影刀出鞘,抓取数据
在当今数字化时代,数据分析已成为企业决策和发展的关键驱动力。而获取高质量的数据则是数据分析的首要任务。在这个信息爆炸的时代,网络上蕴含着海量的数据,其中招聘网站的数据对于人力资源分析、市场趋势研究等具有重要价值。58 招聘网站作为国内知名的招聘平台,拥有丰富的职位信息,为我们的数据分析提供了广阔的数据源。为了高效地从 58 招聘网站获取所需数据,我们选择使用影刀这款强大的工具。
影刀是一款基于人工智能的自动化流程机器人,它能够模拟人类在计算机上的各种操作,实现自动化的数据抓取、处理和分析等任务,同时不需要处理反爬等琐事。使用影刀进行数据抓取,无需复杂的编程知识,通过简单的可视化操作即可完成。这使得数据抓取变得更加便捷、高效,大大降低了数据获取的门槛。
接下来,我们将详细介绍使用影刀抓取 58 招聘网站数据的具体步骤。首先,确保已经下载并安装好影刀软件,并在浏览器中添加影刀插件,这是后续操作的基础。打开影刀工具,在界面中找到 “网页自动化” 选项,点击其中的 “打开网页” 指令。在弹出的对话框中,输入 58 招聘网站的网址,如【58同城 58.com】北京分类信息 - 本地 免费 高效,然后点击确定,影刀会自动打开 58 招聘网站。
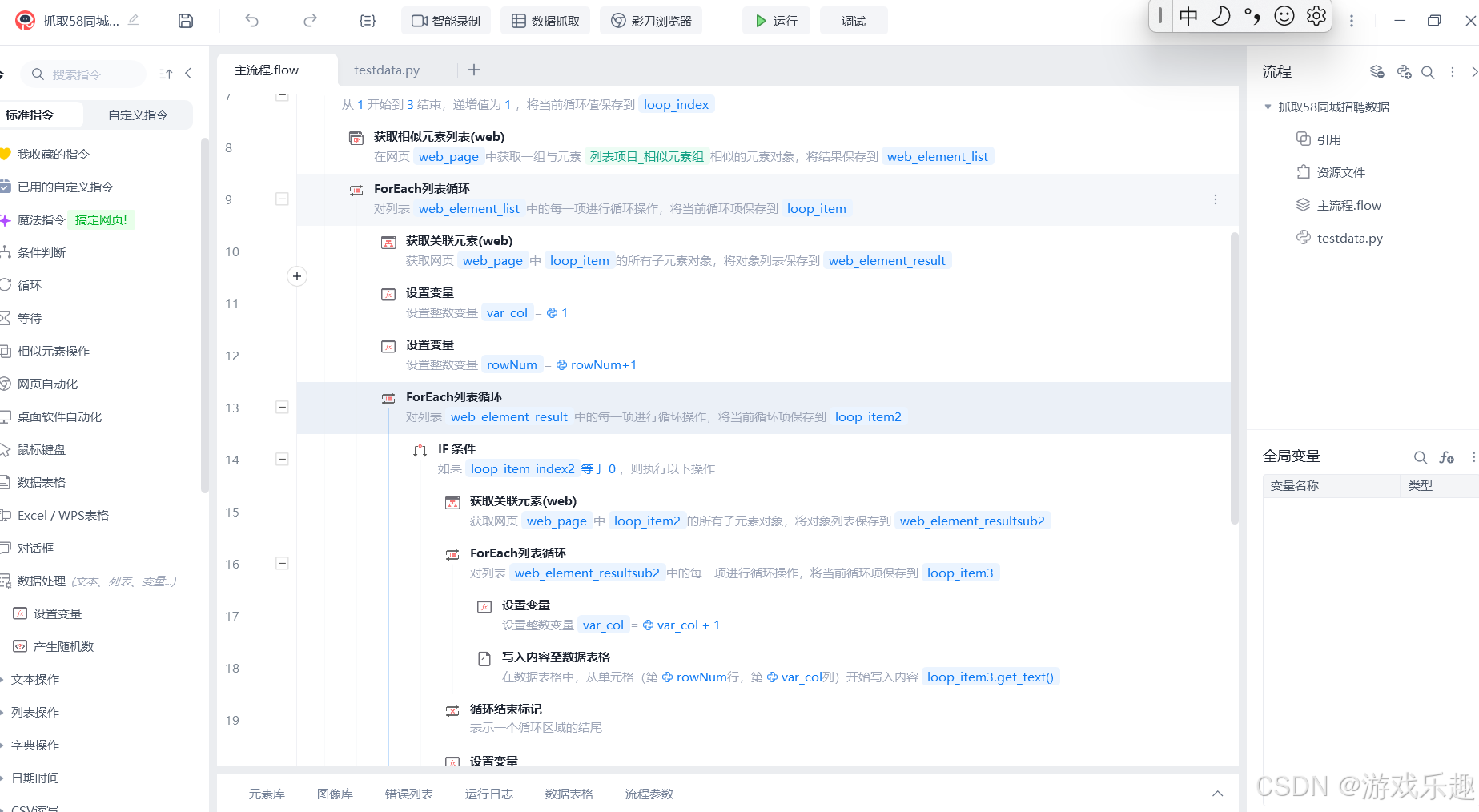
完成上述设置后,我们就可以点击影刀界面正中心上方的 “运行” 按钮,开启数据抓取测试。在测试过程中,我们需要密切关注影刀的运行状态和抓取结果,检查是否存在数据遗漏、抓取错误等问题。如果发现问题,及时调整相应的设置和参数,确保数据抓取的准确性和完整性。
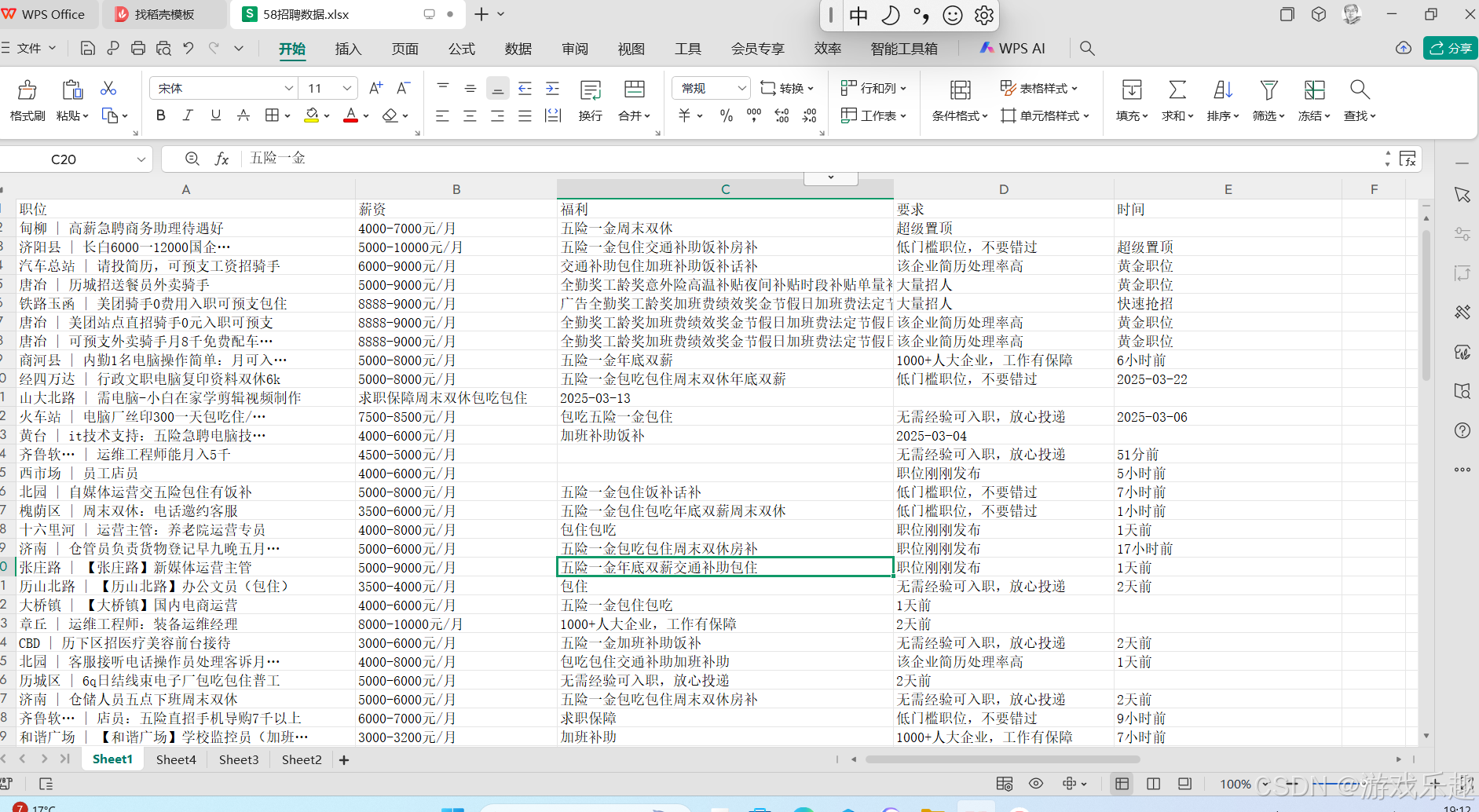
通过以上步骤,我们成功使用影刀从 58 招聘网站抓取到了大量的职位信息。然而,由于这些数据是从网页上直接抓取的非结构化数据,格式和内容可能存在不规范的情况,这给后续的数据分析带来了一定的困难。为了将这些数据转化为有价值的信息,我们需要进一步对其进行处理和分析。在下文中,我们将介绍如何使用豆包大模型对抓取到的职位信息进行提取和整理,使其更加规范化、结构化,以便于后续的数据分析和可视化展示。
数据初现,问题浮现
通过影刀的高效运作,我们成功从 58 招聘网站抓取到了大量的职位信息。这些数据犹如一座蕴含丰富信息的宝藏,为我们后续的数据分析提供了坚实的基础。然而,当我们深入审视这些抓取到的数据时,却发现它们存在着诸多不规范的问题。
