文章 目录
- 1.前言
- 2.爬取目标
- 3.准备工作
- 3.1 环境安装
- 3.2 代理免费获取
- 四、爬虫实战分析
- 4.1 翻页分析
- 4.2 获取视频跳转链接
- 4.3 下载视频
- 4.4 视频音频合并
- 4.5 完整源码
- 五、总结
1.前言
粉丝们(lsp)期待已久的Python批量下载哔哩哔哩美女视频教程它终于来了,接下来跟着我的步骤一步步实现即可!
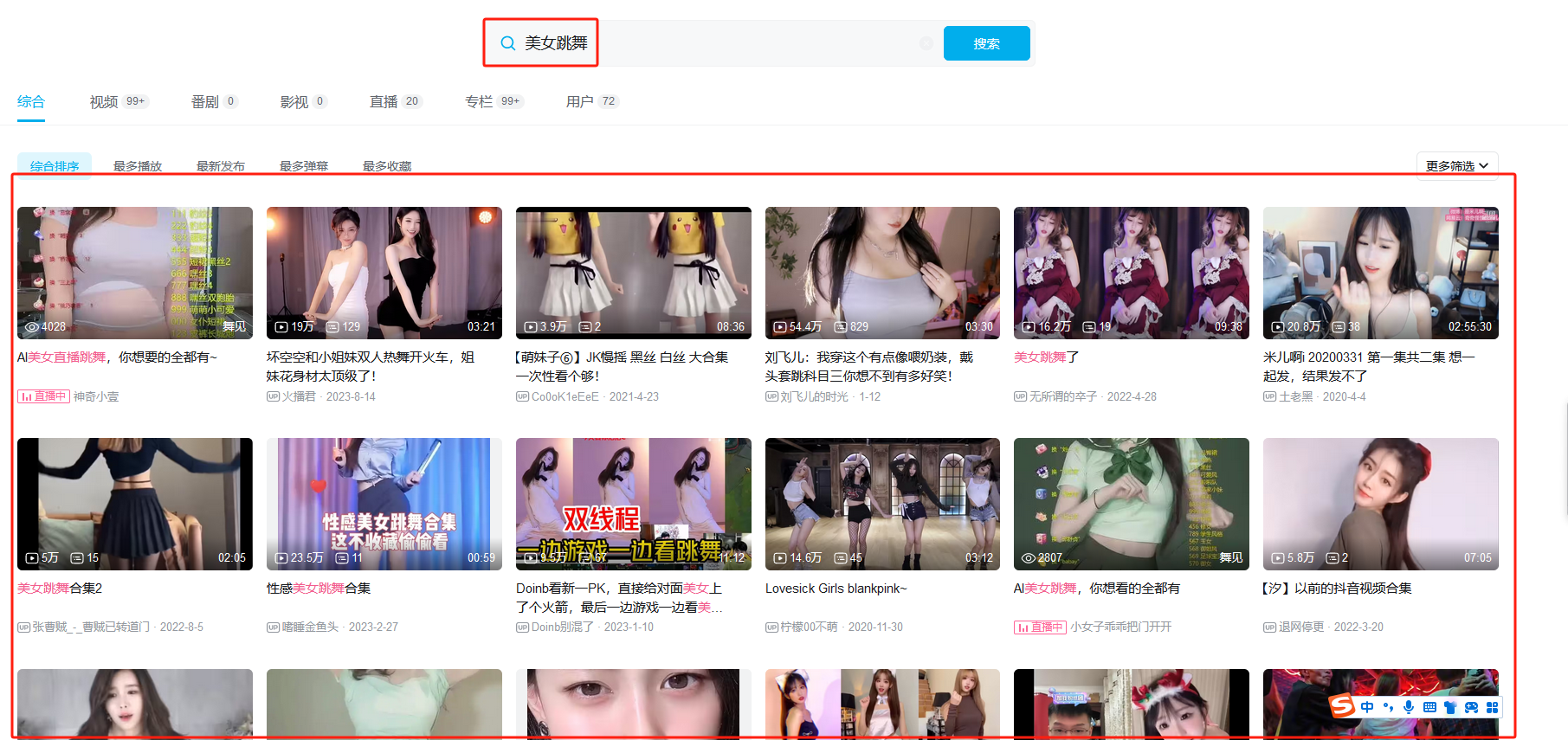
2.爬取目标
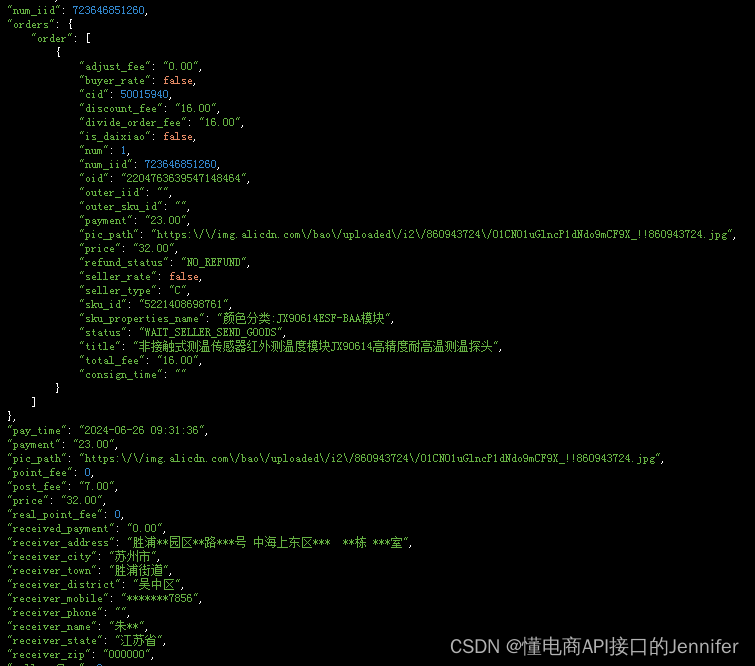
本次博主爬取的目标是哔哩哔哩在搜索框输入关键词后的所有视频:
3.准备工作
3.1 环境安装
Python:3.10
编辑器:PyCharm
由于哔哩哔哩的视频和音频是分开的,所以本次我们需要用到moviepy模块进行合并(moviepy 是一个强大的 Python 模块,用于视频编辑,如视频剪辑、视频合成、视频字幕添加、音频处理等),执行下面pip命令进行安装:
pip install requests # 网页数据爬取
pip install moviepy # 用于合并音频和视频
3.2 代理免费获取
由于哔哩哔哩限制很严,为了能正常获取数据,博主使用了代理IP。
1、注册账号:代理IP试用
2、选择查看代理IP产品:
3、有动态IP、静态IP、机房IP、移动代理IP可以选择,博主这里选择是机房IP:
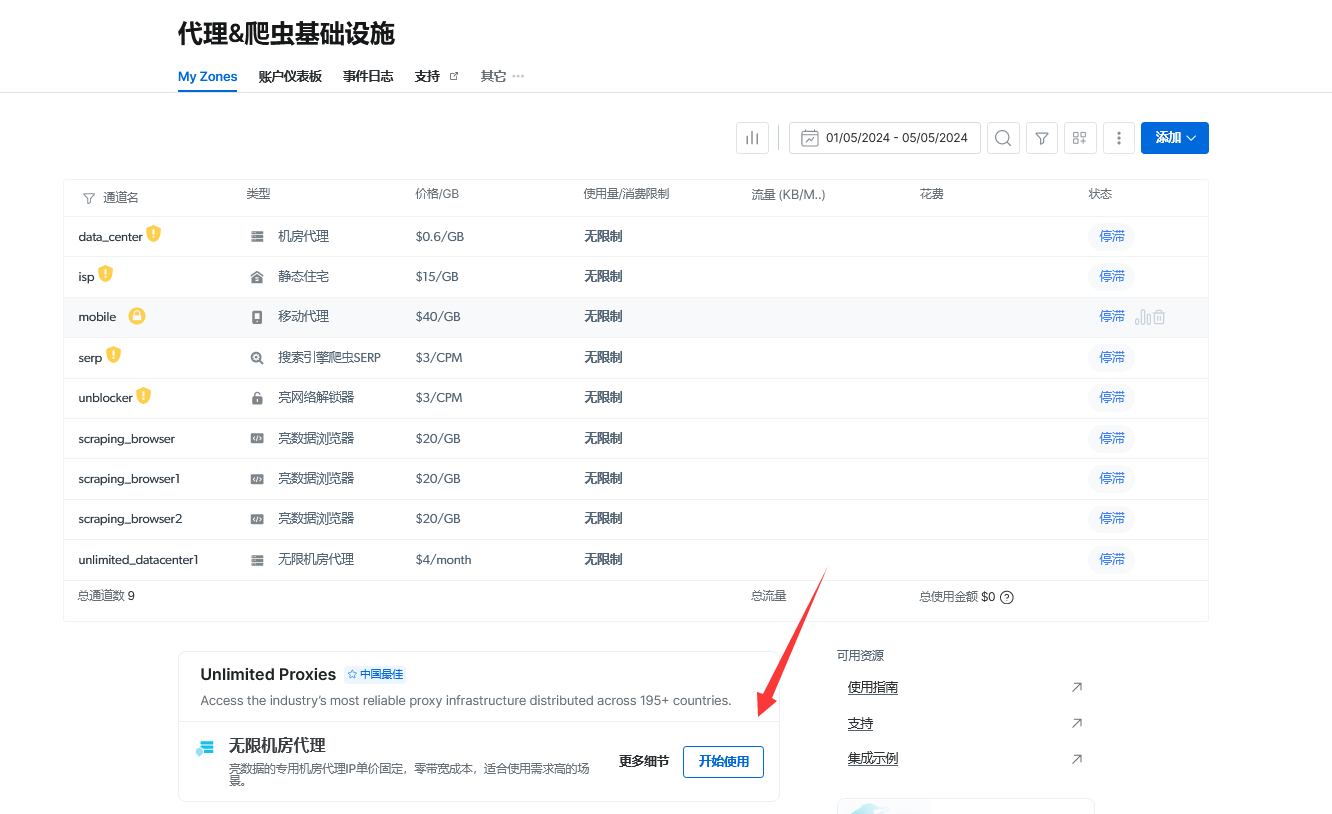
4、配置通道,可以设置IP类型(共享/独享)、IP数、IP来源国家等等:
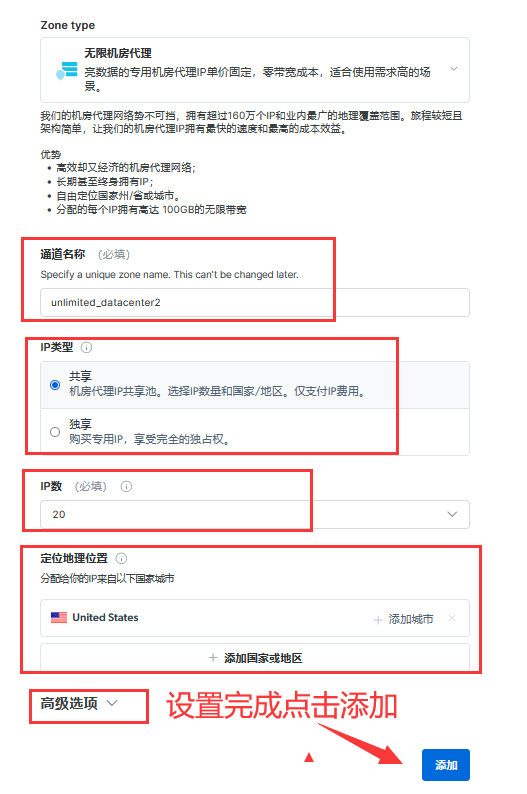
5、配置完成后可以看到主机、用户名和密码,等下我们添加到代码中去获取IP:
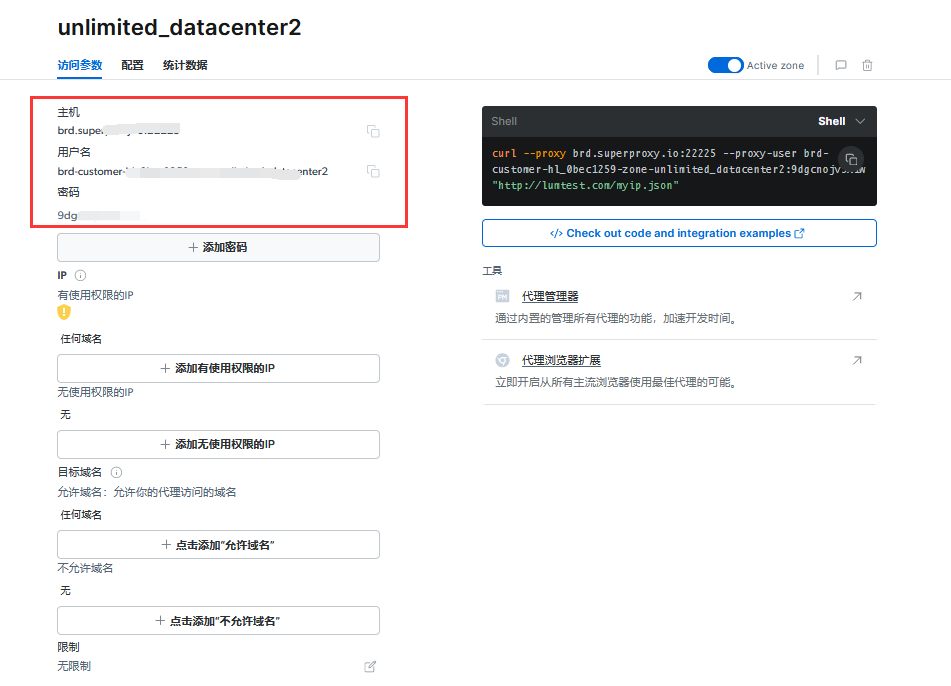
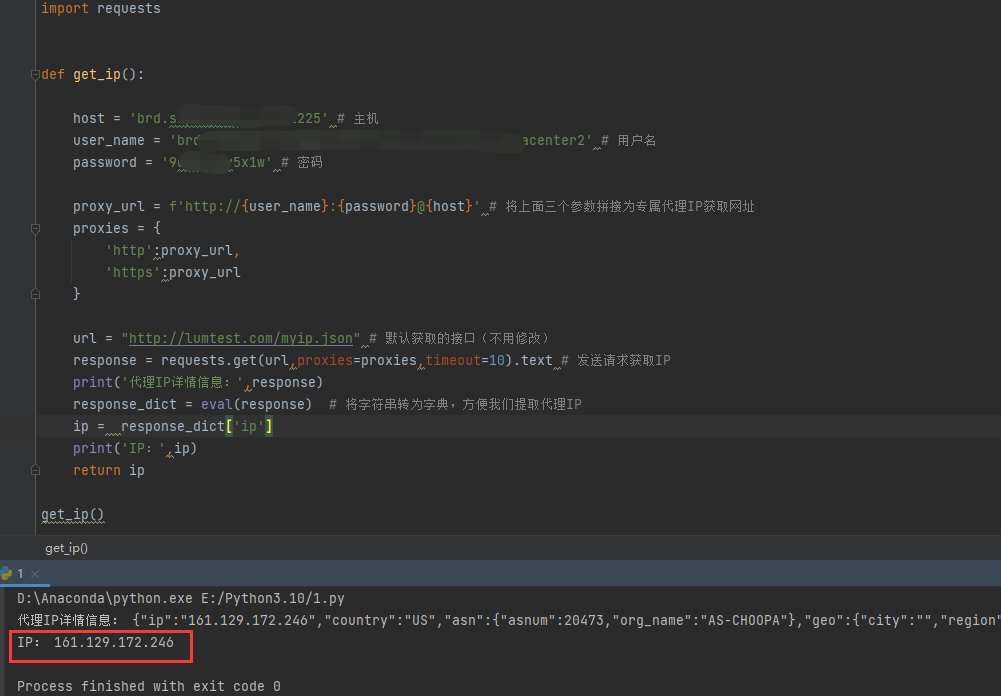
6、下面代码只需要修改刚才获取到的主机、用户名和密码,即可返回代理IP:
import requests # python基础爬虫库
def get_ip():
"""获取亮数据代理IP"""
host = '你的主机' # 主机
user_name = '你的用户名' # 用户名
password = '你的密码' # 密码
proxy_url = f'http://{user_name}:{password}@{host}' # 将上面三个参数拼接为专属代理IP获取网址
proxies = {
'http':proxy_url,
'https':proxy_url
}
url = "http://lumtest.com/myip.json" # 默认获取的接口(不用修改)
response = requests.get(url,proxies=proxies,timeout=10).text # 发送请求获取IP
