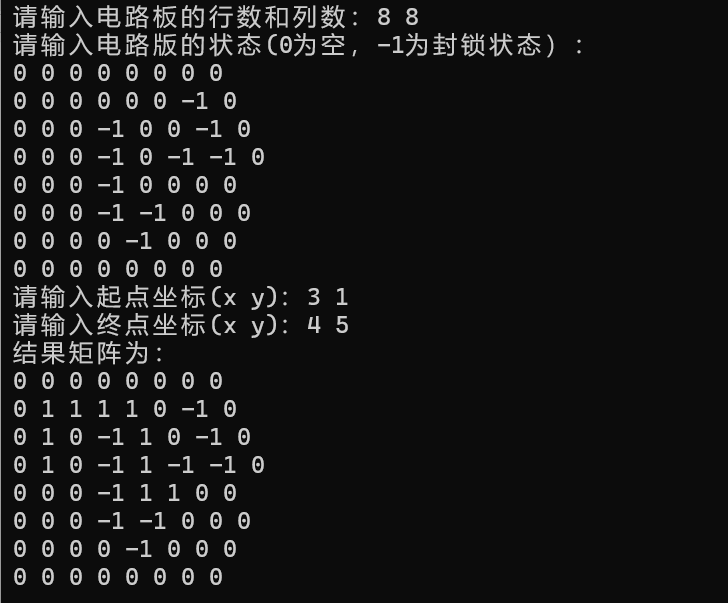
说在前面
🎈整理一些常见常用的正则表达式。
常见的正则表达式
1、手机号码
/^[1][3456789][0-9]{9}$/
这个正则表达式 /^[1][3456789][0-9]{9}$/ 用于匹配中国的手机号码的一部分,但不包括全部有效的手机号码格式。下面是对它的详细解释:
-
^:表示匹配字符串的开始。 -
[1]:手机号码以数字1开头。 -
[3456789]:第二位数字可以是3、4、5、6、7、8或9,排除了以1和2开头的号码,这符合中国手机号码的分配规则,其中13和15开头的号码被分配给了其他用途。 -
[0-9]{9}:接下来的是9个数字,这代表手机号码的剩余部分。 -
$:表示匹配字符串的结束。
将这些组合起来,这个正则表达式匹配的是一个以 1 开头,第二位是 3 到 9 之间的数字,后面紧跟着9个数字的字符串,符合中国大陆部分手机号码的标准格式(11位数字,以13x、14x、16x、17x、18x或19x开头)的一部分。
例如,以下号码的一部分会被匹配:
139(部分匹配,完整号码可能是13912345678)158(部分匹配,完整号码可能是15800012345)
请注意,这个正则表达式只匹配了手机号码的前两位和最后九位数字,并没有匹配完整的手机号码格式。此外,由于手机号码的分配可能会随时间变化,这个正则表达式可能需要更新以适应新的号码分配规则。
2、邮箱
/^([A-Za-z0-9_\-\.])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,4})$/
这个正则表达式 ^([A-Za-z0-9_\-\.])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,4})$ 用于验证电子邮件地址的格式。下面是对它的详细解释:
-
^:表示匹配字符串的开始。 -
([A-Za-z0-9_\-\.])+:这部分是一个捕获组,匹配一个或多个以下字符:- 大写字母
A到Z。 - 小写字母
a到z。 - 数字
0到9。 - 下划线
_。 - 连字符
-。 - 点
.。
- 大写字母
-
\@:匹配字面意义上的@符号。@在正则表达式中是一个特殊字符,通常需要使用反斜线\进行转义。 -
([A-Za-z0-9_\-\.])+:这部分与第一个捕获组相同,匹配邮箱用户名部分,即@符号后的局部部分。 -
\.:匹配字面意义上的点.。由于点 `.’ 在正则表达式中也是一个特殊字符,表示任意单个字符,因此也需要转义。 -
([A-Za-z]{2,4}):这是一个捕获组,匹配顶级域名(TLD):- 大写字母
A到Z或小写字母a到z。 {2,4}表示前面的字符组合必须连续重复2到4次,这符合大多数顶级域名的长度。
- 大写字母
-
$:表示匹配字符串的结束。
将这些组合起来,这个正则表达式匹配的是一个标准的电子邮件地址,它包含:
- 一个或多个字母、数字、下划线、连字符或点作为用户名。
- 紧跟一个
@符号。 - 然后是域名,由一个或多个字母、数字、下划线、连字符或点组成。
- 最后是一个点
.跟着2到4个字母的顶级域名。
例如,以下电子邮件地址会被匹配:
example@test.comuser.name@sub.domain.org
而以下电子邮件地址则不会被匹配:
example@.com(没有本地部分)example@test..com(顶级域名前有额外的点)example@test_c(顶级域名不是2到4个字符长)
请注意,电子邮件地址的规范可能比这个正则表达式允许的要复杂得多,而且这个正则表达式没有考虑到新的顶级域名可能超过4个字符的情况。因此,对于电子邮件验证,可能需要一个更复杂的正则表达式或者使用专门的验证库。
3、身份证
/^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$/
这个正则表达式 /^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$/ 用于匹配中国的二代身份证号码,它包含了出生日期和校验码。下面是对它的详细解释:
-
^:表示匹配字符串的开始。 -
[1-9]:匹配从1到9的任意一个数字,身份证号码第一位不可能是0。 -
\d{5}:匹配紧随其后的5个数字,代表身份证号码的前5位。 -
(18|19|([23]\d)):匹配18或19或23后跟任意一个数字,代表出生年份的前两位。 -
\d{2}:匹配出生年份的后两位数字。 -
((0[1-9])|(10|11|12)):匹配月份,可以是01到09或10到12。 -
(([0-2][1-9])|10|20|30|31):匹配日期,可以是01到29或10、20、30、31。 -
\d{3}:匹配年份和日期后的3位数字,代表校验码前面的顺序码。 -
[0-9Xx]:匹配最后一位校验码,可以是0到9的任意一个数字或大写X/小写x。 -
$:表示匹配字符串的结束。
将这些组合起来,这个正则表达式匹配的是一个符合中国二代身份证号码格式的18位数字字符串,其中:
- 前6位是地区代码。
- 接下来的8位是出生年月日(YYYYMMDD)。
- 紧随其后的是3位顺序码,其中奇数分配给男性,偶数分配给女性。
- 最后一位是校验码,可以是0到9的数字或X/x字母。
例如,以下身份证号码会被匹配:
11010519760101123437132519880214566X
而以下身份证号码则不会被匹配:
110000197601011234(地区代码不可能全是0)110105186601011234(出生年份不可能小于1800)110105197601131234(日期不可能超过31)
请注意,这个正则表达式只进行了基本的格式验证,并没有考虑到所有可能的合法性问题,如闰月、世纪年等特殊情况。实际应用中,可能需要结合其他方法来确保身份证号码的准确性和有效性。
4、URL
/^((https?|ftp|file):\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
这个正则表达式 /^((https?|ftp|file):\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/ 用于匹配通用的 URL 地址。下面是对它的详细解释:
-
^:表示匹配字符串的开始。 -
((https?|ftp|file):\/\/)?:这是一个可选的捕获组,匹配协议部分,可以是http、https、ftp或file,后面跟着://。整个捕获组出现0次或1次,表示协议部分可以省略。https?:匹配http或https。ftp:匹配ftp。file:匹配file。
-
([\da-z\.-]+):匹配域名部分,可以包含数字、小写字母、点和连字符。 -
\.:匹配字面意义上的点。 -
([a-z\.]{2,6}):匹配顶级域,可以是2到6个小写字母或点。这符合大多数顶级域名的长度。 -
([\/\w \.-]*):匹配路径部分,可以包含斜杠、字母、数字、空格、点或连字符。这个组可以出现0次或多次,表示路径部分可以是可选的。 -
*:表示前面的路径部分可以重复任意次,包括0次。 -
\/?:匹配可选的斜杠,表示路径可能以斜杠结束或不结束。 -
$:表示匹配字符串的结束。
将这些组合起来,这个正则表达式匹配的是一个通用的 URL 地址,它包含:
- 可选的协议部分(http, https, ftp, file)。
- 域名部分,由数字、小写字母、点和连字符组成。
- 顶级域,由2到6个小写字母或点组成。
- 可选的路径部分,由斜杠、字母、数字、空格、点或连字符组成,路径可以包含多个段。
- 整个 URL 可以以斜杠结束或不结束。
例如,以下 URL 地址会被匹配:
http://www.example.comhttps://www.example.com/path/to/resourceftp://ftp.example.com/dir/file.txtfile:///path/to/local/fileexample.com
而以下 URL 地址则不会被匹配:
http:///example.com(缺少协议的 “😕/” 部分)http://example(缺少顶级域)http://example.c(顶级域太短)http://example.com/invalid-/./path(路径中包含无效字符)
请注意,由于 URL 的复杂性,这个正则表达式可能无法匹配所有有效的 URL,也无法验证 URL 的合法性。对于更准确的 URL 验证,可能需要使用更复杂的正则表达式或专门的验证库。
5、微信号
/^[a-zA-Z]([-_a-zA-Z0-9]{5,19})+$/
6至20位,以字母开头,字母,数字,减号,下划线
-
^:表示匹配字符串的开始。 -
[a-zA-Z]:匹配一个字母,可以是大写或小写,作为字符串的起始字符。 -
([-_a-zA-Z0-9]{5,19}):这是一个捕获组,匹配以下内容:[-_a-zA-Z0-9]:一个字符,可以是连字符-、下划线_、字母(大写或小写)或数字。{5,19}:指定前面的字符组合至少重复5次,最多重复19次。这意味着整个捕获组的长度为6到20个字符。
-
+:表示前面的捕获组可以重复一次或多次。由于第一个字符已经匹配了一个字母,整个模式至少需要一个捕获组,因此整个字符串的长度至少为6个字符。 -
$:表示匹配字符串的结束。
将这些组合起来,这个正则表达式匹配的是一个以字母开头,后跟5到20个字符(可以是连字符、下划线、字母或数字)的字符串,整个字符串长度至少为6个字符。每个部分的字符可以是大写或小写。
例如,以下字符串会被匹配:
user_123profileName-1234Abcdefghijk
而以下字符串则不会被匹配:
123(以数字开头)_username(以下划线开头)user(长度小于6个字符)toolongusername12345678901234567890(长度超过20个字符)
请注意,这个正则表达式是根据特定规则设计的,不同的应用场景可能需要不同的正则表达式规则。
6、车牌号
/^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/
这个正则表达式 /^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/ 用于匹配中国大陆的机动车车牌号码。下面是对它的详细解释:
-
^:表示匹配字符串的开始。 -
[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]:这是一个字符集,匹配车牌号码的第一个字符,可以是中国大陆各个省份的汉字缩写(如“京”代表北京,“沪”代表上海等),或者是一个介于A到Z之间的任何一个大写字母,也可以是“使”、“领”等特殊字符。 -
{1}:表示前面的字符集中的任意一个字符正好出现一次。 -
[A-Z]:匹配一个介于A到Z之间的任何一个大写字母,这通常代表车牌号码中的字母部分。 -
{1}:表示前面的字符集中的任意一个字符正好出现一次。 -
[A-Z0-9]{4}:匹配四个字符,可以是大写字母或数字,这通常代表车牌号码中的数字和字母组合部分。 -
[A-Z0-9挂学警港澳]:这是一个字符集,匹配车牌号码的最后一个字符,可以是大写字母、数字或者特定的字符(如“挂”、“学”、“警”、“港”、“澳”)。 -
{1}:表示前面的字符集中的任意一个字符正好出现一次。 -
$:表示匹配字符串的结束。
将这些组合起来,这个正则表达式匹配的是一个符合中国大陆机动车车牌号码格式的字符串,其中:
- 第一个字符是省份缩写或特定的大写字母。
- 第二个字符是一个大写字母。
- 接下来的四个字符是字母和数字的组合。
- 最后一个字符是大写字母、数字或特定的字符。
例如,以下车牌号码会被匹配:
京A1234挂沪B5678学苏D0099警
而以下车牌号码则不会被匹配:
京A123(长度不足)京A1234ABC(长度超出或格式不正确)京A12344(最后一个字符不符合规定)
请注意,由于车牌号码的格式可能会有所变化,这个正则表达式可能需要根据最新的车牌号码规则进行相应的调整。
7、IP地址
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
这个正则表达式 /^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/ 用于精确匹配 IPv4 地址。下面是对它的详细解释:
-
^:表示匹配字符串的开始。 -
(?: ... ):非捕获括号,用于分组而不捕获匹配的文本,这对于使用量词(如{3})是必要的。 -
25[0-5]:匹配 250 到 255。 -
2[0-4][0-9]:匹配 200 到 249。 -
0[1-9][0-9]?或1[0-9][0-9]?或[1-9]?[0-9]?:匹配 0 到 199。这里允许单个数字(0-9)或两位数字(10-99),以及可选的前导零。 -
\.:匹配字面意义上的点(.在正则表达式中通常表示任意单个字符,因此需要用反斜线转义)。 -
{3}:表示前面的非捕获括号内的模式重复恰好3次,用于匹配 IPv4 地址的前三个八位字节。 -
(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?):这与前面的模式相同,匹配 IPv4 地址的最后一个八位字节。 -
$:表示匹配字符串的结束。
将这些组合起来,这个正则表达式确保每个八位字节都在合法的范围内,即 0 到 255,并且整个字符串正好是一个 IPv4 地址,不包含任何前缀或后缀。
例如,以下 IP 地址会被匹配:
192.168.1.110.0.0.10255.255.255.255
而以下字符串则不会被匹配:
0.0.0.0(虽然有效,但不符合一些人对私有IP地址的过滤标准)192.168.1192.168.1.1.1(多了一个八位字节)123.45.6.789(八位字节超出范围)
请注意,这个正则表达式只匹配标准的 IPv4 地址格式,不匹配 IPv6 地址,也不考虑任何特殊的网络协议或配置细节。
8、十六进制颜色值
/^#?([a-fA-F0-9]{6}|[a-fA-F0-9]{3})$/
这个正则表达式 /^#?([a-fA-F0-9]{6}|[a-fA-F0-9]{3})$/ 用于匹配 CSS 中的十六进制颜色代码。下面是对它的详细解释:
-
^:表示匹配字符串的开始。 -
#?:匹配#符号零次或一次。问号?表示前面的字符#是可选的。 -
([a-fA-F0-9]{6}|[a-fA-F0-9]{3}):这是一个组合的捕获组,用于匹配两种不同长度的十六进制颜色代码:-
[a-fA-F0-9]{6}:匹配恰好六个十六进制数字(0-9 或 a-f)。这是完整的十六进制颜色代码,例如1a2b3c。 -
[a-fA-F0-9]{3}:匹配恰好三个十六进制数字。这是简写的十六进制颜色代码,其中每个数字被重复两次以形成完整的颜色代码,例如123等同于112233。 -
|:逻辑“或”运算符,用于匹配捕获组中的任意一种模式。
-
-
$:表示匹配字符串的结束。
将这些组合起来,这个正则表达式匹配的是一个可选的 # 符号后跟六个或三个十六进制数字的字符串,这符合 CSS 中十六进制颜色代码的标准格式。
例如,以下颜色代码会被匹配:
#1a2b3cabc123a1b2c3123
而以下字符串则不会被匹配:
#1a2b3g(包含无效的十六进制字符 ‘g’)1a2b3c4d(包含多余的十六进制数字)#xyz(虽然#xyz是有效的 CSS 颜色代码,但它不符合这个正则表达式的规则,因为它要求是六个或三个十六进制数字)
请注意,CSS 还支持其他颜色表示方法,如 RGB、RGBA、HSL 或颜色名称,这个正则表达式仅用于匹配十六进制颜色代码。
公众号
关注公众号『前端也能这么有趣』,获取更多有趣内容。
说在后面
🎉 这里是 JYeontu,现在是一名前端工程师,有空会刷刷算法题,平时喜欢打羽毛球 🏸 ,平时也喜欢写些东西,既为自己记录 📋,也希望可以对大家有那么一丢丢的帮助,写的不好望多多谅解 🙇,写错的地方望指出,定会认真改进 😊,偶尔也会在自己的公众号『
前端也能这么有趣』发一些比较有趣的文章,有兴趣的也可以关注下。在此谢谢大家的支持,我们下文再见 🙌。