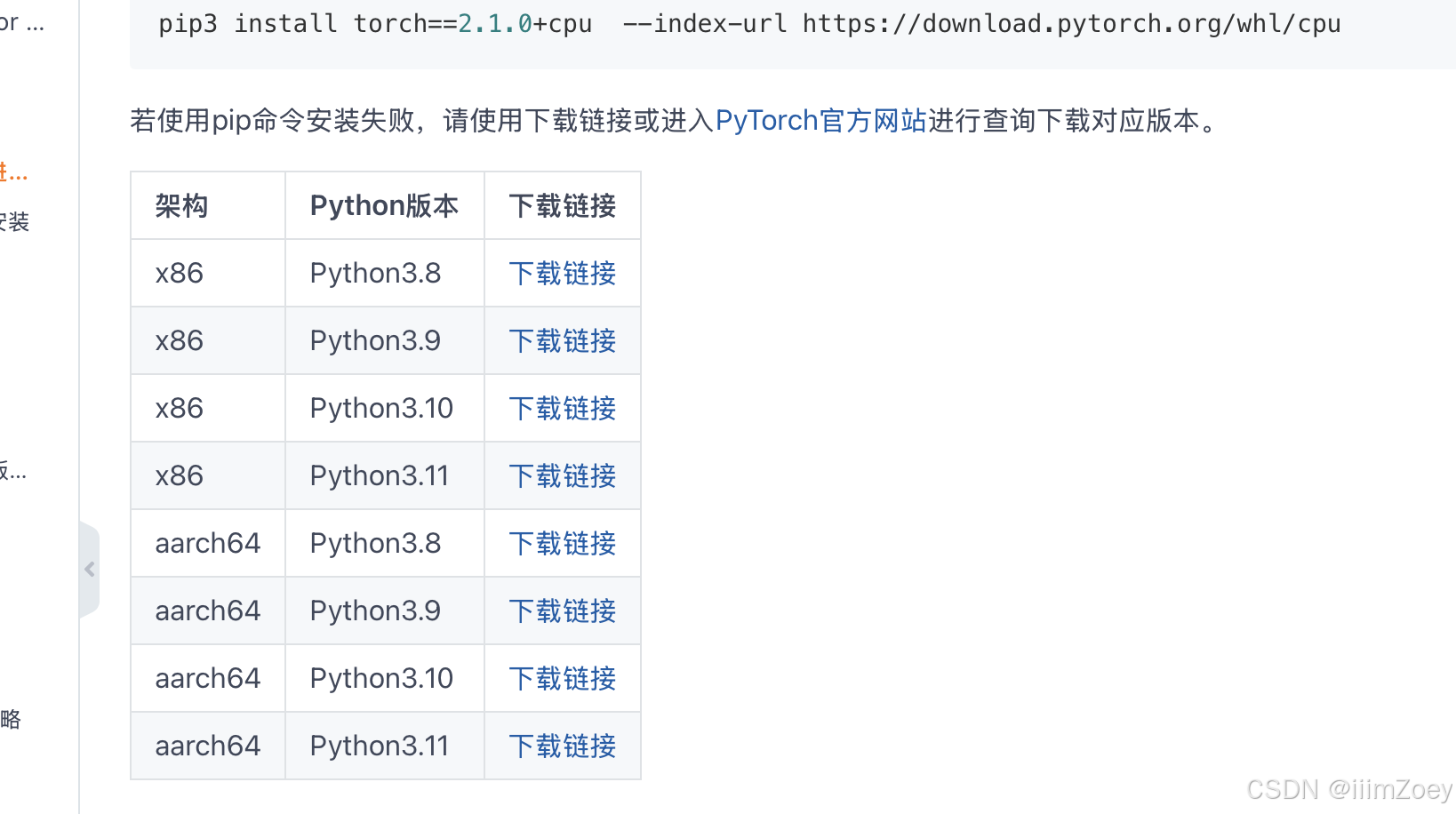
1.获取文件信息、获取视频信息
走的都是同一个方法:baseController里面的getFile。
在getFile方法里面进行判断文件的类型,判断是不是m3u8类型或者ts类型做一些额外的处理。
获取信息底层就是读取文件,然后写入response的OutputStream
out = response.getOutputStream(); File file = new File(filePath);
if (!file.exists()) {
return;
}
in = new FileInputStream(file);
limitInputStream = new LimitInputStream(in,new BandwidthLimiter(1024));
byte[] byteData = new byte[1024];
out = response.getOutputStream();
int len = 0;
while ((len = limitInputStream.read(byteData)) != -1) {
out.write(byteData, 0, len);
}
out.flush();在readFile的时候要做一些校验,防止用户输入类似“../”这种目录从而访问到我们的其他信息
2.新建文件夹
流程:
根据传入的文件名和父目录id(pid)查询是否有同名文件夹,如果没有才能插入数据库。本项目在插入之后又进行了一次校验(校验目录数量是否大于2),是为了防止高并发的插入。
防止高并发也可以加锁。
加锁的话这里延伸一下。
加锁在方法上(synchronized)的时候,锁住的是调用当前方法的对象,我们Bean一般是单例模式,所以锁住这个Bean对象之后其他用户调用这个方法也会串行执行(严重影响效率)。
所以我们应该根据用户Id加锁,或者使用分布式锁。
再说一下synchronize在代理下的问题:
当我们在方法上加入了@async或者@transaction这些注解,他们是使用aop实现的,底层用到了动态代理,所以,我们其实拿到的是代理对象,调用的方法是代理对象的方法,此时如果方法里是使用synchronized(this)这种方法加锁,那么锁就会在事物提交之前就释放那么可能就会引起并发安全问题。
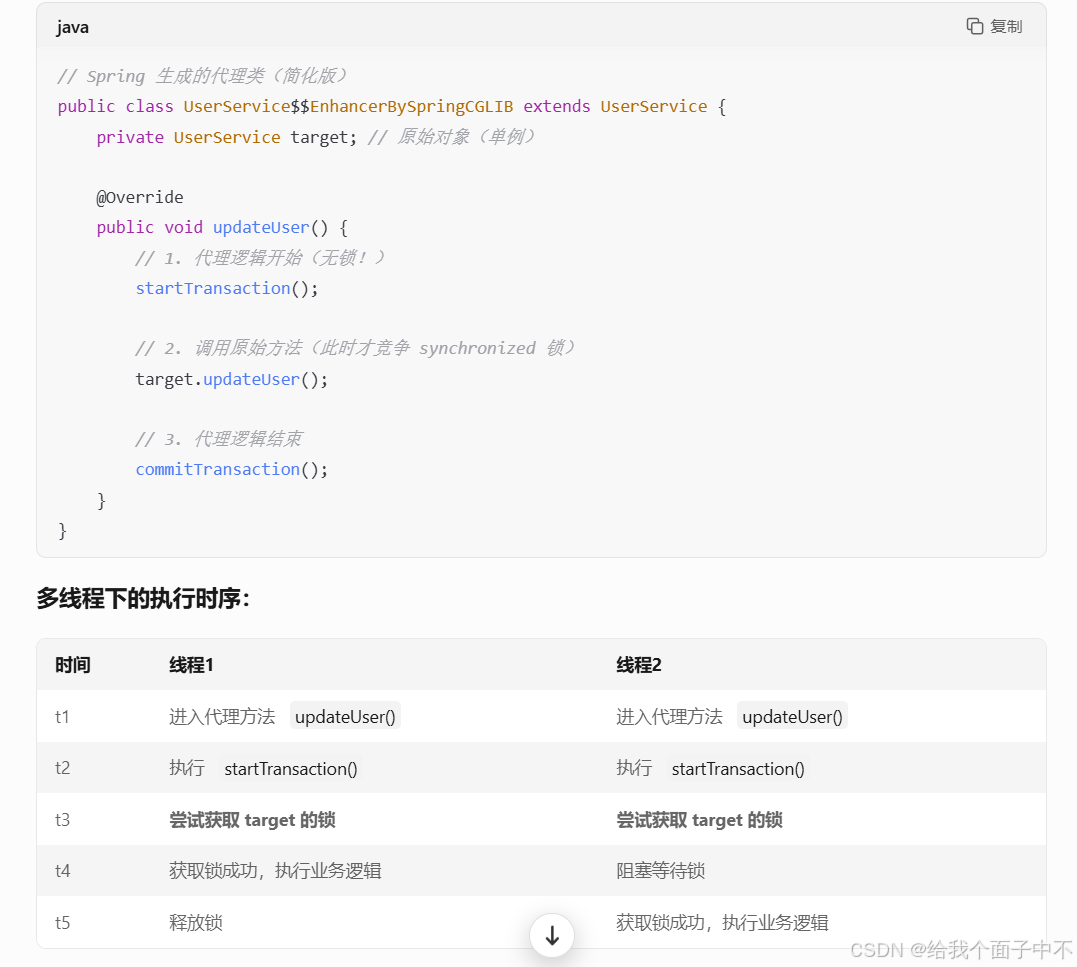
可以看一下下图里面fileInfoService的名字,可以看出是被代理过的对象。

3.批量移动文件
流程:
-
参数校验阶段
- 检查要移动的文件ID列表(
fileIds)是否与目标文件夹ID(filePid)相同,防止将文件移动到自身位置 - 如果目标文件夹不是根目录(
filePid ≠ 0),则验证该文件夹是否存在且有效
- 检查要移动的文件ID列表(
-
准备目标文件夹数据
- 将文件ID字符串拆分为数组(
fileIdArray) - 查询目标文件夹下现有的所有文件,并转换为以文件名为键的Map结构,用于快速查找
- 将文件ID字符串拆分为数组(
-
获取待移动文件列表
- 根据用户ID和文件ID数组,查询出所有需要移动的文件信息
-
执行文件移动操作
- 遍历待移动文件列表,对每个文件:
- 检查目标文件夹中是否已存在同名文件
- 如果存在同名文件,则自动生成新的文件名(重命名)
- 更新文件的父目录ID为目标文件夹ID
- 如果文件名冲突,则使用新生成的文件名
- 遍历待移动文件列表,对每个文件:
-
事务保障
- 整个操作过程在事务管理下进行,确保所有文件移动操作要么全部成功,要么全部回滚
-
异常处理
- 在参数校验和文件夹验证阶段,如果发现异常情况(如无效的目标文件夹),立即抛出业务异常终止操作
4.下载文件实现
流程:下载分为两步:获取下载链接(就是从后端获取一个code,这一步做登录校验)、根据code来真正的下载文件(不校验登录)。
为什么要分为两步:
如果浏览器集成了第三方插件,如果只有一个下载接口我们又希望校验(登录)之后才能下载,那么第三方插件拿不到我们的登录数据就不能实现下载功能。
获取下载链接流程:
校验如果是文件夹不允许下载,根据fileId和userId查询是否存在该文件,存在的话生成一个50位的随机字符串(code)。将这个code作为key,文件的路径和名字作为value,保存到redis中并设置过期时间。
下载文件流程:
从redis中获取文件的路径和名字,设置http响应头
- **
Content-Type**:声明文件为可下载类型(application/x-msdownload) - **
Content-Disposition**:强制浏览器下载而非预览,并指定文件名