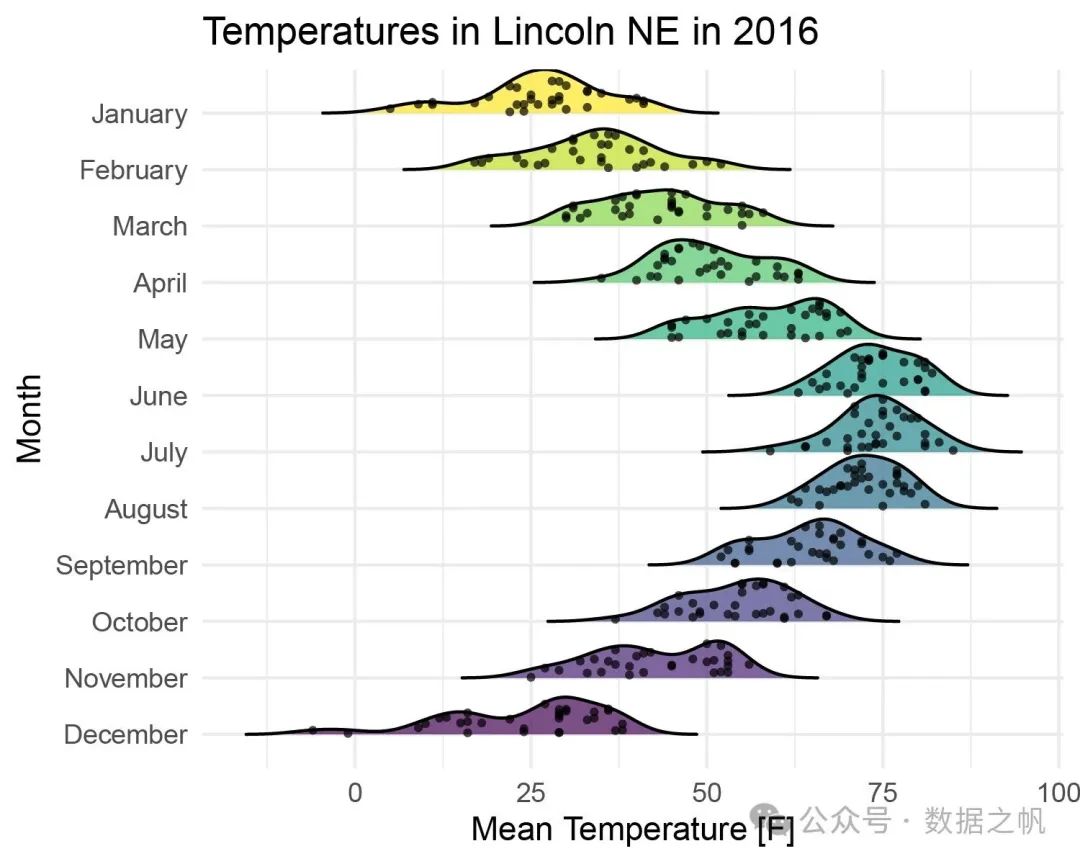
采用正则表达式的方法对字符串进行处理。
str1 = "{我%$是,《速$@.度\发》中 /国、人"
(1)提取汉字
汉字的范围为”\u4e00-\u9fa5“,这个是用Unicode表示的。
import re
res1 = ''.join(re.findall('[\u4e00-\u9fa5]',str1))
print(res1)
输出为:
‘我是速度发中国人’
(2)去除所有符号。采用清理数据,仅保留字母、数字、中文的方法。
import re
res1 = re.sub("[^a-zA-Z0-9\u4e00-\u9fa5]", '', str1)
print(res1)
输出为:
‘我是速度发中国人’







![[jinja2]模板访问对象属性](https://img-blog.csdnimg.cn/direct/5f000f3c42a94f69b3e65fe27e68180d.png)