文件操作(下)
- 5、文件的顺序读写
- 5.1 顺序读写函数介绍
- 5.1.1 fputc与fgetc
- 5.1.2 fputs与fgets
- 5.1.3 fprintf与fscanf
- 5.1.4 fread与fwrite
- 5.2 对比一组函数
- 6. 文件的随机读写
- 6.1 fseek
- 6.2 ftell
- 6.3 rewind
- 7. 文件读取结束的判定
- 7.1 被错误使用的feof
- 8. 文件缓冲区
5、文件的顺序读写
5.1 顺序读写函数介绍
5.1.1 fputc与fgetc
请看:
文件操作(上)
5.1.2 fputs与fgets
fputs: 文本行输出函数
int fputs ( const char * str, FILE * stream );
// 字符串指针 文件指针
代码:
int main()
{
//1.打开文件
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//2.写文件
fputs("I am a student.\n", pf);//\n换行
fputs("are you ok???\n", pf);
//3.关闭文件
fclose(pf);
pf = NULL;
return 0;
}
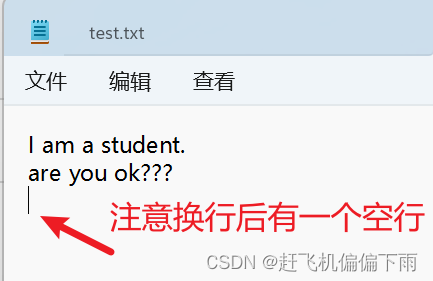
程序执行结果:文件中写入两行字符串,换行后有一个空行!
fgets:
char * fgets ( char * str, int num, FILE * stream );
// 字符串指针 读取的字符个数 文件指针
举例1:
往文件中放入以下内容

代码:
int main()
{
//1.打开文件
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//2.读文件
char arr[20] = "xxxxxxxxxxxxxxxxxxxx";
fgets(arr, 5, pf);//要读5个字符
printf("%s\n", arr);
//3.关闭文件
fclose(pf);
pf = NULL;
return 0;
}
调试观察:
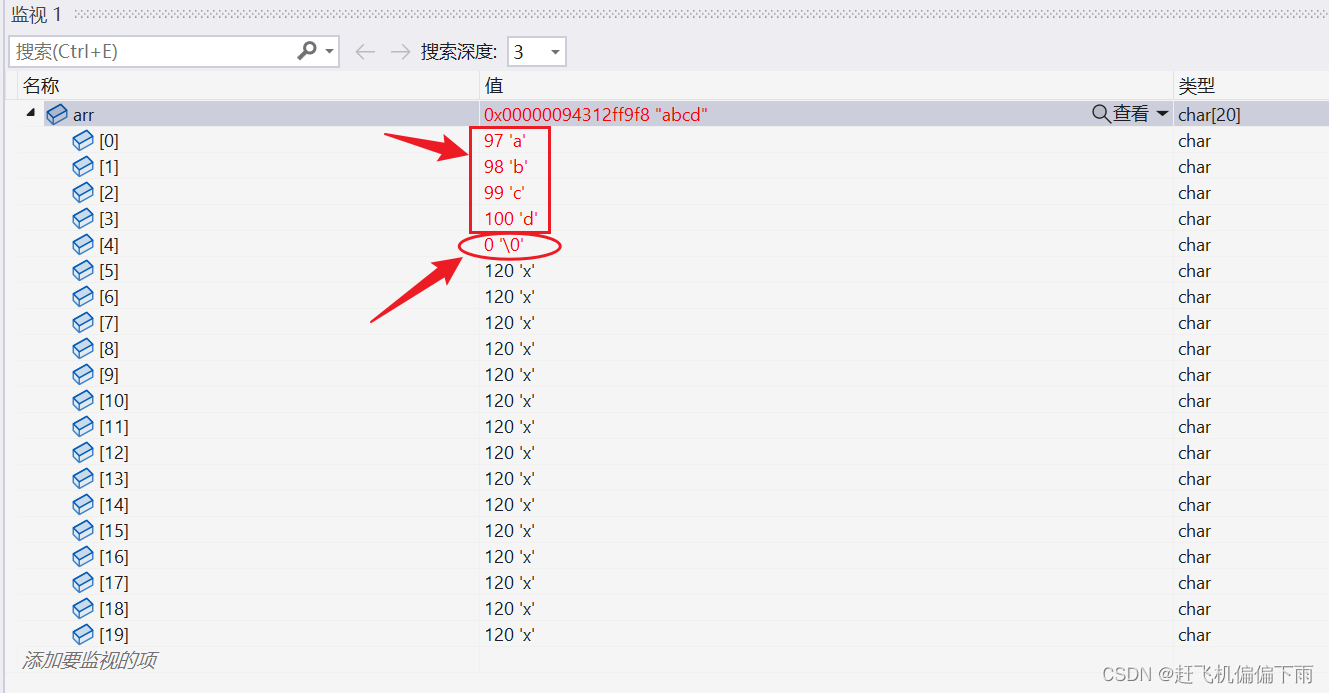
通过观察发现,我们要读取5个字符,但实际只读取了4个有效字符"abcd",末尾自动添加一个"\0",也就是只读取了n-1个字符
运行结果:打印"abcd"
举例2: 文本行输入函数
往文件中放入以下内容

代码:
int main()
{
//1.打开文件
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//2.读文件
char arr[20] = "xxxxxxxxxxxxxxxxxxxx";
fgets(arr, 10, pf);//要读10个字符
printf("%s\n", arr);
//3.关闭文件
fclose(pf);
pf = NULL;
return 0;
}
调试观察:
可以观察到只读取了5个有效字符,还有一个"\n"和一个"\0",也就是说当遇到换行时,后标的字符都不会再读取,当然末尾是依旧要补"\0"的
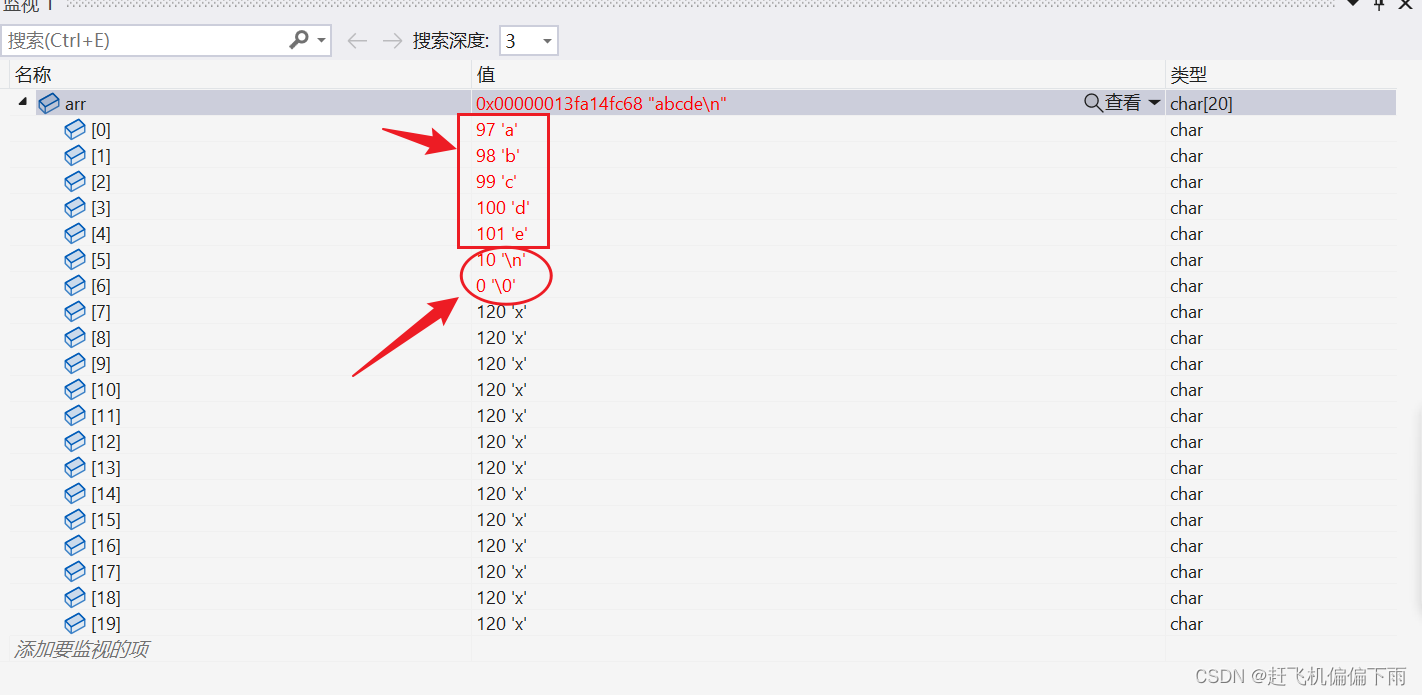
运行结果:打印"abcde"
5.1.3 fprintf与fscanf
首先要明白一个概念
什么是可变参数列表?