由于这些数据是从网页上直接抓取的非结构化数据,没有固定的格式和规范,因此数据格式不一致的问题尤为突出。在薪资待遇这一关键信息中,有的数据是以具体的数值形式呈现,如 “8000 元 / 月”;有的则是一个范围,像 “6000 - 10000 元 / 月”;甚至还有一些是以年薪的方式表述,如 “10 - 15 万年薪”。这种不一致性使得在进行数据分析时,难以对薪资进行统一的计算和比较。
除了数据格式不一致,内容缺失也是一个不容忽视的问题。部分职位信息中,工作地点这一重要信息缺失,这对于分析不同地区的职位分布情况造成了极大的阻碍。还有一些职位,公司名称、岗位职责等关键内容不完整,这使得我们无法全面了解该职位的相关信息,也影响了数据分析的准确性和完整性。
更让人头疼的是,数据中还存在一些错误和噪声信息。比如,在职位名称中,可能会出现错别字或者与实际职位不符的表述;在公司名称中,也可能存在一些简称、别名或者错误的拼写。这些错误和噪声信息不仅干扰了我们对数据的理解,也会对后续的数据分析结果产生误导。
这些不规范的数据就像一团乱麻,给我们的数据分析工作带来了巨大的挑战。如果直接对这些原始数据进行分析,很可能会得出错误的结论,从而影响我们的决策。因此,我们迫切需要一种有效的方法来对这些数据进行处理和整理,使其更加规范化、结构化。而豆包大模型的出现,为我们解决这些问题带来了希望。在下文中,我们将详细介绍如何使用豆包大模型对这些不规范的职位信息进行提取和整理,使其能够满足我们后续数据分析的需求。
豆包登场,精准提取
在面对影刀抓取到的大量不规范职位信息时,豆包大模型凭借其强大的自然语言处理能力和智能分析算法,成为了我们提取关键信息的得力助手。
豆包大模型是字节跳动公司基于 Transformer 架构研发的语言模型,经过海量数据的训练,它对各种自然语言的理解和处理能力十分出色。尤其是在处理非结构化数据时,能够通过深度学习算法,挖掘数据中的潜在模式和关键信息,这使得它在职位信息提取方面具有显著优势。
完成数据预处理后,我们就可以借助豆包大模型进行职位信息的提取了。如下图所示,通过提示词提取职位数据列中的具体职位名称。
# 火山引擎API相关配置
api_url = "https://ark.cn-beijing.volces.com/api/v3/chat/completions"
# 取配置在环境变量中的API Key
api_key = os.environ.get("ARK_API_KEY")
