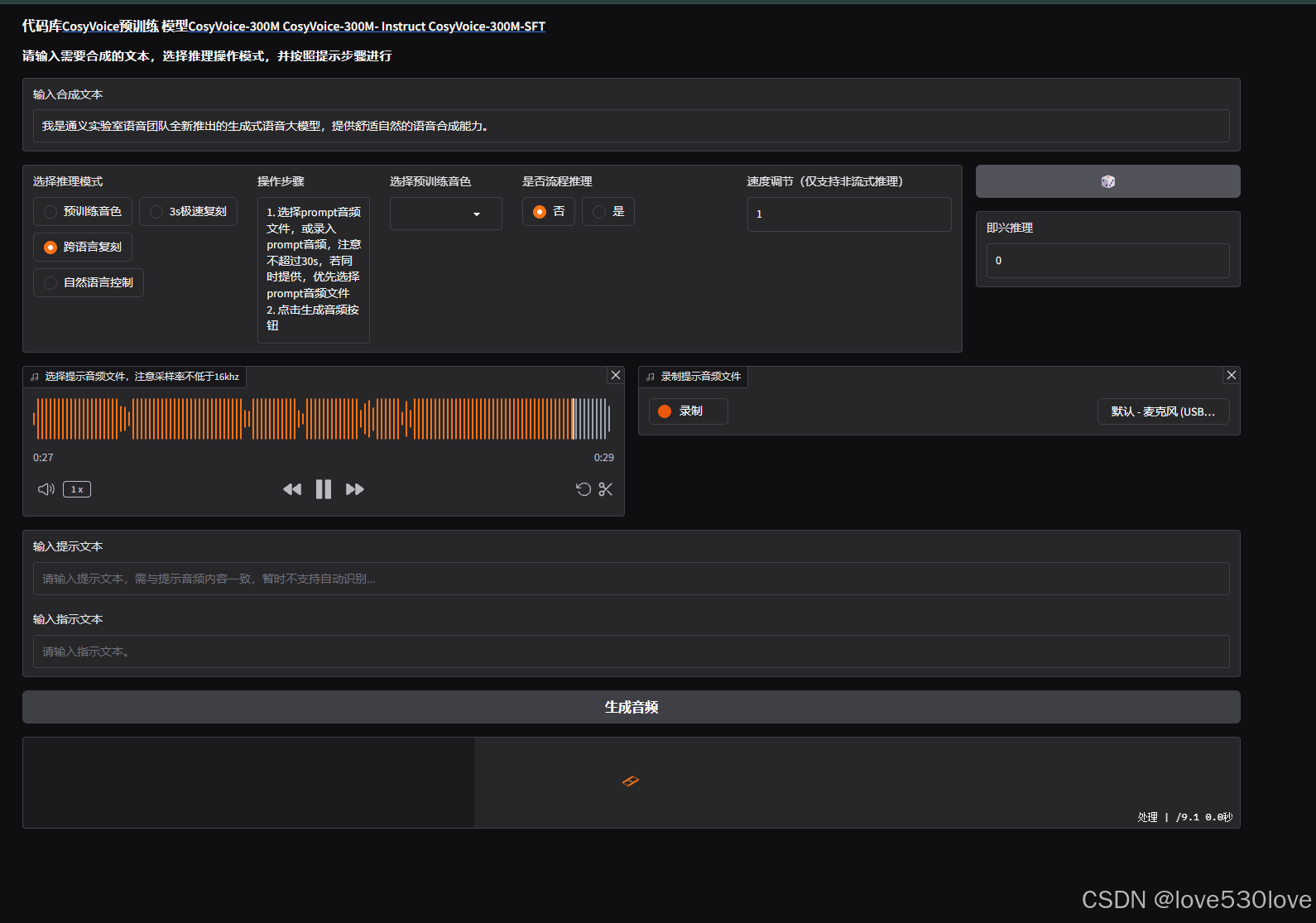
97b59dd3d047792b0649da7e768b15d022bb6f64e188d54e2fb14d0aa1e42295访问http://localhost:50000 可以看到,整个过程还是比较顺利,没有了手动解决依赖的烦恼。
可以看到,整个过程还是比较顺利,没有了手动解决依赖的烦恼。
以下是通过Docker部署CosyVoice V2.0的详细步骤:
项目官方主页里有Docker部署教程,不过是部署V1.0版本的命令,要部署V2.0版本需要修改下版本号再行部署
1、启动Docker容器,启动稳定后待命;
2、克隆存储库
#克隆项目到本地
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
3、进入项目目录
#进入项目目录
cd CosyVoice
4、初始化并更新所有子模块
#初始化并更新所有子模块
git submodule update --init --recursive5、进入Docker文件所在目录
进入Docker文件所在目录
cd runtime/python6、运行 Docker命令构建容器
docker build -t cosyvoice:v2.0 .7、下载模型
在项目目录下新建一个.py文件并命名为“python download_models.py”,然后粘贴以下代码:
#命名为:
python download_models.py该文件内容如下:
from modelscope import snapshot_download
snapshot_download('iic/CosyVoice-300M', local_dir='pretrained_models/CosyVoice-300M')
snapshot_download('iic/CosyVoice-300M-SFT', local_dir='pretrained_models/CosyVoice-300M-SFT')
snapshot_download('iic/CosyVoice-300M-Instruct', local_dir='pretrained_models/CosyVoice-300M-Instruct')
snapshot_download('iic/CosyVoice-ttsfrd', local_dir='pretrained_models/CosyVoice-ttsfrd')
然后运行该python download_models.py文件来自动下载模型,等全部模型下载完毕后,可以启动容器以运行CosyVoice声音克隆。
8、镜像构建完成后运行容器
英伟达显卡用户:
docker run -d --runtime=nvidia -p 50000:50000 cosyvoice:v2.0 /bin/bash -c "cd /opt/CosyVoice/CosyVoice/runtime/python/grpc && python3 server.py --port 50000 --max_conc 4 --model_dir iic/CosyVoice-300M && sleep infinity"
非NVIDIA用户请看第9条中的命令
9、浏览器访问
http://localhost:5000010、相关命令注解
# 进入包含Dockerfile的目录
cd runtime/python
# 使用当前目录下的Dockerfile构建一个名为cosyvoice:v2.0的Docker镜像
docker build -t cosyvoice:v2.0 .
