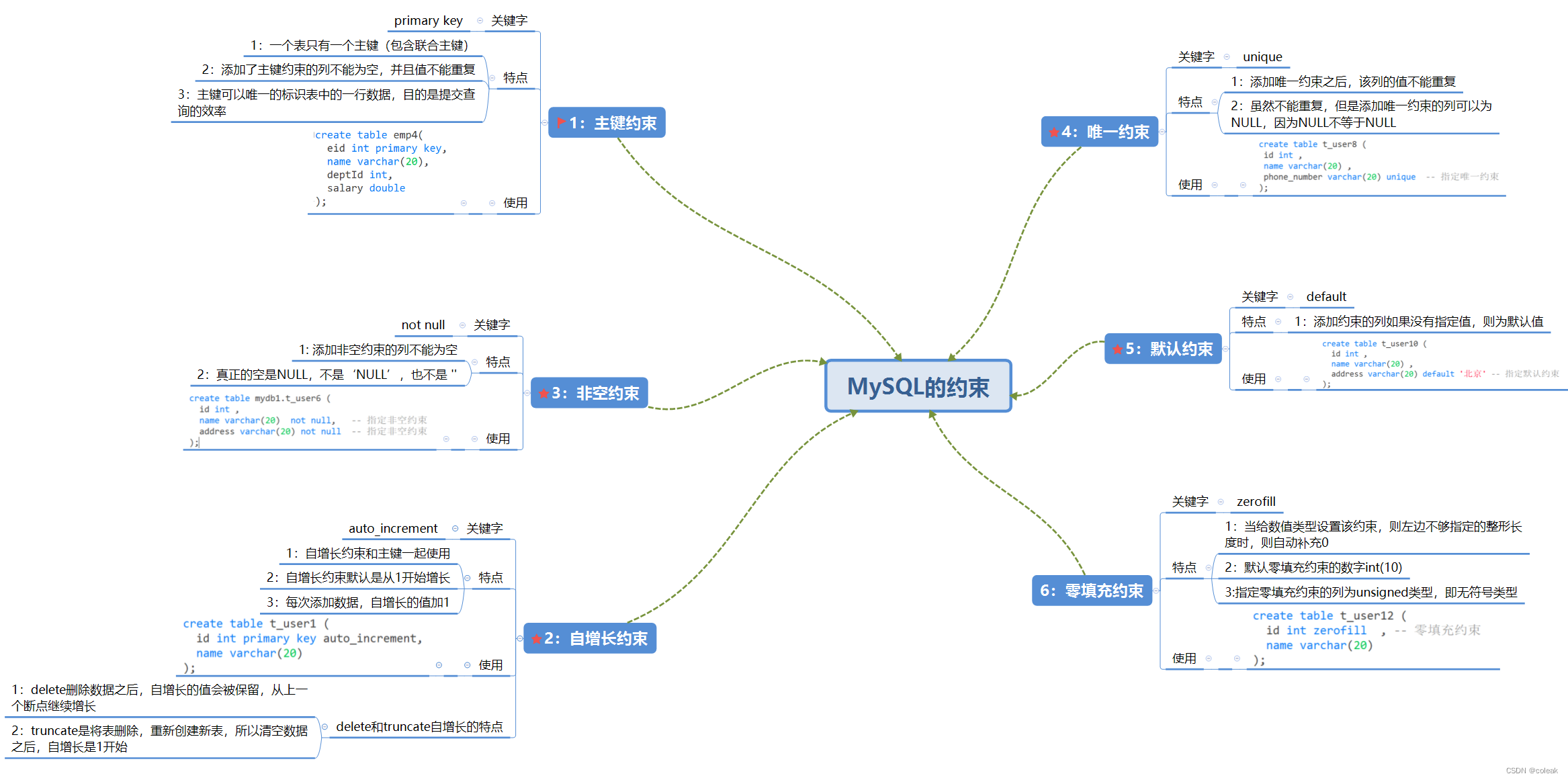
文章目录
- 1.开始:构造函数
- 1.2 在栈区和堆区创建对象
- 1.3 缺省构造函数
- 1.4 类型转换构造函数
- 1.5 拷贝构造函数
- 1.6 缺省拷贝构造函数(浅拷贝)
- 1.7 深拷贝构造函数 (深拷贝)
- 1.8 拷贝赋值
1.开始:构造函数
语法形式
class 类名{
类名(形参表){...}//构造函数
};
特点和作用
- 与类名相同,没有返回值类型
- 对象创建时自动被调用,不能像普通成员函数一样显示调用
- 主要负责初始化成员变量
- 即根据这个类创建一个对象,那怎样是创建一个对象嘞?
- 给这个给这个对象分配个地址
- 给这个对象的每个成员变量都赋初值
- 即根据这个类创建一个对象,那怎样是创建一个对象嘞?
1.2 在栈区和堆区创建对象
在哪里创建对象
通常,根据使用场景的不同,我们可以再栈区和堆区两个地方创建对象
在这两个地方创建对象有什么不同呢?
栈区(stack)
- 堆区变量由编译器自动分配释放内存,一般存放函数的参数值、局部变量等
- 变量名、函数名、指针名等都在栈区
堆区(heap)
- 一般由程序员分配释放,若程序不是放,程序结束时可能由操作系统回收,也可能导致内存泄漏,一般必须手动释放
- 注意:与数据结构中的堆是两回事,分配方式类似链表
代码举例
class A{
public:
//这里定义了一个有参构造函数,参数为i并给其赋了缺省值为1
//也就是说,如果给这个构造函数传入控制,则i的值为1
//在构造函数中,我们把i的值传给了成员变量m_i
A(int i = 0){
m_i = i;
}
private:
int m_i;
}
int main(void){
//在栈区创建对象
A a1;//调用无参构造
//下面两种写法效果都可以认为是一样的
A a1(1);
A a1 = A(1)
//在栈区创建A列列表
A arr1[3];
A arr2[3] = {A(1), A(2), A(3)};
//在堆区创建对象
A* a2 = new A;//构造函数不传参
A* a3 = new A(2);//构造函数传参
//在栈区释放内存
delete a2;
delete a3;
//在堆区创建A列列表
A* arr3 = new A[3];
A* arr4 = new A[3]{A(1), A(2), A(3)};
//在堆区释放内存
delete[] arr3;
delete[] arr4;//注意:释放堆区的数组时,要加上[]
}
1.3 缺省构造函数
如果写一个类的时候,没有定义任何构造函数,为了保证类对象能正常创建出来,
编译器会为其提供一个缺省构造函数。
- 对于基本类型成员变量,不做初始化
- 对于类类型的成员变量(成员子对象),将自动调用相应的类缺省构造函数来初始化。
如果,一个类自己定义了构造函数,那么无论是否有参数,编译器都不会再提供缺省构造函数。所以,后面也是没办法调用缺省构造函数的。
class A{
public:
A(){cout << "无参构造" << endl;m_i = 0;}
int m_i;
};
class B{
public:
int m_j;
int* m_p;
A m_a;
};
void defCons_test(){
B b;
cout << b.m_j << endl;//未知,自己的基本成员变量会被初始化成什么是不确定的。
cout << b.m_a.m_i << endl;//类类型会调用自己的默认构造函数进行初始化
1.4 类型转换构造函数
一般情况下,当构造函数只有一个参数的时候,都可以看成类型转换构造函数。
这种函数,可以将传入参数的类型转换成目标类类型。
隐式转换
若采用隐式转换形式,编译器会自己去类中寻找能匹配上的构造函数进行调用。以完成类型转换。但是隐式转换代码可读性很不好,一般不建议使用。
显示转换
更推荐使用显示转换,c++风格显示转换的格式和调用类型转换构造函数的格式相同。
同时,在定义类型转换构造函数的时候,前面可以用explicit关键字修饰。表示,这个类型转换只能使用显示类型转换,不能使用隐式类型转换。那么,使用隐式类型转换就会报错。
class Integer{
public:
Integer(){cout << "Integer()" << endl; m_i = 0;}
//类型转换构造函数
//加上explicit表示,类型转换只能显示转换,不能隐式转换
explicit Integer(int i){
cout << "Integer(int)" << endl;
m_i = i+15;
}
void print(void){
cout << m_i << endl;
}
private:
int m_i;
};
void castCons_test(){
Integer i;
i.print();
//explicit Integer(int)
//前面有explicit,所有,不能进行隐式的类型转换,顾报错
//i = 100;//编译器进行了隐式转换
//编译器会在构造函数中找,最匹配的那个构造函数,调用
//显示转换(更推荐)
i = (Integer)200;//c风格显示转换
i = Integer(300);//c++风格显示转换,和构造函数调用写法一样
i.print();
}
1.5 拷贝构造函数
用一个已经定义的对象构造同类型的副本对象,将调用该类的拷贝构造函数。
//const修饰,避免传入的对象被修改
类名(const 类型& that){
//克隆源对象that的副本对象
}
类型 对象1;
类名 对象2(对象1);//拷贝构造
类名 对象2 = 对象1;//和上面一样
class A{
public:
A(int data = 0):m_data(data){cout << "A(int)" << endl;}
A(const A& that){
//注意,拷贝构造函数形参,必须加引用,必须加const
/*1.为什么必须加引用?
*如果没有引用,相当于不是穿这个对象的地址,而是传这个对象的副本。
*既然出现了副本,那是不是要对这个对象拷贝一个副本出来。
*既然要拷贝一个副本出来,那又要使用拷贝构造了。
*既然使用拷贝构造,又要传一个对象副本了
*...
*死循环了,所以,编译不会通过。
*2.为什么必须加const?
*如果不加const,那就形参只是一个普通引用。
*普通引用只能引用左值。
*如果传入右值,则会直接报错。
*所以,必须加const,将形参变为右值引用(万能引用)
*/
cout << "A(const A&)" << endl;
m_data = that.m_data;
}
int m_data;
};
void coyCons_test(){
A a1(100);
//A a2(a1);
A a2 = a1;//和上一行意思一样
cout << a1.m_data << endl;
cout << a2.m_data << endl;
}
1.6 缺省拷贝构造函数(浅拷贝)
如果我们在类中没有定义拷贝构造函数,但是后面使用了拷贝构造。
那么编译器会给我们提供一个缺省的拷贝构造函数。
缺省的拷贝构造函数是浅拷贝的。
- 对基本类型成员变量,按字节复制
- 对类类型成员变量,调用类成员自己的拷贝构造函数
class A{
public:
A(int data = 0):m_data(data){cout << "A(int)" << endl;}
A(const A& that){
cout << "A(const &A)" << endl;
m_data = that.m_data;
}
int m_data;
};
class B{
public:
A m_a;//成员子对象
};
void cpCons_test(){
/*编译器处理逻辑:
*如果,是用无参构造创建对象,
*那么,对象中的类成员变量也是用自己的无参构造进行创建。
*如果,使用拷贝构造创建对象,
*呢么,对象中的类成员变量也是用自己的拷贝构造进行创建。
*/
B b1;//调用B缺省无参构造函数
cout << b1.m_a.m_data << endl;//0
B b2(b1);//拷贝构造
cout << b2.m_a.m_data << endl;//0
}
拷贝构造函数调用时机(笔试会考)
- 用已定义的对象作为同类型对象的构造实参
- 以对象的形式向函数传递参数
- 丛函数中返回对象(有时候会因为编译优化而被省略)
拷贝构造过程风险高效率低,设计时应该尽可能避免
- 避免或减少对象的拷贝
- 传递对象形式参数时候,使用引用型参数
- 丛函数中返回对象时候,使用引用函数返回值
一个笔试题例子:
class A{
public:
A(){
cout << "A的无参构造" << endl;
}
A(const A& that){
cout << "A的拷贝构造函数" << endl;
}
};
void func(A a){}
A bar(){
A a;
cout << "&a=" << &a << endl;
return a;
}
void bishi_cpConst_test(){
//问:代码执行期间会调用多少次构造函数?6次
A a1;//1,无参构造
A a2 = a1;//2,拷贝构造
func(a1);//3,func的形参不是引用,所以,传入的是对象的副本,所以,调用一次拷贝构造
A s3 = bar();//编译器优化,会优化两次
//6,返回值是A,不是引用,所以,返回副本,调用一次拷贝构造
//bar函数内部还创建了一个A的对象,调用一次无参构造
//最后,这个语句本身是拷贝构造,将bar()返回的对象拷贝构造给了s3
cout << "&s3=" << &s3 <<endl;
//全局变量s3就是局部变量a的引用,两个指向同一块地址,这是编译器优化的结果。
}
1.7 深拷贝构造函数 (深拷贝)
先说什么是浅拷贝
类中缺省的拷贝构造函数,对指针形式的成员变量按照字节复制,不会复制指针所指向的内容,这种拷贝方式被称为浅拷贝。
看下面的例子,第一个对象实例,i1。
他的成员变量m_pi是个指向int的指针。
我们让这个指针指向地址为1001的int,这个int里面存的是100。第二个对象i2,它由i1浅拷贝构造而来,
i2也有个成员变量m_pi也是个指针。由于是浅拷贝构造,i2的成员变量m_pi会复制值i1中m_pi的内容(图中step1)。
那i1中存的是什么呢?是100的地址1001。(这个地址是我编的,为了好理解)
也就是说,i1中的m_pi和i2中的m_pi都指向了同一个地址的100。
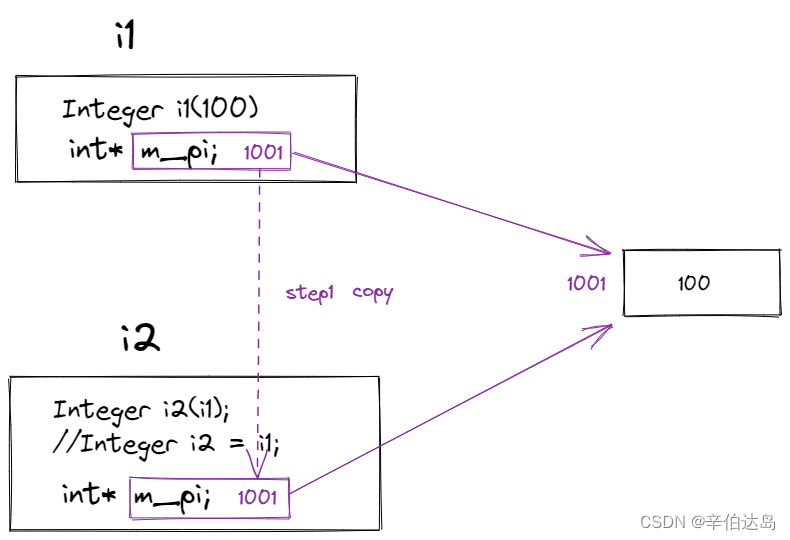
会出现这么两种情况
- 我通过i1的m_pi和i2的m_pi都可以改变存在1001地址上的100
- 1001这个内存会被释放两次,释放i1时一次,释放i2时一次
- 也就是我们常说的
double free
- 也就是我们常说的
深拷贝
为了避免浅拷贝的问题,必须自己定义拷贝构造函数,针对指针形式的成员变量,实现对指针指向内容的赋值,即深拷贝。
也就是说,如果,你定义的类中成员变量有指针,那就必须使用深拷贝,浅拷贝是哒咩的。
那深拷贝要完成什么功能呢?
就行下面图中所展示的。
i1对象有个成员变量m_pi是个指针。
指向的地址为1001,这个地址上存的数字是100。
然后,我要通过i1拷贝构造一个i2,但是是深拷贝。
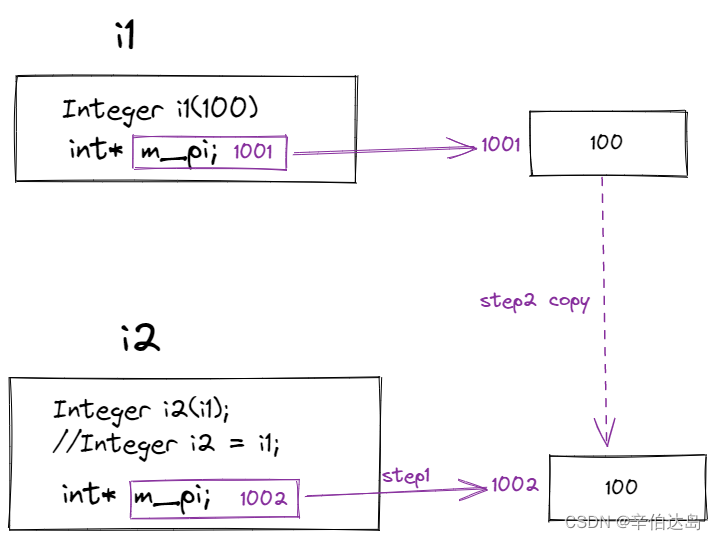
深拷贝这样操作:
- 分配一块新内存,地址为1002,让i2的m_pi指向这块内存
- 把i1的m_pi指向的1001上存的100复制到i2中m_pi所指的内存上
好处:
- i1中m_pi和i2中m_pi指向了不同的地址,这样不会相互干扰,也不会
double free - i1中m_pi所指向的地址存的值复制到了i2的m_pi所指的地址上,完美。
![[深拷贝.png]]
class Integer{
public:
Integer(int i = 0){
m_pi = new int(i);//类里面在堆区分配了内存,但是用户如果不知道,就忘记销毁了
}
~Integer(void){
cout << "析构函数" << m_pi << endl;
delete m_pi;
}
/*
Integer(const Integer& that){
cout<< "缺省浅拷贝构造" << endl;
m_pi = that.m_pi;
}*/
//自定义深拷贝
Integer(const Integer& that){
cout <<"自定义深拷贝构造"<< endl;
m_pi = new int;//先给新的对象的成员变量分配一块内存(分配新的地址)
*m_pi = *that.m_pi;//再进行复制运算
}
void print(void)const{
cout << *m_pi << endl;
}
void Set(){
*(this->m_pi) =199;
}
private:
int* m_pi;
};
void constructor_test(){
Integer i1(100);
Integer i2(i1);
i1.print();
i2.print();
i2.Set();
i1.print();
i2.print();
}
1.8 拷贝赋值
为什么要说拷贝赋值呢?
因为拷贝赋值和拷贝构造一样,也有深赋值和浅赋值,原理也是一样的,所以一起分析。
浅赋值问题
- 不同之间数据共享
double free- 内存泄漏
- 比如,先初始化一个对象,给这个对象成员分配了内存地址,即有个指针指向他
- 然后,让这个对象的的成员指针指向另一个成员变量
- 那原来那个变量就没有指针指向了,我们也没有进行free操作
所以这时候,我们要自己定义深拷贝赋值函数
#include <iostream>
using namespace std;
int main(void){
int i1 = 100;
int i2 = 0;
i2 = i1;//赋值运算符,如果看成是一个函数,那这个函数的返回值就是等号左边的
//返回结果是个左值(左值是非const的,和右值const区分)
(i2 = i1) = 300;//这样写是没有问题的
//相当于先给i2赋值成100,再对i2赋值300
i2 = 100;
cout << i1 << "," << i2 << endl;
}
自定义深拷贝赋值操作符函数
A& operator=(const A& that){
if(this != &that)//防止自赋值
{
//释放旧资源,因为我们要赋值的可能和旧内存大小不一样
//分配新资源
//拷贝新数据
}
return *this;
}
class Integer{
public:
Integer(int i = 0){
m_pi = new int(i);//类里面在堆区分配了内存,但是用户如果不知道,就忘记销毁了
}
~Integer(void){
cout << "析构函数" << m_pi << endl;
delete m_pi;
}
/*
Integer(const Integer& that){
cout<< "缺省浅拷贝构造" << endl;
m_pi = that.m_pi;
}*/
//自定义深拷贝构造
Integer(const Integer& that){
cout <<"自定义深拷贝构造"<< endl;
m_pi = new int;//先给新的对象的成员变量分配一块内存(分配新的地址)
*m_pi = *that.m_pi;//再进行复制运算
}
//i3 = i2 -> i3.operator=(i2)
//形参用const修饰,表示可以传入左值,也可以传入右值,也就是可以直接传个int
//形参是引用,为了提升效率
//返回值是个引用表示返回这个对象本身,而不是副本
/*Integer& operator=(const Integer& that){
cout << "缺省拷贝赋值函数" << endl;//也是浅拷贝
m_pi = that.m_pi;
return *this;//返回调用这个函数的对象自身
}*/
//深拷贝赋值函数
Integer& operator=(const Integer& that){
cout << "自定义拷贝赋值函数" << endl;
if(this != &that ){
delete m_pi;//释放旧内存
m_pi = new int;//分配新内存
*m_pi = *that.m_pi;//赋值
}
return *this;//返回自引用
}
void print(void)const{
cout << *m_pi << endl;
}
void Set(){
*(this->m_pi) =199;
}
private:
int* m_pi;
};
void constructor_test(){
Integer i1(100);
Integer i2(i1);
Integer i3;
i3.print();
//对于两个自定义的类,编译器不知道怎们对其进行赋值=操作
//编译器会为其提供一个函数:operator=
//这个函数如果咱没自己定义,编译器会为咱们提供的缺省函数
//下面代码相当于i3.operator=(i2)
//其中i3是函数的调用者,i2是传入函数的参数(左调右参)
i3 = i2;//i3=100,拷贝赋值(浅)
//i3.operator=(i2);//这一行和上面意思相同
i1.print();
i2.print();
i2.Set();//将i2=199
i1.print();
i2.print();
i3.print();//按理说应该是100,但是是199,改变i2就会改变i3
}


![[附源码]java毕业设计全国人口普查管理系统论文](https://img-blog.csdnimg.cn/8f9fa5ecde164b7d9af2fd0eeb7b801b.png)

![[附源码]java毕业设计汽车租赁系统](https://img-blog.csdnimg.cn/39f586b0e2f545dd881690c6cdbb847c.png)




![[附源码]计算机毕业设计JAVA化妆品销售管理系统](https://img-blog.csdnimg.cn/d3aca09f22f744038386d988e6b03844.png)