在当今信息爆炸的时代,如何高效地管理和检索大量数据成为了一个重要课题。网易有道推出的开源项目QAnything,正是为了解决这一问题而生。QAnything是一个本地知识库问答系统,支持多种文件格式和数据库,允许用户在离线状态下进行安装和使用。用户只需将任何格式的本地存储文件放入系统,即可获得准确、快速且可靠的答案。
关键特性
QAnything的主要优势在于它能够处理多种格式的文件,包括PDF、Word、PPT、Excel、Markdown、Email、TXT、图片以及CSV等,这使得它在处理不同来源和类型的数据时表现出极高的灵活性。用户可以轻松地将这些文件投入系统,期待得到迅速且准确的回答,这大大提升了信息检索的效率。
系统的数据安全特性同样值得一提。QAnything支持在断开网络的情况下进行安装和使用,这为那些对数据保密性有高要求的企业和个人提供了强有力的保障。系统的跨语言问答支持也是一个显著的优势,它能够自由地在中文和英文之间切换,不受文档语言的限制,这对于多语言环境的用户来说是一个巨大的便利。
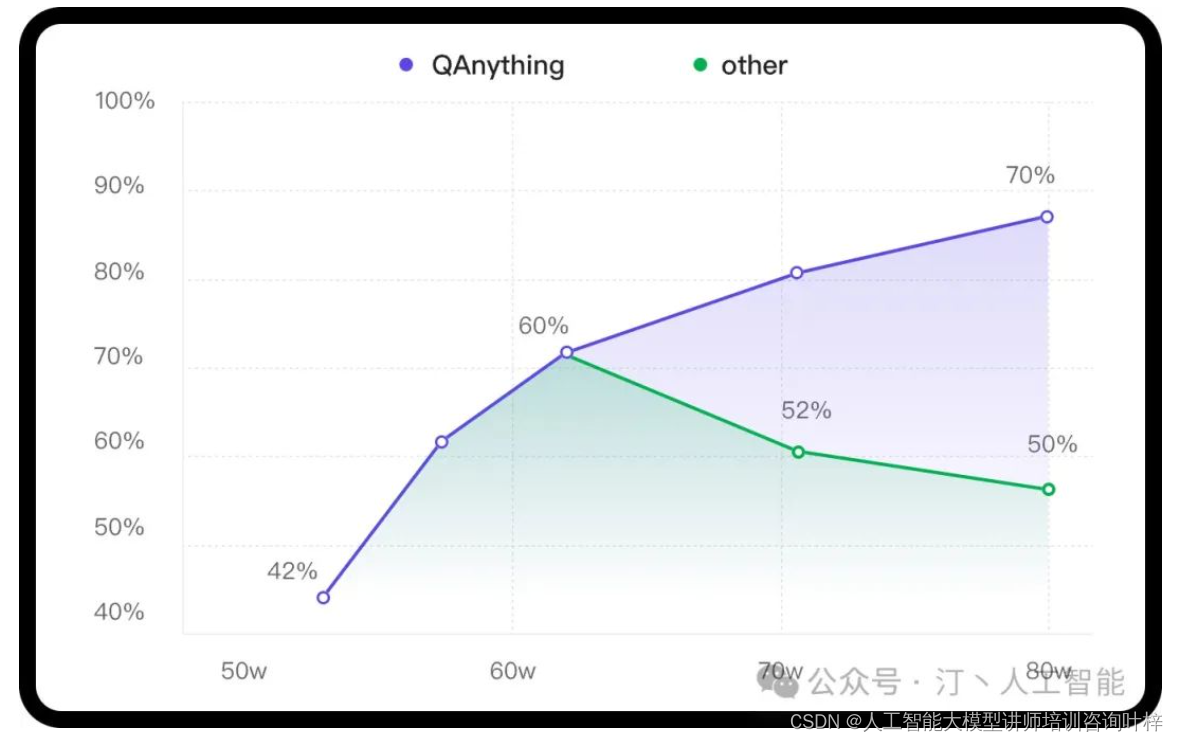
在处理大规模数据时,QAnything的两阶段向量排序技术更是让人眼前一亮。这项技术有效解决了大规模数据检索中常见的准确度下降问题,实现了数据量越大,检索效果越好的优异表现。
在性能方面,QAnything作为一个高性能的生产级系统,它的稳定性和可靠性使其成为企业级应用的理想选择。用户无需进行复杂的配置,一键即可完成安装部署,轻松实现即装即用。
QAnything的易用性也是其一大亮点。无论是个人用户还是企业用户,都能够快速上手,享受到QAnything带来的便捷。而且,QAnything还支持多知识库的问答,让用户能够根据自己的需求,选择和使用不同的知识库。
QAnything采用了BCEmbedding作为其检索组件,这是一个由网易有道开发的中英双语和跨语种语义表征算法模型库。BCEmbedding的强悍双语和跨语种能力,为QAnything提供了强大的语义检索支持,确保了问答结果的准确性和相关性。
QAnything已经在有道速读和有道翻译等多个产品中得到了成功的应用实践,技术成熟度和实用。其开源特性,也为广大开发者和研究者提供了广阔的创新空间。
架构设计
QAnything的架构设计是其高性能问答能力的核心。这一设计采用了创新的两阶段检索方法,特别针对大规模知识库数据场景进行了优化。
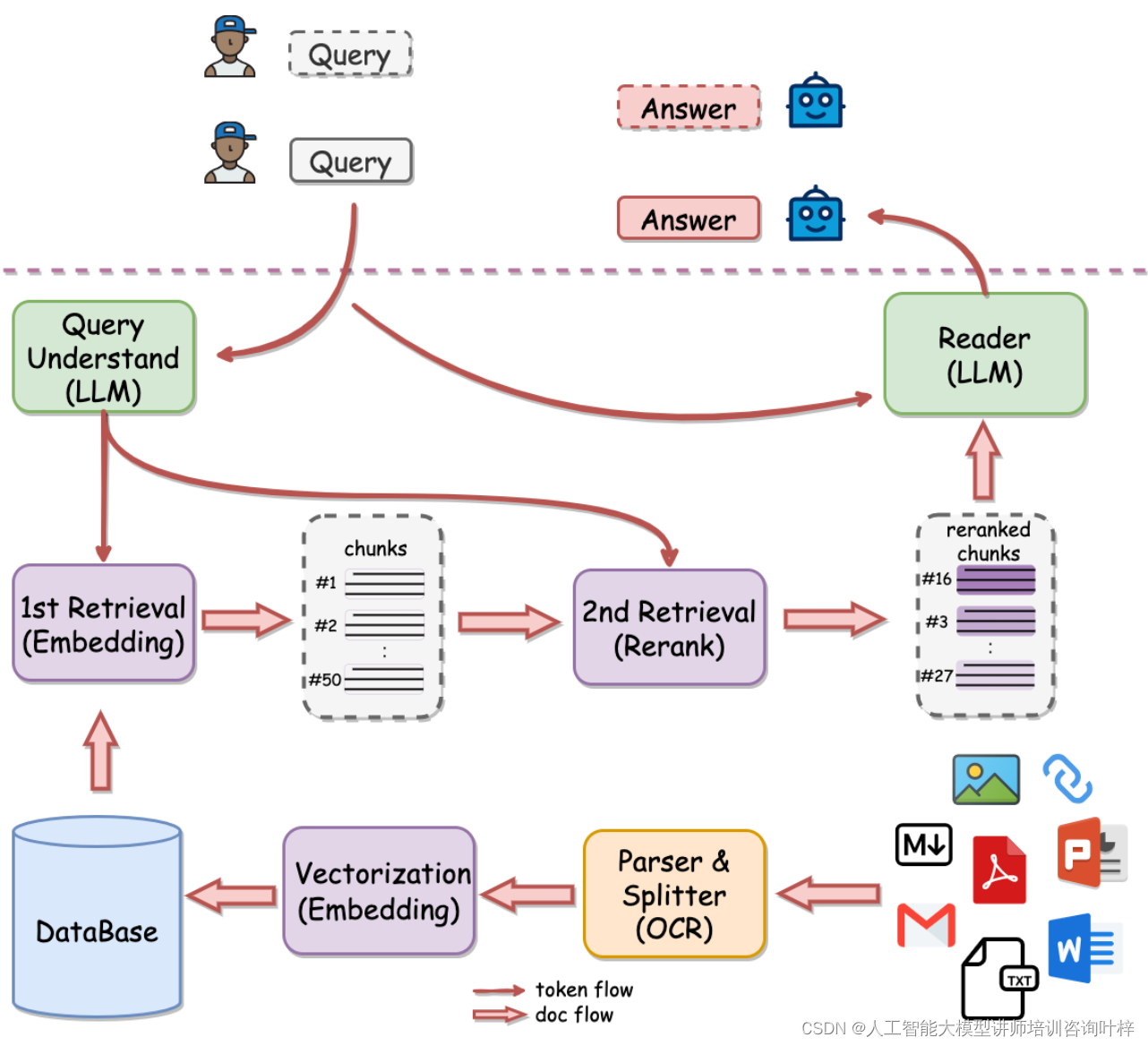
在第一阶段,QAnything使用嵌入技术将文档和查询问题转换成高维向量空间中的点,这个过程称为嵌入检索。这一阶段的关键在于,它能够将文本数据转换为能够通过数学方法进行比较和分析的格式。通过这种方式,QAnything能够快速识别和检索与查询最相关的文档或文档的部分。
嵌入检索的优势在于其能够处理各种格式的文档,包括PDF、Word、PPT、Markdown、Eml、TXT、图片以及网页链接等。这使得QAnything成为一个多才多艺的系统,能够跨越不同格式的数据源进行信息检索。
| 名称 | Retrieval | STS | PairClassification | Classification | Reranking | Clustering | 平均值 |
|---|---|---|---|---|---|---|---|
| bge-base-en-v1.5 | 37.14 | 55.06 | 75.45 | 59.73 | 43.05 | 37.74 | 47.20 |
| bge-base-zh-v1.5 | 47.60 | 63.72 | 77.40 | 63.38 | 54.85 | 32.56 | 53.60 |
| bge-large-en-v1.5 | 37.15 | 54.09 | 75.00 | 59.24 | 42.68 | 37.32 | 46.82 |
| bge-large-zh-v1.5 | 47.54 | 64.73 | 79.14 | 64.19 | 55.88 | 33.26 | 54.21 |
| jina-embeddings-v2-base-en | 31.58 | 54.28 | 74.84 | 58.42 | 41.16 | 34.67 | 44.29 |
| m3e-base | 46.29 | 63.93 | 71.84 | 64.08 | 52.38 | 37.84 | 53.54 |
| m3e-large | 34.85 | 59.74 | 67.69 | 60.07 | 48.99 | 31.62 | 46.78 |
| bce-embedding-base_v1 | 57.60 | 65.73 | 74.96 | 69.00 | 57.29 | 38.95 | 59.43 |
一阶段检索指标汇总
尽管第一阶段的嵌入检索已经能够提供相当准确的结果,但随着知识库数据量的增加,简单的向量匹配可能不足以保证检索质量。因此,QAnything引入了第二阶段的重排检索,这一阶段利用更复杂的算法对第一阶段的结果进行精细的排序和优化。
重排检索的目标是在已经缩小范围的结果集中,进一步识别出与查询最为相关的文档或文档片段。这一阶段可能涉及到对文档的深入分析,包括但不限于语义理解、上下文关联和相关信息的整合。
| 模型名称 | Reranking | 平均值 |
|---|---|---|
| bge-reranker-base | 57.78 | 57.78 |
| bge-reranker-large | 59.69 | 59.69 |
| bce-reranker-base_v1 | 60.06 | 60.06 |
二阶段检索指标汇总
两阶段检索的优势:
-
提高准确性:通过两阶段的检索,QAnything能够在大数据量中保持高准确度,确保用户获得最相关的信息。
-
解决检索退化问题:在数据量不断增长的情况下,单纯的基于向量的第一阶段检索可能会出现准确度下降的问题。第二阶段的重排检索有效解决了这一问题,确保了随着数据量的增加,检索性能不降反升。
-
优化性能:两阶段检索的设计允许系统在保持高准确度的同时,优化查询响应时间和系统资源的使用效率。
QAnything的两阶段检索背后,是强大的BCEmbedding模型。这一模型不仅在语义表征评测中表现卓越,而且在跨语言的问答场景中也有着出色的表现。BCEmbedding的EmbeddingModel专注于生成语义向量,而RerankerModel则擅长对搜索结果进行优化和精排。
QAnything还结合了最新的语言模型和算法,如基于LlamaIndex的RAG评测,进一步增强了系统的问答能力。这些技术的融合,使得QAnything在处理复杂查询和大规模数据时,能够提供更加精准和可靠的结果。
安装与使用
系统条件:
- 对于Linux系统,需要有一个NVIDIA GPU,内存至少为4GB,并且安装了兼容的NVIDIA驱动和CUDA版本。
- 对于Windows 11 with WSL 2,除了上述的GPU要求外,还需要安装GEFORCE EXPERIENCE和Docker Desktop。
安装步骤
-
克隆项目仓库: 打开终端或命令提示符,运行以下命令来克隆QAnything的GitHub仓库到本地机器:
git clone https://github.com/netease-youdao/QAnything.git -
进入项目目录: 克隆完成后,进入项目根目录:
cd QAnything -
执行启动脚本: 在项目根目录下,执行启动脚本
run.sh。这将根据您系统的环境自动配置并启动QAnything服务:bash run.sh如果您使用的是Windows系统,请先进入WSL环境,然后再执行上述命令。
-
指定GPU启动(可选): 如果需要指定特定的GPU进行启动,可以使用以下命令:
bash run.sh -i 0 # 指定0号GPU启动 -
多GPU启动(可选): 如果您有多个GPU,并且希望QAnything使用它们,可以通过指定多个GPU ID来启动:
bash run.sh -i 0,1 # 指定0号和1号GPU启动
使用QAnything
访问前端页面
安装并启动QAnything服务后,您可以通过以下地址在浏览器中访问前端页面:
http://your_host:5052/qanything/
这里的your_host是您的服务器或本地机器的IP地址或主机名。
使用API接口
如果您希望通过编程方式与QAnything交互,可以使用API接口。API的基本地址是:
http://your_host:8777/api/
具体的API文档可以在以下地址找到:
http://your_host:8777/api/docs
这里提供了API的详细描述、请求方法、参数说明等信息。
关闭服务
当您完成使用并希望关闭QAnything服务时,可以执行关闭脚本close.sh:
bash close.sh注意事项
- 确保在安装过程中遵循了所有前提条件,包括软件版本和环境配置。
- 如果在安装或使用过程中遇到问题,可以参考项目的FAQ或在GitHub上提出issue。
- 根据您的网络环境,可能需要配置代理或VPN来访问某些依赖服务。
QAnything作为一个全能型的本地知识库问答系统,以其强大的功能和灵活的部署方式,为个人和企业提供了一个高效、安全的数据检索解决方案。随着社区的不断壮大和技术的持续迭代,QAnything有望在未来发挥更大的作用。
项目地址:GitHub - netease-youdao/QAnything: Question and Answer based on Anything.

![[c++刷题]贪心算法.N01](https://img-blog.csdnimg.cn/direct/01e9ca1efbce45a1844aad3f2427a250.png)