# print('代理IP详情信息:',response)
response_dict = eval(response) # 将字符串转为字典,方便我们提取代理IP
ip = response_dict['ip']
# print('IP:',ip)
return ip
get_ip()
成功返回IP获取成功:
四、爬虫实战分析
4.1 翻页分析
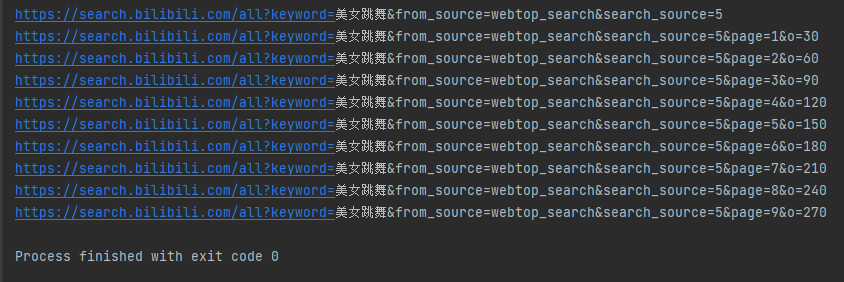
我们搜索关键词后翻页看看链接的规律如下:
第一页链接:
https://search.bilibili.com/all?keyword=%E7%BE%8E%E5%A5%B3%E8%B7%B3%E8%88%9E&from_source=webtop_search&search_source=5
第二页链接:
https://search.bilibili.com/all?vt=67815047&keyword=%E7%BE%8E%E5%A5%B3%E8%B7%B3%E8%88%9E&from_source=webtop_search&search_source=5&page=1&o=30
第三页链接:
https://search.bilibili.com/all?keyword=%E7%BE%8E%E5%A5%B3%E8%B7%B3%E8%88%9E&from_source=webtop_search&search_source=5&page=3&o=60
第四页链接:
https://search.bilibili.com/all?keyword=%E7%BE%8E%E5%A5%B3%E8%B7%B3%E8%88%9E&from_source=webtop_search&search_source=5&page=4&o=90
由上面可以看出规律,我们只需要传入keyword、page和o参数即可:
def main():
keyword = '美女跳舞' # 搜索的关键词
page = 1 # 爬取的页数(每页30个视频)
jump_url_list = [] # 用于存放搜索页每页的全部视频跳转链接
for i in range(1,page+1):
if i ==1:
url = f'https://search.bilibili.com/all?keyword={keyword}&from_source=webtop_search&search_source=5'
else:
url = f'https://search.bilibili.com/all?keyword={keyword}&from_source=webtop_search&search_source=5&page={i-1}&o={(i-1)*30}'
print(url)
4.2 获取视频跳转链接
1、可以看到所有视频都在一个div下面:
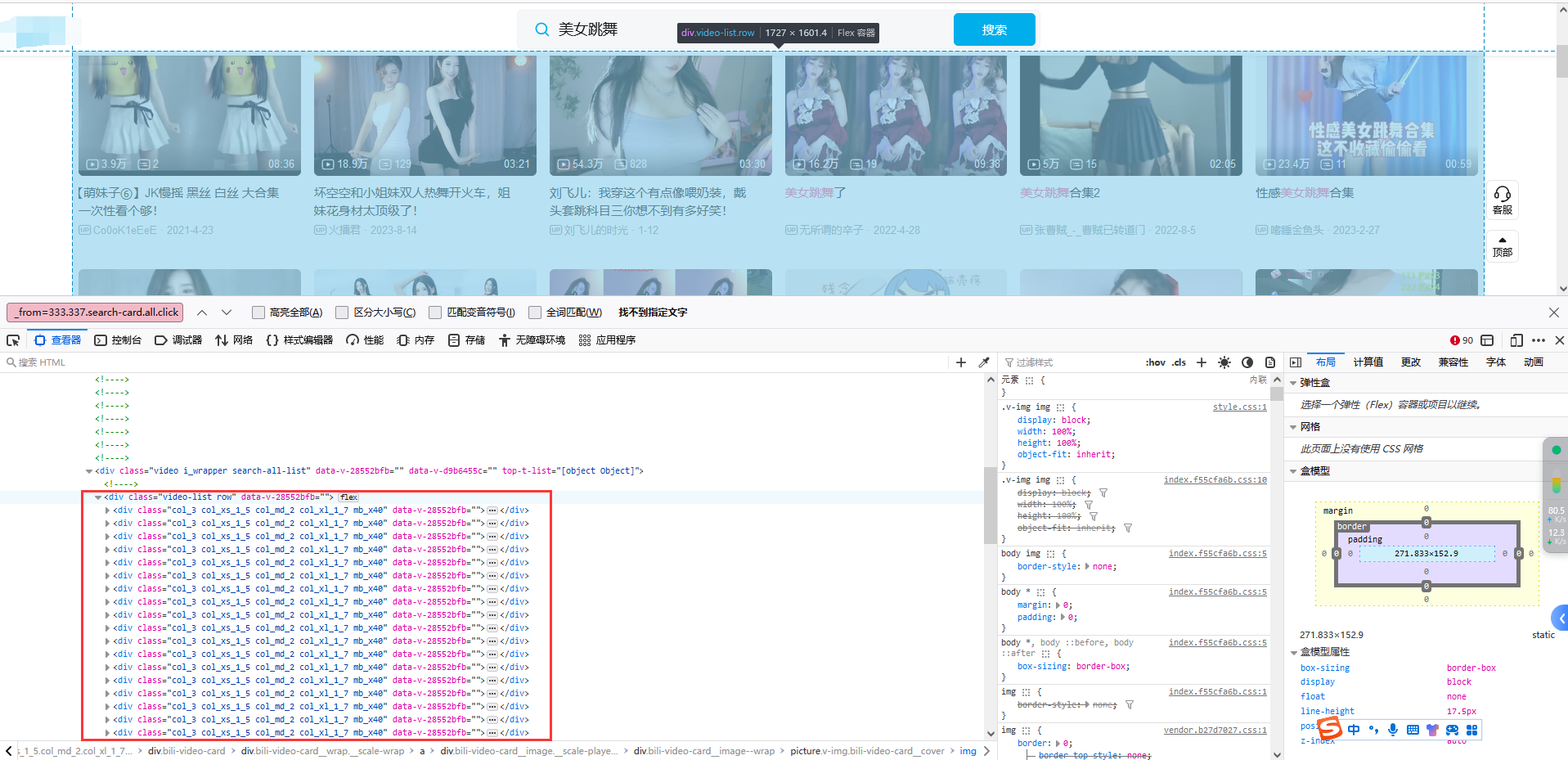