# 定义一个函数,使用火山引擎大模型进行职位名称转换
def convert_position_name(position):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": "doubao-1-5-lite-32k-250115", # 请替换为你要使用的具体模型名称
"messages": [
{"role": "system", "content": "你是一个专业的职位分类助手,需要将不规范的职位名称转换为规范的名称,去掉地方区域类的前缀(如章丘,槐荫区,历下区等)\
,如司机、人事、行政、软件工程师等。"},
{"role": "user", "content": position}
]
}
try:
response = requests.post(api_url, headers=headers, data=json.dumps(data))
response.raise_for_status()
result = response.json()
return result["choices"][0]["message"]["content"].strip()
except requests.RequestException as e:
print(f"请求出错: {e}")
except (KeyError, IndexError, json.JSONDecodeError):
print(f"解析响应出错,职位名称: {position}")
return position
通过豆包大模型的处理,我们成功地从影刀抓取到的不规范数据中提取出了结构化、规范化的职位信息。这些信息为后续的数据分析提供了坚实的基础,使我们能够更加深入地了解 58 招聘网站上 某职位的相关情况,为人力资源分析、市场趋势研究等提供有力的数据支持。接下来,我们将使用 Python 对提取到的职位信息进行数据统计和可视化展示,以便更直观地呈现数据背后的信息和趋势。
Python 助力,图表呈现
经过影刀的数据抓取和豆包大模型的信息提取,我们已经得到了结构化、规范化的职位信息。这些信息是我们深入了解 58 招聘网站上 Python 开发工程师职位情况的宝贵资源,但原始的数据表格形式难以直观地展现数据背后的信息和趋势。为了更清晰、直观地呈现数据分析结果,我们需要借助数据统计图表的强大力量。
