博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。
博客内容主要围绕:
5G/6G协议讲解
算力网络讲解(云计算,边缘计算,端计算)
高级C语言讲解
Rust语言讲解
利用蒙特卡罗法求解 𝜋 的近似值(MPI方法)

MPI
在单一程序中管理所有设备可能比较麻烦。这类工作通常看来就像我们目前所做的那样,对所有的可用设备进行循环,每次循环执行相同的操作(例如启动核函数)。使用 MPI(消息传递接口)可以大大简化程序。使用 MPI 时,我们独立多次启动相同的程序(单程序多数据范例)。在最常见的使用情况下,我们会在您的服务器中启动尽可能多的独立进程副本,并且每个副本只使用一个 GPU。
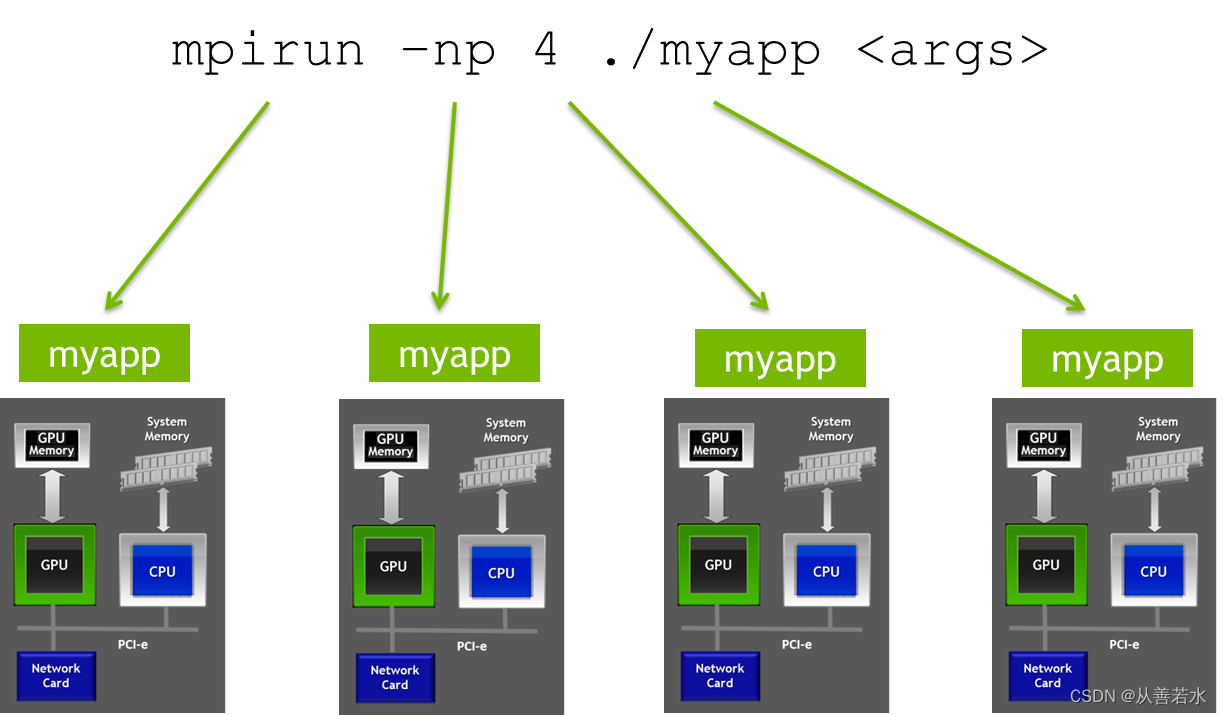
MPI Rank (成员编号)
每个独立进程都有一个唯一数字标识符与之相关联(称为它的 rank),并可提供信息,显示运行中的总进程数量。我们可以通过编程方式使用MPI_Comm_rank()来获取每个进程的rank,以及使用MPI_Comm_size()来获取进程的数量。有了这些信息,我们可以让每个成员做出独立的处理决策(同时仍然只使用源代码的一个副本)。例如,我们可以用cudaSetDevice()把 GPU(任意)设置为等于 MPI rank(假设成员的数量最多与 GPU 数量持平)。
有了 MPI,每个成员都可以直接独立地执行它的 N / number_of_gpus 次计算,然后对计算结果求和。这确实是使用 MPI 编写这类程序的最常见方法。
使用MPI
以下是在代码中使用 MPI 的一些详细信息。
初始化和结束MPI
必须在 MPI 程序的开头优先初始化 MPI,并在末尾结束使用MPI。
// Initialize MPI
MPI_Init(&argc, &argv);
...
// Finalize MPI
MPI_Finalize();
获取成员编号(rank)和成员数
得到成员编号(rank)和成员的总数。
int rank, num_ranks;
// MPI_COMM_WORLD 意味着我们想要包含所有进程。
// 在 MPI 中,可以创建只包含某些成员的“通信器”。
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &num_ranks);
将 GPU 与 MPI 成员关联
我们为每个成员选择一个 GPU。
// 每个成员(任意)选择与其成员号 rank 相对应的 GPU
int dev = rank;
cudaSetDevice(dev);
收集结果
在我们的程序中,我们将对所有成员的结果进行求和(归约),并将结果存储在某个成员中,该成员将执行最终计算并打印结果。按照惯例,这是 0 号成员 rank 0(通常称为“根”处理器)。
对于此类归约,我们将使用 MPI_Reduce,它指定需要归约的数据的位置(hits)、进行归约后的结果的位置(total_hits)、归约的项目数量(1)、归约的数据类型(MPI_INT)、归约要执行的操作(MPI_SUM)、存储结果的成员(root),以及哪些进程参与通信(MPI_COMM_WORLD)。
// 将所有成员的结果累加到第 0 号成员的结果中
int* total_hits;
total_hits = (int*) malloc(sizeof(int));
int root = 0;
MPI_Reduce(hits, total_hits, 1, MPI_INT, MPI_SUM, root, MPI_COMM_WORLD);
if (rank == root) {
// 计算 pi 的最终值并打印结果
...
}
使用例子
#include <iostream>
#include <curand_kernel.h>
#include <mpi.h>
#define N 1024*1024
__global__ void calculate_pi(int* hits, int device) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
// 初始化随机数状态(网格中的每个线程不得重复)
int seed = device;
int offset = 0;
curandState_t curand_state;
curand_init(seed, idx, offset, &curand_state);
// 在 (0.0, 1.0] 内生成随机坐标
float x = curand_uniform(&curand_state);
float y = curand_uniform(&curand_state);
// 如果这一点在圈内,增加点击计数器
if (x * x + y * y <= 1.0f) {
atomicAdd(hits, 1);
}
}
int main(int argc, char** argv) {
// 初始化 MPI
MPI_Init(&argc, &argv);
// 获取我们的rank和rank总数
// MPI_COMM_WORLD 意味着我们想要包含所有进程
// (可以在 MPI 中创建仅
// 包含某些rank的“通信器”)。
int rank, num_ranks;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &num_ranks);
// 确保我们的rank个数不超过 GPU 数量
int device_count;
cudaGetDeviceCount(&device_count);
if (num_ranks > device_count) {
std::cout << "Error: more MPI ranks than GPUs" << std::endl;
return -1;
}
// 每个rank(任意)选择与其rank对应的 GPU
int dev = rank;
cudaSetDevice(dev);
// 分配主机和设备值
int* hits;
hits = (int*) malloc(sizeof(int));
int* d_hits;
cudaMalloc((void**) &d_hits, sizeof(int));
// 初始化点击次数并复制到设备
*hits = 0;
cudaMemcpy(d_hits, hits, sizeof(int), cudaMemcpyHostToDevice);
// 启动核函数进行计算
int threads_per_block = 256;
int blocks = (N / device_count + threads_per_block - 1) / threads_per_block;
calculate_pi<<<blocks, threads_per_block>>>(d_hits, dev);
cudaDeviceSynchronize();
// 将最终结果复制回主机
cudaMemcpy(hits, d_hits, sizeof(int), cudaMemcpyDeviceToHost);
// 将所有rank的结果累加到 rank 0 的结果中
int* total_hits;
total_hits = (int*) malloc(sizeof(int));
int root = 0;
MPI_Reduce(hits, total_hits, 1, MPI_INT, MPI_SUM, root, MPI_COMM_WORLD);
if (rank == root) {
// 计算 pi 的最终值
float pi_est = (float) *total_hits / (float) (N) * 4.0f;
// 打印结果
std::cout << "Estimated value of pi = " << pi_est << std::endl;
std::cout << "Error = " << std::abs((M_PI - pi_est) / pi_est) << std::endl;
}
// 清理
free(hits);
cudaFree(d_hits);
// 最终确定 MPI
MPI_Finalize();
return 0;
}





![[计算机毕业设计]食品安全数据的关联分析模型的应用](https://img-blog.csdnimg.cn/632f16aceeee4be6a8443d20fb0be8d8.png)

![[附源码]java毕业设计社团管理系统](https://img-blog.csdnimg.cn/095fbfab18554148afc5cde52d542ec6.png)