2、然后找到我们要的跳转链接,可以看到在一个a标签下:
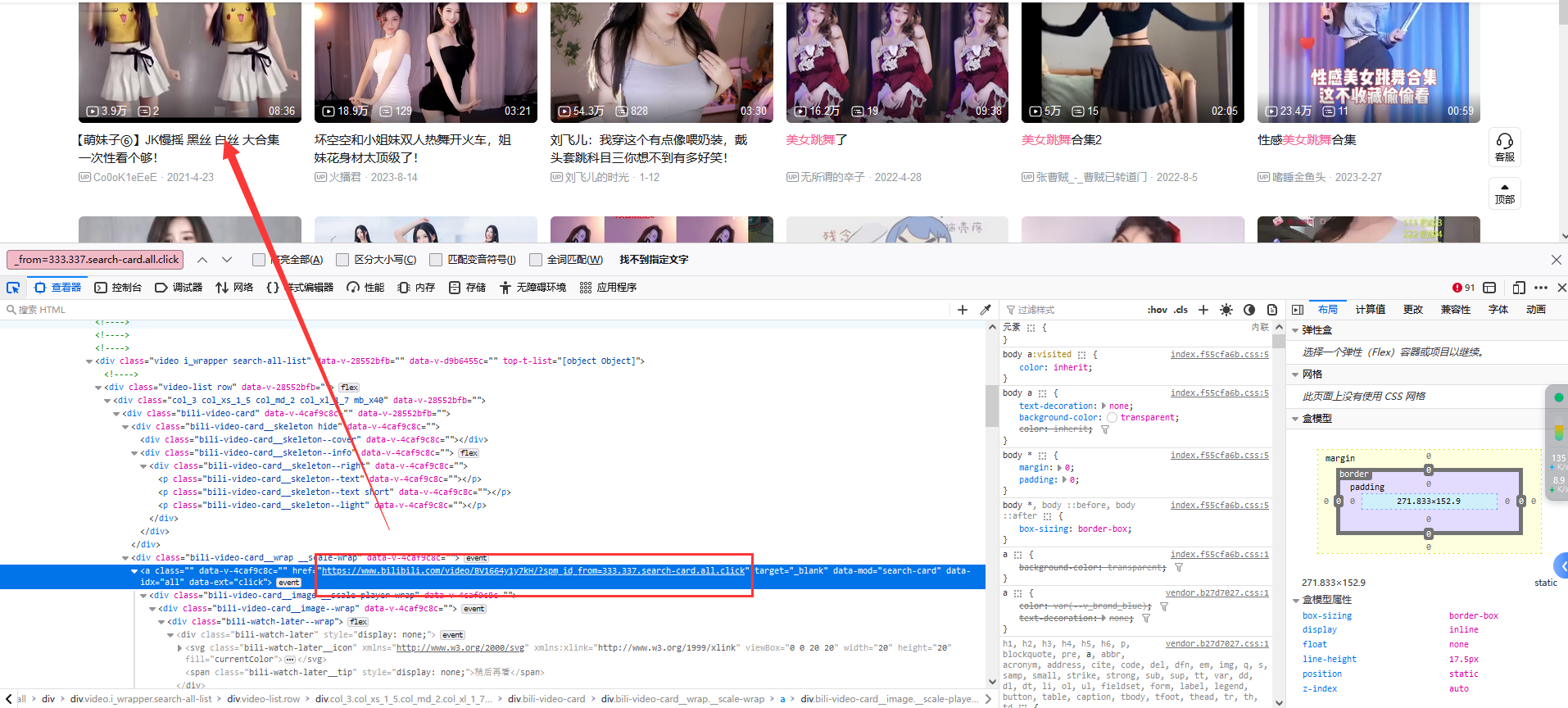
3、接下来只需要获取每一个视频跳转链接即可:
def get_jump_url(url,jump_url_list):
"""获取视频跳转链接"""
headers = {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
# 发送请求
response = requests.get(url, headers=headers)
# 获取网页源码
html_str = response.content.decode()
# print(html_str)
html_data = etree.HTML(html_str)
# 利用xpath取到所有的li标签
div_list = html_data.xpath("//div[@class='video-list row']/div")
# 打印一下div标签个数
# print(len(div_list))
for div in div_list:
# 拼接跳转链接
jump_url = 'https:'+div.xpath(".//div[@class='bili-video-card__wrap __scale-wrap']/a/@href")[0]
# print(jump_url)
# 这里限制一下我们需要的跳转链接,排除无用的链接
if 'https://www.bilibili.com/video' in jump_url:
# 跳转链接存放在列表中
jump_url_list.append(jump_url)
5、获取成功检查一下跳转链接是否正常跳转:
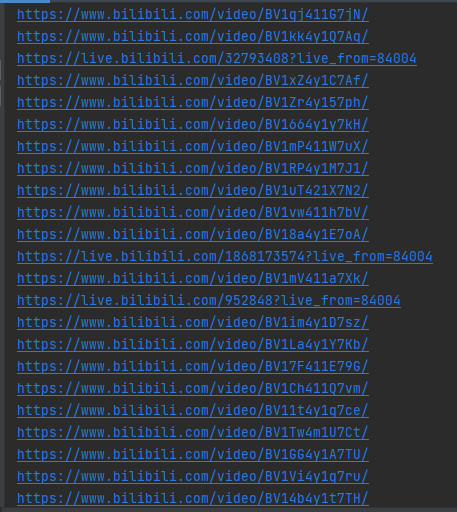
没有问题正常打开:
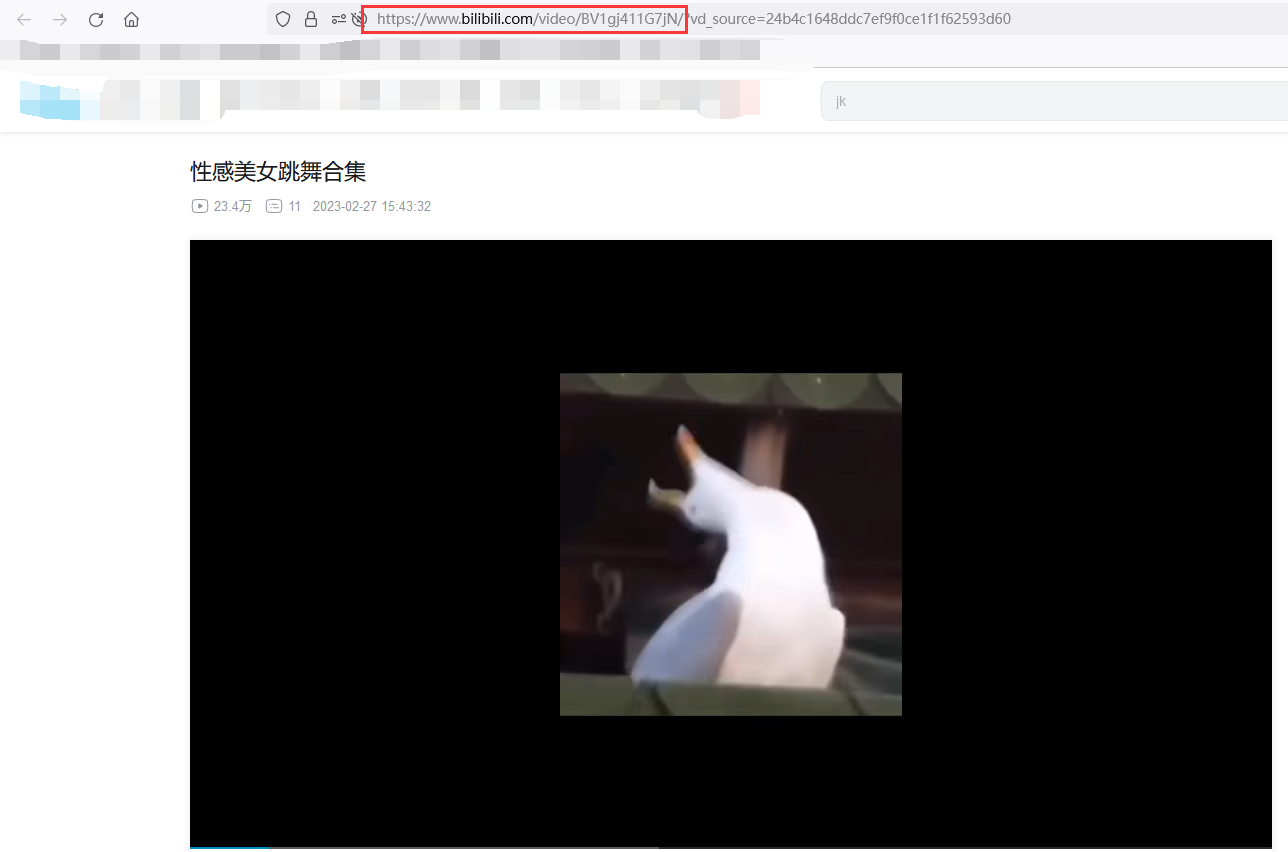
4.3 下载视频
1、首先先找到标题所在标签:
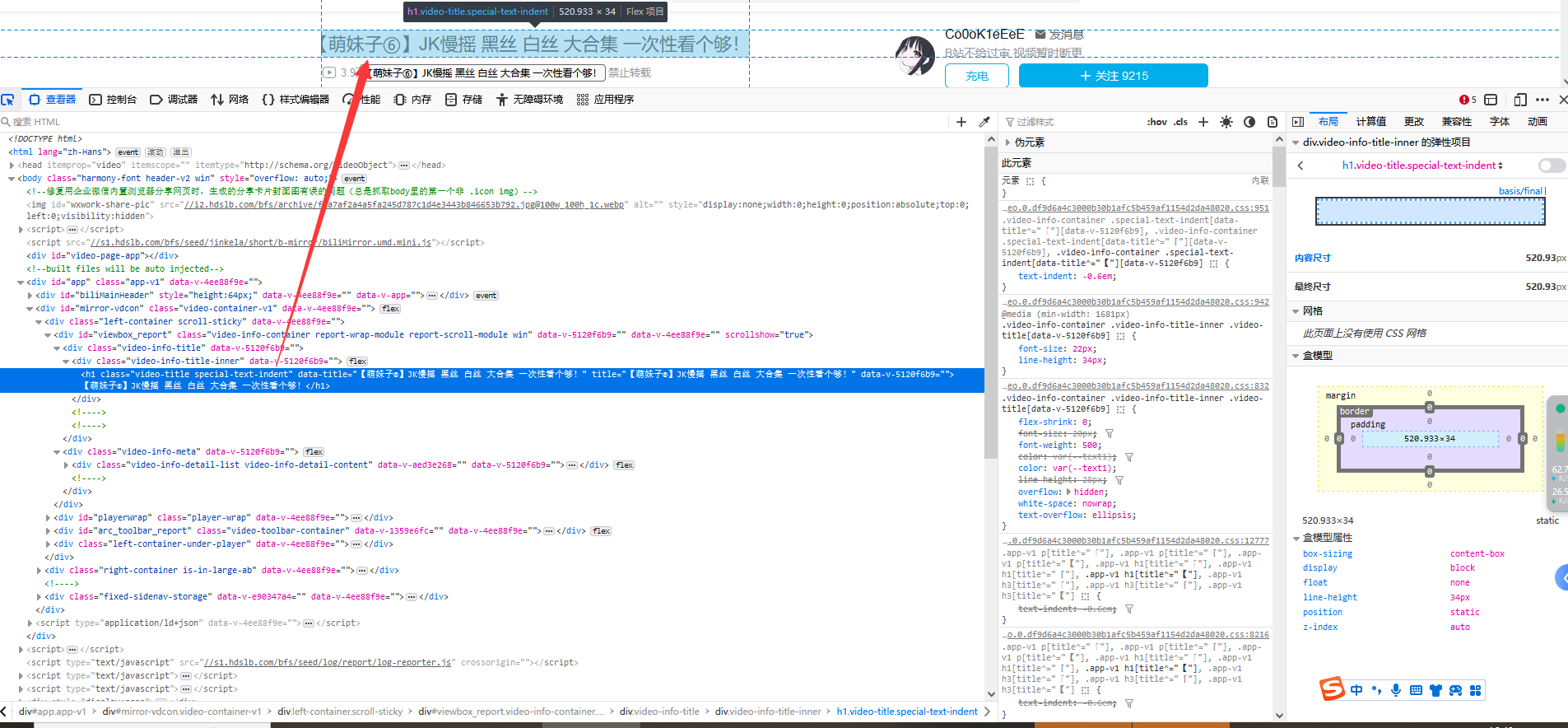
2、视频和音频都藏在script标签里面:
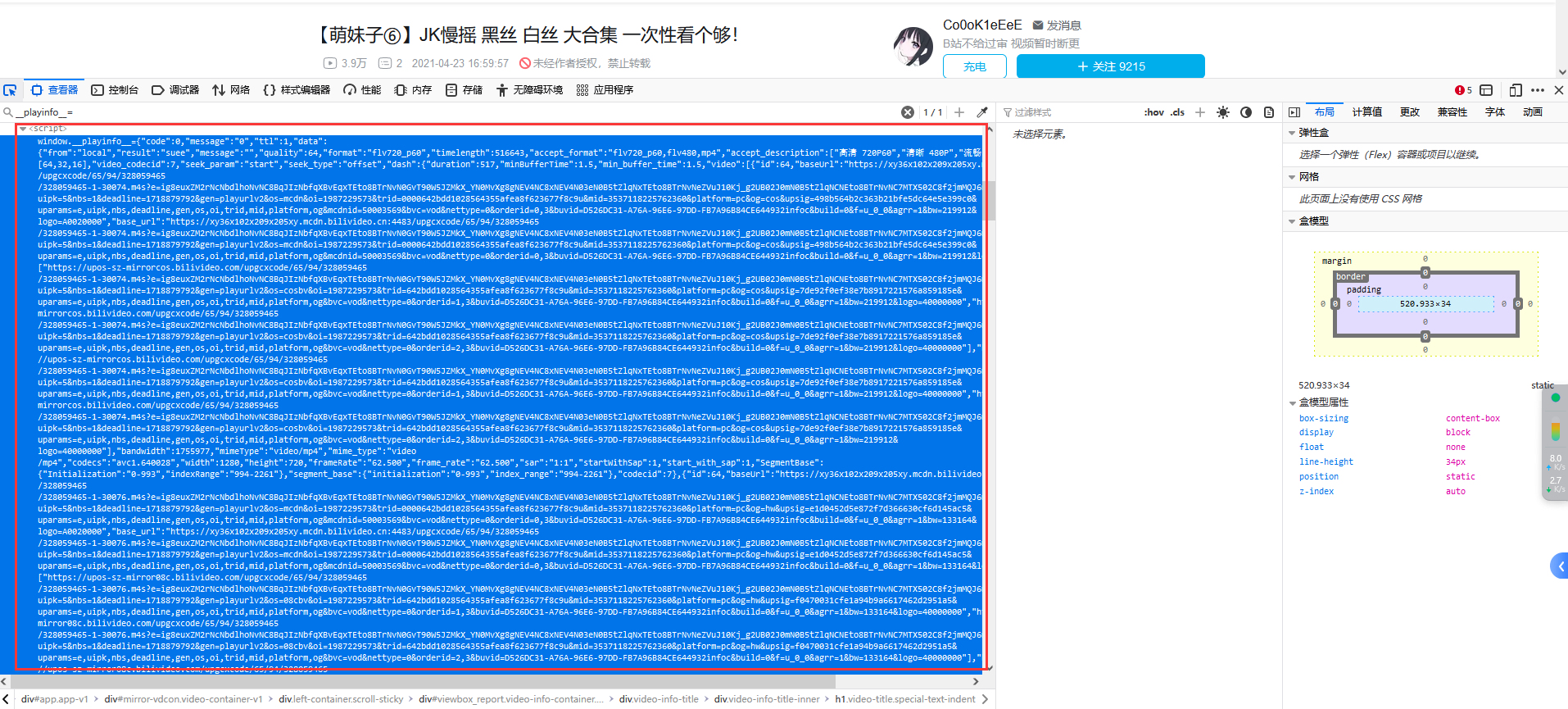
3、遍历我们刚才的跳转链接列表取一个链接进行测试:
def download_video(jump_url_list,keyword):
# 遍历我们刚才获取到的所有跳转链接
for jump_url in jump_url_list: # 先取一个视频进行测试
print('正在下载:',jump_url)
# 发送请求
headers = {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
# 添加代理IP(这里代理IP这里需要看`3.2 获取代理IP`自己去获取)
proxies = get_ip()
