题面链接Htlang/2025lqb_python_b
个人觉得今年这套题整体比往年要简单许多,但是G题想简单了出大问题,预估5+0+10+10+15+12+0+8=60,道阻且长,再接再厉
代码仅供学习参考,满分为赛后洛谷中的测评,蓝桥杯官方测评待完成
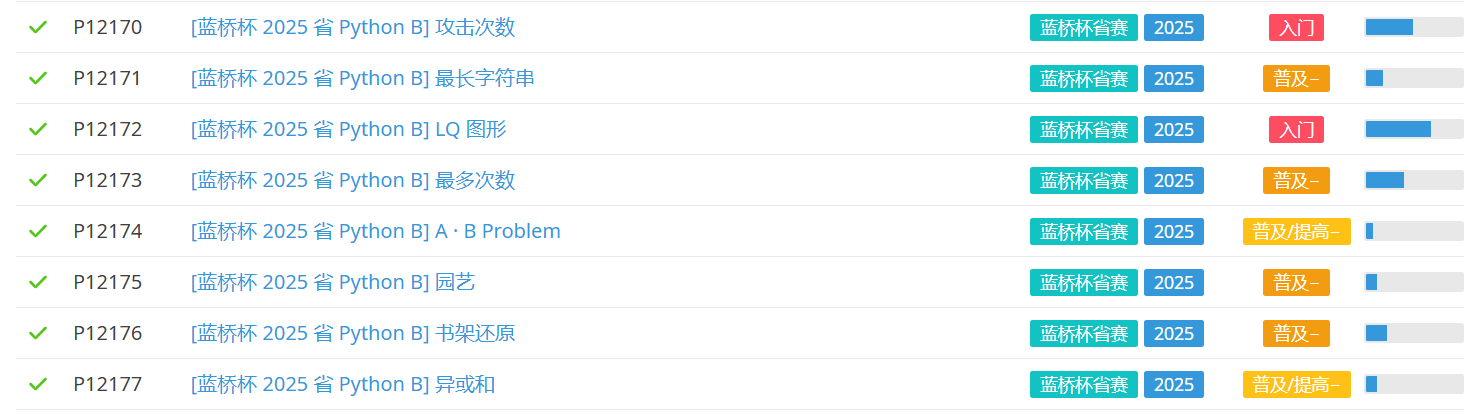
A: 攻击次数
答案:103?181?题目没说明白每回合是不是只能使用一个英雄?
def I():
return input()
def II():
return int(input())
def MII():
return map(int, I().split())
def LMII():
return list(MII())
def solve():
xl = 2025
cnt = 0
for i in range(1, 2025):
cnt += 1
xl -= 5
if i % 2 == 1:
xl -= 15
else:
xl -= 2
if i % 3 == 1:
xl -= 2
elif i % 3 == 2:
xl -= 10
elif i % 3 == 0:
xl -= 7
if xl <= 0:
break
print(i, xl)
print(cnt)
T = 1
for i in range(T):
solve()
B: 最长字符串
答案:afplcu
# # 考场错误解
# def I():
# return input()
# def II():
# return int(input())
# def MII():
# return map(int, I().split())
# def LMII():
# return list(MII())
# def solve():
# with open(r'words.txt', 'r') as file:
# data = file.readlines()
# dic = {}
# for i in range(len(data)):
# x = data[i].strip()
# data[i] = list(x)
# dic[x] = 0
# data[i].sort()
# dic[x] = data[i]
# can = set()
# for i in range(100):
# for x in data:
# if len(x) == i + 1:
# if len(x) == 1:
# can.add(tuple(x))
# else:
# if tuple(x[:len(x) - 1]) in can:
# can.add(tuple(x))
# cnt = 0
# for x in can:
# if len(x) > cnt:
# cnt = len(x)
# res = []
# for x in can:
# if len(x) == cnt:
# res.append(x)
# # print(dic)
# print(res)
# for x in dic:
# # print(tuple(dic[x]))
# if tuple(dic[x]) == res[0]:
# print(x)
# T = 1
# for i in range(T):
# solve()
# 正解
def is_beautiful_words(words):
"""
计算所有优美单词,并返回一个字典:
key: 单词长度
value: 集合,每个元素为 (word, sorted(word)) 表示已经确认的优美单词
"""
# 按长度升序排序(长度相同时字典序排序)
words_sorted = sorted(words, key=lambda w: (len(w), w))
# 用于存储每个长度的优美单词
beautiful_by_length = {}
for word in words_sorted:
l = len(word)
if l == 1:
# 长度为1的单词自动是优美字符串(只要在单词本中)
beautiful_by_length.setdefault(1, set()).add( (word, word) ) # 此处 sorted(word) == word
else:
# 先看是否存在长度为 l-1 的优美单词
if (l - 1) not in beautiful_by_length:
continue
# 取当前单词的前 l-1 个字符,并计算其排序结果
prefix = word[:-1]
sorted_prefix = ''.join(sorted(prefix))
# 检查是否存在一个长度为 l-1 的优美单词,其排序后的字符与 prefix 一致
found = False
for bw, bw_sorted in beautiful_by_length[l - 1]:
if bw_sorted == sorted_prefix:
found = True
break
if found:
beautiful_by_length.setdefault(l, set()).add( (word, ''.join(sorted(word))) )
return beautiful_by_length
def find_longest_beautiful_word(filename):
with open(filename, "r", encoding="utf-8") as f:
# 每一行一个单词,去除空白符
words = [line.strip() for line in f if line.strip()]
beautiful_by_length = is_beautiful_words(words)
if not beautiful_by_length:
return ""
# 找到存在的最大长度
max_len = max(beautiful_by_length.keys())
# 在最大长度中,找出字典序最小的那个单词
candidates = [word for word, _ in beautiful_by_length[max_len]]
result = min(candidates) if candidates else ""
return result
if __name__ == "__main__":
# 假设文件名为 words.txt
result = find_longest_beautiful_word("words.txt")
print("最长的优美字符串为:", result)
C: LQ 图形
def I():
return input()
def II():
return int(input())
def MII():
return map(int, I().split())
def LMII():
return list(MII())
def solve():
w, h, v = MII()
for i in range(h):
print("Q" * w)
for i in range(w):
print("Q" * (w + v))
T = 1
for i in range(T):
solve()
D: 最多次数
def I():
return input()
def II():
return int(input())
def MII():
return map(int, I().split())
def LMII():
return list(MII())
def solve():
s = I()
check = {'lqb', 'lbq', 'qlb', 'qbl', 'blq', 'bql'}
res = 0
i = 0
# print(len(s))
while i < len(s) - 2:
# print(i, s[i:i + 3])
if s[i:i + 3] in check:
res += 1
i += 2
i += 1
print(res)
T = 1
for i in range(T):
solve()
E: A · B Problem
def I():
return input()
def II():
return int(input())
def MII():
return map(int, I().split())
def LMII():
return list(MII())
def solve():
L = II()
res = 0
lst = [0] * (L + 5)
for i in range(1, L + 1):
for j in range(1, L + 1):
if i * j >= L:
break
lst[i * j] += 1
pre = lst.copy()
for i in range(1, L):
pre[i] += pre[i - 1]
for i in range(1, L):
cnt1 = i
cnt2 = L - i
res += lst[cnt1] * pre[cnt2]
print(res)
T = 1
for i in range(T):
solve()
赛时对拍
def I():
return input()
def II():
return int(input())
def MII():
return map(int, I().split())
def LMII():
return list(MII())
def solve1(n):
res = 0
for i in range(1, n + 1):
for j in range(1, n + 1):
for k in range(1, n + 1):
for l in range(1, n + 1):
if i * k + j * l <= n:
res += 1
# print((i, k), (j, l))
print(res)
def solve2(L):
res = 0
lst = [0] * (L + 5)
for i in range(1, L + 1):
for j in range(1, L + 1):
if i * j >= L:
break
lst[i * j] += 1
pre = lst.copy()
for i in range(1, L):
pre[i] += pre[i - 1]
for i in range(1, L):
cnt1 = i
cnt2 = L - i
res += lst[cnt1] * pre[cnt2]
print(res)
T = 1
for i in range(T):
L = II()
solve1(L)
solve2(L)
F: 园艺
赛时代码,可能超时
def I():
return input()
def II():
return int(input())
def MII():
return map(int, I().split())
def LMII():
return list(MII())
def solve():
n = II()
data = LMII()
res = 1
cnt = 1
for i in range(1, n):
if data[i] > data[i - 1]:
cnt += 1
else:
res = max(res, cnt)
cnt = 1
res = max(res, cnt)
if res == 1 or res == n:
print(res)
return
for jg in range(2, n): # 间隔
if res > (n - 1) // jg + 1:
break
for st in range(n - jg):
cnt = 1
for idx in range(st + jg, n, jg):
if data[idx] > data[idx - jg]:
cnt += 1
else:
res = max(res, cnt)
cnt = 1
res = max(res, cnt)
print(res)
T = 1
for i in range(T):
solve()
赛后优化及对拍
def I():
return input()
def II():
return int(input())
def MII():
return map(int, I().split())
def LMII():
return list(MII())
def solve1(n, data):
res = 1
cnt = 1
for i in range(1, n):
if data[i] > data[i - 1]:
cnt += 1
else:
res = max(res, cnt)
cnt = 1
res = max(res, cnt)
if res == 1 or res == n:
print(res)
return
for jg in range(2, n): # 间隔
if res > (n - 1) // jg + 1:
break
for st in range(n - jg):
cnt = 1
for idx in range(st + jg, n, jg):
