shell数组
- 数组基本概述
- 什么是数组
- 数组的分类
- 普通数组
- 关联数组
- 数组的遍历与循环
- 案例1:
- 案例2:
- 案例3:
- 案例4:
数组基本概述
什么是数组
数组其实也算是变量,传统的变量只能存一个值,但是数组可以存多个值。
实际使用中主要通过for循环遍历数组中的数据
在awk、zabbix低级自动发现会使用到
数组的分类
shell数组分为普通数组和关联数组
普通数组:只能使用整数 作为数组索引
关联数组:可以使用字符串作为数组索引
普通数组
定义普通数组格式:数组名=(值1 值2 值3)
或
数组名[索引]=xxx
books[0]=python
books[1]=java

索引是从0开始的
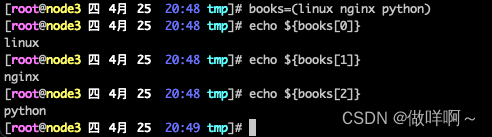
直接当变量输出,只会打印一个值

echo ${books[@]} 使用 @输出所有索引内容

echo ${!books[@]} 加一个!输出所有的索引

books=(linux nginx python) #定义普通数组
echo ${books[1]} #输出指定索引内容,指定索引,得到索引的值
关联数组
定义关联数组格式:数组名=([索引]=值 [索引1]=值1 [索引2]=值2 )

关联数组定义之前需要先申明
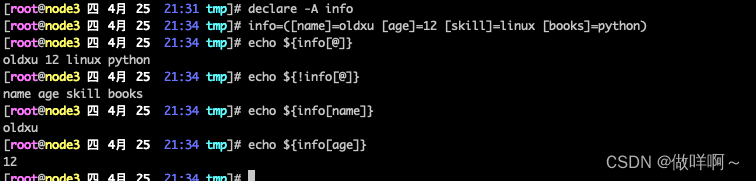
declare -A info
定义关联数组
info=([name]=oldxu [age]=12 [skill]=linux [books]=python)
获取关联数组中的所有数据
echo ${info[@]}
获取关联数组中的所有索引
echo ${!info[@]}
获取关联数组中某一索引的值
echo ${info[name]}
数组的遍历与循环
其实就是对数组进行批量赋值,然后通过循环的方式批量取出数组的值,对取出的内容进行统计。
例如需要统计一个文件中某个字段出现的次数
思路就是:要统计谁,就将谁作为数组的索引,然后看它出现的次数,仅支持关联数组。
数组遍历的两种方式
1.通过数组的个数进行遍历(不推荐)
2.通过数组的索引进行遍历(推荐)
案例1:
#!/bin/bash
while read line #read line命令用于读取文件中的每一行,并将其存储在line变量中.
do
hosts[i++]=$line #数组赋值#每循环一次索引自增1次,将文件中对应行的内容赋值给数组的索引
done</tmp/hosts #读取/tmp/hosts文件
#将赋值步骤拆解开就是以下效果:
#hosts[0]=127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#hosts[1]=::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#hosts[2]=
#hosts[3]=10.0.10.10 www.test.com
#遍历数组
for i in ${!hosts[@]} #${!hosts[@]}数组hosts中的所有索引
do
echo "索引为:$i ,索引对应的值为:${hosts[$i]}"
done
脚本执行效果:

案例2:
使用关联数组统计文件中的男女性别
ck 男
alice 女
tom 男
rose 女
robin 男
sam 男
以性别作为key,出现次数作为value构建关联数组
#!/bin/bash
declare -A list #申明数组
while read line
do
gender=$(echo $line|awk '{print $2}') #获取到文件中每行的性别
#要统计性别,就将性别作为索引,然后让其出现相同性别的时候进行自增
let list[$gender]++
done</tmp/gender.txt
#遍历数组
for i in ${!list[@]}
do
echo "索引为:$i ,索引出现的次数为:${list[$i]}"
done
脚本执行效果:

使用awk实现性别统计的效果

使用常规的方法实现性别统计的效果
sort 排序
uniq -c 在每行前面显示该行重复出现的次数

案例3:
统计/etc/passwd 中 Shell的类型,出现的次数。
常规方法获取:

awk的方法获取:

以shell类型作为key,出现次数作为value构建关联数组
#!/bin/bash
declare -A passwd #申明数组
while read line
do
type=$(echo $line|awk -F ':' '{print $7}') #获取到文件中每行的shell类型
#要统计shell类型,就将shell类型作为索引,然后让其出现相同shell类型的时候进行自增
let passwd[$type]++
done</etc/passwd
#遍历数组
for i in ${!passwd[@]}
do
echo "(索引)shell类型为:$i ,该类型出现的次数为:${passwd[$i]}"
done
脚本执行的效果:

案例4:
使用Shell数组,去统计nginx日志TOP的IP地址。
#!/bin/bash
declare -A accesslog #申明数组
while read line
do
ip=$(echo $line|awk '{print $1}') #获取到文件中每行的访问ip
#要统计ip,就将ip作为索引,然后让其出现相同ip的时候进行自增
let accesslog[$ip]++
done</etc/nginx/logs/access.log
#遍历数组
for i in ${!accesslog[@]}
do
echo "(索引)ip地址:$i ,访问的次数:${accesslog[$i]}"
done
脚本执行效果:

常规方法统计:
cat /etc/nginx/logs/access.log |awk '{print $1}'|sort|uniq -c|sort -nr
sort 参数
-n:对文件进行数字排序
-r:按相反顺序排序

awk方法统计:
awk '{ip[$1]++} END { for (i in ip) {print "IP地址:"i,"访问"ip[i] " 次"}}' /etc/nginx/logs/access.log