response = requests.get(jump_url, headers=headers, proxies=proxies)
# 视频详情json
match = re.search( '__playinfo__=(.*?)</script><script>',response.text)
playinfo = json.loads(match.group(1))
# 视频内容json
match = re.search( r'__INITIAL_STATE__=(.*?);\(function\(\)',response.text)
initial_state = json.loads(match.group(1))
# 视频分多种格式,直接取分辨率最高的视频 1080p
video_url = playinfo['data']['dash']['video'][0]['baseUrl']
# 取出音频地址
audio_url = playinfo['data']['dash']['audio'][0]['baseUrl']
title = initial_state['videoData']['title']
print('视频名字:',title)
# print('视频地址:', video_url)
# print('音频地址:', audio_url)
# 根据关键词创建文件夹
if not os.path.exists(keyword):
os.mkdir(keyword)
# 下载视频
headers.update({"Referer": jump_url})
video_content = requests.get(video_url, headers=headers)
received_video = 0
video_path = f'./{keyword}/{title}_video.mp4'
with open(video_path, 'ab') as output:
while int(video_content.headers['content-length']) > received_video:
headers['Range'] = 'bytes=' + str(received_video) + '-'
response = requests.get(video_url, headers=headers)
output.write(response.content)
received_video += len(response.content)
# 下载音频
audio_content = requests.get(audio_url, headers=headers)
received_audio = 0
audio_path = f'./{keyword}/{title}_audio.mp4'
with open(audio_path, 'ab') as output:
while int(audio_content.headers['content-length']) > received_audio:
# 视频分片下载
headers['Range'] = 'bytes=' + str(received_audio) + '-'
response = requests.get(audio_url, headers=headers)
output.write(response.content)
received_audio += len(response.content)
生成指定关键词文件夹,并下载成功视频和音频:
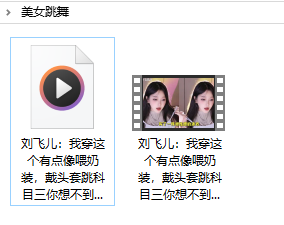
4.4 视频音频合并
这里我们定义一个合并函数,需要传入视频和音频路径即可(注意:合并可能有点慢请耐心等待即可):
def merge_video_audio(video_path, audio_path):
"""传入原始视频和音频路径,合并为新的视频,并删除原始视频和音频"""
print('视频视频合并中请耐心等待~')
# 获取下载好的音频和视频文件
vd = VideoFileClip(video_path)
ad = AudioFileClip(audio_path)
vd2 = vd.set_audio(ad) # 将提取到的音频和视频文件进行合成
output = video_path.replace('_video','')
vd2.write_videofile(output) # 输出新的视频文件
# 移除原始的视频和音频
os.remove(video_path)
os.remove(audio_path)
合并中:
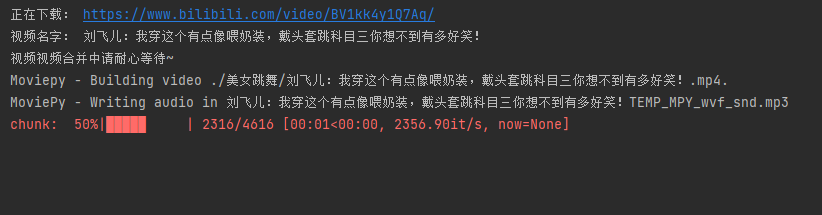
合并成功并删除原始的视频和音频:
4.5 完整源码
下面完整代码需要看3.2获取 并 修改get_ip()函数中的 代理IP信息(主机、用户名和密码),还可以修改关键词和爬取的页数:
import time
import requests
import json
import re
from lxml import etree
from moviepy.editor import *
def get_ip():
"""获取亮数据代理IP"""
host = '你的主机' # 主机
user_name = '你的用户名' # 用户名
password = '你的密码' # 密码
proxy_url = f'http://{user_name}:{password}@{host}' # 将上面三个参数拼接为专属代理IP获取网址
proxies = {
'http': proxy_url,
'https': proxy_url
}
url = "http://lumtest.com/myip.json" # 默认获取的接口(不用修改)
response = requests.get(url, proxies=proxies, timeout=10).text # 发送请求获取IP