if data[idx] > data[idx - jg]:
cnt += 1
else:
res = max(res, cnt)
cnt = 1
res = max(res, cnt)
print(res)
def solve2(n, data):
dp = [[1 for _ in range(n + 1)] for _ in range(n + 1)]
for i in range(0, n):
for j in range(0, i):
if data[i] > data[j]:
dp[i][i - j] = dp[j][i - j] + 1
print(max([max(d) for d in dp]))
T = 1
for i in range(T):
n = II()
# data = LMII()
import random
data = [random.randint(1, 2 ** 20) for _ in range(n)]
import time
t1 = time.time()
solve1(n, data)
t2 = time.time()
solve2(n, data)
t3 = time.time()
print(t2 - t1, t3 - t2)
G: 书架还原
# # 考场错误解
# def I():
# return input()
# def II():
# return int(input())
# def MII():
# return map(int, I().split())
# def LMII():
# return list(MII())
# def solve():
# n = II()
# data = [0] + LMII()
# res = 0
# for i in range(1, n + 1):
# if i != data[i]:
# if i == data[data[i]]:
# res += 1
# x = data[data[i]]
# data[data[i]] = data[i]
# data[i] = x
# print(res, data)
# cnt = 0
# for i in range(1, n + 1):
# if i != data[i]:
# cnt += 1
# if cnt:
# print(res + cnt - 1)
# else:
# print(res)
# T = 1
# for i in range(T):
# solve()
# 正解
n = int(input())
a = list(map(int, input().split()))
visited = [False] * n
ans = 0
for i in range(n):
if not visited[i] and a[i] != i + 1:
count = 0
j = i
while not visited[j]:
visited[j] = True
count += 1
j = a[j] - 1
ans += count - 1
print(ans)H: 异或和
赛时代码,超时
def I():
return input()
def II():
return int(input())
def MII():
return map(int, I().split())
def LMII():
return list(MII())
def solve1():
n = II()
data = LMII()
res = 0
for i in range(n - 1):
for j in range(i + 1, n):
res += (data[i] ^ data[j]) * (j - i)
print(res)
T = 1
for i in range(T):
solve1()
赛时对拍,超时
def I():
return input()
def II():
return int(input())
def MII():
return map(int, I().split())
def LMII():
return list(MII())
def solve1(n, data):
res = 0
for i in range(n - 1):
for j in range(i + 1, n):
# print(data[i],data[j],data[i] ^ data[j])
res += (data[i] ^ data[j]) * (j - i)
print(res)
def solve2(n, data):
res = 0
for j_i in range(1, n):
cnt = 0
for i in range(j_i):
for j in range(i + j_i, n, j_i):
cnt += data[j - j_i] ^ data[j]
res += j_i * cnt
print(res)
T = 1
for i in range(T):
n = II()
# data = LMII()
import random
data = [random.randint(1, 2 ** 20) for _ in range(n)]
import time
t1 = time.time()
solve1(n, data)
t2 = time.time()
solve2(n, data)
t3 = time.time()
print(t2 - t1, t3 - t2)
赛后补题
n = int(input())
a = list(map(int, input().split()))
ans = 0
for k in range(31): # 考虑31位足以覆盖正整数的情况
cnt1 = 0 # 记录当前位为1的个数
sum1 = 0 # 记录当前位为1的位置之和
for j in range(1, n + 1):
b = (a[j - 1] >> k) & 1 # 取出第k位
if b:
cnt0 = j - 1 - cnt1
sum0 = (j - 1) * j // 2 - sum1
ans += (j * cnt0 - sum0) * (1 << k)
cnt1 += 1
sum1 += j
else:
ans += (j * cnt1 - sum1) * (1 << k)
print(ans)







![[NOIP 2003 普及组] 栈 Java](https://i-blog.csdnimg.cn/direct/07c35fd8e1314b9593b56802d8d6f3ed.png)