前言
我们可以以shell的方式来维护和管理HBase。例如:执行建表语句、执行增删改查操作等等。
过滤器的用法
过滤器一般结合scan命令来使用。打开HBase的JAVA API文档。找到RowFilter的构造器说明,我们来看以下,HBase的过滤器该如何使用。
scan '表名', { Filter => "过滤器(比较运算符, '比较器表达式')” }
比较运算符
| 比较运算符 | 描述 |
|---|---|
| = | 等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| != | 不等于 |
比较器
| 比较器 | 描述 |
|---|---|
| BinaryComparator | 匹配完整字节数组 |
| BinaryPrefixComparator | 匹配字节数组前缀 |
| BitComparator | 匹配比特位 |
| NullComparator | 匹配空值 |
| RegexStringComparator | 匹配正则表达式 |
| SubstringComparator | 匹配子字符串 |
比较器表达式
基本语法:比较器类型:比较器的值
| 比较器 | 表达式语言缩写 |
|---|---|
| BinaryComparator | binary:值 |
| BinaryPrefixComparator | binaryprefix:值 |
| BitComparator | bit:值 |
| NullComparator | null |
| RegexStringComparator | regexstring:正则表达式 |
| SubstringComparator | substring:值 |
需求一:使用RowFilter查询指定订单ID的数据
-
需求
只查询订单的ID为:02602f66-adc7-40d4-8485-76b5632b5b53、订单状态以及支付方式 -
分析
1.因为要订单ID就是ORDER_INFO表的rowkey,所以,我们应该使用rowkey过滤器来过滤
2.通过HBase的JAVA API,找到RowFilter构造器
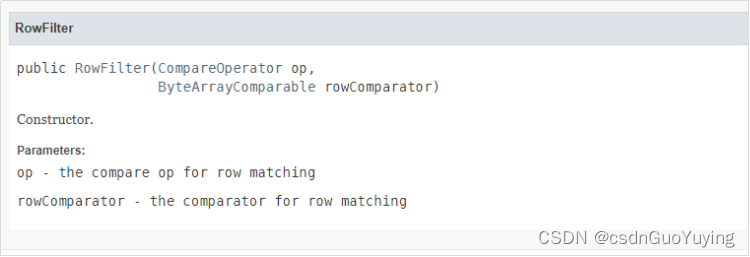
通过上图,可以分析得到,RowFilter过滤器接受两个参数,op——比较运算符
rowComparator——比较器所以构建该Filter的时候,只需要传入两个参数即可
-
命令
scan 'ORDER_INFO', {FILTER => "RowFilter(=,'binary:02602f66-adc7-40d4-8485-76b5632b5b53')"}
需求二:查询状态为已付款的订单
-
需求
查询状态为「已付款」的订单 -
分析
1.因为此处要指定列来进行查询,所以,我们不再使用rowkey过滤器,而是要使用列过滤器
2.我们要针对指定列和指定值进行过滤,比较适合使用SingleColumnValueFilter过滤器,查看JAVA API
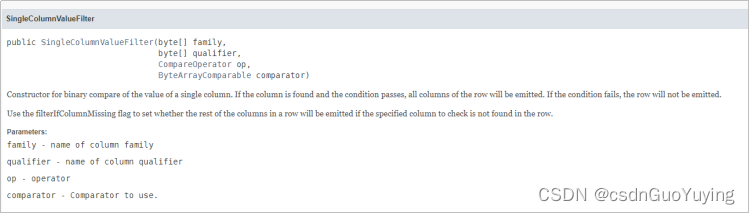
需要传入四个参数:列簇
列标识(列名)
比较运算符
比较器注意:
列名STATUS的大小写一定要对!此处使用的是大写!
列名写错了查不出来数据,但HBase不会报错,因为HBase是无模式的 -
命令
scan 'ORDER_INFO', {FILTER => "SingleColumnValueFilter('C1', 'STATUS', =, 'binary:已付款')", FORMATTER => 'toString'}
需求三:查询支付方式为1,且金额大于3000的订单
-
分析
- 此处需要使用多个过滤器共同来实现查询,多个过滤器,可以使用AND或者OR来组合多个过滤器完成查询
- 使用SingleColumnValueFilter实现对应列的查询
-
命令
- 查询支付方式为1
SingleColumnValueFilter('C1', 'PAYWAY', = , 'binary:1') - 查询金额大于3000的订单
SingleColumnValueFilter('C1', 'PAY_MONEY', > , 'binary:3000') - 组合查询
scan 'ORDER_INFO', {FILTER => "SingleColumnValueFilter('C1', 'PAYWAY', = , 'binary:1') AND SingleColumnValueFilter('C1', 'PAY_MONEY', > , 'binary:3000')", FORMATTER => 'toString'}
- 查询支付方式为1
-
注意:
HBase shell中比较默认都是字符串比较,所以如果是比较数值类型的,会出现不准确的情况。例如:在字符串比较中4000是比100000大的
INCR
-
需求
某新闻APP应用为了统计每个新闻的每隔一段时间的访问次数,他们将这些数据保存在HBase中。
该表格数据如下所示:新闻ID 访问次数 时间段 ROWKEY 0000000001 12 00:00-01:00 0000000001_00:00-01:00 0000000002 12 01:00-02:00 0000000002_01:00-02:00 要求:原子性增加新闻的访问次数值。
-
incr操作简介
incr可以实现对某个单元格的值进行原子性计数。语法如下:
incr '表名','rowkey','列蔟:列名',累加值(默认累加1)- 如果某一列要实现计数功能,必须要使用incr来创建对应的列
- 使用put创建的列是不能实现累加的
-
导入测试数据
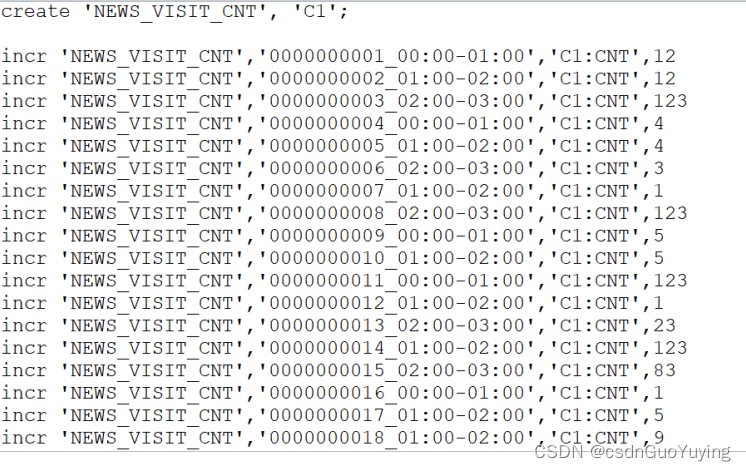
该脚本创建了一个表,名为NEWS_VISIT_CNT,列蔟为C1。并使用incr创建了若干个计数器,每个rowkey为:新闻的编号_时间段。CNT为count的缩写,表示访问的次数。
hbase shell /export/software/NEWS_VISIT_CNT.txt scan 'NEWS_VISIT_CNT', {LIMIT => 5, FORMATTER => 'toString'} -
需求一:对0000000020新闻01:00 - 02:00访问计数+1
- 获取0000000020这条新闻在01:00-02:00当前的访问次数
get_counter 'NEWS_VISIT_CNT','0000000020_01:00-02:00','C1:CNT'
此处,如果用get获取到的数据是这样的:
base(main):029:0> get ‘NEWS_VISIT_CNT’,‘0000000020_01:00-02:00’,‘C1:CNT’
COLUMN CELL
C1:CNT timestamp=1599529533072, value=\x00\x00\x00\x00\x00\x00\x00\x06
1 row(s)
Took 0.0243 seconds-
使用incr进行累加
incr 'NEWS_VISIT_CNT','0000000020_01:00-02:00','C1:CNT' -
再次查看新闻当前的访问次数
get_counter 'NEWS_VISIT_CNT','0000000020_01:00-02:00','C1:CNT'
- 获取0000000020这条新闻在01:00-02:00当前的访问次数






![洛谷-P2114 [NOI2014] 起床困难综合症](https://img-blog.csdnimg.cn/img_convert/7edf53c01bf4534d76928418a7f7b6eb.png)


![[GYCTF2020]EasyThinking (ThinkPHP V6.0.0)](https://img-blog.csdnimg.cn/2e9f06245b514ab38ea4936319e11d5a.png)