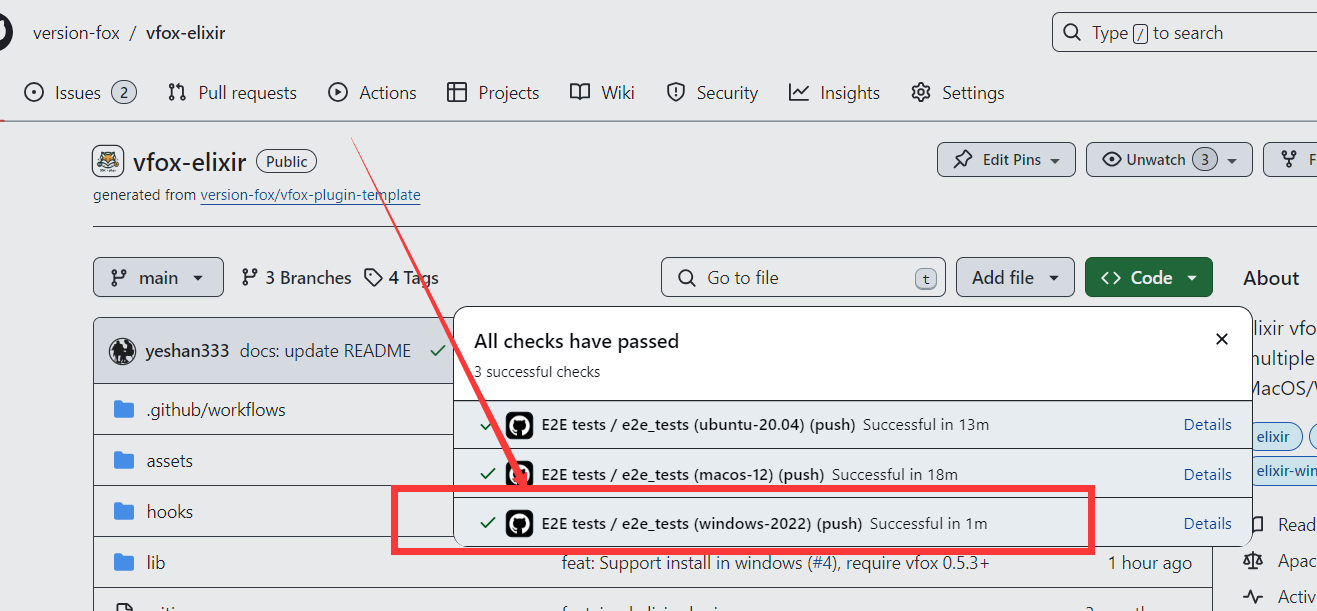
工具介绍
一、概述
Kettle,又名 Pentaho Data Integration(PDI),是一个开源的数据集成工具,最初由 Pentaho 公司开发。它能够从多种数据源提取、转换并加载(ETL)数据,适用于数据仓库建设、数据迁移和数据同步等场景。

二、架构
Kettle 的架构主要由以下几个组件组成:
- Spoon:图形化设计工具,用于创建和测试 ETL 作业和转换。
- Pan:命令行工具,用于执行数据转换。
- Kitchen:命令行工具,用于执行作业(Job)。
- Carte:轻量级 Web 服务器,用于远程执行和监控 ETL 作业和转换。
三、基本工作流程
Kettle 的工作流程主要分为以下几个步骤:
-
数据源连接:
- 通过 Spoon 连接不同的数据源,如数据库、文件、Web 服务等。
-
创建转换(Transformation):
- 转换是数据处理的核心单元,定义了从数据源到目标的数据流。使用 Spoon 创建转换图,通过不同的步骤(Steps)实现数据提取、转换和加载。
-
创建作业(Job):
- 作业是对多个转换的调度和控制,定义了 ETL 过程的执行顺序和依赖关系。
-
执行和监控:
- 使用 Spoon 进行本地测试和调试。通过 Pan 和 Kitchen 在生产环境中执行转换和作业。使用 Carte 提供的 Web 界面进行远程监控和管理。
四、使用场景
-
数据仓库建设:
- 从多个异构数据源提取数据,进行清洗、转换后加载到数据仓库中。
-
数据迁移:
- 将数据从旧系统迁移到新系统,支持不同数据库之间的数据传输。
-
数据同步:
- 定期从业务系统抽取数据,并同步到数据分析平台或报表系统。
-
数据集成:
- 集成来自多个业务系统的数据,形成统一的视图,支持业务分析和决策。
五、优越点
-
图形化界面:
- Spoon 提供直观的图形化设计界面,降低了 ETL 开发的门槛,方便快速构建和测试 ETL 流程。
-
多种数据源支持:
- 支持多种数据源类型,包括关系型数据库、NoSQL 数据库、文件(CSV、Excel、XML 等)、Web 服务等,具有很强的扩展性。
-
丰富的转换和作业步骤:
- 提供了丰富的数据处理步骤,如过滤、聚合、连接、排序、数据清洗等,能够满足复杂的数据处理需求。
-
可扩展性:
- 支持通过插件机制扩展功能,用户可以根据需要自定义数据处理逻辑。
-
社区支持和文档:
- 作为一个开源项目,Kettle 拥有广泛的社区支持和丰富的文档资源,用户可以方便地获取帮助和分享经验。
-
跨平台:
- 基于 Java 开发,支持在多种操作系统(Windows、Linux、macOS)上运行。
安装部署
安装 Pentaho Data Integration (Kettle) 的过程相对简单,但为了确保安装和配置正确,下面是一个详细的步骤指南:
一、前提条件
- Java 环境:
- 确保系统上已安装 JDK(Java Development Kit),建议使用 JDK 8 或更高版本。
- 验证 Java 安装:
java -version
二、下载 Kettle
-
访问 Pentaho 官网:
- 访问 Pentaho 社区下载页面,选择最新的 Pentaho Data Integration (PDI) 版本。
-
下载 PDI:
- 选择合适的版本(通常是 ZIP 或 TAR.GZ 格式),下载到本地系统。
三、解压文件
- 解压 PDI 文件:
- Windows 系统:
unzip pdi-ce-8.3.0.0-371.zip -d C:\pentaho - Linux / macOS 系统:
tar -zxvf pdi-ce-8.3.0.0-371.tar.gz -C /opt
- Windows 系统:
四、配置环境变量
为了方便使用,可以将 PDI 的 bin 目录添加到系统的 PATH 环境变量中。
-
编辑环境变量:
-
Windows:
- 右键“计算机”,选择“属性”。
- 点击“高级系统设置”。
- 在“系统属性”窗口中,点击“环境变量”。
- 在“系统变量”中找到
Path,编辑并添加 PDIbin目录的路径,例如C:\pentaho\data-integration\bin。