# 如果你想使用instruct推理模式,将iic/CosyVoice-300M改为iic/CosyVoice-300M-Instruct
# 使用grpc方式运行服务
# 在后台运行一个Docker容器,使用NVIDIA运行时,将容器的50000端口映射到宿主机的50000端口
# 容器中运行的命令会启动一个gRPC服务器,端口为50000,最大并发数为4,模型目录为iic/CosyVoice-300M
docker run -d --runtime=nvidia -p 50000:50000 cosyvoice:v2.0 /bin/bash -c "cd /opt/CosyVoice/CosyVoice/runtime/python/grpc && python3 server.py --port 50000 --max_conc 4 --model_dir iic/CosyVoice-300M && sleep infinity"
# 进入grpc目录并运行客户端进行测试
cd grpc && python3 client.py --port 50000 --mode <sft|zero_shot|cross_lingual|instruct>
# 使用fastapi方式运行服务
# 在后台运行一个Docker容器,使用NVIDIA运行时,将容器的50000端口映射到宿主机的50000端口
# 容器中运行的命令会启动一个FastAPI服务器,端口为50000,模型目录为iic/CosyVoice-300M
docker run -d --runtime=nvidia -p 50000:50000 cosyvoice:v2.0 /bin/bash -c "cd /opt/CosyVoice/CosyVoice/runtime/python/fastapi && python3 server.py --port 50000 --model_dir iic/CosyVoice-300M && sleep infinity"
# 进入fastapi目录并运行客户端进行测试
cd fastapi && python3 client.py --port 50000 --mode <sft|zero_shot|cross_lingual|instruct>
命令解释
• `cd runtime/python`:
切换到包含Dockerfile的目录。
• `docker build -t cosyvoice:v2.0 .`:
基于当前目录下的Dockerfile构建一个新的Docker镜像,标签为`cosyvoice:v2.0`。
• `docker run -d --runtime=nvidia -p 50000:50000 cosyvoice:v2.0 ...`:
运行一个Docker容器,使用NVIDIA运行时以便利用GPU加速,并将容器的50000端口映射到宿主机的50000端口。容器中运行的命令会启动一个服务(gRPC或FastAPI),并保持运行状态。
• `cd grpc && python3 client.py --port 50000 --mode ...`:
切换到grpc目录并运行客户端脚本,连接到本地运行的服务进行测试。
• `cd fastapi && python3 client.py --port 50000 --mode ...`:
切换到fastapi目录并运行客户端脚本,连接到本地运行的服务进行测试。
这些命令用于构建和运行一个语音合成服务的Docker容器,并通过gRPC或FastAPI接口进行测试。