-
说明:
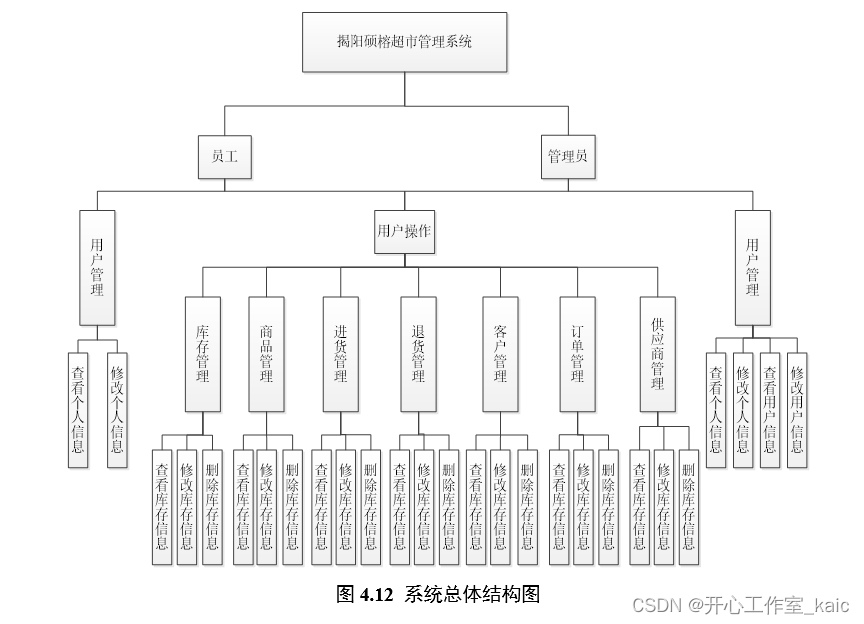
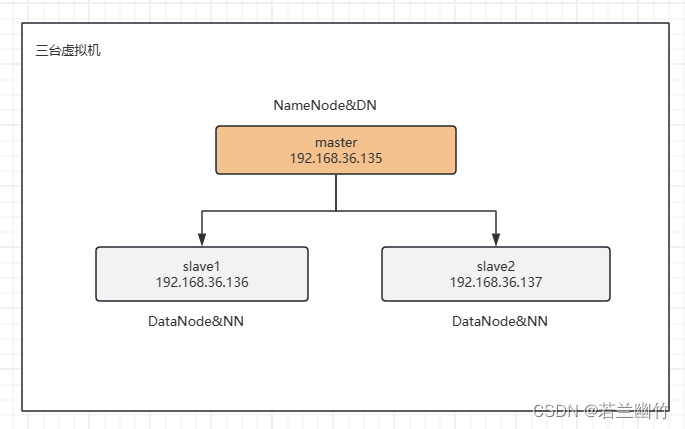
- 完成Hadoop全分布式环境搭建,需准备至少3台虚拟机(master slave01 slave02)
-
环境:
- VMWare + Centos7 + JDK1.8+ Hadoop3.3.6
-
主机规划:
- 主节点:master
- 从节点:slave01 , slave02
一、准备工作
-
1、所有主机安装jdk
-
上传jdk-8u171-linux-x64.tar.gz到/root目录下,然后执行下面的命令进行解压安装
tar -zvxf jdk-8u171-linux-x64.tar.gz -C /opt/software/ -
配置环境变量,执行:
vim ~/.bash_profile
在.bash_profile文件中添加如下信息:export JAVA_HOME=/opt/software/jdk1.8.0_171 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin; -
让环境变量生效
source ~/.bash_profile -
验证jdk是否安装成功
java -version
-
-
2、所有主机都需要关闭防火墙
systemctl stop firewalld.service systemctl disable firewalld.service -
3、所有主机都需要配置主机名映射关系
vim /etc/hosts,在文件末尾添加如下内容,注意:IP地址改成你自己环境的IP地址192.168.36.135 master 192.168.36.136 slave1 192.168.36.137 slave2 -
4、配置免密码登录(配置两两之间的免密码登录)
所有的机器都需要产生一对密钥:公钥和私钥
ssh-keygen -t rsa
所有主机需要执行ssh-copy-id -i .ssh/id_rsa.pub root@master ssh-copy-id -i .ssh/id_rsa.pub root@slave01 ssh-copy-id -i .ssh/id_rsa.pub root@slave02 -
5、保证每台机器的时间是一样的(可选做)
如果不一样的话,我们在执行MapReduce程序的时候可能会存在问题.。 解决方案:
1)搭建一个时间同步的服务器,网上很多教程可以使用
2)使用putty/shell工具,可以简单实现这个功能:
date -s 2024-03-16后面必须敲一个回车
二、在主节点上进行安装配置(master)
-
上传hadoop安装包,解决配置环境变量
tar -zvxf hadoop-3.3.6.tar.gz -C /opt/software/
注意需要同时设置:master slave1 slave2export HADOOP_HOME=/opt/software/hadoop-3.3.6 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH