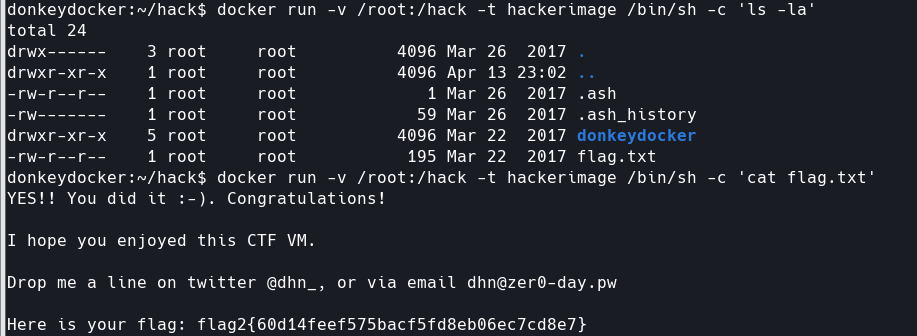
1 NLP模型的几个阶段
1.1 第一阶段(在深度学习出现之前)
- 通常聚焦于特征工程(feature engineering)
- 利用领域知识从数据中提取好的特征
1.2 第二阶段(在深度学习出现之后)
- 特征可以从数据中习得——>研究转向了结构工程(architecture engineering)
- 通过设计一个合适的网络结构,学习好的特征
1.3 第三阶段(预训练 + 微调)
- 用一个固定的结构预训练一个语言模型(language model, LM)
- 预训练的方式就是让模型补全上下文(比如完形填空)
- 预训练不需要专家知识,因此可以在网络上搜集的大规模文本上直接进行训练
- 这一阶段的一个研究方向是目标工程(objective engineering)
- 为预训练任务和微调任务设计更好的目标函数
- 让下游任务的目标与预训练的目标对齐是有利的
- 几种经典预训练任务
-
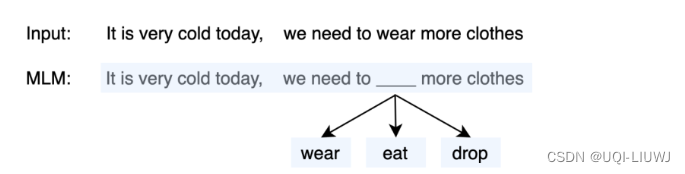
Masked Language Modeling(MLM)
- 随机选取一个固定长度的词袋区间,然后挖掉中心部分的词,让模型预测该位置的词
-
Next Sentence Prediction(NSP)
- 给定两个句子,来判断他们之间的关系
- 存在三种关系
- entailment(isNext)
- 紧相邻的两个句子
- contradiction(isNotNext)
- 这两个句子不存在前后关系,例如两个句子来自于不同的文章
- Neutral
- 中性关系,当前的两个句子可能来自于同一篇文章,但是不属于isNext关系的
- entailment(isNext)

-
1.4 第四阶段(预训练 + Prompt Tuning)
- 通过添加模板的方法来避免引入额外的参数,从而让语言模型可以在小样本(Few-shot)或零样本(Zero-shot)场景下达到理想的效果
2 prompt tuning
- Prompt的目的是将Fine-tuning的下游任务目标转换为Pre-training的任务
2.1 举例说明
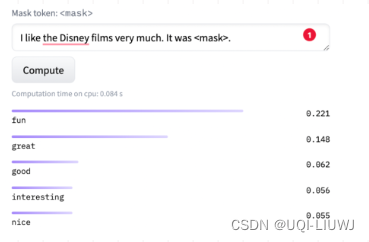
给定一个句子
[CLS] I like the Disney films very much. [SEP]
- 传统的Fine-tuning方法
- 通过BERT的Transformer获得
[CLS]表征 - 之后再喂入新增加的MLP分类器进行二分类,预测该句子是积极的(positive)还是消极的(negative)
- 需要一定量的训练数据来训练
- 通过BERT的Transformer获得
- Prompt-Tuning
- 构建模板(Template Construction)
- 通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有
[MASK]标记的模板 - 拼接到原始的文本中,获得Prompt-Tuning的输入
- [CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP]
- 将其喂入BERT模型中,并复用预训练好的MLM分类器,即可直接得到
