写在前面
关于MySQL的下载安装和其图形化软件Navicat的下载安装,网上已经有了很多的教程,这里就不再赘述了,本文主要是介绍了关于MySQL数据库的基础知识。
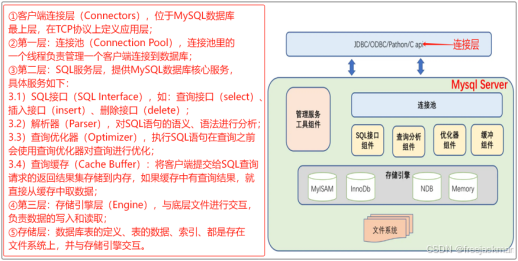
MySQL数据库
MySQL数据库基础
MySQL数据库概念
MySQL 数据库: 是一个关系型数据库管理系统 。
支持SQL语句的数据库:
① MySQL数据库; ② SQL Server数据库; ③ Oracle数据库; ④ Sybase数据库; ⑤ DB2数据库; ⑥ PostgreSQL数据库; ⑦ 人大金仓数据库(国产)。
MySQL数据库的逻辑结构
计算机数据容量计算方式
1、1PB = 1024TB
2、1TB = 1024GB
3、1GB = 1024MB
4、1MB = 1024KB
5、1KB = 1024B
6、1B = 8bits(比特)
PB:拍字节,TB:太字节,GB:千兆字节;MB:兆字节,KB:千字节,B:字节
MySQL数据库的数据类型
① 整数类型 (bool、 int 、 big int ) ; ② 浮点数类型 ( float 、 double 、 decimal ) ; ③ 字符串类型 ( varchar 、 text 、 blob ) ; ④ 日期类型 ( DateTime(年-月-日 时:分:秒) 、 TimeStamp(时间戳) ) ; ⑤ 其他数据类型 ( enum 等) 。
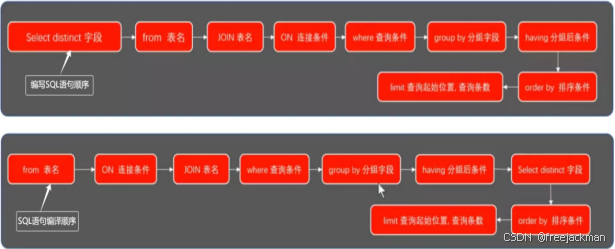
编写SQL语句的顺序,解释器编译SQL语句的顺序
编写SQL语句顺序与解释器编译SQL语句顺序(重点):
exists与in、内表与外表的区别
内表与外表的区别:
- 建表默认就是内表,如:
create table 指定表名;- 加
external就是外表,如:create table external 指定表名;- 删掉内表,
HDFS(分布式文件系统)上的数据被删掉了;- 删除外表,
HDFS上的数据是存在的。
exists 与 in的区别:
exists的效率比in查询要高,因为in不走索引。
in适合于外表数据量大而内表数据小的情况;exists适合于外表小而内表大的情况。
数据库常用命令
查看函数帮助的、查看警告的命令
- 查看函数说明命令:
help 函数名,如:help abs;----查看abs()函数帮助 - 显示数据库警告的命令:
show warnings
数据库常用的函数
avg(expression):返回字段expression的平均值;max(expression): 返回字段expression中的最大值;min(expression):返回字段expression中的最小值;sum(expression):返回字段expression的总和;count(expression): 返回字段expression的行数;replace(string, from_string, new_string): string:原始字符串;from_string:要替换的子字符串;new_string:新的替换子字符串;group_concat(expression):用于将group by产生的同一个分组中的值连接起来,返回一个字符串结果user():返回当前用户名:select USER();database(): 返回当前数据库名:select DATABASE();version():返回数据库的版本号:select VERSION();
新建、选择、删除数据库与新建、显示、删除表的命令
- 新建数据库命令:
create database 数据库名 character set utf8 collate utf8_general_ci;
注意:
character set设置编码格式,collate校验编码格式
-
选择数据库命令:
use 数据库名; -
删除数据库命令:
drop database 数据库名; -
新建表命令:
create table 表名; -
显示表命令:
show tables; -
删除指定表的命令:
drop table 指定表名;
查看指定表的结构的命令
- 查看表的字段与字段值命令:
describe 指定表名;
为指定表添加、修改、重命名、删除字段的命令
-
为指定表添加一个字段:
alter table 指定表名 add 字段名 字段类型; -
为指定表修改字段类型:
alter table 指定表名 modify 字段名 字段类型; -
重命名指定表的字段:
alter table 指定表名 change 原字段名 新字段名 字段类型; -
为指定表删除字段:
alter table 指定表名 drop 字段名;
新建表并为表添加一条数据
- 为指定表添加一条数据:
insert into 指定表名(字段名1,字段名2,字段名3,字段名4)values(数据1,数据2,数据3,数据4);
使用MySQL语句的例子
自动插入录入时间
--新建一个自动记录时间的消息表
create table test_msg(
id int primary key auto_increment comment "主键",
message longtext comment "消息",
cre_time timestamp not null default current_timestamp comment "录入时间"
)comment="记录消息的表";
-- 没有输入时间,会自动记录插入数据时系统时间
insert into test_msg(message) values("这是一个重大的新闻");
查询其他数据库的表
--编写一个查询其他数据库数据时数据的SQL语句
select from database_name.表名;
-- 其中database_name不是当前选择的数据库
单表查询(重点)
-- 新建学生表并插入相应的数据
create table student(
s_id int(10) primary key default 0 comment'用户ID',
sname varchar(10) comment'用户姓名',
sex varchar(1) comment'用户性别',
age int(3) comment'用户年龄',
s_time DateTime comment'记录时间',
s_info longtext comment'用户简介'
)engine=InnoDB default charset=utf8;
-- 查询学生表中所有数据
select * from student;
select s_id,sname,sex,age,s_time,s_info from student;
-- 查询学生姓名为张浩的信息
select * from student where sname="张浩";
select * from student where sname in("张浩");
-- 查询学生姓名,重复的不要显示
select distinct(sname) from student;
-- 查询年龄为20-40的学生信息
