了解 Transformer 模型,并基于 Transformer 模型实现在机器翻译任务上的应用!
Transformer 介绍
基于循环或卷积神经网络的序列到序列建模方法是现存机器翻译任务中的经典方法。然而,它们在建模文本长程依赖方面都存在一定的局限性。
为了更好地描述文字序列,谷歌的研究人员在 2017 年提出了一种新的模型 Transformer
Transformer 视频讲解
它摒弃了循环结构,并完全通过注意力机制完成对源语言序列和目标语言序列全局依赖的建模。在抽取每个单词的上下文特征时,Transformer 通过自注意力机制(self-attention)衡量上下文中每一个单词对当前单词的重要程度
Transformer 的主要组件包括编码器 (Encoder)、解码器 (Decoder) 和注意力层。其核心是利用多头自注意力机制(Multi-Head Self-Attention)
// 关于 Transformer的20题

layer
- sublayer
- multi-head self-attention
- positionwise feed-forword network
嵌入表示层
输入文本序列,生成词向量 + 位置编码
为了得到不同位置对应的编码,Transformer 模型使用不同频率的正余弦函数如下所示
P
E
p
o
s
,
2
i
=
sin
(
p
i
s
/
1000
0
2
i
/
d
)
PE_{pos, 2i}=\sin(pis/10000^{2i/d})
PEpos,2i=sin(pis/100002i/d)
P
E
p
o
s
,
2
i
+
1
=
cos
(
p
i
s
/
1000
0
2
i
/
d
)
PE_{pos, 2i+1}=\cos(pis/10000^{2i/d})
PEpos,2i+1=cos(pis/100002i/d)
注意力层
**自注意力(Self-Attention)**操作是基于 Transformer 的机器翻译模型的基本操作,在源语言的编码和目标语言的生成中频繁地被使用以建模源语言、目标语言任意两个单词之间的依赖关系
给定由单词语义嵌入及其位置编码叠加得到的输入表示
{
x
i
∈
R
d
}
i
=
1
t
\{x_{i} \in R^{d}\}_{i=1}^{t}
{xi∈Rd}i=1t
为了实现对上下文语义依赖的建模,进一步引入在自注意力机制中涉及到的三个元素:查询
q
i
(
Q
u
e
r
y
)
q_{i}(Query)
qi(Query) ,键
k
i
(
K
e
y
)
k_{i}(Key)
ki(Key) ,值
v
i
(
V
a
l
u
e
)
v_{i}(Value)
vi(Value)
通过位置
i
i
i 查询向量与其他位置的键向量做点积得到匹配分数
q
i
⋅
k
1
,
q
i
⋅
k
2
,
.
.
.
,
q
i
⋅
k
t
q_{i}\cdot k_{1},q_{i}\cdot k_{2},...,q_{i}\cdot k_{t}
qi⋅k1,qi⋅k2,...,qi⋅kt
Z
=
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
m
a
x
(
Q
K
T
d
)
V
Z=Attention(Q,K,V)=Softmax(\frac{QK^{T}}{\sqrt{d}})V
Z=Attention(Q,K,V)=Softmax(dQKT)V
其中
Q
∈
R
L
×
d
q
Q \in R^{L\times d_{q}}
Q∈RL×dq,
K
∈
R
L
×
d
k
K \in R^{L\times d_{k}}
K∈RL×dk,
V
∈
R
L
×
d
v
V \in R^{L\times d_{v}}
V∈RL×dv 分别表示输入序列中的不同单词的
q
,
k
,
v
q,k,v
q,k,v 向量拼接组成的矩阵,L 表示序列长度,
Z
∈
R
L
×
d
v
Z \in R^{L\times d_{v}}
Z∈RL×dv 表示自注意力操作的输出,
d
\sqrt{d}
d 表示稳定优化的放缩因子
//🤡
前馈层
前馈层接受自注意力子层的输出作为输入,并通过一个带有 Relu 激活函数的两层全连接网络对输入进行更加复杂的非线性变换
F
F
N
(
x
)
=
R
e
l
u
(
x
W
1
+
b
1
)
W
2
+
b
2
FFN(x)=Relu(xW_{1}+b_{1})W_{2}+b_{2}