-
Linux / macOS:
nano ~/.bashrc在文件末尾添加:
export PENTAHO_HOME=/opt/data-integration export PATH=$PATH:$PENTAHO_HOME保存并退出编辑器,然后使更改生效:
source ~/.bashrc
-
五、启动 Spoon
- 启动 Spoon 图形化工具:
- Windows 系统:
直接双击Spoon.bat。 - Linux / macOS 系统:
进入 PDI 目录并运行 Spoon 脚本:cd /opt/data-integration ./spoon.sh
- Windows 系统:
六、安装和配置 JDBC 驱动
如果需要连接特定的数据库,需要下载相应的 JDBC 驱动并将其放置在 PDI 的 lib 目录中。
-
下载 JDBC 驱动:
- 例如,对于 MySQL 数据库,从 MySQL 官方网站 下载 JDBC 驱动。
-
将驱动放置到 lib 目录:
- 将下载的驱动 JAR 文件复制到
data-integration/lib目录中。
- 将下载的驱动 JAR 文件复制到
七、验证安装
- 创建测试转换:
- 打开 Spoon 工具。
- 新建一个转换(Transformation)。
- 添加输入步骤,例如“CSV 文件输入”。
- 配置输入文件路径,添加输出步骤,例如“表输出”。
- 运行转换,确保可以成功执行。
八、常见问题解决
-
Java 版本问题:
- 如果遇到 Java 版本不兼容的问题,确保使用的是 JDK 而不是 JRE,并且版本符合要求。
-
内存设置:
- 在执行大规模数据处理任务时,可以通过修改
spoon.sh或Spoon.bat文件中的 JVM 参数来增加内存分配。例如:export JAVA_OPTS="-Xms1024m -Xmx4096m"
- 在执行大规模数据处理任务时,可以通过修改
通过以上步骤,可以成功安装和配置 Pentaho Data Integration (Kettle)。该工具的图形化界面 Spoon 使得数据集成任务的设计和执行变得直观且高效。配置 JDBC 驱动后,Kettle 能够连接多种数据源,适用于广泛的数据集成和处理场景。
使用案例
使用 Kettle 同步 MySQL 数据到 Hive 表的案例
本案例将介绍如何使用 Kettle 将 MySQL 数据同步到 Hive 表,包括任务优化、参数传递以及每一步的详细解释。
一、前提条件
- 已安装并配置好 Kettle(Pentaho Data Integration)。
- 已安装并配置好 MySQL 和 Hive。
- 下载并放置好 MySQL 和 Hive 的 JDBC 驱动到 Kettle 的
lib目录中。
二、创建 ETL 转换和作业
-
打开 Spoon
启动 Spoon 工具:
./spoon.sh -
创建新转换
新建一个转换(Transformation),将其保存为
mysql_to_hive.ktr。 -
参数传递
在转换中设置参数,以便动态传递数据库连接信息和表名。
- 点击菜单栏的“编辑”->“设置变量”。
- 添加以下参数:
MYSQL_HOSTMYSQL_PORTMYSQL_DBMYSQL_USERMYSQL_PASSWORDMYSQL_TABLEHIVE_DBHIVE_TABLE
-
添加步骤
-
表输入(Table Input)
- 添加“表输入”步骤,并命名为
MySQL Input。 - 配置数据库连接:
- 新建 MySQL 数据库连接,使用以下参数:
- 主机名:
${MYSQL_HOST} - 端口:
${MYSQL_PORT} - 数据库名:
${MYSQL_DB} - 用户名:
${MYSQL_USER} - 密码:
${MYSQL_PASSWORD}
- 主机名:
- 新建 MySQL 数据库连接,使用以下参数:
- SQL 查询:
SELECT * FROM ${MYSQL_TABLE}
- 添加“表输入”步骤,并命名为
-
字段选择(Select Values)
- 添加“字段选择”步骤,并命名为
Select Fields。 - 连接到
MySQL Input步骤。 - 在“字段选择”中,选择需要传输到 Hive 的字段。