select * from student where age between 20 and 40;
select * from student where age>=20 and age<=40;
-- 查询以年龄进行(小到大,大到小)排序显示学生信息
-- 小到大排序:
select * from student where age order by age asc;
-- 大到小排序:
select * from student where age order by age desc;
-- 查询姓名以A开头、以A结尾、包含A、A开头并且后面跟一个字符的学生信息
-- A开头:
select * from student where sname like'A%';
-- A结尾:
select * from student where sname like'%A';
-- 包含A:
select * from student where sname like'%A%';
-- A开头并且后面跟一个字符:
select * from student where sname like'A_';
-- 查询性别不为女的学生信息
select * from student where sex not in ('女');
select * from student where sex !='女';
-- 查询年龄是22、55岁的学生信息
select * from student where age in (22,55);
select * from student where age=22 or age=55;
-- 查询年龄由小到大,在第二到第五的所有学生信息
select * from student where age order by age desc limit 1,4;
-- 查询最新的学生信息
select * from student order by s_time desc limit 1;
-- 查询相同年龄等于2的人数,并显示其姓名
select age as "年龄",count(age) as "人数",group_concat(sname)
from student where age group by age having count(age)=2;
-- 根据学生的年龄查询显示学生处于的年龄段
select * ,
case when t1.age between 0 and 18 then 'young'
when t1.age between 19 and 45 then 'middle'
else 'old' end as 'test_age'
from student t1;
-- 将李丽的年龄更新100岁
update student set sex='女',age="100" where s_id='97';
-- 删除李丽的数据
delete from student where sname="李丽";
-- 清除学生表所有的数据
truncate table student;
笛卡尔积
连接查询没有建外键时会出现笛卡尔积:如集合A={a,b}, 集合B={1,2} 两个集合则为笛卡尔积 {(a,1),(a,2),(b,1),(b,2)}。
MySQL 的连接查询
左连接查询:
left join 表名 on 连接条件……-----左表全部保留,右表关联不上用null表示;右连接查询:
right join 表名 on 连接条件……-----右表全部保留,左表关联不上的用null表示;内连接查询:
inner join 表名 on- 连接条件(join 表名 on 连接条件)……-----两表关联保留两表中交集的记录;全连接查询:
左连接+ union all +右连接-----两表关联查询它们的所有记录;
三表查询(重点)
-- 创建员工表
create table employee(
id int primary key auto_increment,
name varchar(10) unique,
age int,
salary double,
check(salary>7000 and salary<=15000),
relation_department_name varchar(20));
-- 创建部门表
create table department(
id int primary key auto_increment,
department_name varchar(20) unique,
department_person_num int);
-- 创建项目表
create table project(
id int primary key auto_increment,
project_name varchar(20),
relation_department_name varchar(20));
-- 1、要求-查询姓名为张三的员工,所在部门的名称、部门人数、关联项目的数量、关联项目的具体名称
select t1.name as "姓名", t2.department_name as "部门名",
t2.department_person_num as "部门人数",count(t3.project_name) as "关联项目个数",
group_concat(t3.project_name) as "关联项目名称"
from employee t1, department t2, project t3
where t1.relation_department_name = t2.department_name
and t2.department_name = t3.relation_department_name
and t1.name = "张三" group by t2.department_name,t2.department_person_num ;
select t1.name as "姓名",t2.department_name as "部门名", t2.department_person_num as "部门人数",
count(t3.project_name) as "关联项目个数",group_concat(t3.project_name) as "关联项目名称"
from employee t1 left join department t2 on t1.relation_department_name = t2.department_name
left join project t3 on t2.department_name = t3.relation_department_name
where t2.department_name is not null
and t3.relation_department_name is not null
and t1.name = "张三" group by t2.department_name,t2.department_person_num ;
-- 2、要求-查询所有的员工,所在部门的人数与关联的项目数,具体项目的名称?
