K8s + vLLM & Ray:DeepSeek-r1 671B 满血版分布式推理部署实践
-
- 前言
- 环境准备
-
- 1. 模型下载
- 2. 软硬件环境介绍
- 正式部署
-
- 1. 模型切分
- 2. 整体部署架构
- 3. 安装 LeaderWorkerSet
- 4. 通过 LWS 部署DeepSeek-r1模型
- 5. 查看显存使用率
- 6. 服务对外暴露
- 7. 测试调用API
-
- 7.1 通过 curl
- 7.2 通过 OpenWebUI
- 性能压测
-
- vLLM引擎
-
- vllm-openai:v0.8.2
- vllm-openai:v0.8.1
- SGLang引擎
-
- sglang:v0.4.4.post3-cu125
- 结论与建议
-
- 建议:
- 参考资料
前言
自从上次发布 【AI-智算】K8s+SGLang实战:DeepSeek-r1:671b满血版多机多卡私有化部署全攻略] 文章后,本次将演示另一个主流推理引擎工具——vLLM,结合K8s、LWS、Ray、Volcano等技术栈,部署DeepSeek-r1 671b 满血版分布式推理集群,并对比其与SGLang推理引擎的性能表现。
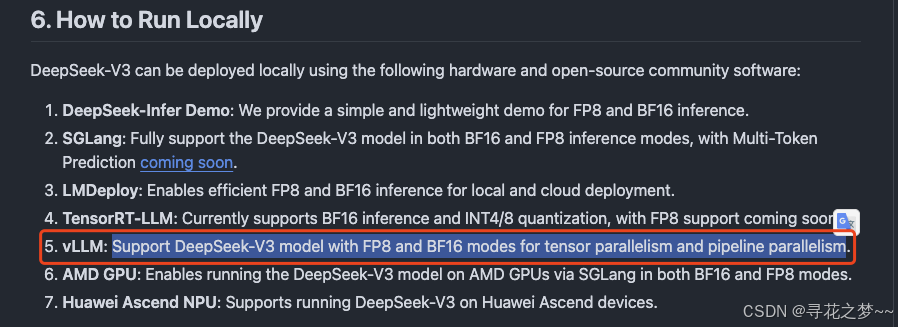
选型vLLM推理引擎的理由:
环境准备
1. 模型下载
本次阿程部署的是企业级满血版的Deepseek-R1 671B。
方式一:通过
HuggingFace下载
仓库地址:https://huggingface.co/deepseek-ai/DeepSeek-R1
方式二:通过
ModelScope下载 (阿程通过此方式下载)
仓库地址:https://modelscope.cn