[MASK]预测的各个token的概率分布
- 通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有
- 标签词映射(Label Word Verbalizer)
- 因为
[MASK]部分我们只对部分词感兴趣【比如 positive/negative】 - ——>需要建立一个映射关系
- 如果
[MASK]预测的词是“great”,则认为是positive类 - 如果是“terrible”,则认为是negative类
- 如果
- 因为
- 训练
- 只对预训练好的MLM head进行微调
- 构建模板(Template Construction)
3 PET(Pattern-Exploiting Training)
《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》(EACL2021)
3.1 pattern 和verbalizer
3.1.1 Pattern(Template)
- 记作T ,即上文提到的模板,为额外添加的带有
[mask]标记的短文本 - 通常一个样本只有一个Pattern(因为我们希望只有1个让模型预测的
[mask]标记) - 不同的任务、不同的样本可能会有其更加合适的pattern
- ——> 如何构建合适的pattern是Prompt-Tuning的研究点之一
3.1.2 Verbalizer
- 记作V ,即标签词的映射,对于具体的分类任务,需要选择指定的标签词(label word)。
- 例如情感分析中,期望Verbalizer可能是
- V(positive)=great; V(negative)=terrible
- (positive和negative是类标签)
- 如何构建Verbalizer是另一个研究挑战 。
上述两个组件被称为Pattern-Verbalizer-Pair(PVP),一般记作P=(T,V)
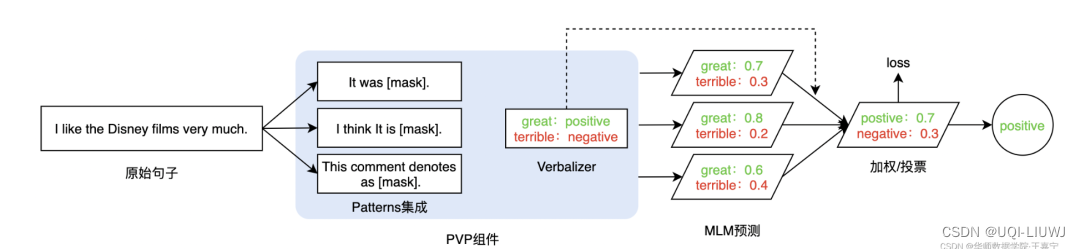
3.2 Patterns Ensembling
- 一般情况下,一个句子只能有一个PVP
- 这可能并不是最优的,是否可以为一个句子设计多个不同的PVP呢?
- ——>Prompt-Tuning的集成
- Patterns Ensembling :同一个句子设计多个不同的pattern
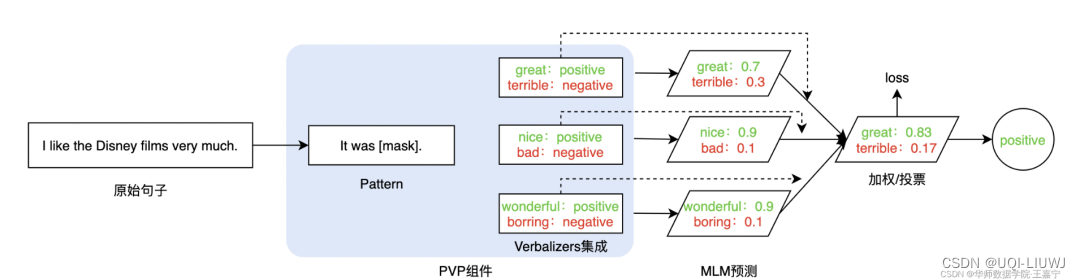
3.3 Verbalizers Ensembling
- 在给定的某个Pattern下,并非只有1个词可以作为label word。
- 例如positive类,则可以选择“great”、“nice”、“wonderful”。当模型预测出这三个词时,均可以判定为positive类。
- 在训练和推理时,可以对所有label word的预测概率进行加权或投票处理,并最后获得概率最大的类
3.4 PVPs Ensembling(Prompt Ensembling)
- Pattern和Verbalizer均进行集成,此时同一个句子有多个Pattern,每个Pattern又对应多个label word
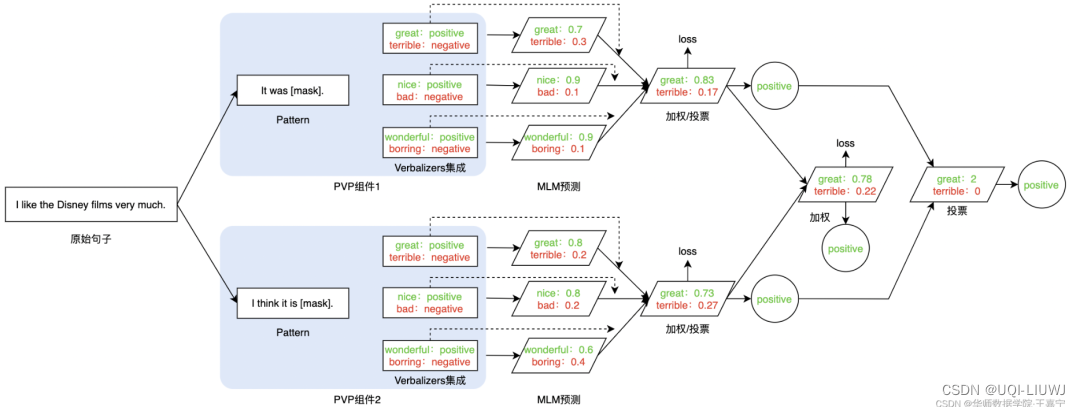
3.5 选择不同的Pattern和Verbalizer会产生差异很大的结果
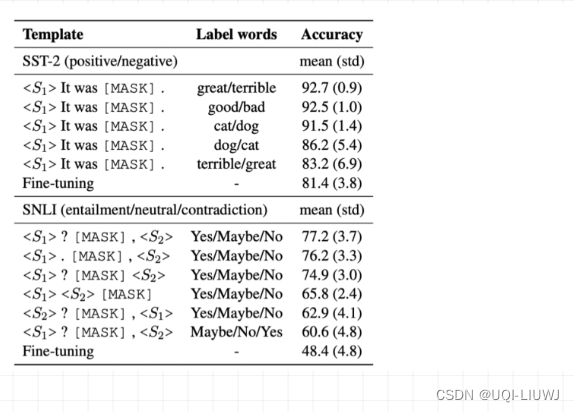
4 挑选合适的pattern
- 从3.5可以看出,不同的pattern对结果影响很大,所以如何挑选合适的pattern,是近几年学术界的一个热点
- 离散的模板构建(Hard Prompt)
- 直接与原始文本拼接显式离散的字符,且在训练中这些离散字符的词向量(Word Embedding) 始终保持不变
- ——>很难寻找到最佳的模板
- ——>效果不稳定
- 连续的模板构建(Soft Prompt)
- 让模型在训练过程中根据具体的上下文语义和任务目标对模板参数进行连续可调
- 离散的模板构建(Hard Prompt)
| 离散的模板构建 Hard Prompt | 启发式法(Heuristic-based Template) | 通过规则、启发式搜索等方法构建合适的模板 |
| 生成(Generation) | 根据给定的任务训练数据(通常是小样本场景),生成出合适的模板 | |
| 连续的模板构建 Soft Template | 词向量微调(Word Embedding) |
|
| 伪标记(Pseudo Token) | 不显式地定义离散的模板,而是将模板作为可训练的参数 |
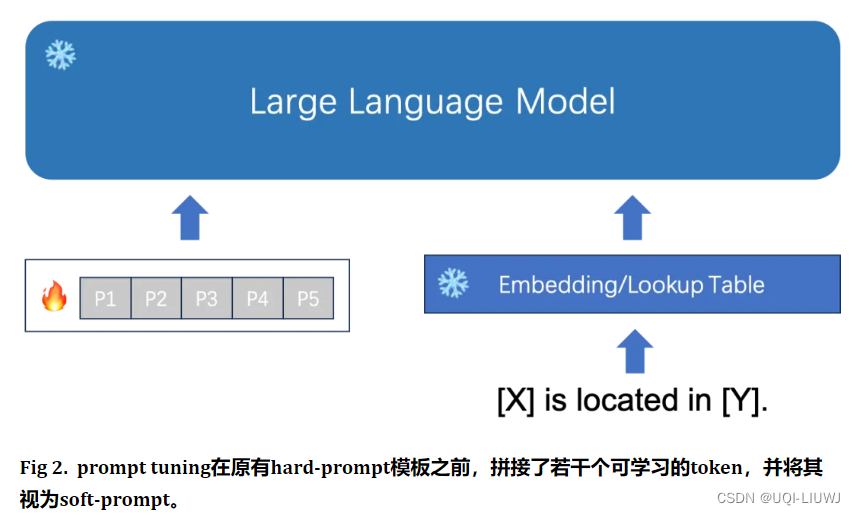
4.1 soft prompt
The Power of Scale for Parameter-Efficient Prompt Tuning, EMNLP 2021
- 记Y是LLM的输出,X是输入token,θ是Transformer的权重参数
- NLP中的文本生成任务可以表示为
- NLP中的文本生成任务可以表示为
- 之前的hard Prompting在生成 Y 时向模型添加额外信息以作为条件:
- 这一过程可以表示为
- 也就是将prompt的语句和输入token 连接在一起,输入给pre-train 模型,在pre-train 模型中,用它的参数生成 embedding,经过一系列的流程得到对应的输出
- 这一过程可以表示为
- soft prompt/prompt tuning 使用一组特殊Token作为prompt
- 给定一系列 n 个Token,
- 第一步是将这些Token向量化,形成一个矩阵
- 【使用pre-train 模型的参数】
- (e是向量空间的维度)
- soft prompt以参数
的形式表示
- (p是prompt的长度)
- 将prompt与向量化后的输入连接起来,形成一个整体矩阵
- 该矩阵接着正常地通过编码器-解码器流动
- 模型旨在最大化
的概率,但仅更新prompt参数θP
- 第一步是将这些Token向量化,形成一个矩阵
- 给定一系列 n 个Token,
参考内容:一文详解Prompt学习和微调(Prompt Learning & Prompt Tuning)







![[大模型] BlueLM-7B-Chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/e6dcf4f6486b461ba21af25a9cc502a2.png#pic_center)