select t1.name as "姓名",t2.department_person_num as "部门人数",
count(t3.project_name) as "关联项目个数",group_concat(t3.project_name) as "关联项目名称"
from employee t1, department t2, project t3
where t1.relation_department_name = t2.department_name
and t2.department_name = t3.relation_department_name
group by t1.name,t2.department_person_num ;
select t1.name as "姓名",t2.department_person_num as "部门人数",
count(t3.project_name) as "关联项目个数",group_concat(t3.project_name) as "关联项目名称"
from employee t1 left join department t2 on t1.relation_department_name = t2.department_name
left join project t3 on t2.department_name = t3.relation_department_name
where t2.department_name is not null
and t3.relation_department_name is not null
group by t1.name,t2.department_person_num ;
-- 3、要求-查询出每个人工程师所在的部门、薪资、负责项目名称
select t1.name as "姓名",t2.department_name as "部门名",t1.salary as "薪资",
group_concat(t3.project_name) as "关联项目名称"
from employee t1, department t2, project t3
where t1.relation_department_name = t2.department_name
and t2.department_name = t3.relation_department_name
group by t1.name,t1.salary;
select t1.name as "姓名",t2.department_name as "部门名",t1.salary as "薪资",
group_concat(t3.project_name) as "关联项目名称"
from employee t1 left join department t2 on t1.relation_department_name = t2.department_name
left join project t3 on t2.department_name = t3.relation_department_name
where t2.department_name is not null
and t3.relation_department_name is not null
group by t1.name,t1.salary;
-- 4、要求-查询出每个人工程师所在的部门、薪资、负责项目名称,并增加一个工资阶段财富类型字段
select t1.name as "姓名",t2.department_name as "部门名",t1.salary as "薪资",
group_concat(t3.project_name) as "关联项目名称",
case when t1.salary between 0 and 4000 then "低收入"
when t1.salary between 4001 and 8000 then "中收入"
else "高收入" end as "财富类型"
from employee t1, department t2, project t3
where t1.relation_department_name = t2.department_name
and t2.department_name = t3.relation_department_name
group by t1.name,t1.salary;
select t1.name as "姓名",t2.department_name as "部门名",t1.salary as "薪资",
group_concat(t3.project_name) as "关联项目名称" ,
case when t1.salary between 0 and 4000 then "低收入"
when t1.salary between 4001 and 8000 then "中收入"
else "高收入" end as "财富类型"
from employee t1 left join department t2 on t1.relation_department_name = t2.department_name
left join project t3 on t2.department_name = t3.relation_department_name
where t2.department_name is not null
and t3.relation_department_name is not null
group by t1.name,t1.salary;
-- 5、要求-查询项目中学生管理系统最高薪资的工程师姓名、所在项目、薪资
select t1.name as "姓名",t3.project_name as "项目名",t1.salary as "薪资"
from employee t1, department t2, project t3
where t1.relation_department_name = t2.department_name
