ragflow部署与使用教程-智能文档处理与知识管理的创新引擎
1. ragflow简介
RAGFlow作为新一代智能文档处理平台,深度融合检索增强生成(RAG)技术与自动化工作流引擎,为企业级知识管理提供全栈解决方案。通过结合多模态解析、语义理解与智能推理能力,重塑了非结构化数据处理范式。传统的生成模型在回答复杂问题时常常依赖于预训练数据的广度与深度,而检索增强生成(Retrieval-Augmented Generation,简称RAG)则有效结合了检索与生成的优势,为各类应用场景提供了更为灵活、高效的解决方案。能够针对性的进行解答。
ragflow官方网址:https://ragflow.io/
github项目地址:https://github.com/infiniflow/ragflow
- 核心功能架构
- 多模态文档解析
集成OCR、文档结构识别和跨模态理解技术,支持PDF、Word、PPT、表格、扫描件等30+格式的深度解析。突破性地实现文本、公式、图表的多维度信息提取,准确率较传统方案提升40%。 - 智能语义检索
构建混合检索体系,融合关键词匹配、向量语义检索和关系图谱查询。独创的"多路召回-动态加权"机制,在金融实测场景中达到92%的召回准确率,较单向量检索提升35%。 - 动态工作流引擎
可视化编排文档处理流程,支持条件分支、人工复核节点和API对接。某医疗客户案例显示,报告生成效率从8小时缩短至20分钟,流程错误率降低70%。 - 精准问答系统
基于深度语义理解的问答引擎,支持多轮对话和溯源验证。在法律合同审查场景中,关键条款定位准确率达到98.6%,回答相关性评分超业界基准25%。
-
技术突破
-
混合增强索引:融合BM25、DPR和ColBERT模型,构建多层检索体系
-
动态上下文感知:基于Transformer的查询重写技术,实现意图精准捕捉
-
私有化安全部署:支持本地化部署和分级权限管理,通过等保三级认证
-
-
应用场景(包括但不限于在线问答系统、智能客服、知识库问答、个性化推荐等)
-
金融投研:自动解析财报/研报,构建智能投研知识库
-
法律合规:合同关键条款提取与风险预警
-
医疗健康:科研文献分析与诊疗指南生成
-
智能制造:设备手册知识化与故障诊断辅助
-
2. ragflow安装部署
2.1 环境准备
本次部署演示环境为Linux CentOS 7.9 操作系统
(base) [root@ops05 ~]# docker -v
Docker version 24.0.8, build e0dfb46
(base) [root@ops05 ~]# docker-compose -v
Docker Compose version v2.33.0
(base) [root@ops05 ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
(base) [root@ops05 ~]# free -h
total used free shared buff/cache available
Mem: 31G 3.3G 1.3G 1.6G 26G 25G
Swap: 0B 0B 0B
# 配置vm.max_map_count参数
(base) [root@ops05 ~]# vim /etc/sysctl.conf
vm.max_map_count=262144
(base) [root@ops05 ~]# sysctl -p
vm.swappiness = 0
net.core.somaxconn = 1024
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_max_syn_backlog = 1024
vm.max_map_count = 262144
max_map_count是 Linux 系统内核中的一个参数,用于限制一个进程可以拥有的最大内存映射区域数量。内存映射区域是指内存映射文件、匿名内存映射等。这个参数对于一些应用程序(例如常见的 Elasticsearch等等)特别重要,因为它们在运行时会创建大量的内存映射区域.
2.2 配置ragflow服务
# 拉取源代码
(base) [root@ops05 ~]# git clone https://github.com/infiniflow/ragflow.git
Cloning into 'ragflow'...
remote: Enumerating objects: 31866, done.
remote: Counting objects: 100% (171/171), done.
remote: Compressing objects: 100% (74/74), done.
remote: Total 31866 (delta 108), reused 100 (delta 96), pack-reused 31695 (from 3)
Receiving objects: 100% (31866/31866), 73.80 MiB | 16.92 MiB/s, done.
Resolving deltas: 100% (23143/23143), done.