数据统计图表能够将复杂的数据转化为直观的图形,使数据中的信息和趋势一目了然。它不仅能够帮助我们快速理解数据的特征和规律,还能在向他人展示数据分析结果时,更有效地传达信息,增强说服力。例如,通过柱状图,我们可以清晰地比较不同公司提供的 Python 开发工程师职位的薪资水平;利用折线图,能够直观地看到不同时间段内 Python 开发工程师职位的需求量变化趋势;而饼图则可以展示不同工作地点的职位占比情况,让我们对职位的地域分布有更直观的认识。
import os
import pandas as pd
import xlsxwriter
import requests
import json
# 火山引擎API相关配置
api_url = "https://ark.cn-beijing.volces.com/api/v3/chat/completions"
# 取配置在环境变量中的API Key
api_key = os.environ.get("ARK_API_KEY")
# 定义一个函数,使用火山引擎大模型进行职位名称转换
def convert_position_name(position):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": "doubao-1-5-lite-32k-250115", # 请替换为你要使用的具体模型名称
"messages": [
{"role": "system", "content": "你是一个专业的职位分类助手,需要将不规范的职位名称转换为规范的名称,去掉地方区域类的前缀(如章丘,槐荫区,历下区等)\
,如司机、人事、行政、软件工程师等。"},
{"role": "user", "content": position}
]
}
try:
response = requests.post(api_url, headers=headers, data=json.dumps(data))
response.raise_for_status()
result = response.json()
return result["choices"][0]["message"]["content"].strip()
except requests.RequestException as e:
print(f"请求出错: {e}")
except (KeyError, IndexError, json.JSONDecodeError):
print(f"解析响应出错,职位名称: {position}")
return position
# 读取 Excel 文件
file_path = '58招聘数据.xlsx'
