YOLOV3 Pytorch版本代码解读
代码与coco数据集关注
wx公众号JokerTong回复yolov3即可获取
参考视频 YOLO系列算法
文章目录
- YOLOV3 Pytorch版本代码解读
- 数据集准备与关键文件说明
- 前提准备
- 代码大致流程
- 需要自行修改代码的部分
- 项目代码解读
- 一 数据与标签的读取
- 二 模型构造
- convolutional层的构建
- rout层与shortcut层的构建
- yolo层的构建
- 三 前向传播
- 四 计算损失
数据集准备与关键文件说明
使用经典的coco2014数据集,下载地址点击此处进入官网下载(也可以自行去网上搜索)
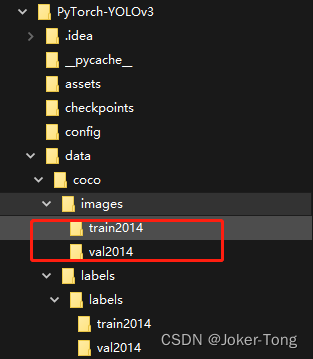
下载之后解压到项目对应的文件夹, 如下
下载的数据集image和label的版本需要一一对应
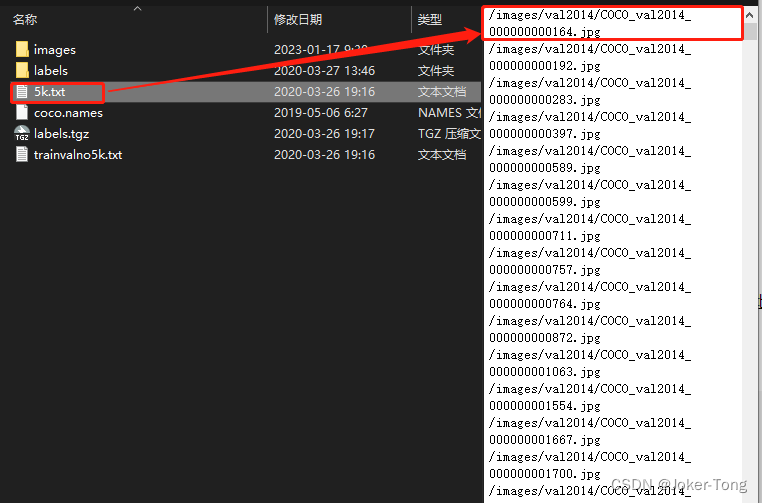
trainvalno5k.txt文件
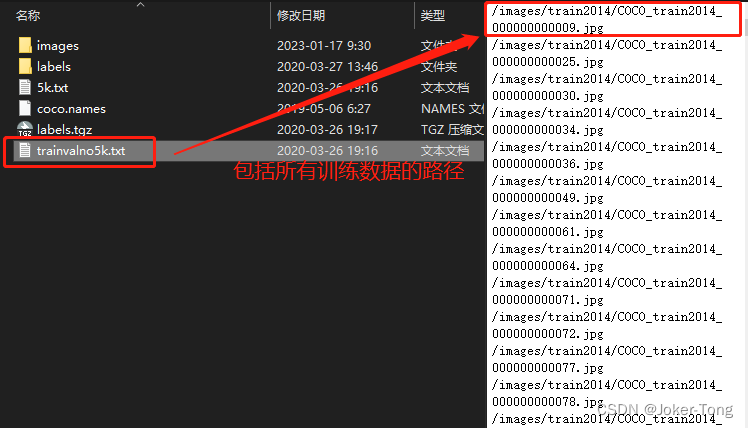
5k.txt文件 : 验证集的数据的位置
PyTorch-YOLOv3\config\yolov3.cfg
网络配置文件
前提准备
代码大致流程
第一步: 加载配置参数
第二步: 构造模型
第三步: 读取数据
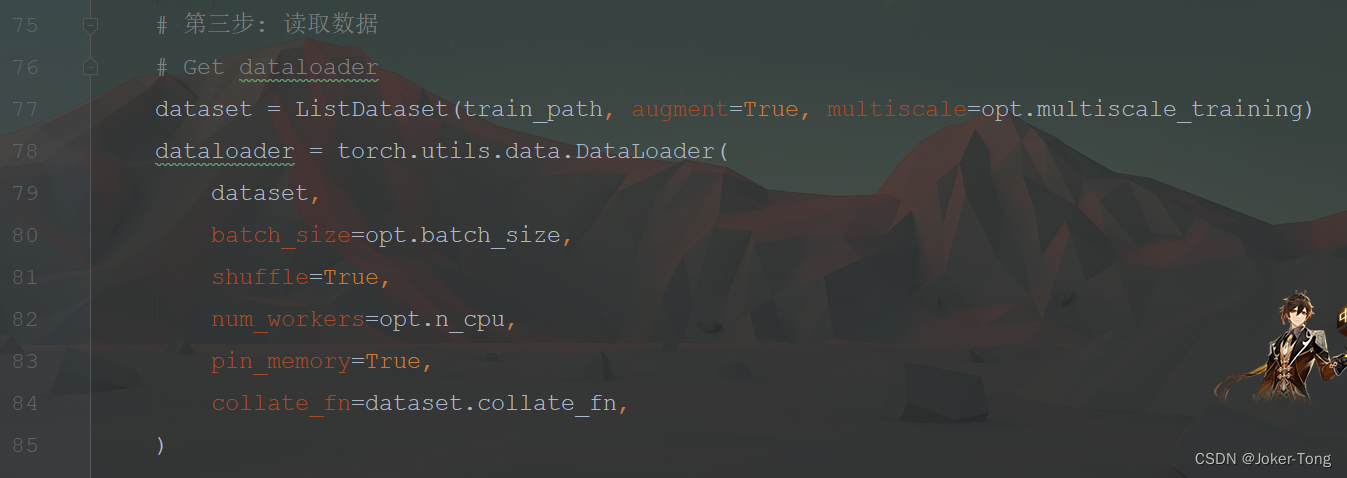
Tips:以前在小数据集上进行训练的时候我们可以将数据集全部加载到内存中,但是由于coco数据集太大了, 内存放不下, 因此我们使用generator来提供数据, 在训练的过程中才读取数据, 根据模型的需要一个batch一个batch的为其提供数据
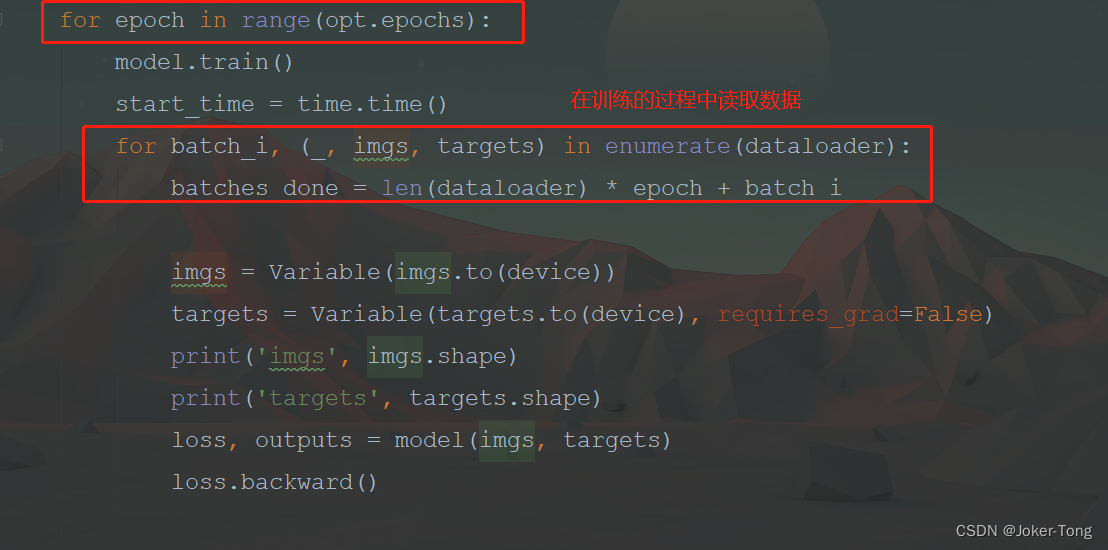
需要自行修改代码的部分
添加训练参数
--data_config config/coco.data
--pretrained_weights weights/darknet53.conv.74
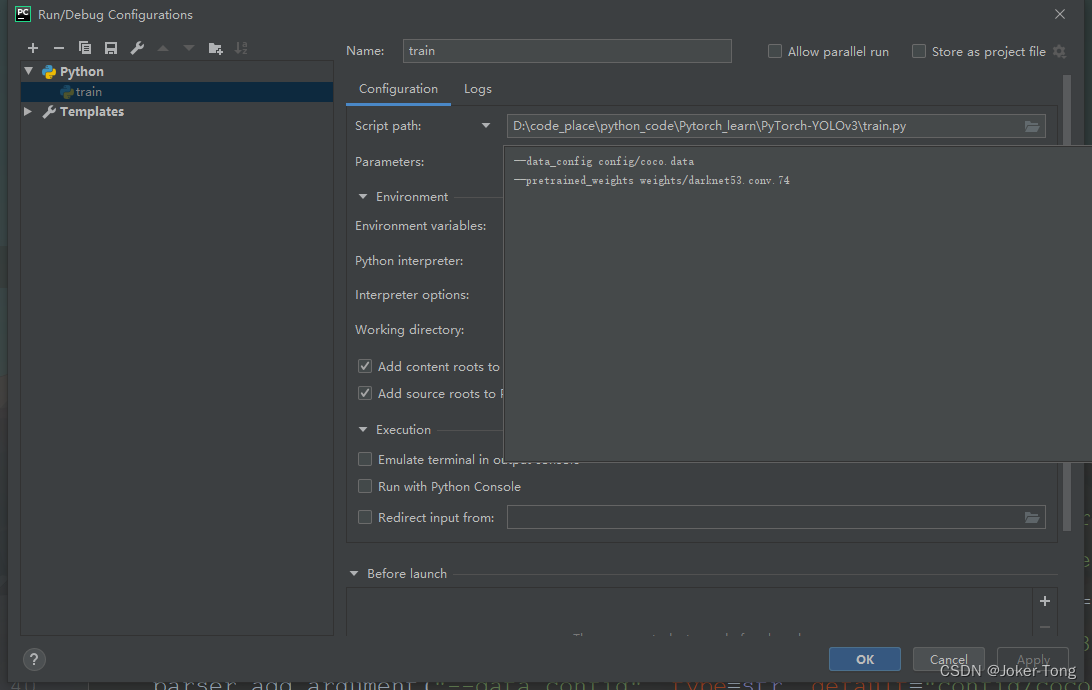
coco.data描述了训练数据集所需要的所有信息: 类别, 训练数据, 验证数据
pretrained_weights 迁移学习的思想, 加载一个预训练模型
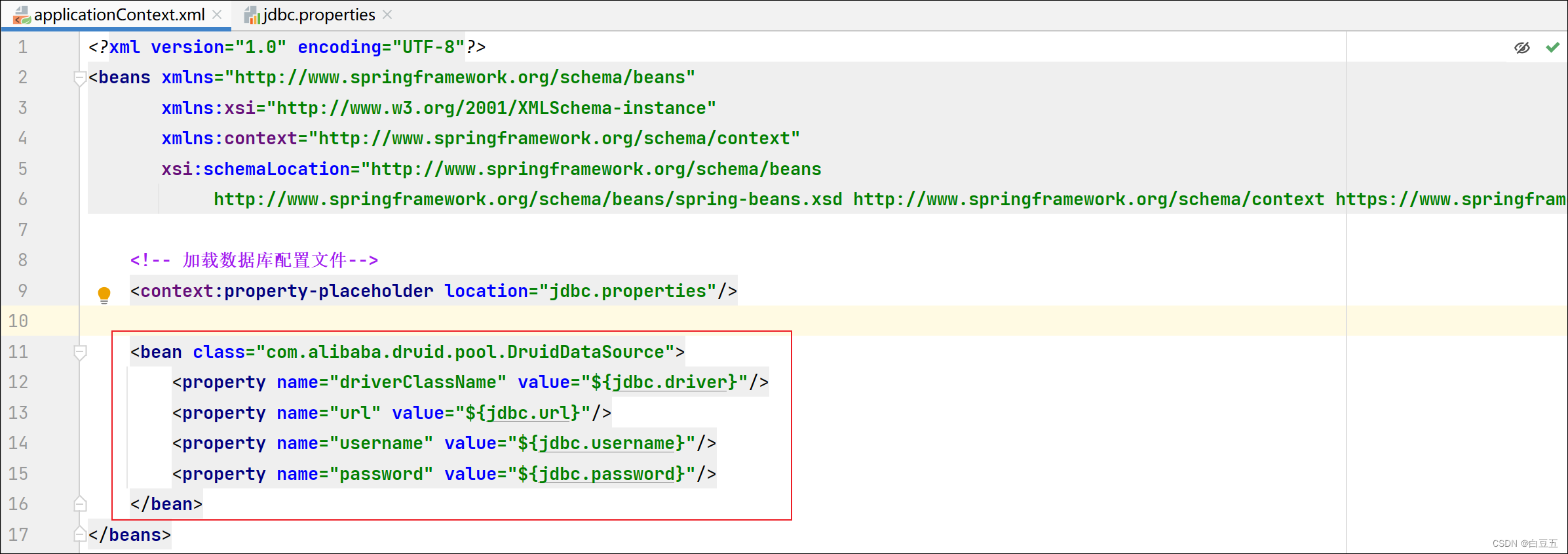
修改数据集路径
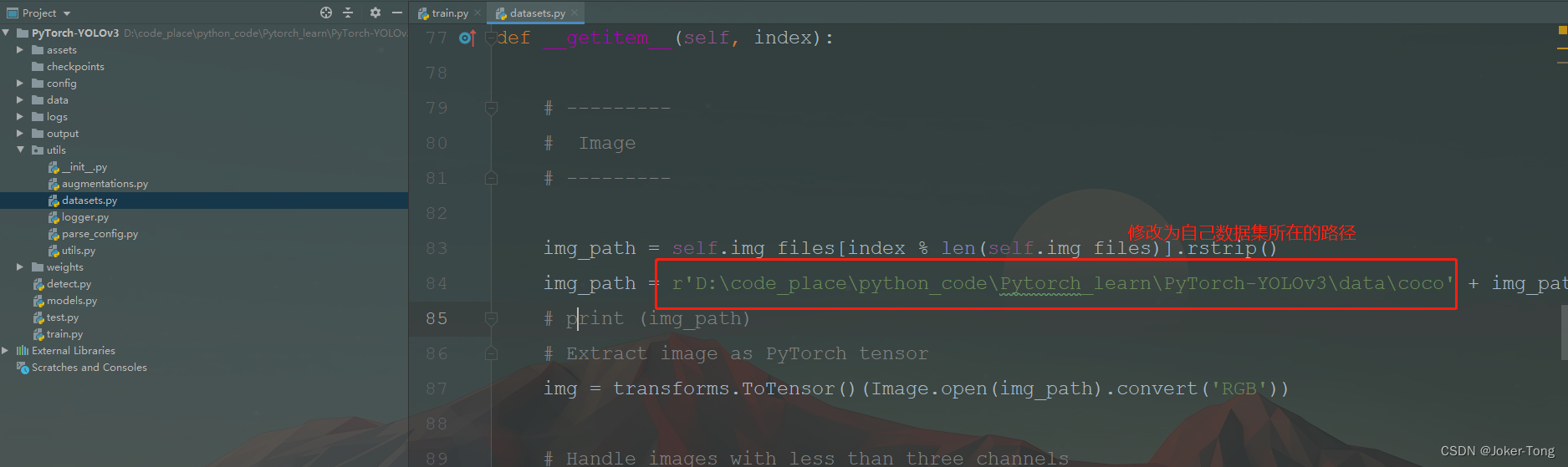

项目代码解读
一 数据与标签的读取
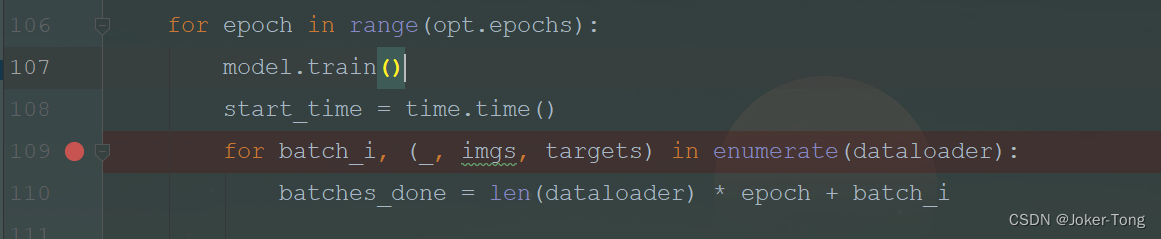
在109行打上断点, 观察数据的读取过程
点击Step Into My Code进入项目中的datasets.py文件, 可以看出, dataset通过getitem一张一张的读取图片
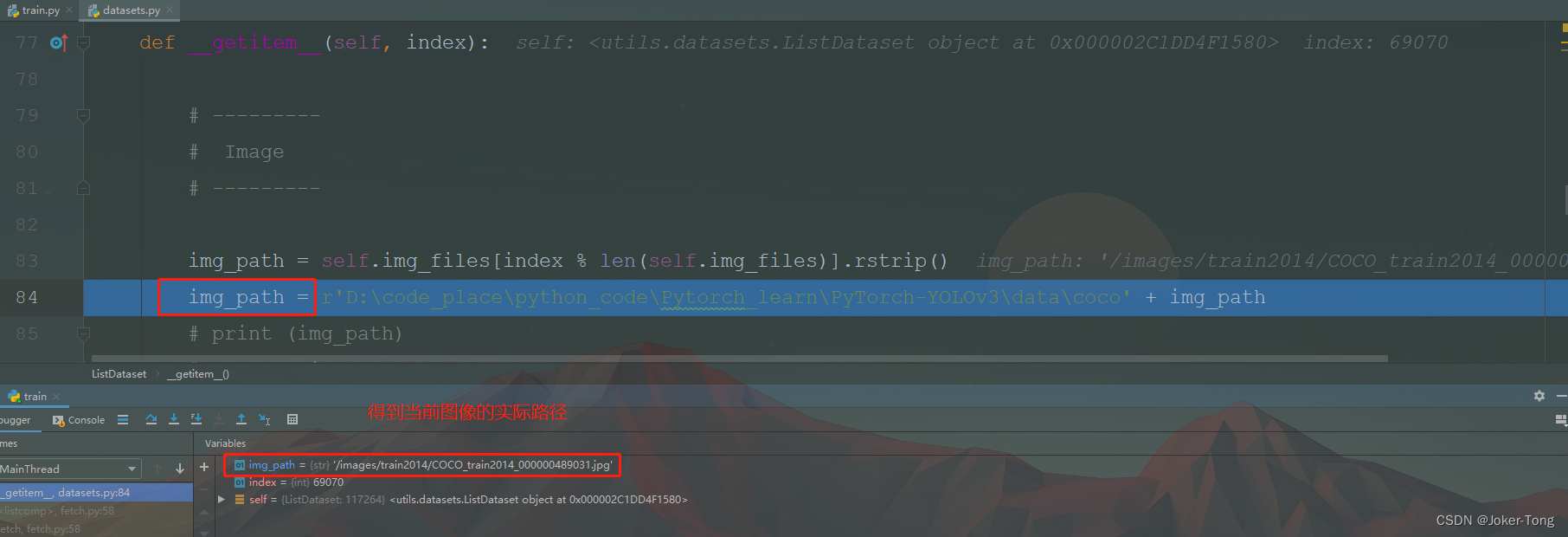
使用Image.open实际读取图片,统一通道为RGB,并且转换为tensor格式

使用padding的思想, 把原本的长方形图片padding为正方形

与读取图像类似, 读取对应的标签, 里面包括了类别, box的信息
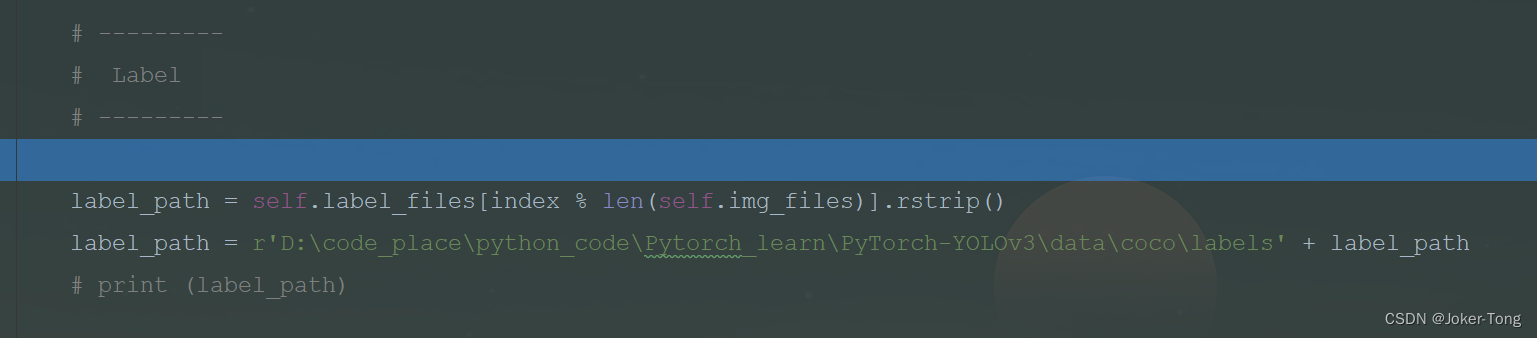
这里要注意 图片的编号与标签的编号应该是对应的, 不然数据与标签不匹配训练结果啥也不是
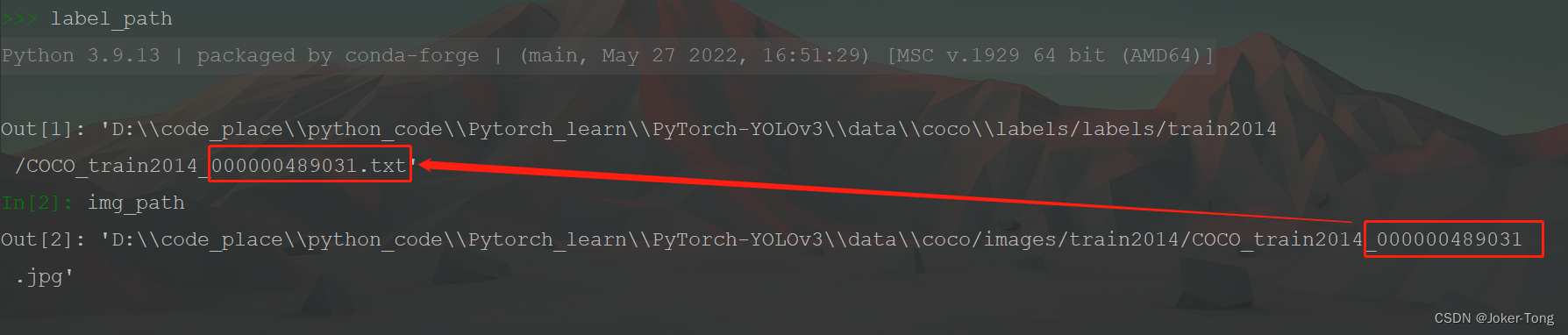
读取label文件中的物体框信息
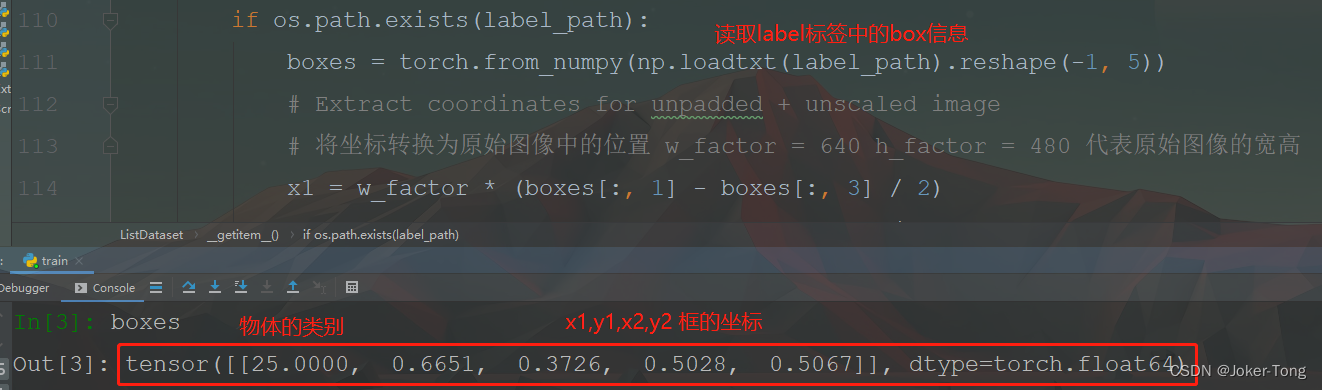
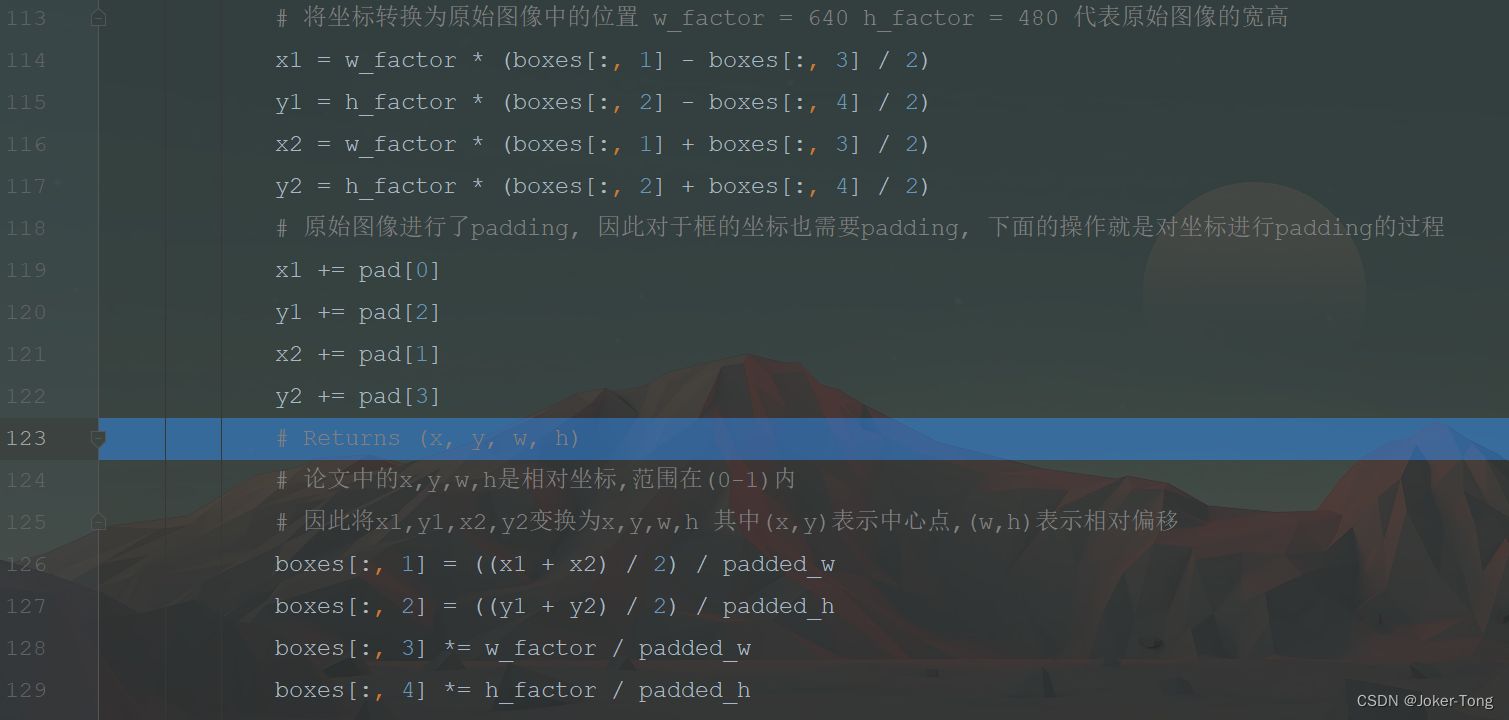
原始图像经过了padding处理, 因此标签中框的坐标也需要进行padding的操作, 最后转化为网络中需要的x,y,w,h格式
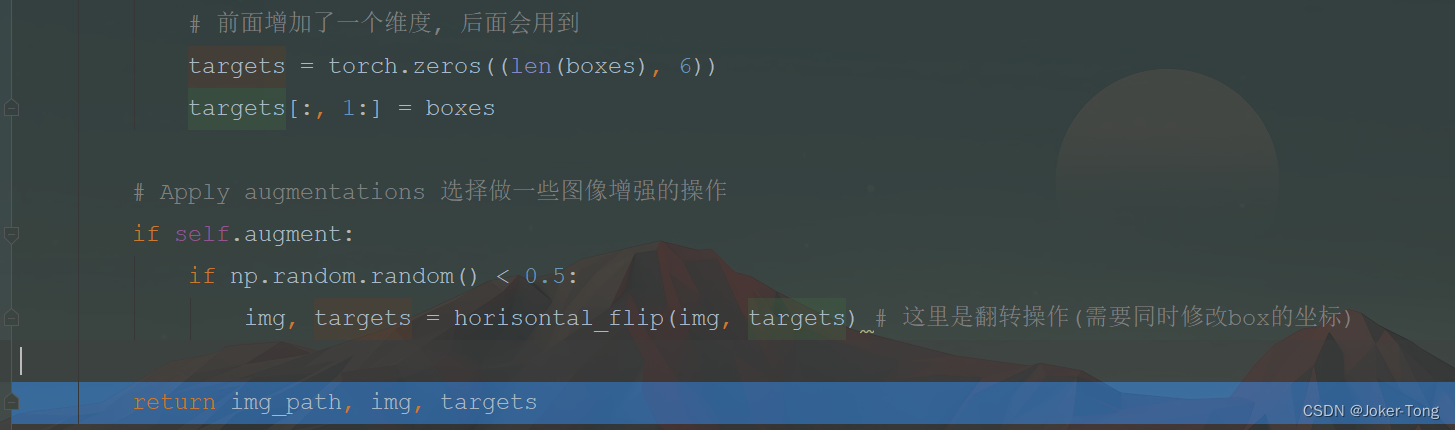
这一系列操作之后, 得到一个img 和 target, 后面会反复进行batch次, 然后返回模型一个batch的数据
二 模型构造
重新把断点打在66行
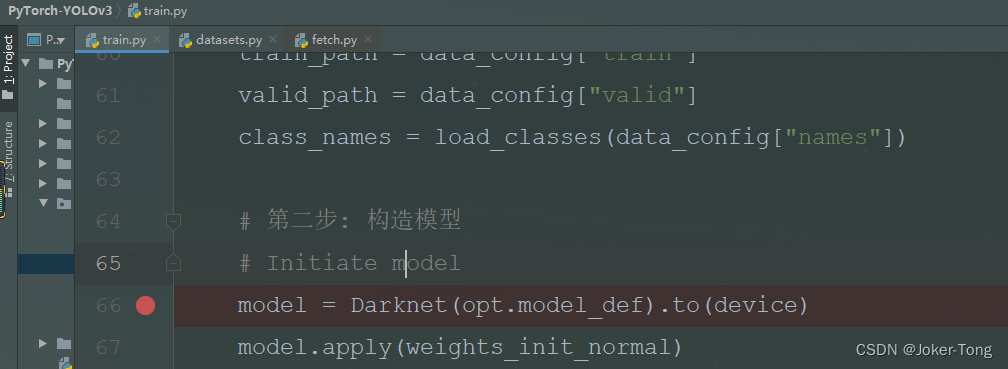
进入models.py, init函数中根据之前的yolov3.cfg文件对网络整体架构进行定义, forward函数规定了网络前向传播的整个过程
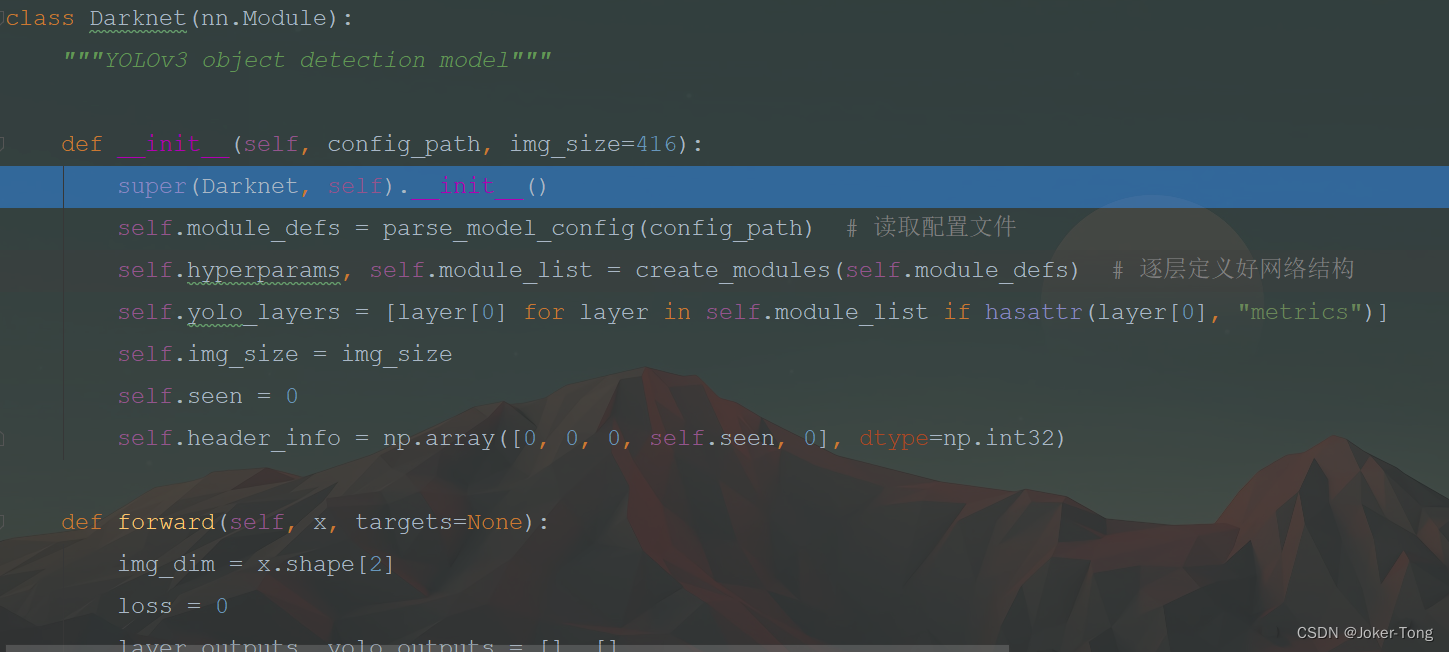
加载配置文件的信息到self.module_defs变量中

self.hyperparams, self.module_list = create_modules(self.module_defs) # 逐层定义好网络结构
调用create_modules来进行模型的构建
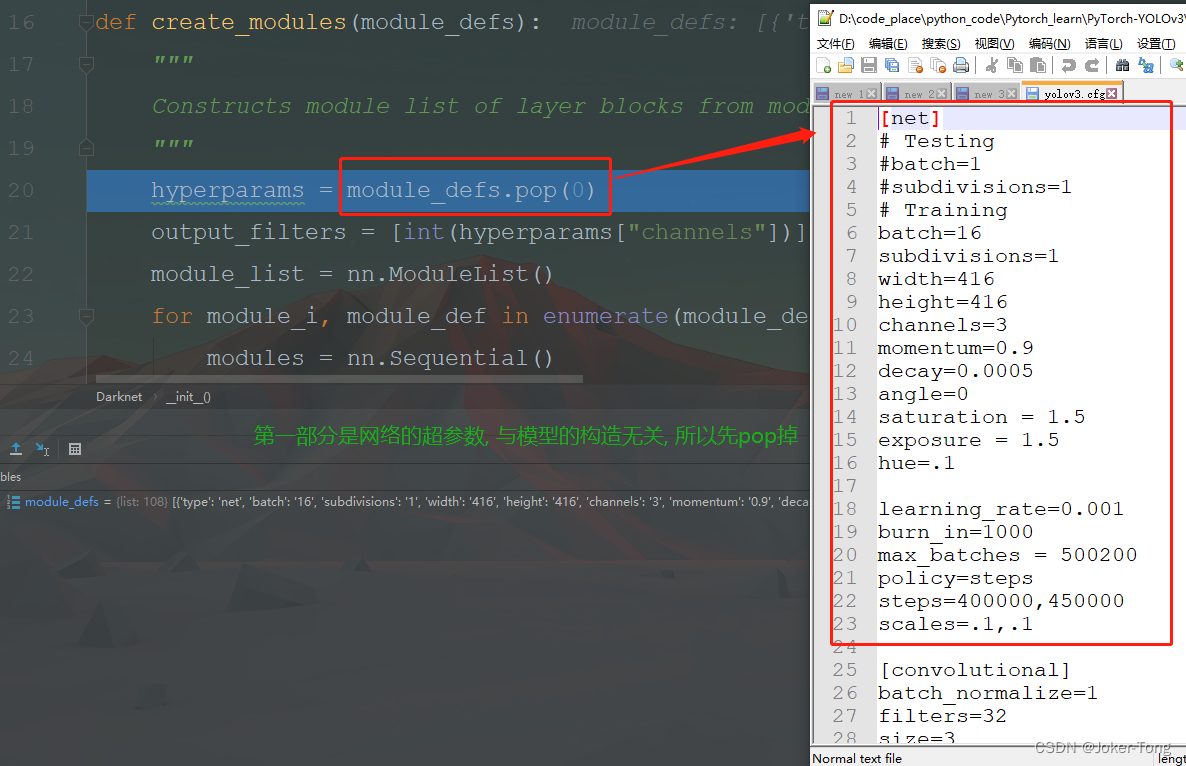
循环增加网络层
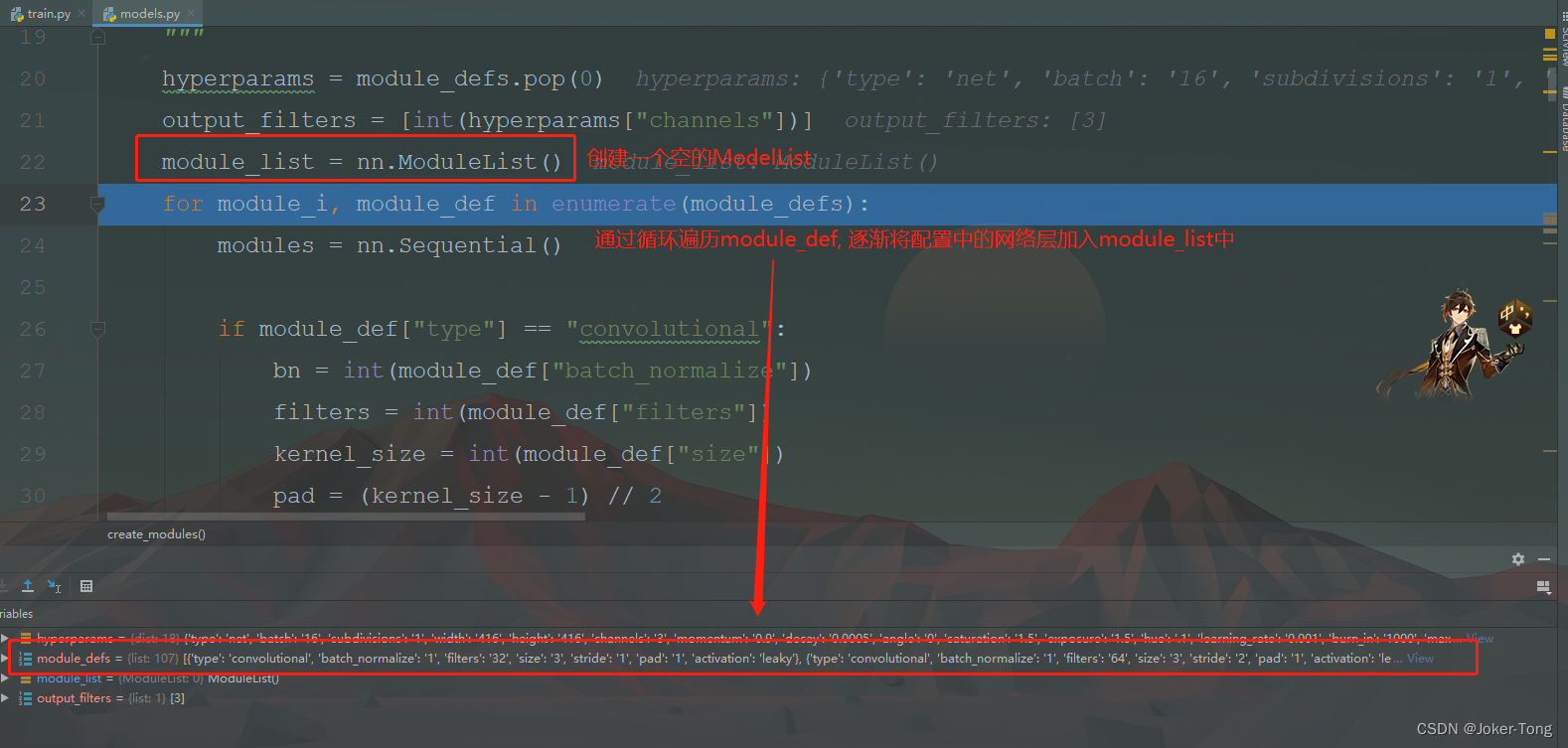
convolutional层的构建
注意这里的convolutional其实可能包括了卷积, BN, 以及Relu三种操作, 先将里面的参数信息读取出来
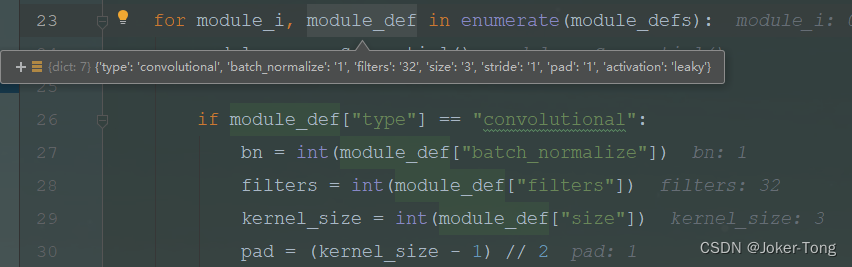
**根据参数信息 添加Conv2d 也就是卷积层 **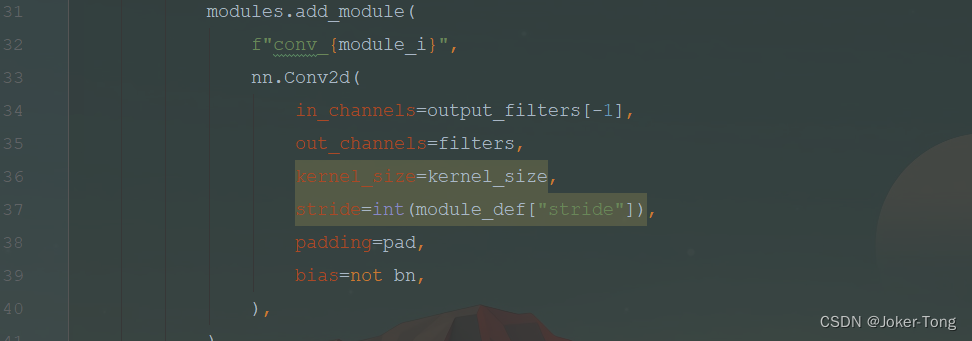
如果有bn层以及激活函数, 将它们加入到网络结构当中

这里在控制台打印一下当前构造的modules, 其中包含了我们想要的三种层
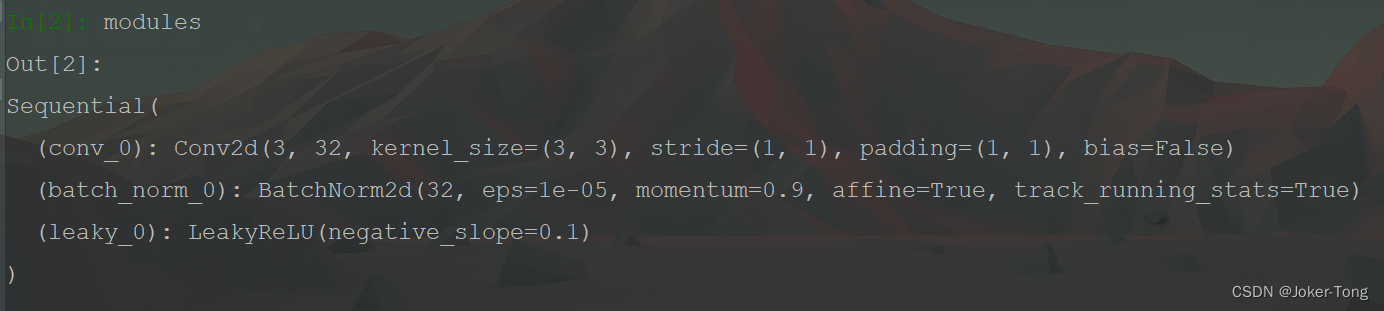
也就是将之前构造完成的第一个模块加入到大的module_list当中, 并且记录下filters的输出个数

rout层与shortcut层的构建
这里只是创建了个空的层, 具体的操作执行在前向传播中
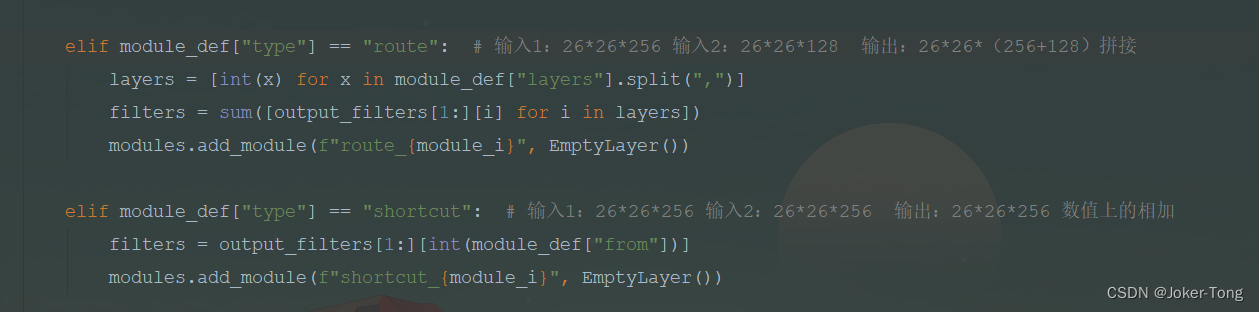
rout层主要起到拼接的作用, 起到了特征融合的作用
shortcut层主要是加法的作用(resnet的思想), 残差连接的功能已经很熟悉了, 这里就不介绍了
配置文件中的-3表示跟

yolo层的构建
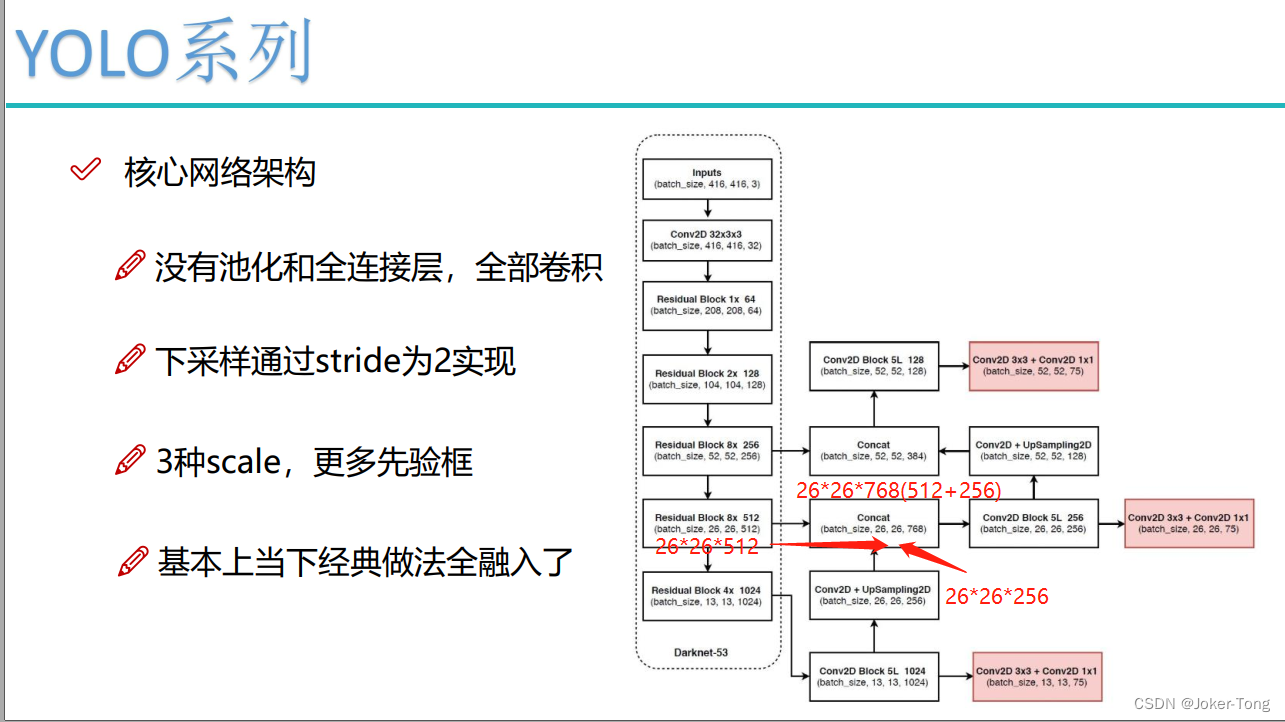
YOLOV3中有三种YOLO层, 它们分别可以检测大中小三种物体
YOLOV3中有三种scale的先验框, 对应着这三种YOLO层, 感受野比较大的YOLO层对应使用大的先验框
这里通过anchor的编号获取实际先验框的大小
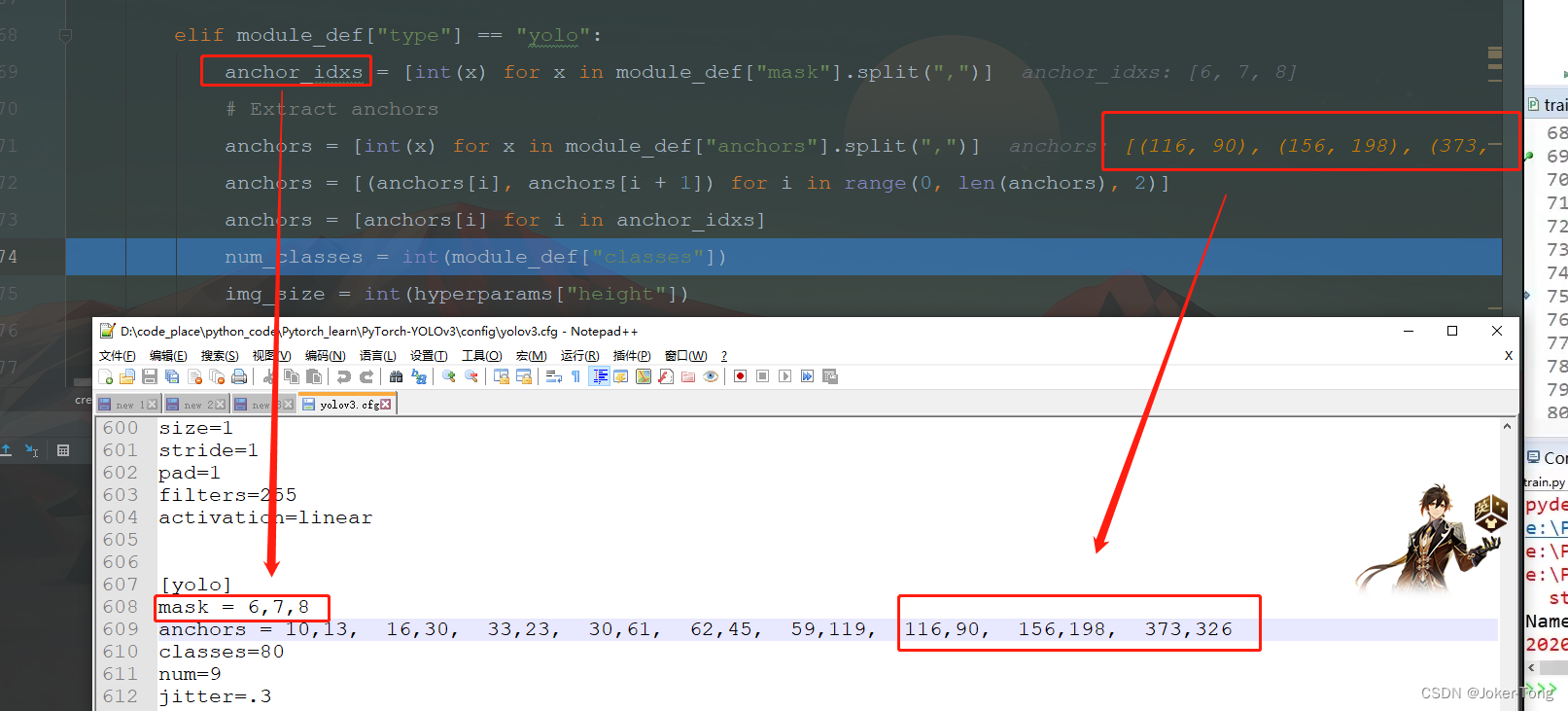
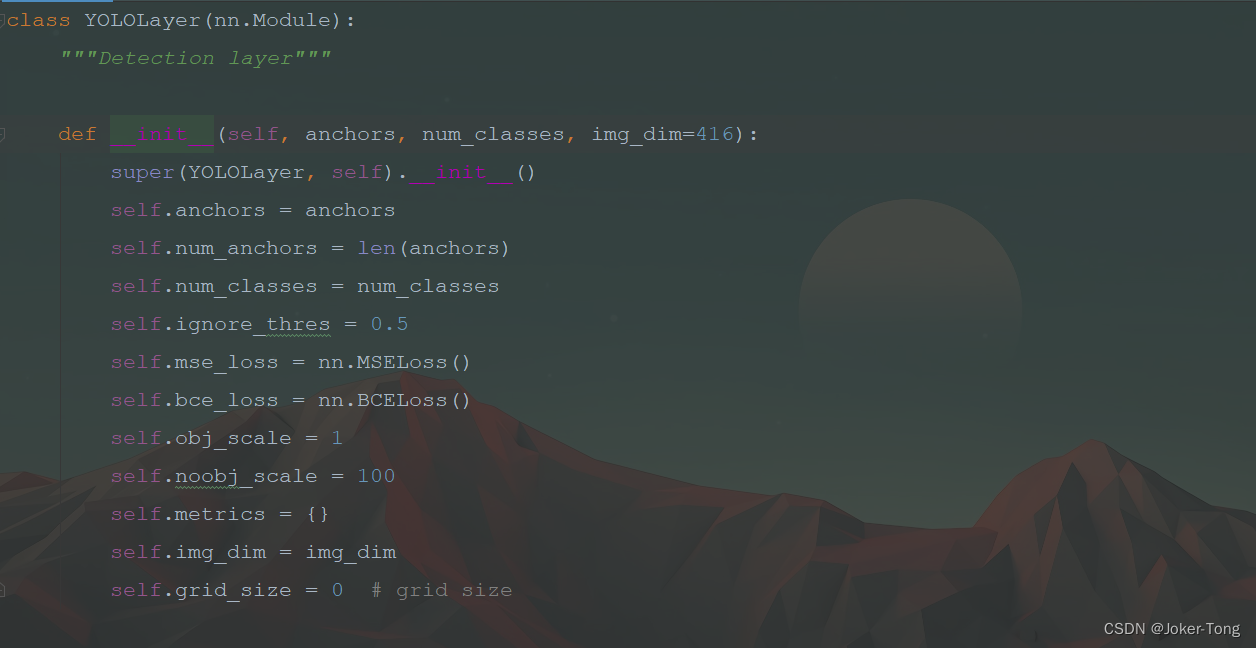
调用YOLOLayer来构建出YOLO层, 具体的前向传播在后面介绍
三 前向传播
在各个模型的forward处打上断点
首先进入的是Darknet的forward
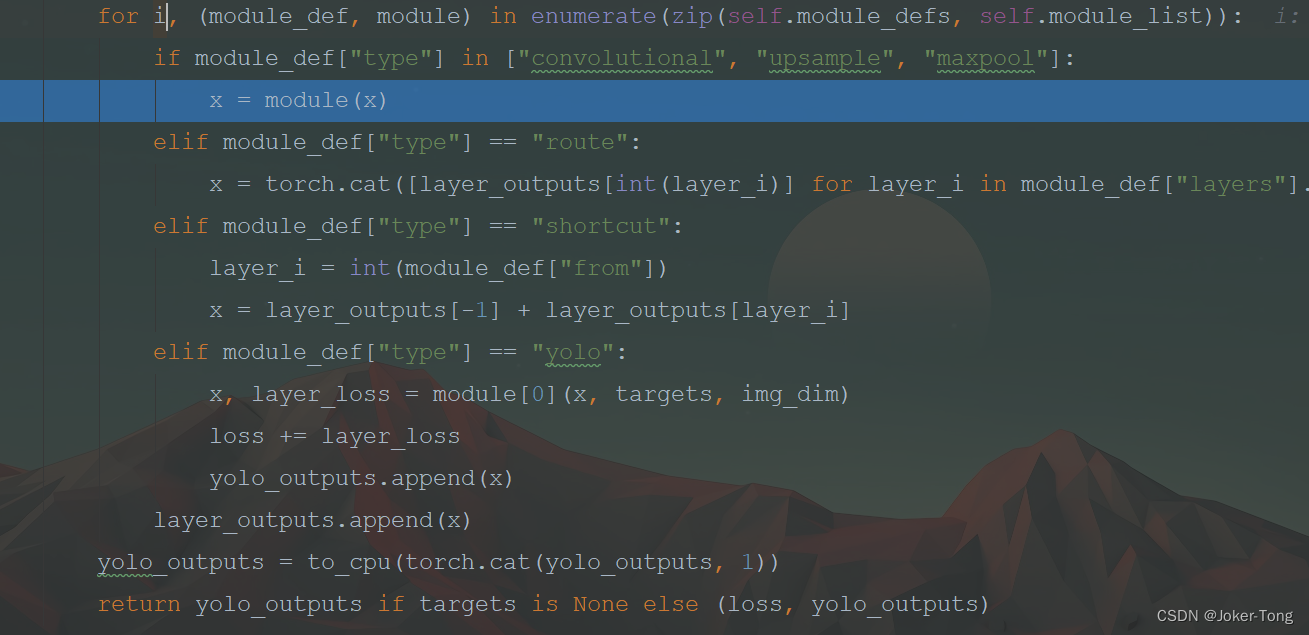
这里的卷积, 上采样, 和最大池化层的前向传播都非常简单, 根据pytorch内置的函数, 直接x = module(x)就可以了
if module_def["type"] in ["convolutional", "upsample", "maxpool"]:
x = module(x)
elif module_def["type"] == "route":
x = torch.cat([layer_outputs[int(layer_i)] for layer_i in module_def["layers"].split(",")], 1)
elif module_def["type"] == "shortcut":
layer_i = int(module_def["from"])
x = layer_outputs[-1] + layer_outputs[layer_i]
route层的效果是按某个维度做拼接shortcut层的效果是对两层做加法
最重要的是YOLO层
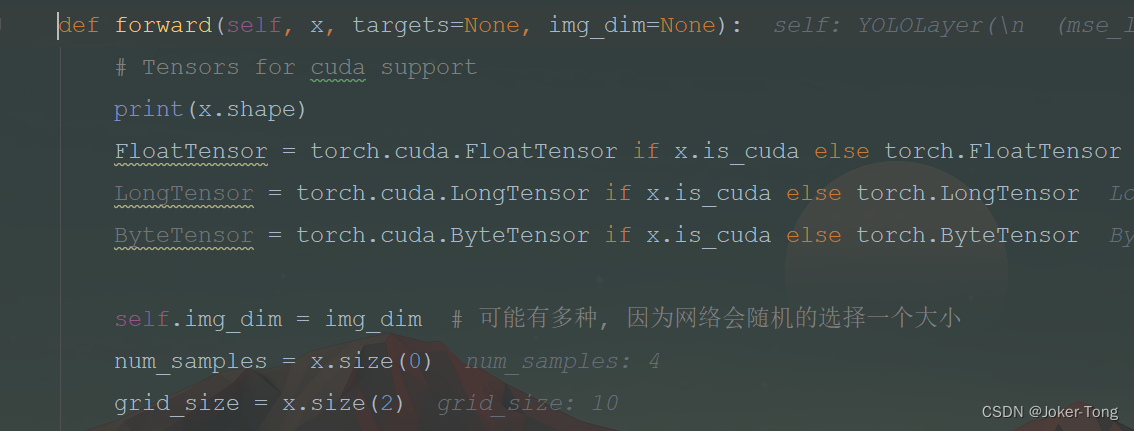
这里的img_dim可能有多种大小 但都能被32整除, 因为YOLOV3网络会随机的选择一个大小的图片进行训练
对于预测的维度进行调整, 4 * 3 * 15 * 15 * 85
4表示batch_size3表示 先验框的有三种15 * 15为特征图的大小85 = 80 + 5表示80个类别 与x,y,w,h与 置信度
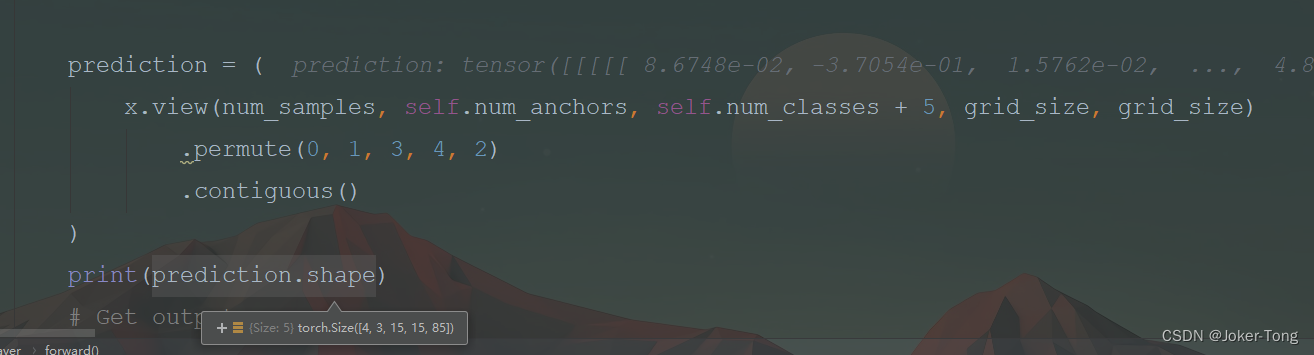
取出其中的x,y,w,h,c与每个类别的预测值

通过相对位置得到对应的绝对位置
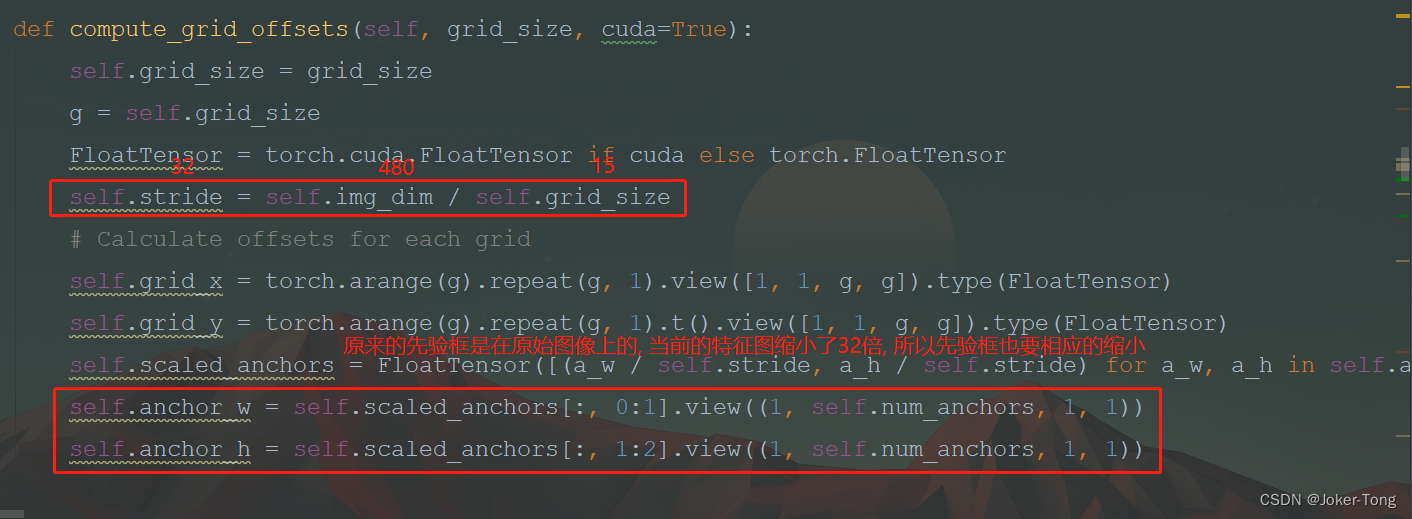
得到特征图(如当前为15*15)中各个坐标的实际位置
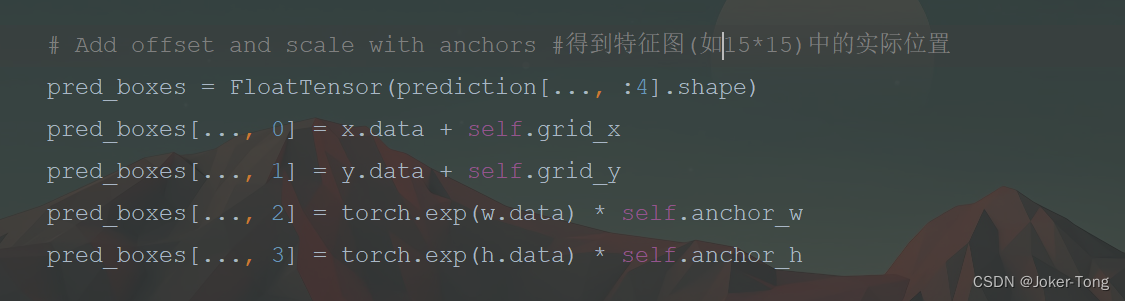
因为标签中的框是在原始图像中的, 所以output要把预测框也放大相应的倍数还原到原始图像中
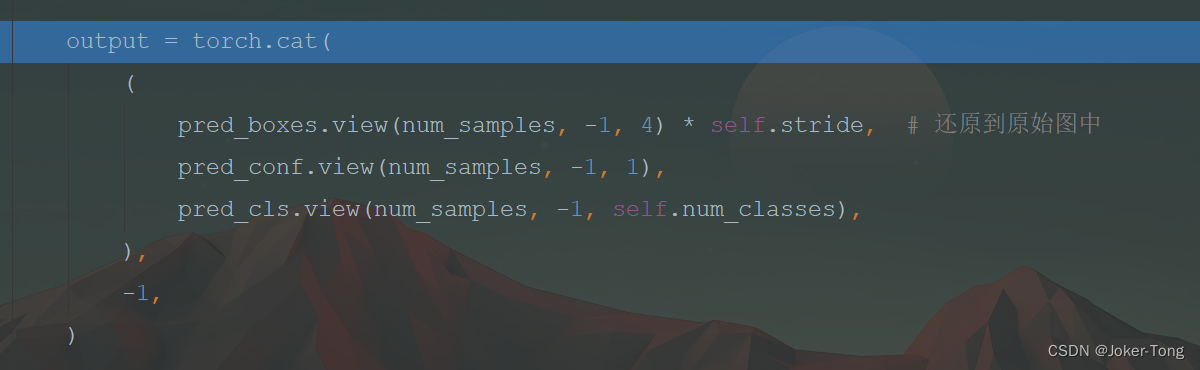
四 计算损失
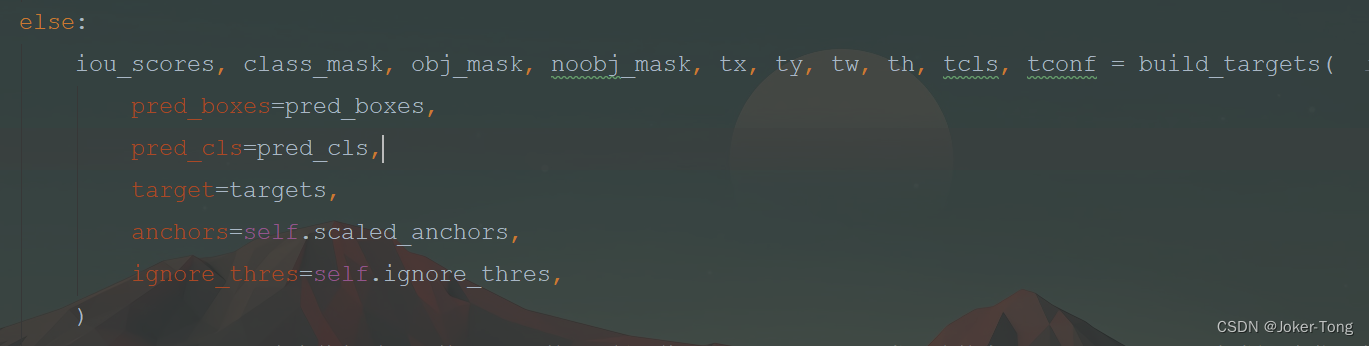
通过build_targets函数将标签值进行转换, 转换成和预测值相同的格式, 这里可以点进去自己看一下build_targets的内容
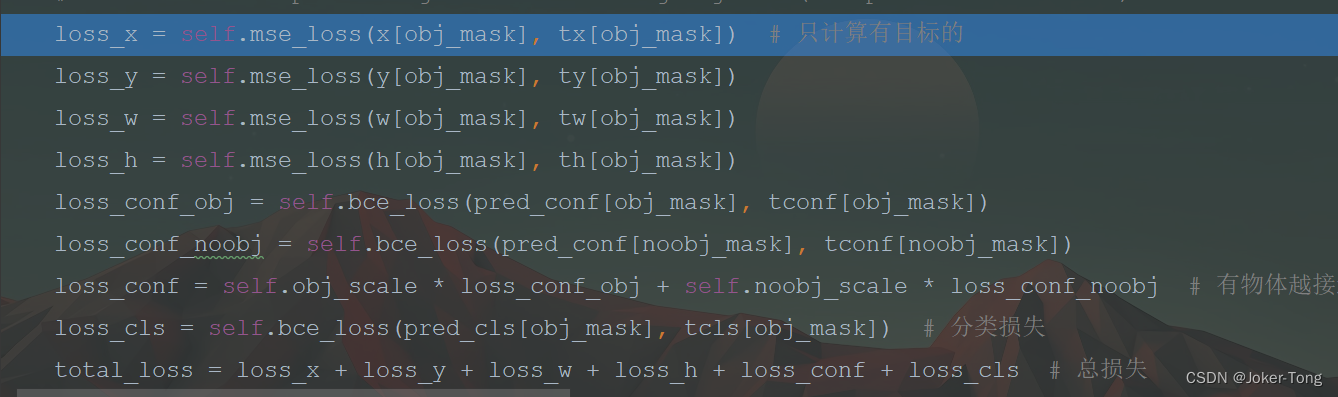
计算loss
- 对于
x,y,w,h来说, 并不是所有的位置都要算一遍, 我们只计算有物体的位置处的损失, 所以这里用了obj_mask作为index loss_conf_obj,loss_conf_noobj计算的是前景和背景的损失, 也就是当前位置是不是物体. 因为这里的预测值和真实值只有0和1, 所以使用bce_loss即可计算
他们两个相加, 乘上相应的权重参数就得到了置信度损失loss_conf_noobjloss_cls分类损失的原理也类似
最终将所有的损失相加就得到了总损失
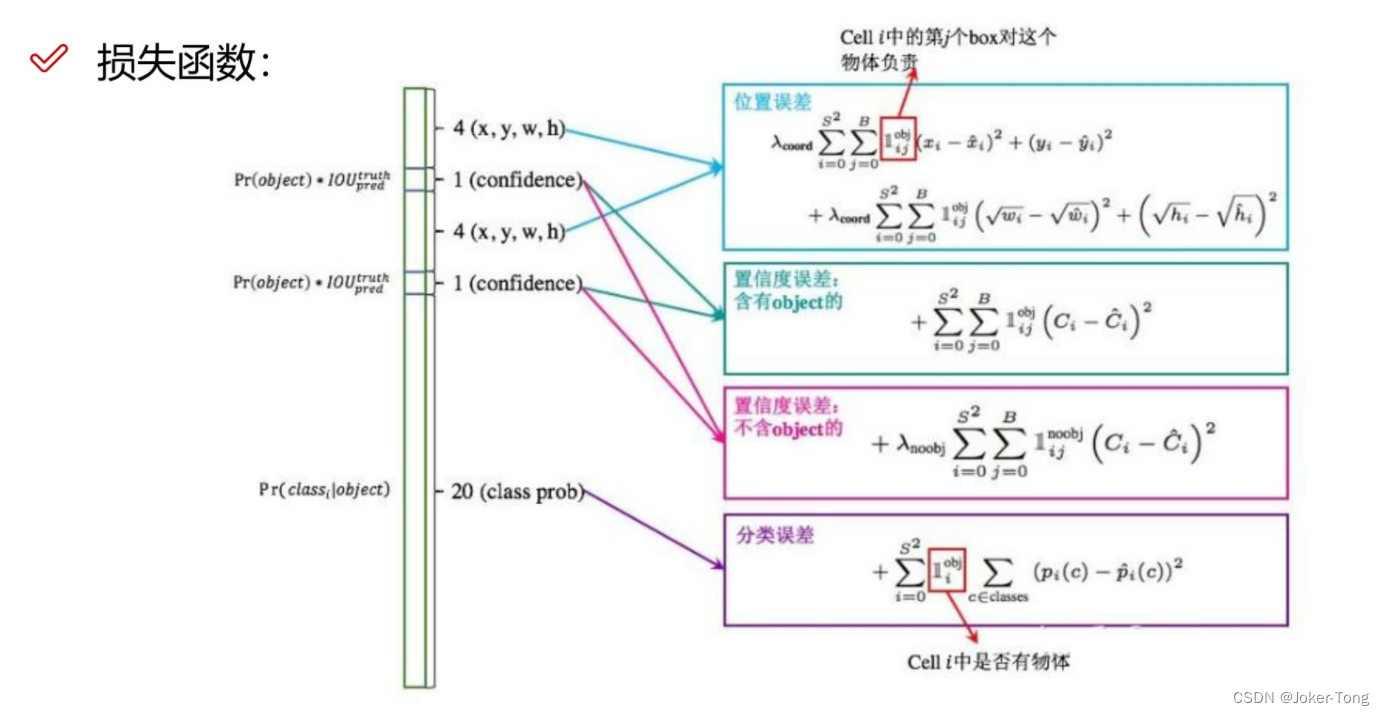
这里附上一张损失函数的计算图像, 可以看出和代码中的一样, 很好理解
后面的操作基本上是通用的pytorch训练模式



![[Paper Reading] Towards Conversational Recommendation over Multi-Type Dialogs](https://cdn.jsdelivr.net/gh/xin007-kong/picture_new/img/20230122163613.png)