(base) [root@ops05 ragflow]# ll -h
total 4.0K
drwxr-xr-x 18 root root 4.0K Apr 3 09:30 ragflow
# 更改.env配置(如果网速快,可以不配置)
(base) [root@ops05 ragflow]# cd docker/
(base) [root@ops05 docker]# vim .env
#RAGFLOW_IMAGE=infiniflow/ragflow:v0.17.2-slim
RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.17.2
# [注意]:RAGFLOW_IMAGE的值默认官方镜像下载很慢,并且image镜像文件非常大,可以把值换成国内的镜像源,下方提供2个镜像下载加速,**RAGFLOW_IMAGE** 的值取决于下方使用哪个下载路径,也可以使用下方的镜像重新tag标签
# 镜像下载加速参考
### 阿里加速仓库
(base) [root@ops05 docker]# docker pull registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.17.2
### 或华为加速仓库
(base) [root@ops05 docker]# docker pull swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.17.2
(base) [root@ops05 docker]# docker images | grep ragflow
swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow v0.17.2 eff1c12fb3b4 2 weeks ago 18.3GB
# 先docker pull把镜像文件下载后,再启动,避免up等待许久
(base) [root@ops05 docker]# docker-compose -p ragflow -f docker-compose.yml up -d
3. ragflow使用介绍
3.1 访问登录与界面设置
Web-UI-界面访问,服务器IP+80默认端口
点击注册,注册后登录即可
点击右上方头像进入到设置页面,可以在Profile- Language中将语言改为简体中文
3.2 配置添加大模型
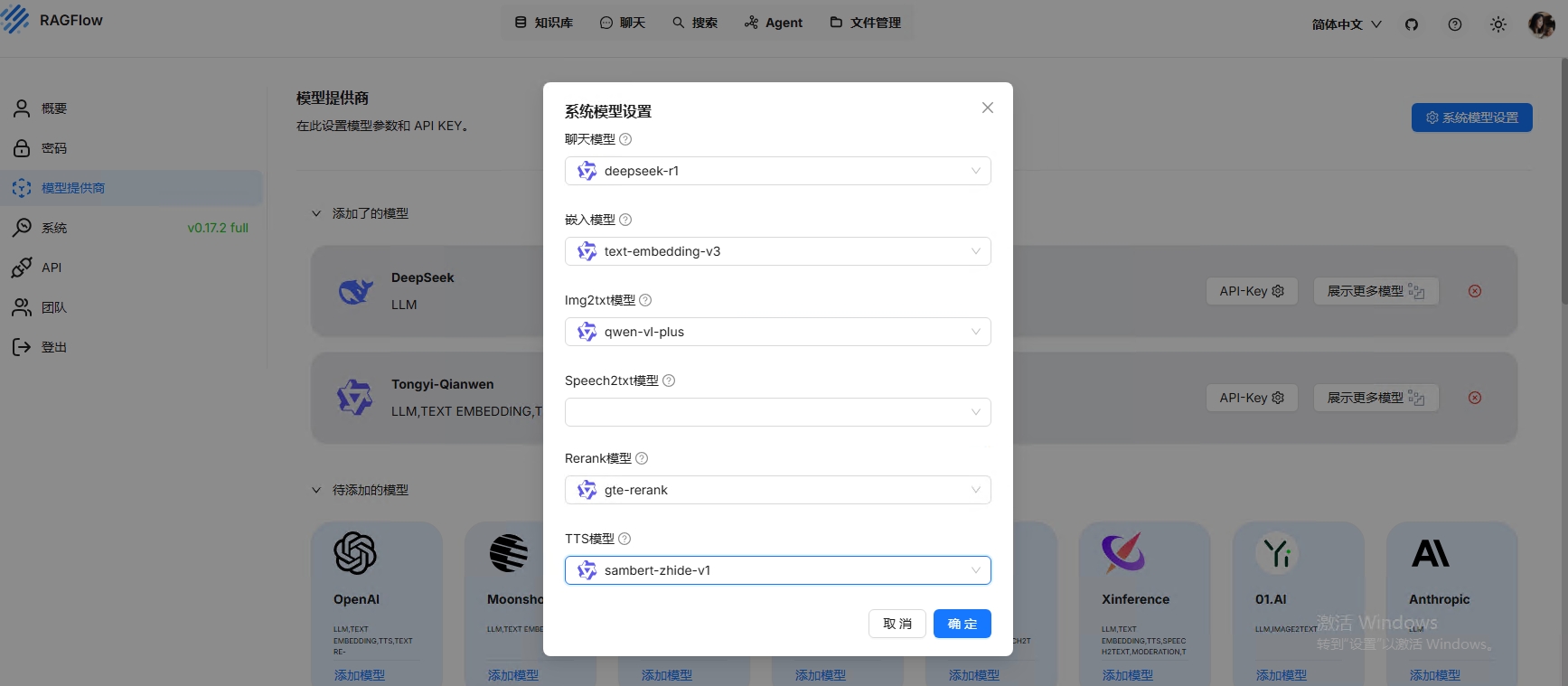
再模型提供商中添加大模型,例如Qwen、DeepSeek,注意需要先准备自己的API-KEY
模型提供商界面中,右上角系统模型设置,可以配置已经添加的模型,例如我这里配置了deepseek-r1
3.3 建立知识库
点击知识库,右边有一个
创建知识库按钮,定义知识库名称,例如我这里名称资产重组,知识库的数据集文件随意,只要可以识别即可我这里的素材分享:
通过网盘分享的文件
链接: https://pan.baidu.com/s/1AIEX4eQhBrR-B4IwUCygvQ?pwd=h6rb 提取码: h6rb
–来自百度网盘超级会员v6的分享
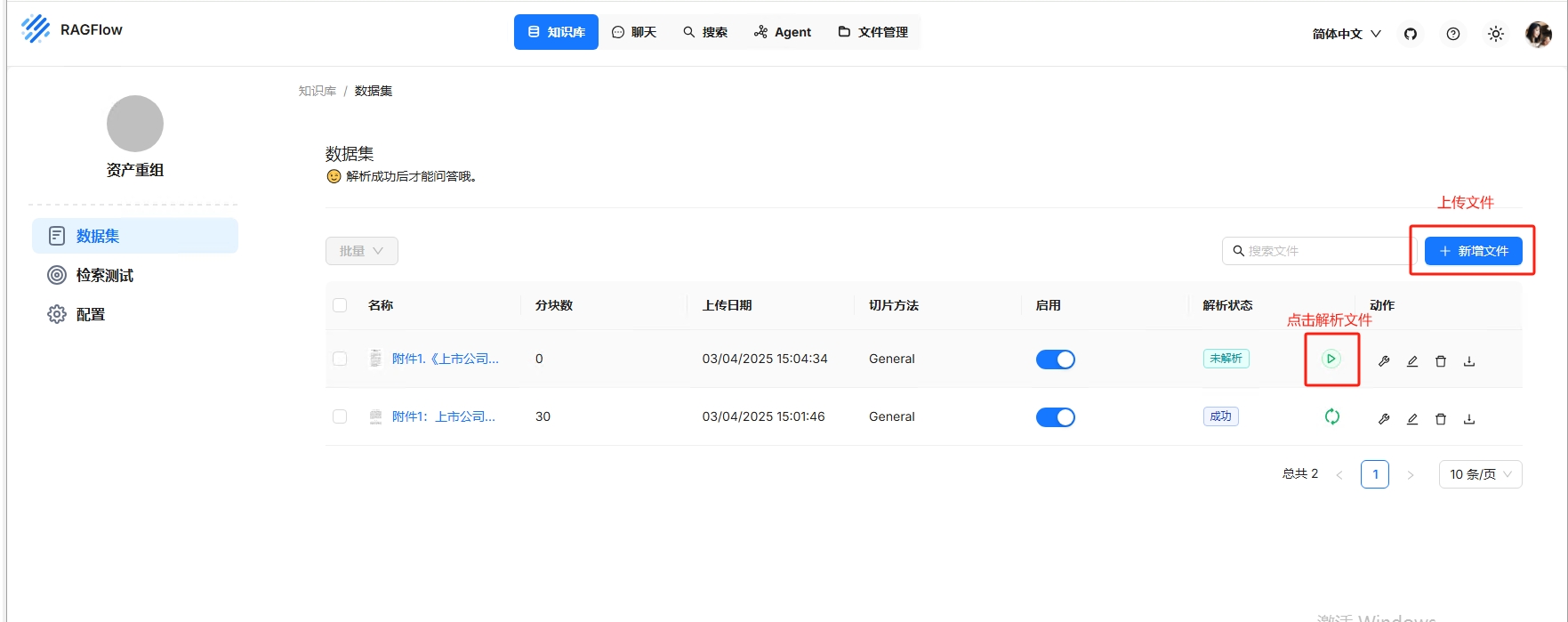
上传文件后,例如上传《附件1:上市公司重大资产重组管理办法.pdf》,需要点击解析文件,等待解析状态完成。此时自己的知识库就已经成功的配置完成