and t2.department_name = t3.relation_department_name
and t3.project_name = "学生管理系统"
order by t1.salary desc limit 1;
select t1.name as "姓名",t3.project_name as "项目名",t1.salary as "薪资"
from employee t1 left join department t2 on t1.relation_department_name = t2.department_name
left join project t3 on t2.department_name = t3.relation_department_name
where t2.department_name is not null
and t3.relation_department_name is not null
and t3.project_name = "学生管理系统"
order by t1.salary desc limit 1;
MySQL视图
什么是视图
MySQL数据库视图:视图(View)是一种虚拟存在的表。
视图的特点
- 视图的列可以来自不同的表,是表的抽象和在逻辑意义上建立的新关系
- 视图是由基本表(实表)产生的表(虚表)
- 视图的建立和删除不影响基本表
- 对视图内容的更新(增删改)直接影响基本表
- 当视图来自多个基本表时,不允许添加、删除、更新数据。
视图的优缺点
优点:
1、
安全:一些数据表有着重要的信息,有些字段是保密的,不能让用户直接看到;2、
性能:视图建立在服务器上,直接调用在服务器上运行,可以提高性能;3、
灵活:建立一张视图,视图中的数据直接映射到新建的表,这样,就可以少做很多改动,也达到了升级数据表的目的。缺点:如果实际数据表的结构变更了,就需要及时对相关的视图进行相应的维护。
视图相关的SQL语句
- 声明视图:
create view 视图名 as SQL查询语句; - 查看视图:
show tables; - 删除视图:
drop view 视图名;
MySQL存储过程
什么是存储过程
存储过程:是一组为了完成特定功能的SQL语句集合。
存储过程的优缺点
优点:
- 封装性:封装成一个没有返回值函数;
- 可增强SQL语句的功能和灵活性:针对特定的功能编写存储过程;
- 高性能:存储过程编写成功后,就存储在数据库服务器中,以后客户端可以直接调用,从而提高性能;
- 提高数据库的安全性:存储过程作为接口提供给外部程序,外部程序无法直接操作数据库表,可以提高数据安全性。
缺点:
DBMS(DBMS是数据库管理系统)中的存储过程语法有所不同,所以可移植性差。
存储过程的语法
create procedure 存储过程名(in 参数名 参数类型,out 参数名 参数类型)
-- in:表示输入,out:表示输出
begin
-- 实现功能的SQL语句(一般是查询语句的封装);
end;
-- 调用存储过程:
call 存储过程名();
-- 删除存储过程:
drop procedure 存储过程名;
-- 例子如下:
-- 新建存储过程test_add:
create procedure test_add(in a int,in b int,out c int)
begin
set c=a+b;
end
-- 调用存储过程:
call test_add(2,3,@a);
-- 查看输出
select @a;
-- 删除存储过程:
drop procedure test_add;
MySQL 数据库导入导出
将表导出:
-- 将表test_csv导出到指定路径下面,导成csv类型文件
select id,name from test_csv
into outfile 'D:/test_as/test(utf8).csv'
character set utf8
fields terminated by ',';
-- 导入前可以先查看导入的路径:show variables like 'secure_file_priv';
-- 将into outfile 'D:/test_as/test(utf8).csv'中路径改为对应路径
-- character set utf8 表示字符编码为utf-8
-- fields terminated by ','; 表明数据与数据直接用','分隔开
将表导入:
load data local infile 'D:/test_as/test(utf8).csv'
into table test_csv
character set utf8
fields terminated by ',';
-- 将infile 'D:/test_as/test(utf8).csv'中路径改为对应路径
-- character set utf8 表示字符编码为utf-8
-- fields terminated by ','; 表明数据与数据直接用','分隔开
数据库整体导入导出(以Navicat为例):
- 导出:右键数据库,选择
“存储SQL文件”,选择对应的存储位置; - 导入:连接中新建数据,选中新建数据库右键
“运行SQL文件”;
MySQL 中事务的基本使用
事务概念:是一个操作序列,不可分割的工作单位,这些操作要么都执行,要么都不执行。
事务的语法:
1、
begin或start transaction:显式地开启一个事务;2、
commit或commit work:提交事务,对数据库进行的修改是永久性的;3、
rollback或rollback work:回滚结束用户事务,并撤销正在进行的所有未提交的修改事务;4、
savepoint S1:在事务中创建一个回滚点(savepoint),一个事务中可以有多个回滚点,S1代表回滚点名称;5、
rollback to [savepoint] S1:把事务回滚到标记点,S1代表回滚点名称。
![[ deepseek 指令篇章 ]300个领域和赛道喂饭级deepseek指令](https://i-blog.csdnimg.cn/direct/c1b3d76f12a4452a9d68a3807a9e027b.png)