- 添加“字段选择”步骤,并命名为
-
表输出(Table Output)
-
添加“表输出”步骤,并命名为
Hive Output。 -
配置数据库连接:
- 新建 Hive 数据库连接,使用以下参数:
- 主机名:HiveServer2 的主机地址
- 端口:10000
- 数据库名:
${HIVE_DB} - 用户名:Hive 用户名(如有)
- 密码:Hive 密码(如有)
- 新建 Hive 数据库连接,使用以下参数:
-
表名:
${HIVE_TABLE} -
确保“truncate table”选项被选中,以便每次同步时清空目标表。
-
-
-
保存转换
保存转换为
mysql_to_hive.ktr。
三、创建作业
-
创建新作业
新建一个作业(Job),将其保存为
mysql_to_hive_job.kjb。 -
添加开始(Start)和作业(Job)步骤
-
开始(Start)
- 添加“开始”步骤。
-
设置变量(Set Variables)
- 添加“设置变量”步骤,并连接到“开始”步骤。
- 配置以下变量:
MYSQL_HOST:localhostMYSQL_PORT:3306MYSQL_DB:your_mysql_databaseMYSQL_USER:your_mysql_userMYSQL_PASSWORD:your_mysql_passwordMYSQL_TABLE:your_mysql_tableHIVE_DB:your_hive_databaseHIVE_TABLE:your_hive_table
-
转换(Transformation)
- 添加“转换”步骤,并连接到“设置变量”步骤。
- 选择转换文件
mysql_to_hive.ktr。
-
四、任务优化
-
优化 JDBC 驱动
- 使用最新版本的 MySQL 和 Hive JDBC 驱动,以提高连接性能和稳定性。
-
调优转换步骤
- 在“表输入”步骤中使用分页查询(如
LIMIT和OFFSET)以减少内存消耗。 - 使用“字段选择”步骤过滤掉不必要的字段,减少数据传输量。
- 在“表输入”步骤中使用分页查询(如
-
并行处理
- 如果数据量较大,可以在“转换”设置中启用并行处理,设置合适的并行度。
五、代码解释
- 参数传递:在作业中使用“设置变量”步骤动态传递数据库连接信息,确保灵活性和可维护性。
- MySQL 输入:使用“表输入”步骤从 MySQL 数据库中提取数据,通过配置参数动态生成 SQL 查询。
- 字段选择:通过“字段选择”步骤过滤需要同步的字段,提高同步效率。
- Hive 输出:使用“表输出”步骤将数据加载到 Hive 表中,配置参数确保目标表动态变化。
六、运行和测试
-
运行作业
在 Spoon 中打开
mysql_to_hive_job.kjb,点击“运行”按钮启动作业。 -
验证结果
- 确认 MySQL 数据库中的数据成功同步到 Hive 表。
- 在 Hive 中执行查询验证数据正确性:
SELECT * FROM your_hive_table;
以上案例详细介绍了如何使用 Kettle 将 MySQL 数据同步到 Hive 表的全过程,包括创建转换和作业、参数传递、任务优化以及每一步的详细配置和解释。通过合理配置和优化,可以确保数据同步的高效性和稳定性。
性能优化
在使用 Kettle(Pentaho Data Integration)进行数据处理和集成时,性能优化是确保高效运行和资源有效利用的关键。以下是一些性能优化策略和技巧:
一、转换和作业优化
-
优化数据源查询
- 过滤数据:在
Table Input步骤中使用 SQL 过滤条件,减少不必要的数据提取。SELECT * FROM your_table WHERE condition - 分页查询:对于大数据量,使用分页查询(LIMIT 和 OFFSET)减少单次加载的数据量。
- 过滤数据:在
-
减少数据处理步骤
- 简化转换逻辑:尽量减少不必要的步骤和复杂的逻辑,只保留必要的转换操作。
- 合并步骤:合并可以在同一操作中完成的多个步骤,减少步骤之间的数据传输。
-
并行处理
- 调整并行度:在转换设置中调整并行度,通过
Set Number of Copies参数设置步骤的并行执行数量。 - 多线程执行:在作业设置中启用并行处理步骤选项,允许多个步骤同时运行。
- 调整并行度:在转换设置中调整并行度,通过
-
优化内存使用
- 分配足够的 JVM 内存:在 Spoon 启动脚本(spoon.bat 或 spoon.sh)中调整 JVM 内存分配参数,例如:
export JAVA_OPTS="-Xms1024m -Xmx4096m" - 合理设置缓存:在转换步骤(如
Sort Rows和Group By)中设置合适的缓存大小,避免频繁的磁盘 I/O。
- 分配足够的 JVM 内存:在 Spoon 启动脚本(spoon.bat 或 spoon.sh)中调整 JVM 内存分配参数,例如:
二、数据库和文件优化
-
使用批量处理
- 批量插入:在
Table Output步骤中启用批量插入选项,提高数据写入效率。 - 分批提交:在
Table Output步骤中设置提交记录数,减少每次提交的记录数量,避免单次提交过多数据。
- 批量插入:在
-
索引和分区
- 数据库索引:确保源数据库表和目标数据库表上的查询和连接字段已建立索引,提高查询和插入性能。
- 分区表:对大数据表进行分区处理,减少单个分区内的数据量,提高查询和插入效率。
三、网络和硬件优化
-
网络优化
- 网络带宽:确保网络带宽足够,避免数据传输瓶颈。
- 本地处理:尽量在数据源和目标都在本地网络内处理数据,减少网络延迟。
-
硬件优化
- 硬件资源:确保服务器硬件资源(CPU、内存、磁盘 I/O)充足,以支持大规模数据处理。
- SSD 存储:使用 SSD 存储设备,减少磁盘 I/O 延迟,提高读写速度。
四、Kettle 配置优化
-
调优 Kettle 配置文件
- kettle.properties:在 Kettle 的配置文件(kettle.properties)中设置优化参数,例如:
KETTLE_CARTE_OBJECT_TIMEOUT_MINUTES=1440 KETTLE_COMPATIBILITY_MEMORY_DONT_COMMIT_STREAM=Y
- kettle.properties:在 Kettle 的配置文件(kettle.properties)中设置优化参数,例如:
-
日志级别
- 减少日志量:在转换和作业设置中调整日志级别,减少详细日志输出,减轻日志记录带来的性能开销。
KETTLE_LOG_LEVEL=Minimal
- 减少日志量:在转换和作业设置中调整日志级别,减少详细日志输出,减轻日志记录带来的性能开销。
五、性能监控和调试
-
性能监控
- 使用 Kettle 提供的性能监控工具,监控转换和作业的执行时间、内存使用情况和各步骤的性能指标。
- 通过性能监控图表(Performance Graphs)识别瓶颈步骤并进行优化。
-
性能调试
- 使用 Kettle 的调试功能,逐步执行转换,检查每个步骤的输入和输出数据,发现并解决性能问题。
- 通过日志文件分析错误和性能问题,进行有针对性的优化。
示例:优化一个简单的 MySQL 到 Hive 的数据同步转换
-- 在 MySQL 中执行的查询,使用过滤条件减少数据量
SELECT id, name, value FROM source_table WHERE update_time > '2023-01-01';
# Spoon 启动脚本中增加 JVM 内存分配
export JAVA_OPTS="-Xms2048m -Xmx8192m"
# kettle.properties 中的优化配置
KETTLE_CARTE_OBJECT_TIMEOUT_MINUTES=1440
KETTLE_COMPATIBILITY_MEMORY_DONT_COMMIT_STREAM=Y
KETTLE_LOG_LEVEL=Minimal
通过以上各种优化策略,可以显著提升 Kettle 在数据同步和处理中的性能。合理使用并行处理、优化数据源查询、减少不必要的步骤、调优内存使用以及监控和调试性能,是确保高效运行的关键。
总结
Kettle(Pentaho Data Integration)是一个功能强大且易于使用的数据集成工具,适用于多种数据处理和集成场景。其图形化界面和丰富的功能使其成为构建数据仓库、进行数据迁移和数据同步的理想选择。凭借其广泛的数据源支持、可扩展性和社区资源,Kettle 成为企业级数据处理和集成的有力工具。