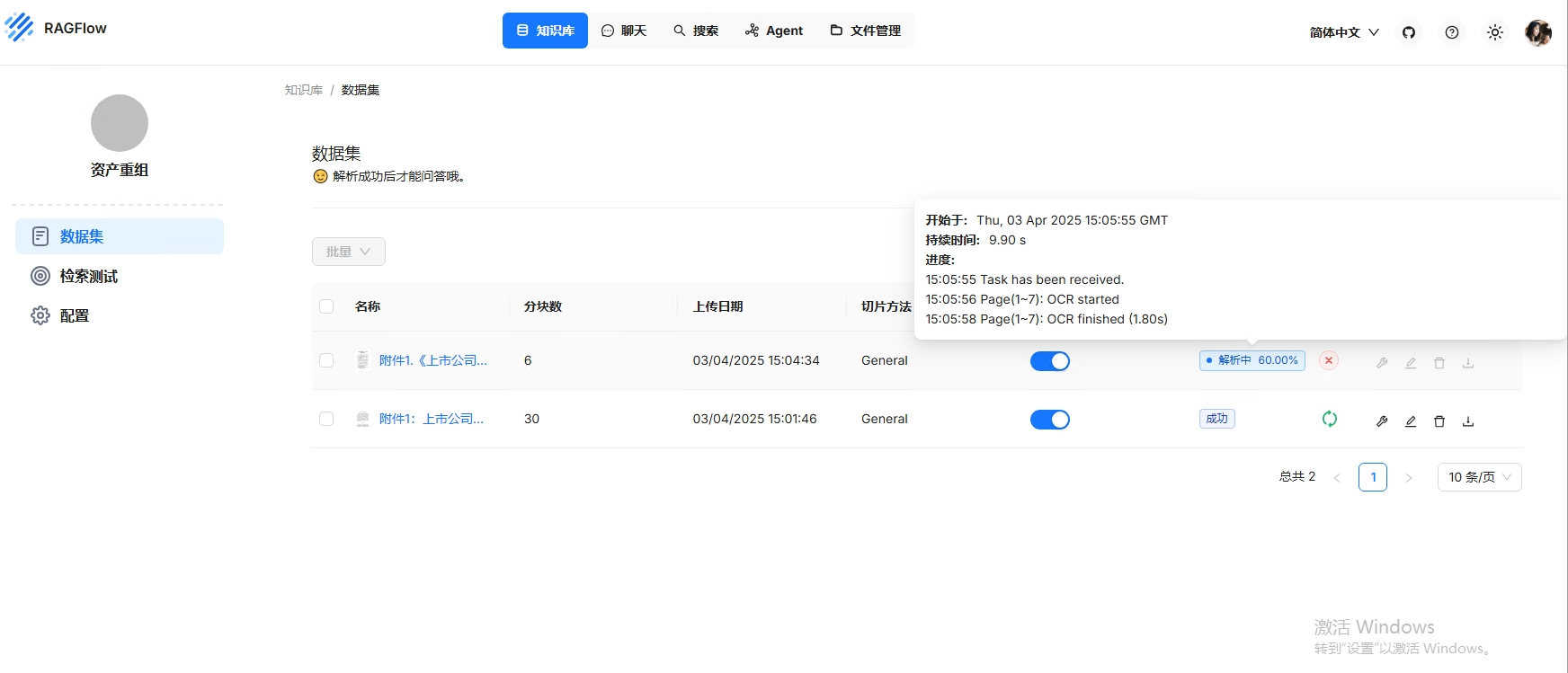
可以点击文件名称进入查看解析状态
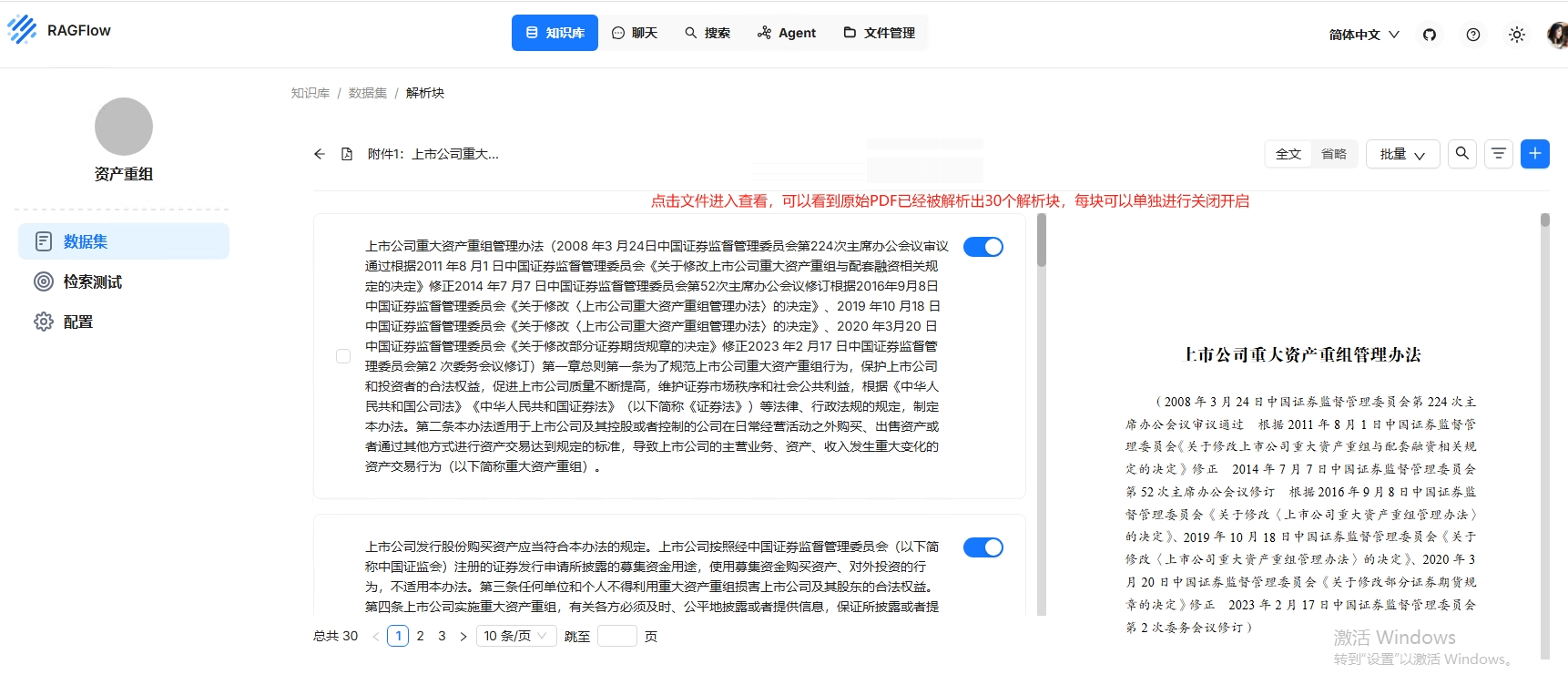
3.4 使用知识库
- 使用示例1(PDF政策解读)
创建一个聊天,注意在知识库的位置关联上已经建好的知识库
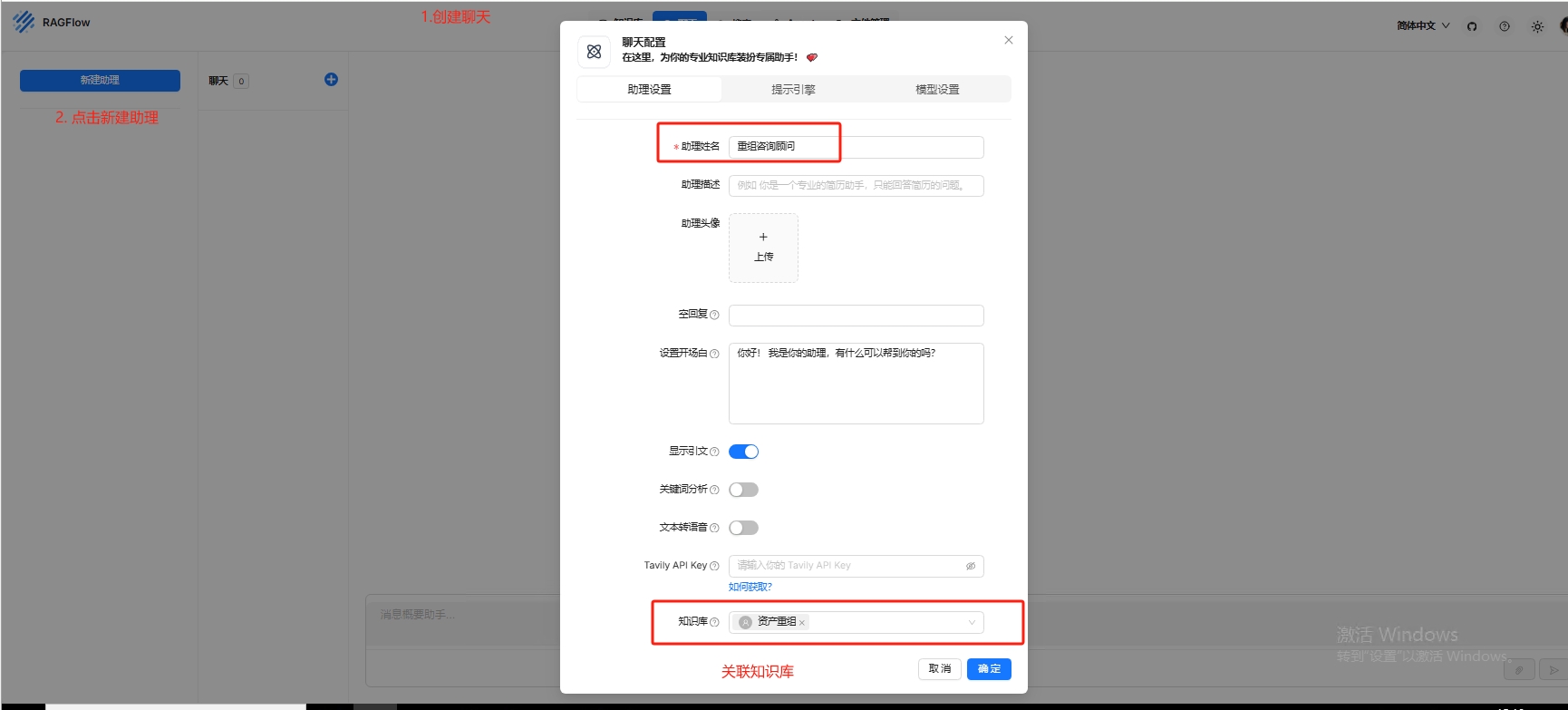
还需要设置模型设置,自由度可以去慢慢调试,这需要比较熟练使用以后进行微调,鼠标放在?图标会有参数的详细解释
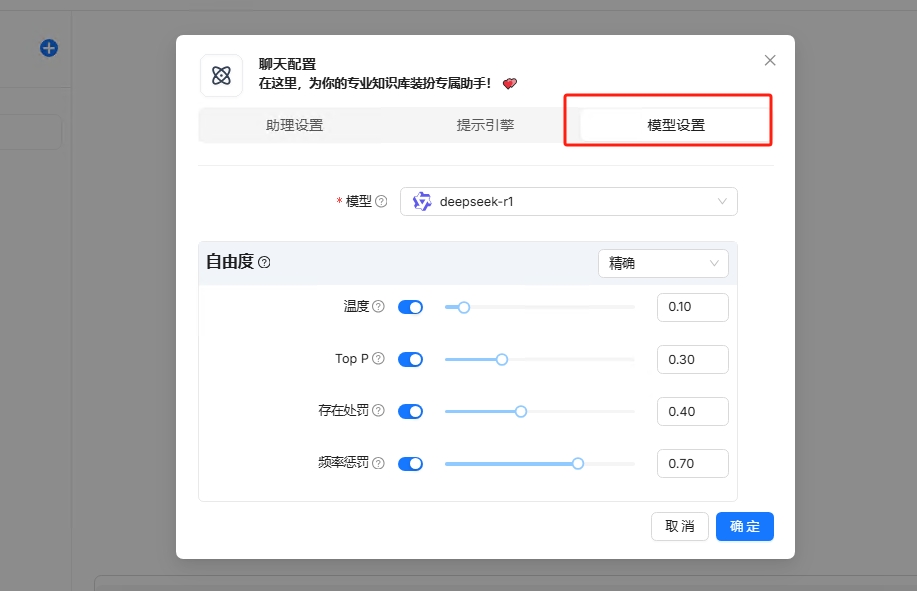
使用聊天窗口进行提问
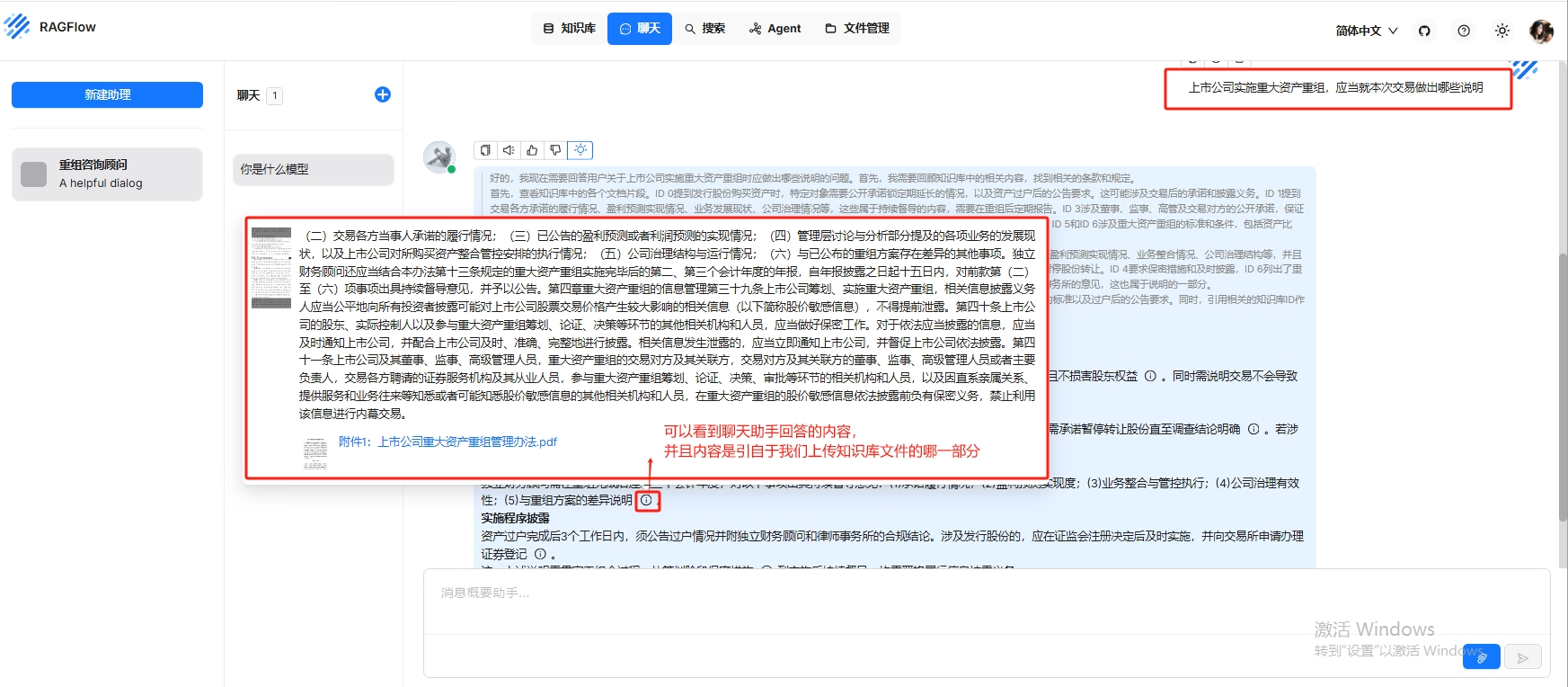
可以看到提问的回答内容,会显示引用了附件1:上市公司重大资产重组管理办法.pdf,并且在回答内容中都会有关联出引用文中的出处,在回答的窗口的上方也可以看Prompt提示
使用示例2(自定义文件,进行数据分析)
新建一个知识库
- 数据文件内容
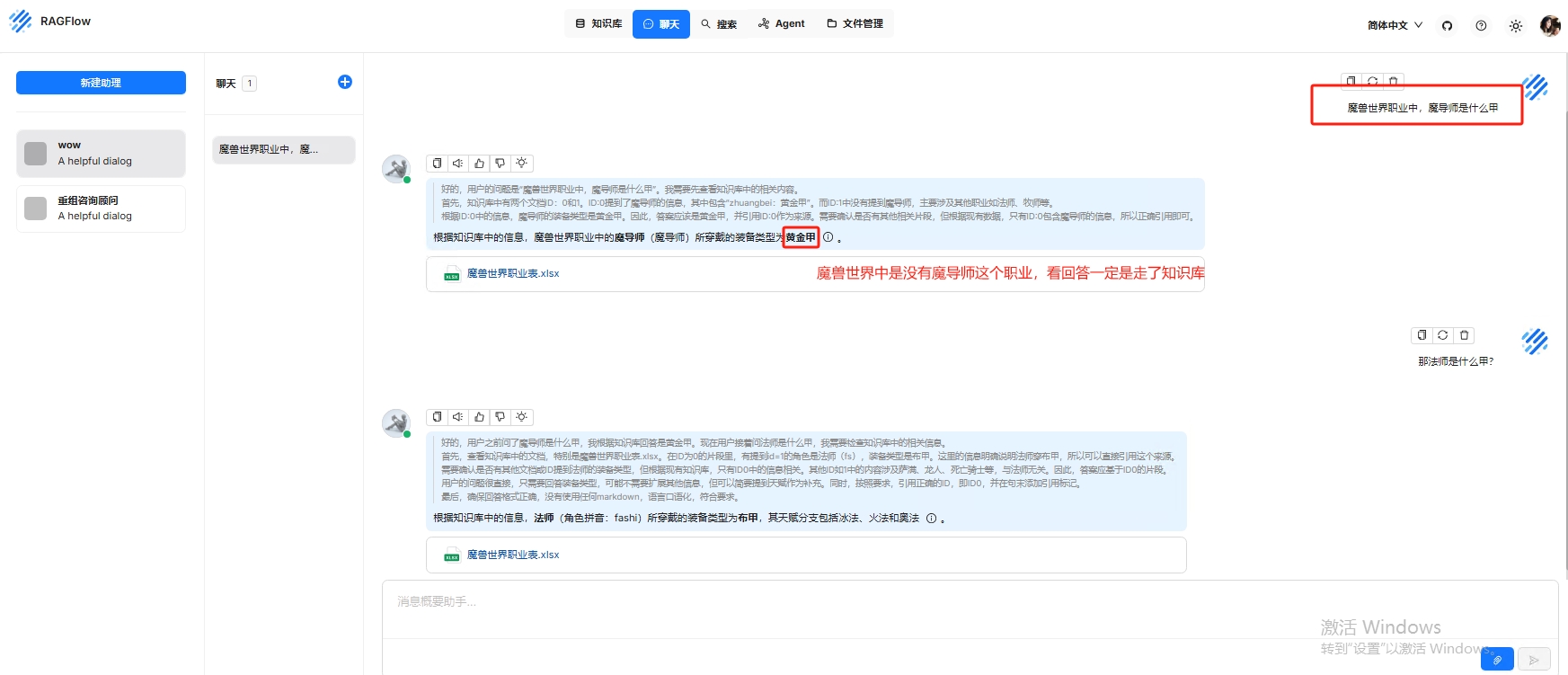
魔兽世界职业表,其中加了一行游戏不存在的魔导师职业,来印证知识库的使用一定会去读取本地本地并给出正确回答,素材上方的网盘分享中有
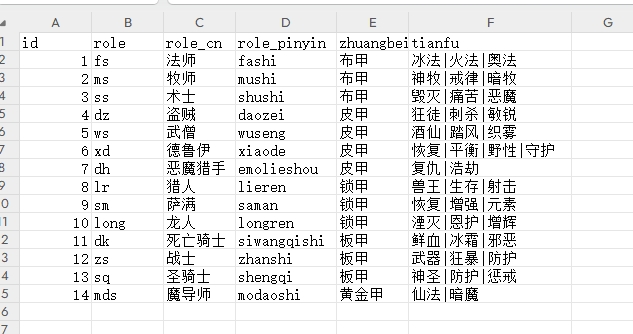
- 建立一个聊天,方法同示例1