try:
df = pd.read_excel(file_path)
# 使用火山引擎大模型转换职位列中的不规范名称为规范名称
df['职位'] = df['职位'].apply(convert_position_name)
# 统计“职位”列中每个职位的数量
position_counts = df['职位'].value_counts()
# 创建一个新的 Excel 文件和工作表
workbook = xlsxwriter.Workbook('58招聘数据.xlsx')
worksheet = workbook.add_worksheet()
# 写入表头
worksheet.write('A1', '职位')
worksheet.write('B1', '数量')
# 写入统计数据
row = 1
for position, count in position_counts.items():
worksheet.write(row, 0, position)
worksheet.write(row, 1, count)
row += 1
# 创建柱状图
chart = workbook.add_chart({'type': 'column'})
# 配置图表数据
chart.add_series({
'categories': ['Sheet1', 1, 0, row - 1, 0],
'values': ['Sheet1', 1, 1, row - 1, 1],
})
# 设置图表标题和坐标轴标签
chart.set_title({'name': '招聘职位统计'})
chart.set_x_axis({'name': '职位'})
chart.set_y_axis({'name': '数量'})
# 在工作表中插入图表
worksheet.insert_chart('D2', chart)
# 关闭工作簿
workbook.close()
except FileNotFoundError:
print(f"错误: 未找到文件 {file_path}。")
except KeyError:
print("错误: Excel 文件中未找到 '职位' 列。")
except Exception as e:
print(f"发生未知错误: {e}")
洞察结果,展望未来
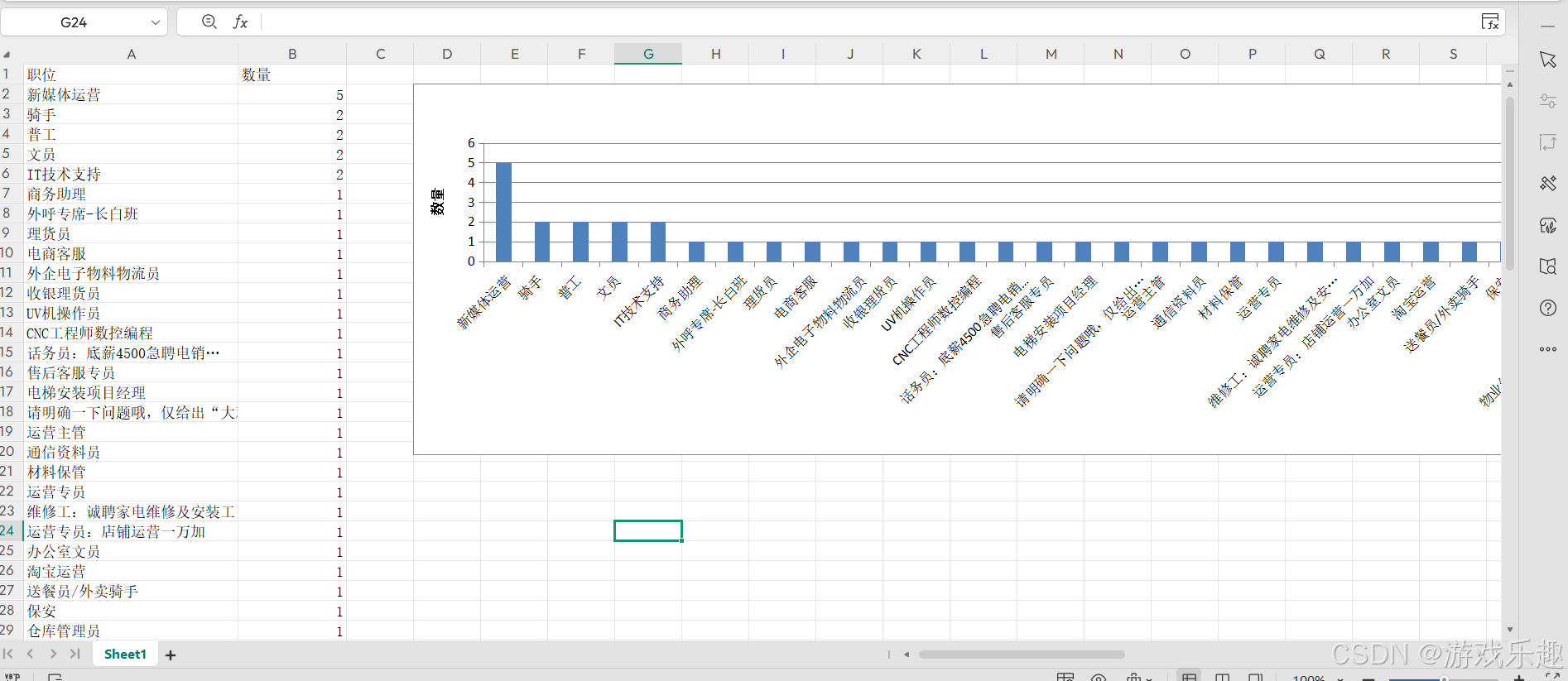
通过影刀、豆包大模型和 Python 的协同运用,我们成功地完成了从 58 招聘网站获取职位信息、处理非结构化数据以及进行数据可视化的全过程。这一系列操作不仅展示了 AI 技术在数据分析领域的强大威力,也为我们深入了解人才市场的动态提供了有力的支持。
影刀帮助我们突破了数据获取的瓶颈,高效地从 58 招聘网站抓取到海量职位信息,大大节省了人力和时间成本。豆包大模型凭借其强大的自然语言处理能力,将这些非结构化的混乱数据转化为结构化、规范化的有用信息,使得我们能够从中提取出关键要素,为后续分析奠定了坚实基础。而 Python 及其丰富的库,如 matplotlib 和 seaborn,则将这些数据以直观、美观的图表形式呈现出来,让数据背后的信息和趋势一目了然。
从生成的统计图表中,我们可以清晰地洞察到许多有价值的信息。比如,不同公司提供的 Python 开发工程师职位薪资水平存在明显差异,这可能与公司规模、行业地位、业务需求等因素有关;通过职位需求趋势图,我们能看到该职位在不同时间段的需求量变化,这对于企业制定招聘计划以及求职者规划职业发展都具有重要参考意义;工作地点分布的饼图则直观地展示了不同地区对 Python 开发工程师的需求程度,反映了区域经济发展和产业布局的特点。
展望未来,AI 在数据分析领域的发展前景无比广阔。随着技术的不断进步和创新,AI 将能够处理更加复杂的数据,挖掘出更深层次的信息和价值。一方面,大模型的性能和能力将持续提升,能够更4好地理解和处理各种自然语言和复杂语义,在数据提取、分析和解读方面发挥更大的作用。另一方面,自动化和智能化的数据处理流程将进一步简化数据分析的操作,降低对专业技术人员的依赖,使得更多的企业和个人能够受益于数据分析。
此外,AI 与其他新兴技术,如物联网、区块链、云计算等的融合也将为数据分析带来更多的可能性。例如,物联网设备产生的海量实时数据,将为 AI 提供更丰富的数据源,从而实现更精准的预测和决策;区块链技术则可以保障数据的安全性和可信度,为数据分析提供可靠的数据基础;云计算则为 AI 数据分析提供强大的计算资源和存储能力,使得大规模的数据处理和分析成为可能。
对于广大的数据分析爱好者和从业者来说,这是一个充满机遇和挑战的时代。我们应该积极拥抱 AI 技术,不断学习和探索新的方法和工具,提升自己的数据分析能力。同时,也要关注 AI 技术在实际应用中可能带来的问题和风险,如数据隐私、算法偏见等,确保 AI 技术的健康、可持续发展。希望大家能够在 AI 辅助数据分析的道路上不断前行,挖掘数据的无限价值,为个人和社会创造更多的财富和价值。