# print('代理IP详情信息:',response)
response_dict = eval(response) # 将字符串转为字典,方便我们提取代理IP
ip = response_dict['ip']
# print('IP:',ip)
return ip
def get_jump_url(url,jump_url_list):
"""获取视频跳转链接"""
headers = {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
# 发送请求
response = requests.get(url, headers=headers)
# 获取网页源码
html_str = response.content.decode()
# print(html_str)
html_data = etree.HTML(html_str)
# 利用xpath取到所有的li标签
div_list = html_data.xpath("//div[@class='video-list row']/div")
# 打印一下div标签个数
# print(len(div_list))
for div in div_list:
# 拼接跳转链接
jump_url = 'https:'+div.xpath(".//div[@class='bili-video-card__wrap __scale-wrap']/a/@href")[0]
# print(jump_url)
# 这里限制一下我们需要的跳转链接,排除无用的链接
if 'https://www.bilibili.com/video' in jump_url:
# 跳转链接存放在列表中
jump_url_list.append(jump_url)
def merge_video_audio(video_path, audio_path):
"""传入原始视频和音频路径,合并为新的视频,并删除原始视频和音频"""
print('原始视频音频合并中,请耐心等待~')
# 获取下载好的音频和视频文件
vd = VideoFileClip(video_path)
ad = AudioFileClip(audio_path)
vd2 = vd.set_audio(ad) # 将提取到的音频和视频文件进行合成
output = video_path.replace('_video','')
vd2.write_videofile(output) # 输出新的视频文件
# 移除原始的视频和音频
os.remove(video_path)
os.remove(audio_path)
def download_video(jump_url_list,keyword):
# 遍历我们刚才获取到的所有跳转链接
for jump_url in jump_url_list: # 先取一个视频进行测试
print('正在下载:',jump_url)
