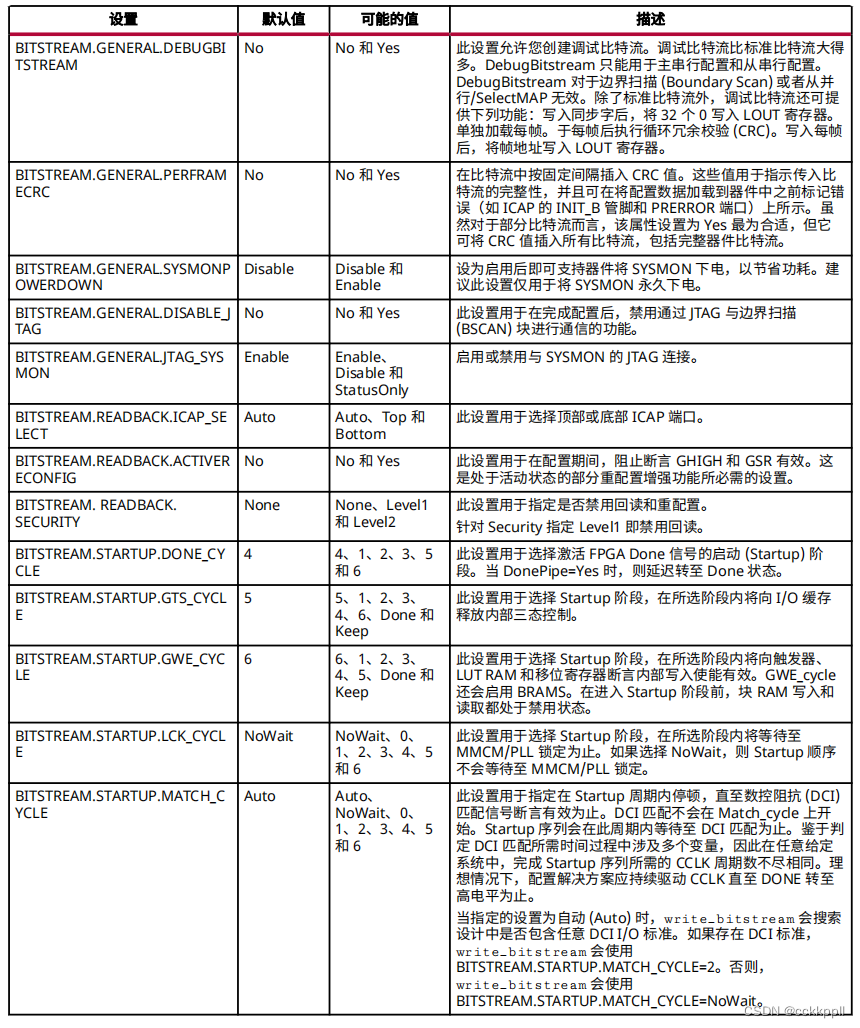
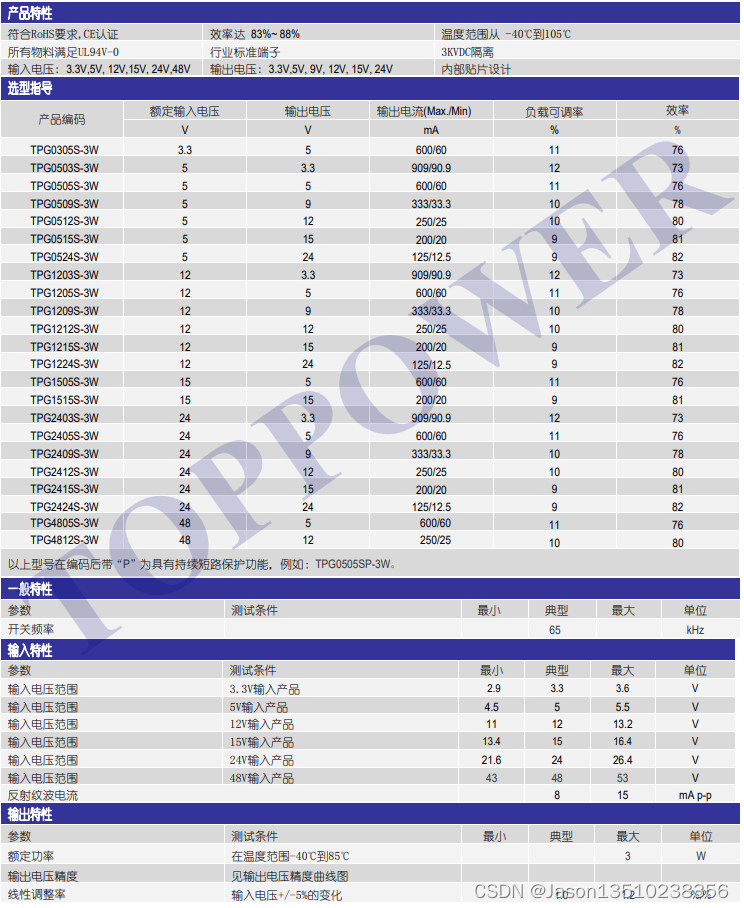
一、DDP实现流程
(1)初始化进程
(2)model并行
(3)BN并行
(4)data并行
(5)进程同步
二、DDP代码实现
(1)初始化进程
#-------------- 初始化进程,设置用到的显卡 -----------------#
ngpus_per_node = torch.cuda.device_count()
if distributed:
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
rank = int(os.environ["RANK"])
device = torch.device("cuda", local_rank)
if local_rank == 0:
print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) training...")
print("Gpu Device Count : ", ngpus_per_node)
else:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
local_rank = 0
rank = 0
概念说明:
RANK: 使用os.environ[“RANK”]获取进程的序号,一般1个GPU对应一个进程。它是一个全局的序号,从0开始,最大值为GPU数量-1。一般单机多卡的情况要比多机多卡的情况常见的多,单机多卡时,rank就等于local_rank。
LOCAL_RANK:使用os.environ[“LOCAL_RANK”]获取每个进程在所在主机中的序号。从0开始,最大值为当前进程所在主机的GPU的数量-1;
WORLD_SIZE:使用os.environ[“world_size”]获取当前启动的所有的进程的数量(所有机器进程的和),一般world_size = gpus_per_node * nnodes。
每个node包含16个GPU,且nproc_per_node=8,nnodes=3,机器的node_rank=5,请问world_size是多少? 答案:world_size = 3*8 = 24
看下图比较方便理解:
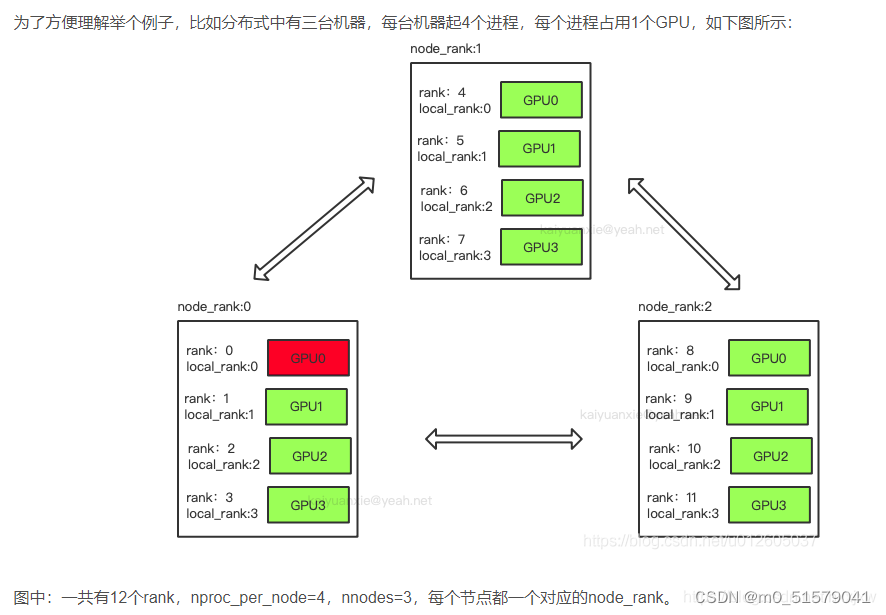
在分布式训练中,RANK,LOCAL_RANK,WORLD_SIZE这三个环境变量通常需要在所有进程中保持一致,并且需要在初始化分布式训练环境时设置。例如,在 PyTorch 中,可以使用 torch.distributed.init_process_group() 函数来初始化分布式训练环境,并自动设置RANK,LOCAL_RANK,WORLD_SIZE这三个环境变量。
(2)模型并行
# -------------- 模型并行 --------------#
if Cuda:
if distributed:
model_train = model_train.cuda(local_rank)
model_train = torch.nn.parallel.DistributedDataParallel(model_train, device_ids=[local_rank],find_unused_parameters=find_unused_parameters)
else:
model_train = torch.nn.DataParallel(model)
cudnn.benchmark = True
model_train = model_train.cuda()
nn.parallel.DistributedDataParallel函数接口中,find_unused_parameters: 如果模型的输出有不需要进行反向传播的,此参数需要设置为True;如果你的模型结构有有冗余的没有参加反向传播的参数,而find_unused_parameters设置为False,在训练过程中就会报错。
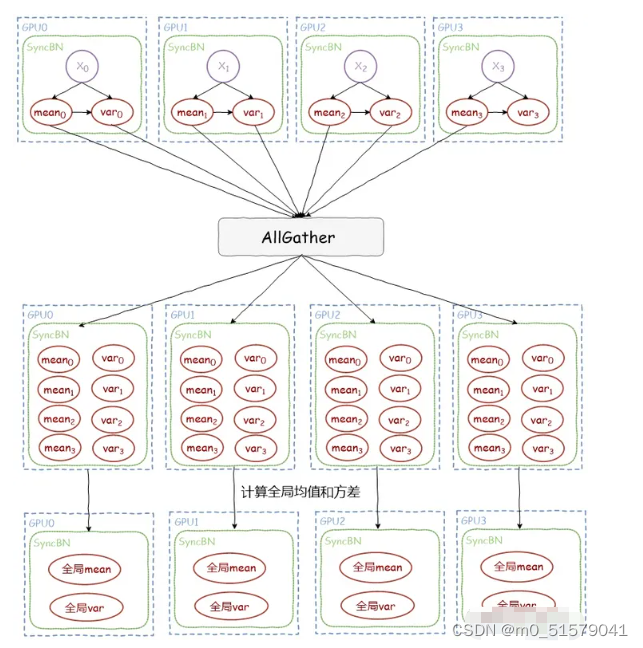
(3)BN并行
# -------------- 多卡同步Bn --------------#
if sync_bn and ngpus_per_node > 1 and distributed:
model_train = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
elif sync_bn:
print("Sync_bn is not support in one gpu or not distributed.")
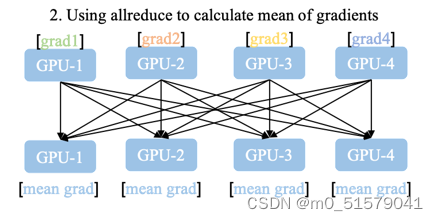
前向传播期间,损失函数的计算在每个 GPU 上独立执行,因此无需收集网络输出。
反向传播期间,各进程通过一种 ALL-Reduce或AllGather 的方法与其他进程通讯,交换各自的梯度,均值和方差,从而获得所有GPU上的平均梯度,全局的均值和方差,同时更新 running_mean 和 running_var。
各进程使用平均梯度在所有 GPU 上执行梯度下降,更新自己的参数。因为各个进程的初始参数、更新梯度一致,所以更新后的参数完全相同。
(4)数据并行
# -------------- 数据并行 --------------#
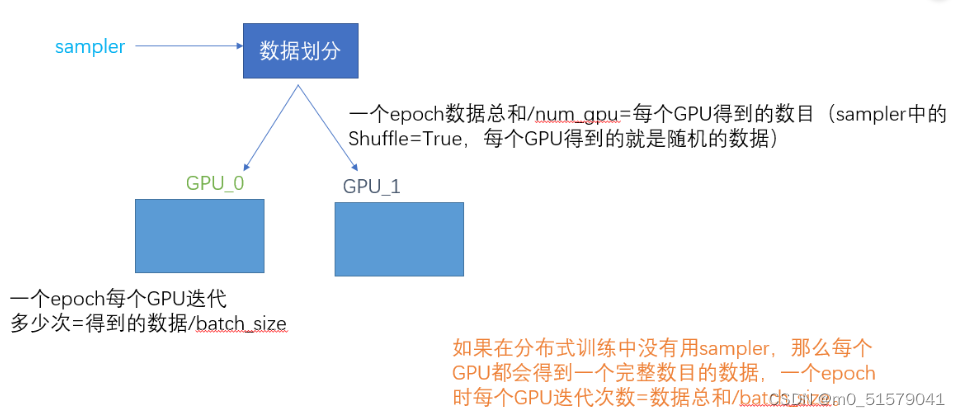
if distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, shuffle=True, )
val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset, shuffle=False, )
batch_size = batch_size // ngpus_per_node
shuffle = False
else:
train_sampler = None
val_sampler = None
shuffle = True
# -------------- 训练每进行一轮,都需要调用 train.sampler.set_epoch --------------#
if args.distributed:
train_sampler.set_epoch(epoch)
看下面这张图可以很好理解utils.data.distributed.DistributedSampler
(5)进程同步
#----------- 训练 -----------#
num_update = 0
for epoch in range(Init_epoch, Total_epoch):
for iter in range(epoch_step):
pass
#----------- 验证 -----------#
for epoch in range(Init_epoch, Total_epoch):
for iter in range(epoch_step):
pass
#----------- 进程同步 -----------#
if distributed:
dist.barrier()
dist.barrier()是一个同步操作,用于在分布式训练中进行进程间的同步。
当调用dist.barrier()时,当前进程会被阻塞,直到所有参与分布式训练的进程都调用了dist.barrier(),才会继续执行后续的代码。
这个同步操作的目的是确保所有进程都达到了同一个同步点,以便进行下一步的操作。在分布式训练中,可能会有一些需要所有进程都完成的操作,例如数据的收集、模型的更新等。通过使用dist.barrier()进行同步,可以保证所有进程在同一时间点上进行下一步操作,避免数据不一致或竞争条件的发生。
在给定的代码中,dist.barrier()被用于确保所有进程都已经写入了各自的部分结果,以便后续的合并操作可以顺利进行。在调用dist.barrier()之前和之后,分别进行了部分结果的保存和读取操作,通过同步操作可以保证这些操作在所有进程都完成之后再进行。
三、DDP完整训练框架
import torch
import torch.nn as nn
from torchvision import models
import matplotlib.pyplot as plt
import torch.distributed as dist
import os
import torch.backends.cudnn as cudnn
# -------------- DDP相关参数 --------------#
distributed=True
sync_bn = True
Cuda = True
find_unused_parameters=False
num_train_data = 100
batch_size = 10
epoch_step = num_train_data // batch_size
Init_epoch = 50
Total_epoch = 300
#---------- 搭建DDP训练框架 ------------#
#---------- model ------------#
model = models.AlexNet()
model = model.train()
#-------------- 初始化进程,设置用到的显卡 -----------------#
ngpus_per_node = torch.cuda.device_count()