FFN(x)=Relu(xW1+b1)W2+b2
其中
W
1
,
b
1
,
W
2
,
b
2
W_{1},b_{1},W_{2},b_{2}
W1,b1,W2,b2 表示前馈子层的参数。另外,以往的训练发现,增大前馈子层隐状态的维度有利于提升最终翻译结果的质量,因此,前馈子层隐状态的维度一般比自注意力子层要大。
//🙈
残差连接与层归一化
Transformer 结构组成的网络结构通常都是非常庞大而复杂,这就导致模型的训练比较困难。研究者们在 Transformer 块中进一步引入了残差连接与层归一化技术以进一步提升训练的稳定性。
具体来说,残差连接主要是指使用一条直连通道直接将对应子层的输入连接到输出上去,从而避免由于网络过深在优化过程中潜在的梯度消失问题
x
l
+
1
=
f
(
x
l
)
+
x
l
x^{l+1}=f(x^l)+x^l
xl+1=f(xl)+xl
其中
x
l
x^l
xl 表示第
l
l
l 层的输入,
f
(
⋅
)
f(\cdot)
f(⋅) 表示一个映射函数
此外,为了进一步使得每一层的输入输出范围稳定在一个合理的范围内,层归一化技术被进一步引入每个 Transformer 块的当中:
L N ( x ) = α ⋅ x − μ σ + b LN(x)=\alpha \cdot \frac{x-\mu}{\sigma} + b LN(x)=α⋅σx−μ+b
其中 μ \mu μ 和 σ \sigma σ 分别表示均值和方差,用于将数据平移缩放到均值为 0,方差为 1 的标准分布, a a a 和 b b b 是可学习的参数。层归一化技术可以有效地缓解优化过程中潜在的不稳定、收敛速度慢等问题。
编码器和解码器结构

相比于编码器端,解码器端要更复杂一些。具体来说,解码器的每个 Transformer 块的第一个自注意力子层额外增加了注意力掩码,对应图中的掩码多头注意力(Masked Multi-Head Attention)部分
在翻译的过程中,编码器端主要用于编码源语言序列的信息,而这个序列是完全已知的,因而编码器仅需要考虑如何融合上下文语义信息即可。而解码端则负责生成目标语言序列,这一生成过程是自回归的,即对于每一个单词的生成过程,仅有当前单词之前的目标语言序列是可以被观测的,因此这一额外增加的掩码是用来掩盖后续的文本信息,以防模型在训练阶段直接看到后续的文本序列进而无法得到有效地训练。
此外,解码器端还额外增加了一个多头注意力(Multi-Head Attention)模块,使用交叉注意力(Cross-attention)方法,同时接收来自编码器端的输出以及当前 Transformer 块的前一个掩码注意力层的输出
//🙃
基于 task2 的 baseline 修改代码
主要修改模型结构部分的代码:
# 位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
# Transformer
class TransformerModel(nn.Module):
def __init__(self, src_vocab, tgt_vocab, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout):
super(TransformerModel, self).__init__()
self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout)
self.src_embedding = nn.Embedding(len(src_vocab), d_model)
self.tgt_embedding = nn.Embedding(len(tgt_vocab), d_model)
self.positional_encoding = PositionalEncoding(d_model, dropout)
self.fc_out = nn.Linear(d_model, len(tgt_vocab))
self.src_vocab = src_vocab
self.tgt_vocab = tgt_vocab
self.d_model = d_model
def forward(self, src, tgt):
# 调整src和tgt的维度
src = src.transpose(0, 1) # (seq_len, batch_size)
tgt = tgt.transpose(0, 1) # (seq_len, batch_size)
src_mask = self.transformer.generate_square_subsequent_mask(src.size(0)).to(src.device)
tgt_mask = self.transformer.generate_square_subsequent_mask(tgt.size(0)).to(tgt.device)
src_padding_mask = (src == self.src_vocab['<pad>']).transpose(0, 1)
tgt_padding_mask = (tgt == self.tgt_vocab['<pad>']).transpose(0, 1)
src_embedded = self.positional_encoding(self.src_embedding(src) * math.sqrt(self.d_model))
tgt_embedded = self.positional_encoding(self.tgt_embedding(tgt) * math.sqrt(self.d_model))
output = self.transformer(src_embedded, tgt_embedded,
src_mask, tgt_mask, None, src_padding_mask, tgt_padding_mask, src_padding_mask)
return self.fc_out(output).transpose(0, 1)
其他上分技巧
-
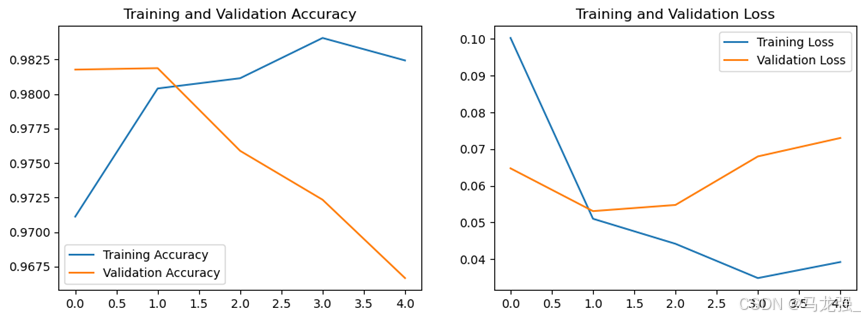
最简单的就是调参,将 epochs 调大一点,使用全部训练集,以及调整模型的参数,如head、layers等。如果数据量允许,增加模型的深度(更多的编码器/解码器层)或宽度(更大的隐藏层尺寸),这通常可以提高模型的表达能力和翻译质量,尤其是在处理复杂或专业内容时。
-
加入术语词典,这是在此竞赛中比较有效的方法,加入术语词典的方法策略也有很多,如:
-
在模型生成的翻译输出中替换术语,这是最简单的方法
-
整合到数据预处理流程,确保它们在翻译中保持一致
-
在模型内部动态地调整术语的嵌入,这涉及到在模型中加入一个额外的层,该层负责查找术语词典中的术语,并为其生成专门的嵌入向量,然后将这些向量与常规的词嵌入结合使用
-
-
认真做数据清洗,我们在 Task2 已经提到过当前训练集存在脏数据的问题,会影响我们的模型训练
-
数据扩增:
-
回译(back-translation):将源语言文本先翻译成目标语言,再将目标语言文本翻译回源语言,生成的新文本作为额外的训练数据
-
同义词替换:随机选择句子中的词,并用其同义词替换
-
使用句法分析和语义解析技术重新表述句子,保持原意不变
-
将文本翻译成多种语言后再翻译回原语言,以获得多样化翻译
-
-
采用更精细的学习率调度策略(baseline我们使用的是固定学习率):
-
Noam Scheduler:结合了warmup阶段和衰减阶段
-
Step Decay:最简单的一种学习率衰减策略,每隔一定数量的epoch,学习率按固定比例衰减
-
Cosine Annealing:学习率随周期性变化,通常从初始值下降到接近零,然后再逐渐上升
-
-
自己训练一个小的预训练模型,尽量选择 1B 以下小模型,对 GPU 资源要求比较高,仅仅使用魔搭平台可能就满足不了
-
将训练集上训练出来的模型拿到开发集(dev dataset)上 finetune 可以提高测试集(test dataset)的得分,因为开发集与测试集的分布比较相近
-
在开发集和测试集上训一个语言模型,用这个语言模型给训练集中的句子打分,选出一些高分句子
-
集成学习:训练多个不同初始化或架构的模型,并使用集成方法(如投票或平均)来产生最终翻译。这可以减少单一模型的过拟合风险,提高翻译的稳定性。
课后思考
相比于组队学习的课程,夏令营/竞赛不会手把手教你怎么做,需要自己动手实践
当然了,两者同样有读不懂的理论学习🥺
说实话,幸好能白嫖,让我在笔记本老伙计上训练模型我都不舍得😋
我有一个坏习惯,就是老是喜欢重复运行,试图发现偶然因素导致的错误。
实际上计算机很少掷骰子,如果结果不理想,要多在自己身上找原因,运行之前先排除基本错误