例如:printf
//printf
int printf ( const char * format, ... );
// 可变参数列表
举例:参数的数量是可变的
int main()
{
printf("abcde\n");//一个参数
printf("%d\n", 100);//两个参数
printf("%d %c\n", 100, 'a');//三个参数
return 0;
}
进入正题:
fprintf: 格式化输出函数
//fprintf
int fprintf ( FILE * stream, const char * format, ... );
// 文件指针 可变参数列表
代码:
struct S
{
char name[20];
int age;
float score;
};
int main()
{
struct S s = { "xiaoming", 18, 99.0f };
//1.打开文件
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//2.写文件
fprintf(pf, "%s %d %.1f", s.name, s.age, s.score);//格式化的输出函数
//3.关闭文件
fclose(pf);
pf = NULL;
return 0;
}
运行结果:结构体中的内容被写到了文件中

fscanf: 格式化输入函数
int fscanf ( FILE * stream, const char * format, ... );//从文件中读
用上文中fprintf向文件中输出的结果为例
代码:
struct S
{
char name[20];
int age;
float score;
};
int main()
{
struct S s = { 0 };
//1.打开文件
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//2.读文件
fscanf(pf, "%s %d %f", s.name, &(s.age), &(s.score));//格式化的输入函数
//将读取的结果打印出来
fprintf(stdout, "%s %d %.1f", s.name, s.age, s.score);
//3.关闭文件
fclose(pf);
pf = NULL;
return 0;
}
程序执行结果:成功读取到了文件中的内容,并打印在了屏幕上

5.1.4 fread与fwrite
fwrite: 将ptr指向的空间中count个大小为size的数据写到文件中
size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
// ptr指向的空间 大小 个数 文件指针
代码:
struct S
{
char name[20];
int age;
float score;
};
int main()
{
struct S s = { "wangwu",18,66.6f };
//1. 打开文件
FILE* pf = fopen("test.txt", "wb");//二进制的写
if (pf == NULL)
{
perror("fopen");
return 1;
}
//2. 写文件
fwrite(&s, sizeof(struct S), 1, pf);//将s所指向空间中大小为sizeof(struct S)的1个数据写到pf所指向的文件中
//3. 关闭文件
fclose(pf);
pf = NULL;
return 0;
}
运行结果:因为写入的是二进制的信息,所以人是看不懂的
fread: 从文件中读取count个大小为size的数据存放到ptr指向的空间中
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
// ptr指向的空间 大小 个数 文件指针
代码:
//fread
struct S
{
char name[20];
int age;
float score;
};
int main()
{
struct S s = { 0 };
//1. 打开文件
FILE* pf = fopen("test.txt", "rb");//二进制的读
if (pf == NULL)
{
perror("fopen");
return 1;
}
//2. 写文件
fread(&s, sizeof(struct S), 1, pf);
printf("%s %d %f", s.name, s.age, s.score);
//3. 关闭文件
fclose(pf);
pf = NULL;
return 0;
}
运行结果:
5.2 对比一组函数
scanf/printf: 针对标准输入流/标准输出流的 格式化 输入/输出函数
fscanf/fprintf: 针对所有输入流/所有输出流的 格式化 输入/输出函数
sscanf/sprintf:
- sprintf: 将格式化的数据写到字符串中,可以理解为将格式化的数据转换成字符串
int sprintf ( char * str, const char * format, ... );
代码举例:
struct S
{
char name[20];
int age;
float score;
};
int main()
{
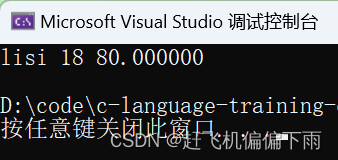
struct S s = { "lisi",18,80.0f };
char arr[20] = { 0 };
sprintf(arr, "%s %d %f", s.name, s.age, s.score);//将结构体变量s中的内容转换成字符串
printf("%s\n", arr);
return 0;
}
执行结果:
- sscanf: 从字符串中提取格式化的数据,也可以理解为将字符串转换为格式化的数据
int sscanf ( const char * s, const char * format, ...);
代码举例:
struct S
{
char name[20];
int age;
float score;
};
int main()
{
char arr[100] = { 0 };
struct S s = { "lisi",18,80.0f };
//临时变量
struct S tmp = {0};
//将s中的各个数据转化成字符串,存放在arr中
sprintf(arr, "%s %d %f", s.name, s.age, s.score);
//从arr中提取格式化的数据存放在tmp中
sscanf(arr, "%s %d %f", tmp.name, &(tmp.age), &(tmp.score));
printf("%s %d %f", tmp.name, tmp.age, tmp.score);
return 0;
}
执行结果:

6. 文件的随机读写
6.1 fseek
根据文件指针的位置和偏移量来定位文件指针(文件内容的光标)。
int fseek ( FILE * stream, long int offset, int origin );
代码:
int main()
{
FILE* pFile;
pFile = fopen("test.txt", "wb");
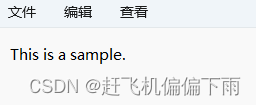
fputs("This is an apple.", pFile);
fseek(pFile, 9, SEEK_SET);
fputs(" sam", pFile);//This is a sample.
fclose(pFile);
pFile = NULL;
return 0;
}
执行结果:
6.2 ftell
返回文件指针相对于起始位置的偏移量
long int ftell ( FILE * stream );
代码:
int main()
{
FILE* pFile;
long size;
pFile = fopen("test.txt", "rb");
if (pFile == NULL)
perror("fopen");
else
{
fseek(pFile, 0, SEEK_END);
size = ftell(pFile);
fclose(pFile);
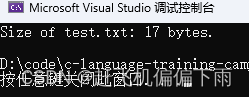
printf("Size of test.txt: %ld bytes.\n", size);
}
return 0;
}
运行结果:
6.3 rewind
让文件指针的位置回到文件的起始位置
void rewind ( FILE * stream );
代码:
int main()
{
int n;
FILE* pFile;
char buffer[27];
pFile = fopen("myfile.txt", "w+");
for (n = 'A'; n <= 'Z'; n++)
fputc(n, pFile);
rewind(pFile);
fread(buffer, 1, 26, pFile);
fclose(pFile);
pFile = NULL;
buffer[26] = '\0';
printf(buffer);
return 0;
}
7. 文件读取结束的判定
7.1 被错误使用的feof
牢记:在文件读取过程中,不能用feof函数的返回值直接来判断文件的是否结束。
feof 的作用是:当文件读取结束的时候,判断是读取结束的原因是否是:遇到文件尾结束。
-
文本文件读取是否结束,判断返回值是否为EOF( fgetc ),或者NULL( fgets )
例如:
• fgetc 判断是否为EOF .
• fgets 判断返回值是否为NULL . -
二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。
例如:
• fread判断返回值是否小于实际要读的个数。
8. 文件缓冲区
ANSIC 标准采用“缓冲文件系统” 处理的数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序中每一个正在使用的文件开辟一块“文件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓冲区,装满缓冲区后才一起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根据C编译系统决定的。