# 发送请求
headers = {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
# 添加代理IP(这里代理IP这里需要看`3.2 获取代理IP`自己去获取)
proxies = get_ip()
response = requests.get(jump_url, headers=headers, proxies=proxies)
# 视频详情json
match = re.search( '__playinfo__=(.*?)</script><script>',response.text)
playinfo = json.loads(match.group(1))
# 视频内容json
match = re.search( r'__INITIAL_STATE__=(.*?);\(function\(\)',response.text)
initial_state = json.loads(match.group(1))
# 视频分多种格式,直接取分辨率最高的视频 1080p
video_url = playinfo['data']['dash']['video'][0]['baseUrl']
# 取出音频地址
audio_url = playinfo['data']['dash']['audio'][0]['baseUrl']
title = initial_state['videoData']['title']
print('视频名字:',title)
# print('视频地址:', video_url)
# print('音频地址:', audio_url)
# 根据关键词创建文件夹
if not os.path.exists(keyword):
os.mkdir(keyword)
# 下载视频
headers.update({"Referer": jump_url})
video_content = requests.get(video_url, headers=headers)
received_video = 0
video_path = f'./{keyword}/{title}_video.mp4'
with open(video_path, 'ab') as output:
while int(video_content.headers['content-length']) > received_video:
headers['Range'] = 'bytes=' + str(received_video) + '-'
response = requests.get(video_url, headers=headers)
output.write(response.content)
received_video += len(response.content)
# 下载音频
audio_content = requests.get(audio_url, headers=headers)