if distributed:
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
rank = int(os.environ["RANK"])
device = torch.device("cuda", local_rank)
if local_rank == 0:
print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) training...")
print("Gpu Device Count : ", ngpus_per_node)
else:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
local_rank = 0
rank = 0
# -------------- 多卡同步Bn --------------#
if sync_bn and ngpus_per_node > 1 and distributed:
model_train = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
elif sync_bn:
print("Sync_bn is not support in one gpu or not distributed.")
# -------------- 数据并行 --------------#
if Cuda:
if distributed:
model_train = model_train.cuda(local_rank)
model_train = torch.nn.parallel.DistributedDataParallel(model_train, device_ids=[local_rank],find_unused_parameters=find_unused_parameters)
else:
model_train = torch.nn.DataParallel(model)
cudnn.benchmark = True
model_train = model_train.cuda()
# -------------- 数据分配 --------------#
if distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, shuffle=True, )
val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset, shuffle=False, )
batch_size = batch_size // ngpus_per_node
shuffle = False
else:
train_sampler = None
train_sampler_no_aug = None
val_sampler = None
shuffle = True
num_update = 0
for epoch in range(Init_epoch, Total_epoch):
#----------- 一轮训练和验证 -----------#
# -------------- train.sampler.set_epoch --------------#
if args.distributed:
train_sampler.set_epoch(epoch)
for iter in range(train_epoch_step):
pass
for iter in range(val_epoch_step):
pass
#----------- 进程同步 -----------#
if distributed:
dist.barrier()
四、DDP启动指令
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 torchrun --nproc_per_node=2 --master_port='29501' train.py
-CUDA_VISIBLE_DEVICES:指定使用哪几块GPU
-nproc_per_node :每台机器中运行几个进程
-master_port :0号机器的可用端口