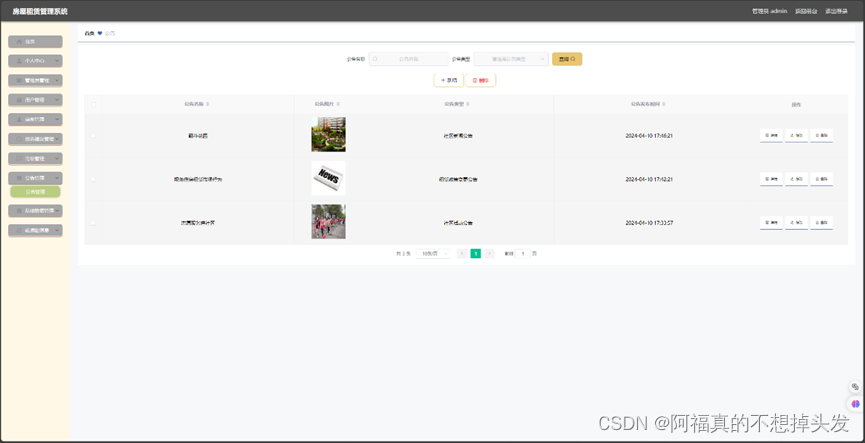
整体功能:
1 创建框架构建相关的文件夹
2 创建app,模块文件
3 在 app模块文件中创建application函数(用于处理请求)
4 将request_handler()中的处理逻辑交由app模块的application函数完成5 app模块的 application函数返回响应报文
6 在application 文件夹中创建一个utils 模块
7 utils 模块中创建 create_http_response() 函数,专门用来拼接响应报文
8 修改 app模块的application的返回响应协议的部分
逻辑关系:

文件架构:
main.py
# TCP服务端
import socket
from application import app
class WebServer(object):
def __init__(self):
# 1,导入模块
# 2·创建套接字
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 3·设置地址重用
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# 4、绑定端口
address = ("", 10000)
tcp_server_socket.bind(address)
# 5﹑设置监听·让套接字由主动变为被动接收
tcp_server_socket.listen(128)
self.tcp_server_socket = tcp_server_socket
def start(self):
"""
启动Web服务器
"""
# 6﹑接受客户端连接 定义函数request——handler()
while True:
new_client_socket, ip_port = self.tcp_server_socket.accept()
print(f"新的连接请求:{ip_port}")
# 调用函数处理请求
self.request_handler(new_client_socket, ip_port)
def request_handler(self, new_client_socket, ip_port):
"""
接收数据并响应
:return:
"""
# 7.接收客户端浏览器发送的请求协议
request_data = new_client_socket.recv(1024)
# 8﹑判断协议是否为空
if not request_data:
print(f"{str(ip_port)}客户端已经下线!!!")
new_client_socket.close()
return
# 使用application文件夹下的app模块处理
response_data = app.application("static", request_data, ip_port)
new_client_socket.send(response_data)
new_client_socket.close()
return
def main():
# 创建对象
ws = WebServer()
ws.start()
if __name__ == '__main__':
main()
app.py
"""
解析客户端浏览器发送的消息,并将响应信息发回
"""
from application import utils
def parse_request(request_data, ip_port):
"""
解析请求报文,返回客户端请求的资源路径
:param request_data: 接受到的客户端请求信息
:param ip_port: 客户端IP地址
:return: 客户端请求的资源路径
"""
# 根据客户端请求的资源返回对应资源
# 1 解码得到请求字符串
request_text = request_data.decode()
loc = request_text.find("\r\n")
# 2 得到请求行
request_line = request_text[:loc]
# 3按空格拆分得到对应信息
request_line_list = request_line.split(" ")
file_path = request_line_list[1]
print(f"{str(ip_port)}正在请求{file_path}资源,服务器已成功响应!")
# 设置默认首页
if file_path == "/":
file_path = "/index.html"
return file_path
def application(current_dir, request_data, ip_port):
"""
解析客户端的请求信息,找到目标资源路径并返回资源
:param current_dir:服务器资源根目录
:param request_data: 客户端请求资源信息
:param ip_port: 客户端IP地址
:return: 客户端请求的内容
"""
file_path = parse_request(request_data, ip_port)
resource_path = current_dir + file_path
# 9.4响应主体
# response_body = "<html><h>HelloWorld!<h/><html/>"
# 通过读取文件内容返回客户端
try:
with open(resource_path, "rb") as file:
response_body = file.read()
response_data=utils.create_http_response("200 OK", response_body)
except Exception as e:
# 重新修改响应行404
response_body = f"Error! {str(e)}".encode()
response_data = utils.create_http_response("404 Not Found", response_body)
# 10、发送响应报文
return response_data
utils.py
def create_http_response(status, response_body):
# 9﹑拼接响应的报文
# 9.1响应行
response_line = f"HTTP/1.1 {status}\r\n"
# 9.2响应头
response_header = "Server:Python20ws/21.1\r\n"
# 9.3响应空行
response_blank = "\r\n"
response_data = (response_line + response_header + response_blank).encode() + response_body
return response_data



![[答疑]不开发系统只做领域建模,可以画冗余关联吗](https://img-blog.csdnimg.cn/img_convert/406bb0aac68b201da8bfca181f0aa2fb.png)



![[xx点评完结]——白马点评完整代码+rabbitmq实现异步下单+资料,免费](https://img-blog.csdnimg.cn/direct/08bc597190404202840d8b18d02b225a.png)