received_audio = 0
audio_path = f'./{keyword}/{title}_audio.mp4'
with open(audio_path, 'ab') as output:
while int(audio_content.headers['content-length']) > received_audio:
# 视频分片下载
headers['Range'] = 'bytes=' + str(received_audio) + '-'
response = requests.get(audio_url, headers=headers)
output.write(response.content)
received_audio += len(response.content)
# 合并视频和音频
merge_video_audio(video_path, audio_path)
print('********************这是一条隔离线***************************')
time.sleep(1) # 限制速度不能太快了,如果还是不行继续增加暂停时间
def main():
keyword = '美女跳舞' # 搜索的关键词
page = 1 # 爬取的页数(每页30个视频)
jump_url_list = [] # 用于存放搜索页每页的全部视频跳转链接
for i in range(1,page+1):
if i ==1:
url = f'https://search.bilibili.com/all?keyword={keyword}&from_source=webtop_search&search_source=5'
else:
url = f'https://search.bilibili.com/all?keyword={keyword}&from_source=webtop_search&search_source=5&page={i-1}&o={(i-1)*30}'
# print(url)
get_jump_url(url,jump_url_list)
# 翻页休息一秒
time.sleep(1)
download_video(jump_url_list,keyword)
if __name__ == '__main__':
main()
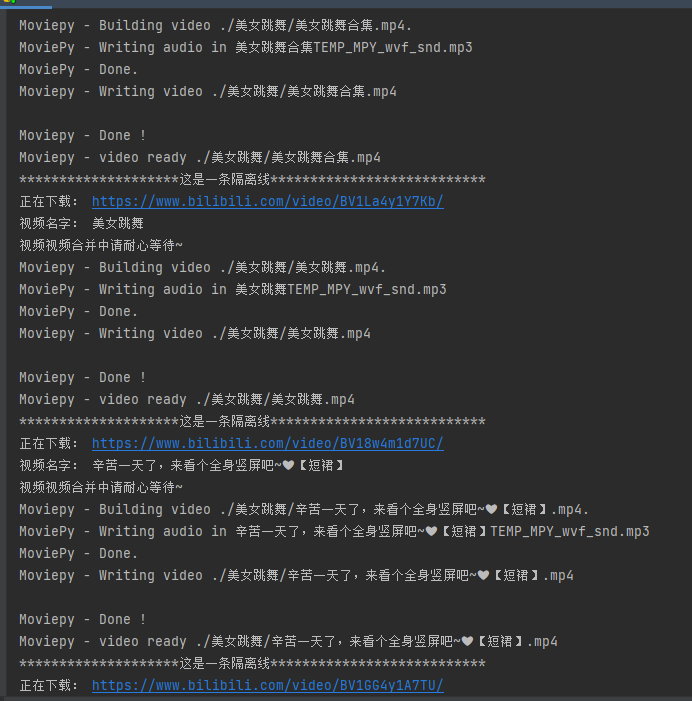
下载中:
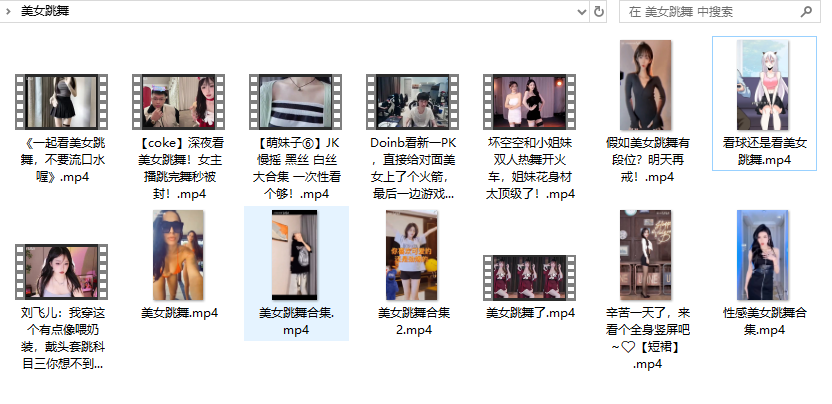
文件夹下全是视频:
五、总结
代理IP对于爬虫是密不可分的,但使用代理IP需要遵守相关法律法规和目标网站的使用规则,不得进行非法活动或滥用代理IP服务,高质量代理IP可以帮助爬虫正常采集公开数据信息,有需要代理IP的小伙伴可以试试:代理IP免费试用
如有问题,可以关注公众号 “Bright Data亮数据”,发送问题后会有官方客服进行回复: