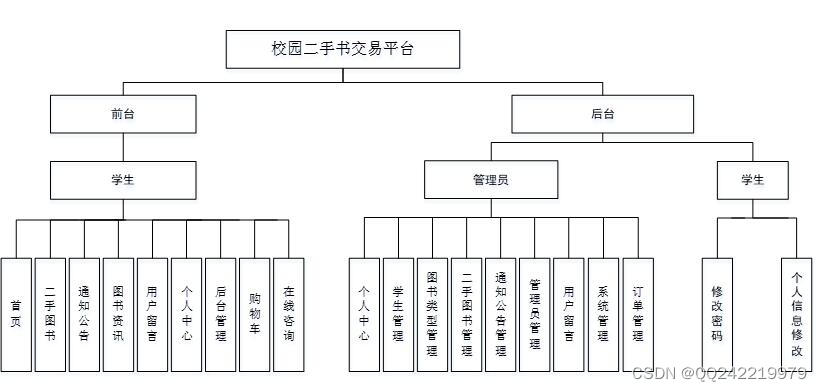
一、内容提要
一条SQL语句是如何被解析的?
一条SQL是如何转换为代码被机器执行的?
SQL从逻辑计划到物理计划的转换经历了怎样的优化?
二、Antlr4
Antlr4 Java编写的强大的语法解析生成器
# 命令行使用方式
curl -O https://raw.githubusercontent.com/apache/spark/master/sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4
antlr4 SqlBase.g4
javac SqlBase*.java
grun SqlBase statement -gui -- 样例一: t1表,里面有字段ageselect * from t1 where t1.age > 10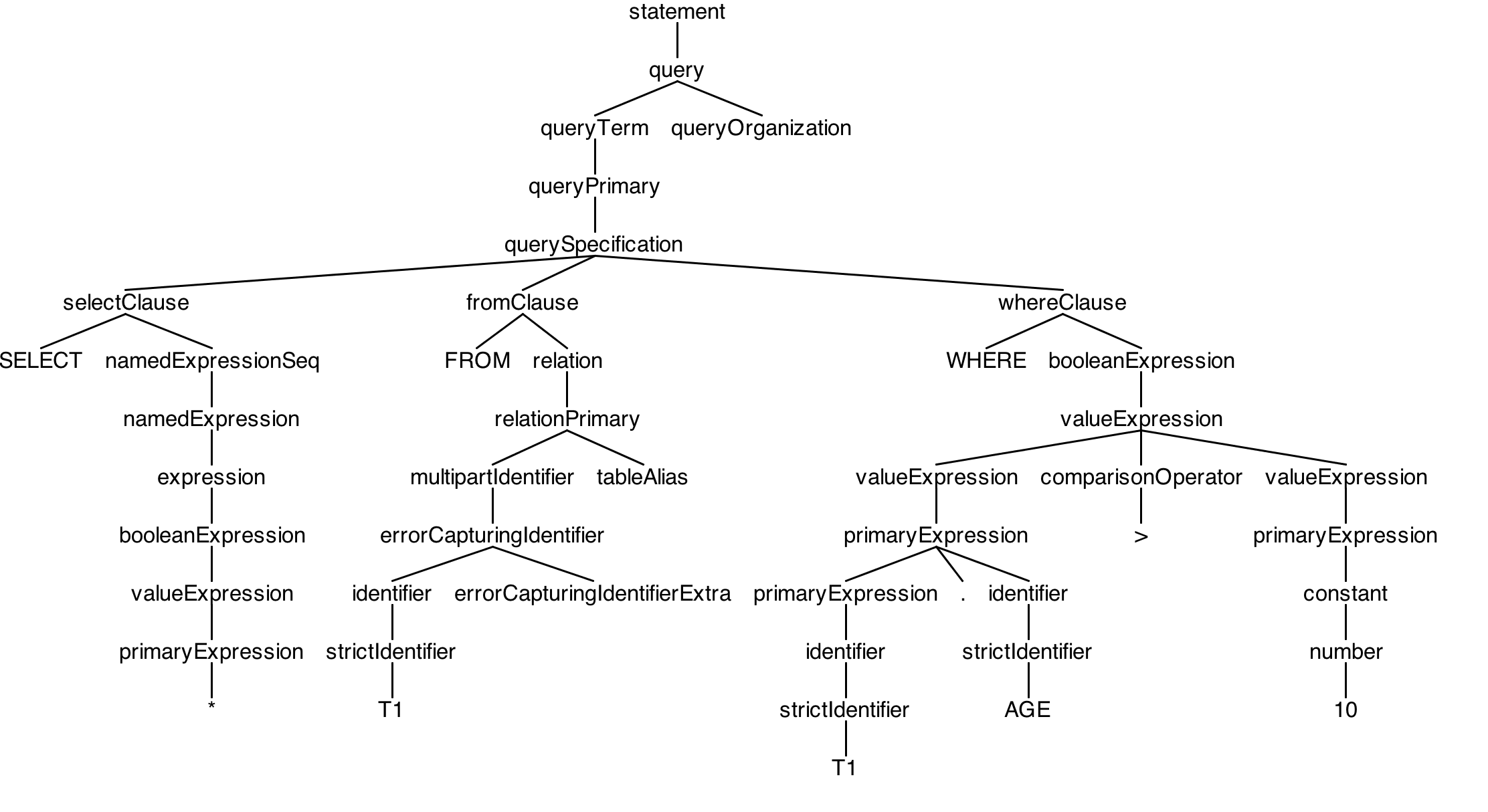
-- 样例二: event 表,user 表, 两张表Join,关联字段为distinct_id字段,并且用户表中age>25, 最后统计条数selectcount(1) asnumfrom
(
select event.distinct_id fromeventjoinuseronuser.distinct_id=event.distinct_id
whereuser.age > 25
)
as t1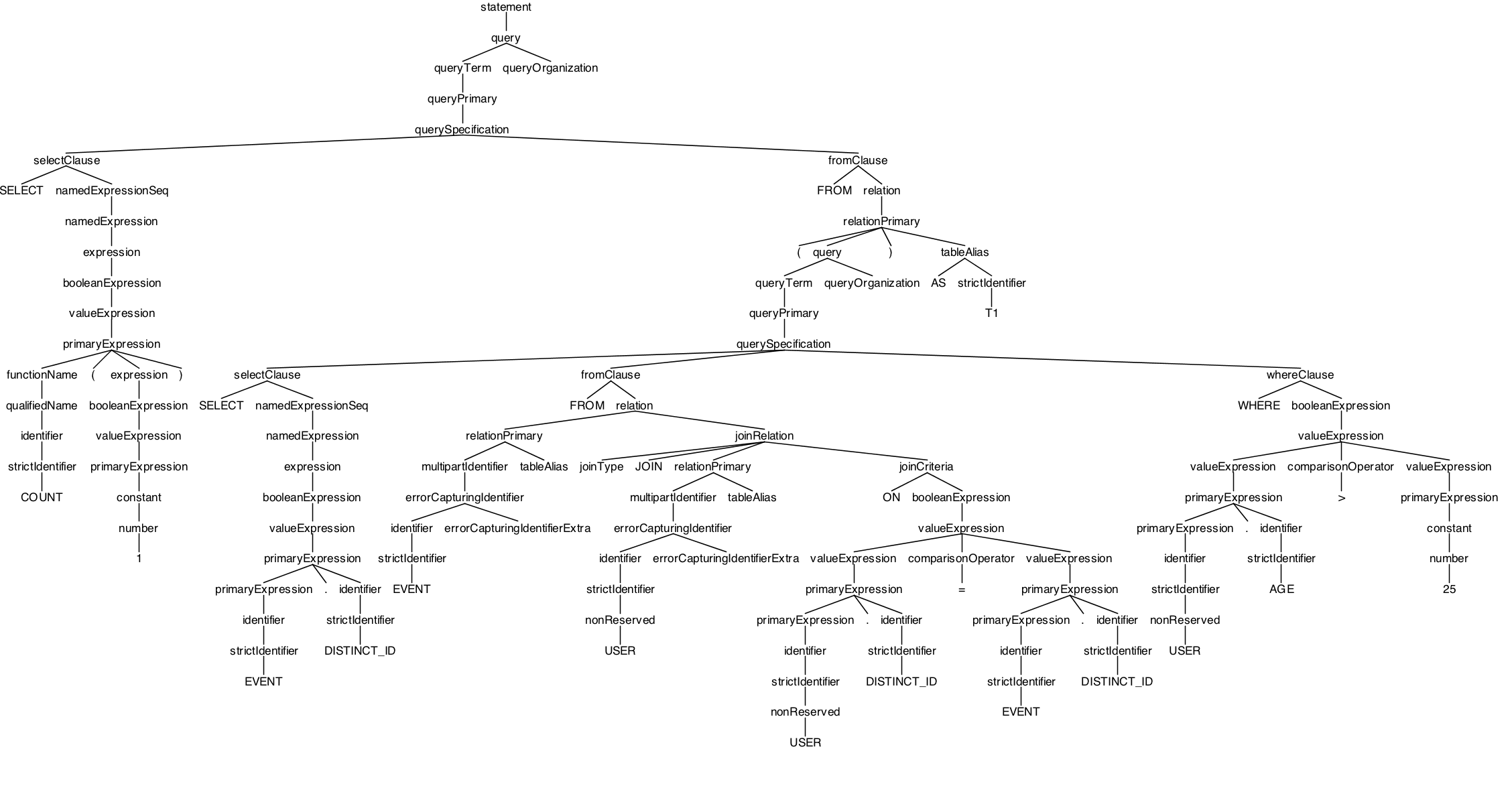
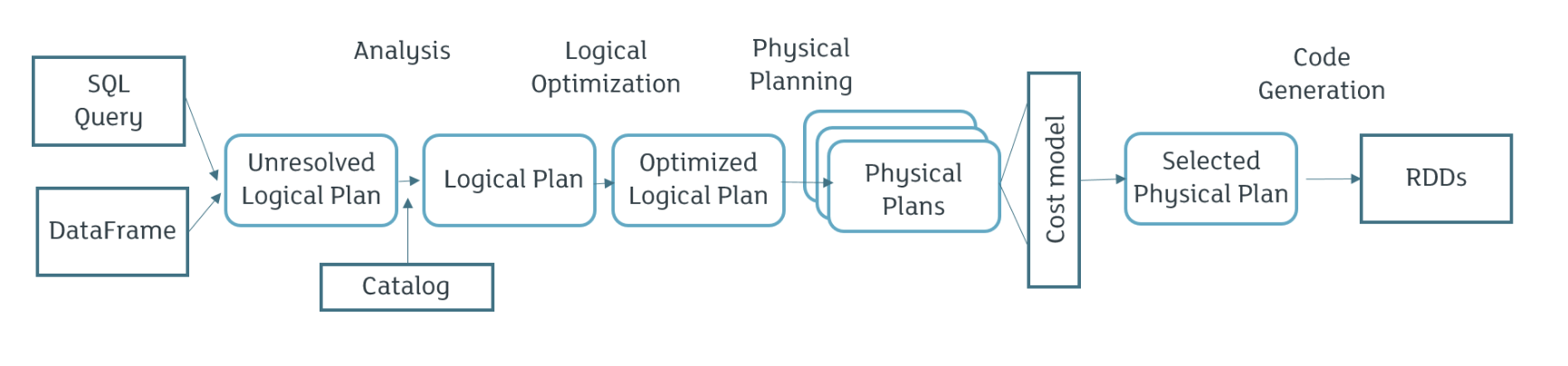
三、 LogicalPlan
遍历AST树(就是上一步Antlr4解析生成的语法树)生成未解析的逻辑计划
== ParsedLogicalPlan ==
'Project ['count(1) AS num#221]
+- 'SubqueryAlias t1
+- 'Project ['event.distinct_id]
+- 'Filter ('user.age > 25)
+- 'JoinInner, ('user.distinct_id = 'event.distinct_id)
:- 'UnresolvedRelation [event]
+- 'UnresolvedRelation [user]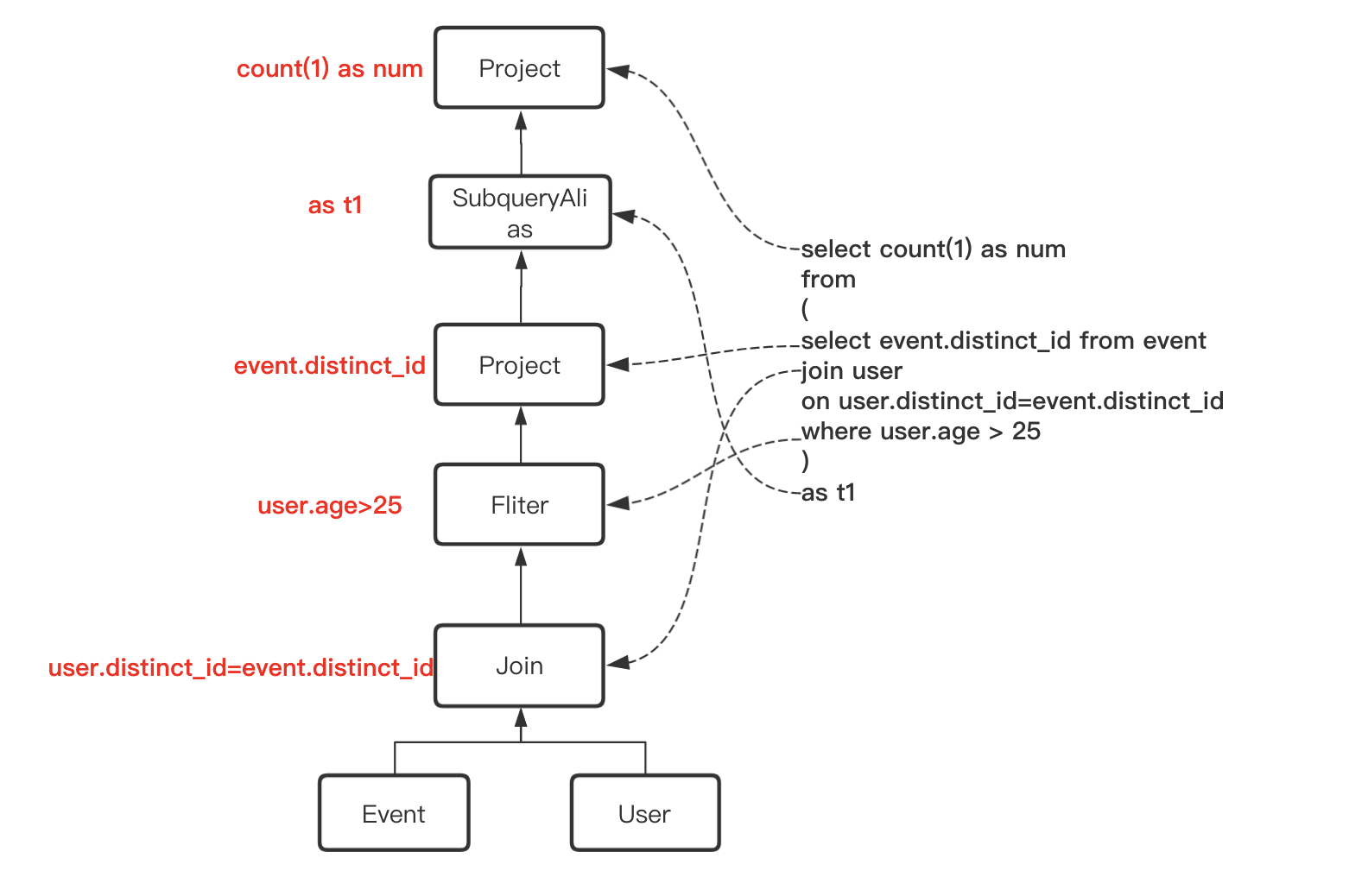
四、Analyzed Logical Plan
将上一步生成的逻辑计划和元数据做关联,生成解析后逻辑计划
== Analyzed Logical Plan ==num: bigint
Aggregate [count(1) AS num#221L]
+- SubqueryAlias t1
+- Project [distinct_id#236]
+- Filter (cast(age#257 as int) > 25)
+- Join Inner, (distinct_id#259= distinct_id#236)
:- SubqueryAlias spark_catalog.ods_news.event
: +- Relation[_hoodie_commit_time#223,_hoodie_commit_seqno#224,_hoodie_record_key#225,_hoodie_partition_path#226,_hoodie_file_name#227,action_type#228,app_version#229,article_id#230,battery_level#231,carrier#232,client_time#233,ctime#234L,device_id#235,distinct_id#236,element_name#237,element_page#238,event#239,imei#240,ip#241,is_charging#242,manufacturer#243,model#244,network_type#245,os#246,... 5 more fields] parquet
+- SubqueryAlias spark_catalog.ods_news.user
+- Relation[_hoodie_commit_time#252,_hoodie_commit_seqno#253,_hoodie_record_key#254,_hoodie_partition_path#255,_hoodie_file_name#256,age#257,ctime#258L,distinct_id#259,email#260,gender#261,logday#262,mobile#263,name#264,nick_name#265,signup_time#266L,type#267,uuid#268] parquet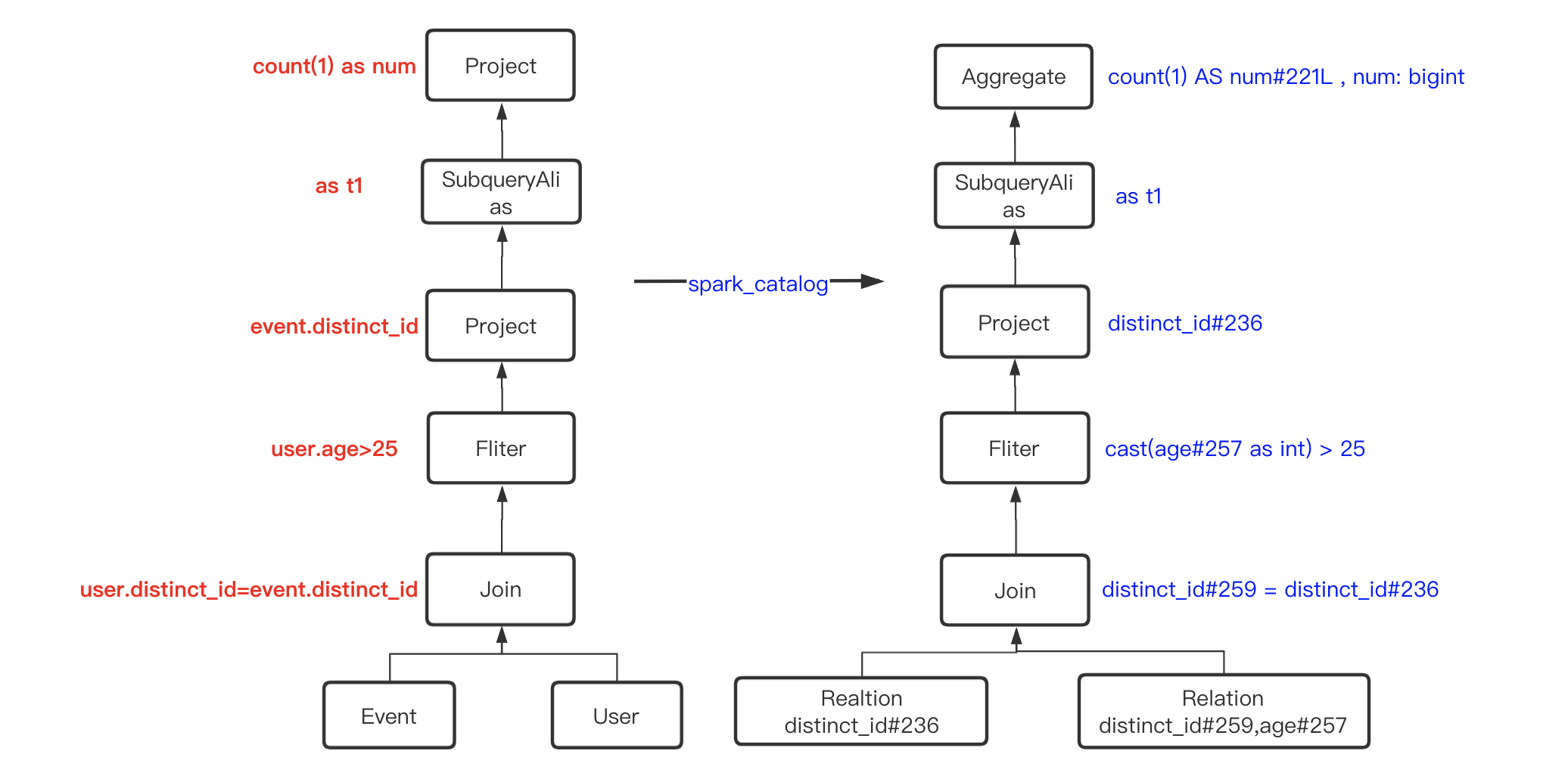
五、Optimized Logical Plan
基于RBO规则,对上一步解析后的逻辑计划做优化,比如谓词下推,列裁剪等等
== Optimized Logical Plan ==
Aggregate [count(1) AS num#221L]
+- Project
+- Join Inner, (distinct_id#259= distinct_id#236)
:- Project [distinct_id#236]
: +- Filter isnotnull(distinct_id#236)
: +- Relation[_hoodie_commit_time#223,_hoodie_commit_seqno#224,_hoodie_record_key#225,_hoodie_partition_path#226,_hoodie_file_name#227,action_type#228,app_version#229,article_id#230,battery_level#231,carrier#232,client_time#233,ctime#234L,device_id#235,distinct_id#236,element_name#237,element_page#238,event#239,imei#240,ip#241,is_charging#242,manufacturer#243,model#244,network_type#245,os#246,... 5 more fields] parquet
+- Project [distinct_id#259]
+- Filter ((isnotnull(age#257) AND (cast(age#257 as int) > 25)) AND isnotnull(distinct_id#259))
+- Relation[_hoodie_commit_time#252,_hoodie_commit_seqno#253,_hoodie_record_key#254,_hoodie_partition_path#255,_hoodie_file_name#256,age#257,ctime#258L,distinct_id#259,email#260,gender#261,logday#262,mobile#263,name#264,nick_name#265,signup_time#266L,type#267,uuid#268] parquet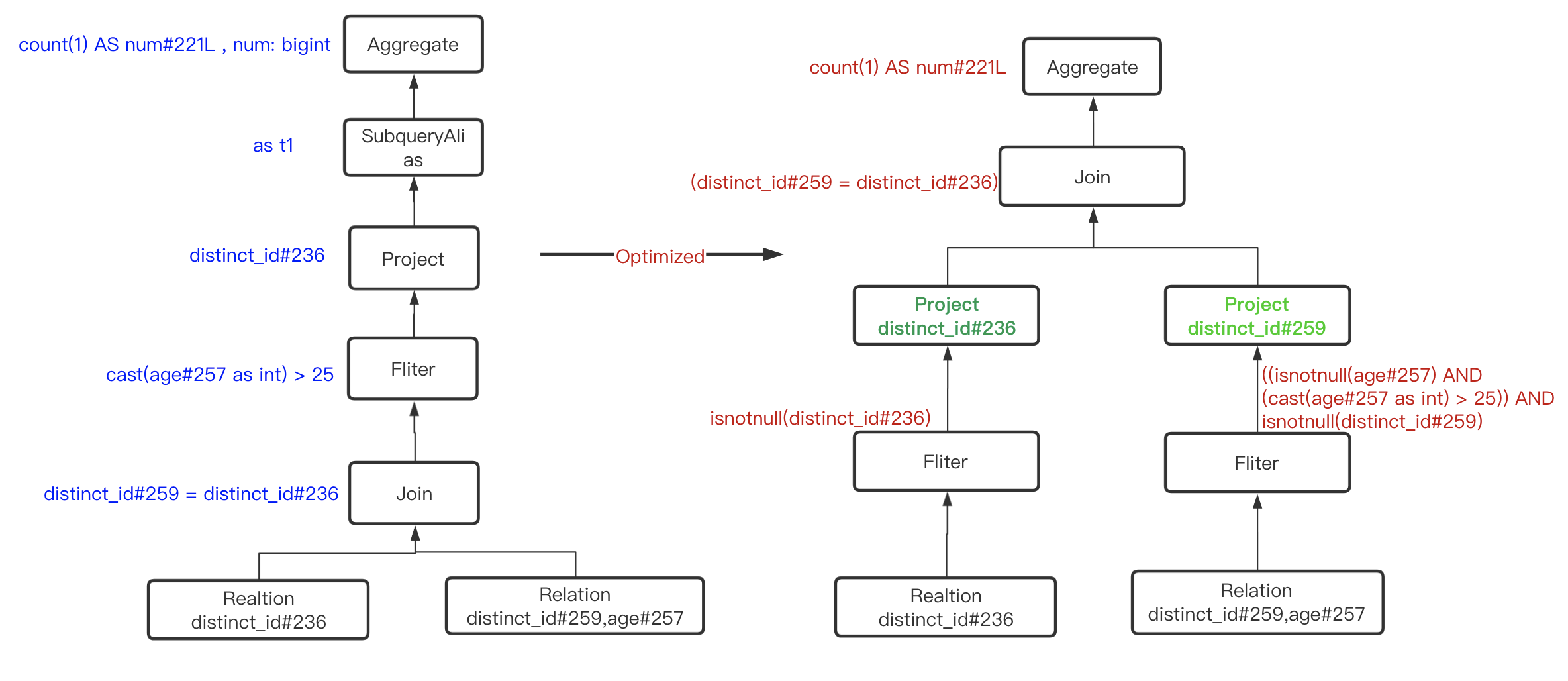
六、Physical Plan
将RBO优化过的逻辑计划,生成物理计划,其中加入CBO优化策略
== Physical Plan ==
*(3) HashAggregate(keys=[], functions=[count(1)], output=[num#221L])
+- Exchange SinglePartition, true, [id=#220]
+- *(2) HashAggregate(keys=[], functions=[partial_count(1)], output=[count#271L])
+- *(2) Project
+- *(2) BroadcastHashJoin [distinct_id#236], [distinct_id#259], Inner, BuildRight
:- *(2) Project [distinct_id#236]
: +- *(2) Filter isnotnull(distinct_id#236)
: +- *(2) ColumnarToRow
: +- FileScan parquet ods_news.event[distinct_id#236,logday#251] Batched: true, DataFilters: [isnotnull(distinct_id#236)], Format: Parquet, Location: CatalogFileIndex[hdfs://namenode:8020/sources/hudi/cow/event], PartitionFilters: [], PushedFilters: [IsNotNull(distinct_id)], ReadSchema: struct<distinct_id:string>
+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, string, true])), [id=#214]
+- *(1) Project [distinct_id#259]
+- *(1) Filter ((isnotnull(age#257) AND (cast(age#257 as int) > 25)) AND isnotnull(distinct_id#259))
+- *(1) ColumnarToRow
+- FileScan parquet ods_news.user[age#257,distinct_id#259] Batched: true, DataFilters: [isnotnull(age#257), (cast(age#257 as int) > 25), isnotnull(distinct_id#259)], Format: Parquet, Location: InMemoryFileIndex[hdfs://namenode:8020/sources/hudi/cow/user], PartitionFilters: [], PushedFilters: [IsNotNull(age), IsNotNull(distinct_id)], ReadSchema: struct<age:string,distinct_id:string>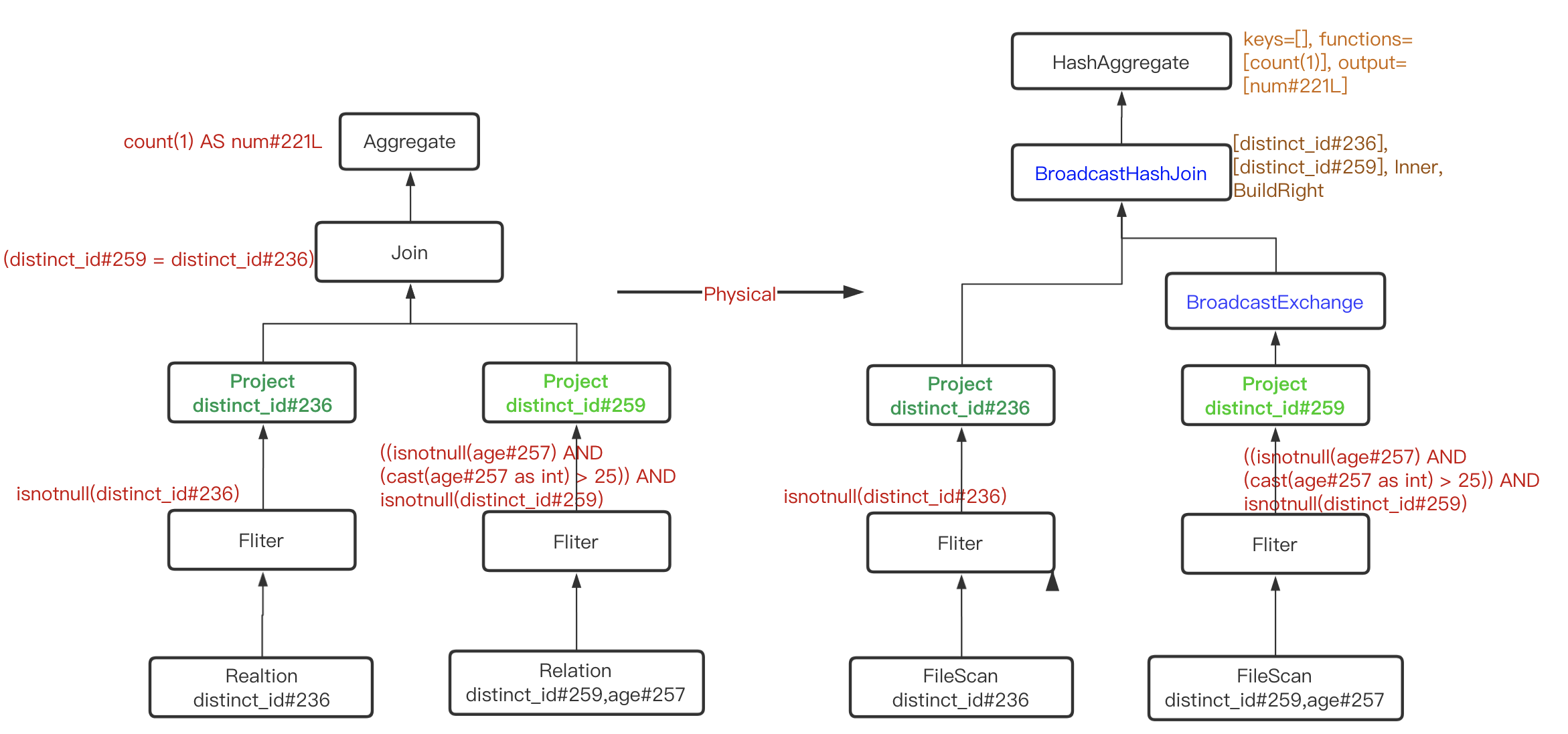


![[JavaWeb]JS](https://img-blog.csdnimg.cn/e482cfe78484450d87284fab9a219cdf.png)