一. Kafka基本介绍
Kafka是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统。具有:高吞吐量、低延迟、可扩展性、持久性、可靠性、容错性、高并发等特性。常见的应用场景有:日志收集、消息系统、流式处理等。
二. Kafka的基本架构
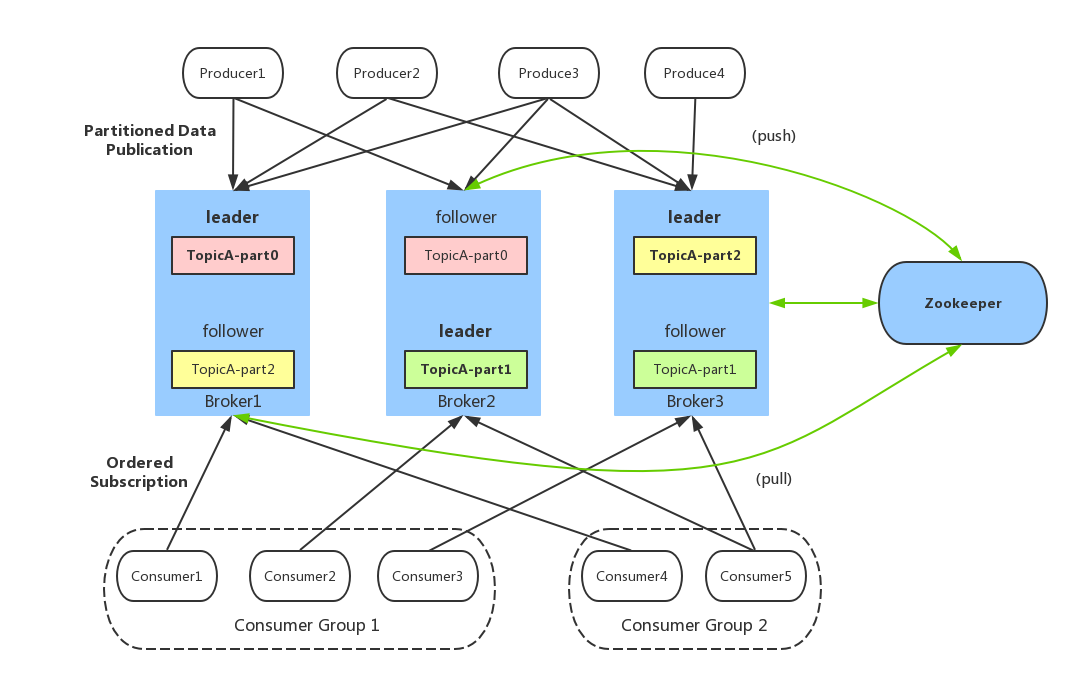
Producer:生产者,也就是发送消息的一方。生产者负责创建消息,然后将其发送到 Kafka。Consumer:消费者,也就是接受消息的一方。消费者连接到 Kafka 上并接收消息,进而进行相应的业务逻辑处理。Consumer Group:一个消费者组可以包含一个或多个消费者。使用多分区 + 多消费者方式可以极大提高数据下游的处理速度,同一消费组中的消费者不会重复消费消息,同样的,不同消费组中的消费者消息消息时互不影响。Kafka 就是通过消费组的方式来实现消息 P2P 模式和广播模式。Broker:服务代理节点。Broker 是 Kafka 的服务节点,即 Kafka 的服务器。Topic:Kafka 中的消息以 Topic 为单位进行划分,生产者将消息发送到特定的 Topic,而消费者负责订阅 Topic 的消息并进行消费。Partition:Topic 是一个逻辑的概念,它可以细分为多个分区,每个分区只属于单个主题。同一个主题下不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。Offset:offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka 保证的是分区有序性而不是主题有序性。Replication:副本,是 Kafka 保证数据高可用的方式,Kafka 同一 Partition 的数据可以在多 Broker 上存在多个副本,通常只有主副本对外提供读写服务,当主副本所在 broker 崩溃或发生网络一场,Kafka 会在 Controller 的管理下会重新选择新的 Leader 副本对外提供读写服务。Record:实际写入 Kafka 中并可以被读取的消息记录。每个 record 包含了 key、value 和 timestamp。
三. Kafka如何保证消息顺序消费
Kafka 在 Topic 级别本身是无序的,只有 partition 上才有序,所以为了保证处理顺序,可以自定义分区器,将需顺序处理的数据发送到同一个 partition。自定义分区器需要实现接口 Partitioner接口并实现 3 个方法:partition,close,configure,在partition 方法中返回分区号即可。
Kafka 中发送 1 条消息的时候,可以指定(topic, partition, key) 3 个参数,partiton 和 key 是可选的。
Kafka 分布式的单位是 partition,同一个 partition 用一个 write ahead log 组织,所以可以保证FIFO 的顺序。不同 partition 之间不能保证顺序。因此你可以指定 partition,将相应的消息发往同 1个 partition,并且在消费端,Kafka 保证1 个 partition 只能被1 个 consumer 消费,就可以实现这些消息的顺序消费。
另外,也可以指定 key(比如 order id),具有同 1 个 key 的所有消息,会发往同 1 个partition,那这样也实现了消息的顺序消息。
四. Kafka发送消息选择分区的逻辑
Kafka在数据生产的时候,有一个数据分发策略。默认的情况使用org.apache.kafka.clients.producer.internals.DefaultPartitioner类,这个类中就是定义数据分发的策略。默认策略为:
- 如果在发消息的时候指定了分区,则消息投递到指定的分区
- 如果没有指定分区,但是消息的key不为空,则基于key的哈希值来选择一个分区
- 如果既没有指定分区,且消息的key也是空,则用轮询的方式选择一个分区
五. Kafka如何避免消息丢失
Kafka的消息避免丢失可以从三个方面考虑处理:Producer发送消息避免失败、Broker能成功保存接收到的消息、Consumer确认消费消息。
-
Producer发送消息避免失败
想要Produce发送消息不失败,那就得知道发送结果,网络抖动这些情况是无法避免的,只能是发送后获取发送结果,那么最直接的方式就是把Kafka默认的异步发送改为同步发送(Broker收到消息后ack回复确认),这样就能实时知道消息发送的结果,但是这样会让Kafka的发送效率大大降低,因为Kafka在默认的异步发送消息的时候可以批量发送,以此大幅度提高发送效率,因此一般很少使用同步发送的方式,除非消息很重要绝不允许丢失。
但是我们可以采用添加异步或调函数,监听消息发送的结果,如果失败可以在回调中重试,以此来达到尽可能的发送成功。同时Producer本身提供了一个retries的机制,如果因为网络问题,或者Broker故障 导致发送失败,就是重试。一般这个retries设置3-5次或者更高,同时重试间隔时间也随着次数增长。 -
Broker能成功保存接收到的消息
Broker要成功的保存接收到的消息并且不丢失,就需要把接收到的消息保存到磁盘。Kafka为了提高性能采用的是异步批量,存储到磁盘的机制,就是有一定的消息量和时间间隔要求的,刷磁盘的这个动作是操作系统来调度的,如果在刷盘之前系统就崩溃了,就会数据丢失。
针对这个情况,Kafka采用Partition分区ack机制,Partition分区是指一个Topic下的多个分区,有一个Leader分区,其他的都是Follower分区,Leader分区负责接收和被读取消息,Follower分区会通过Replication机制同步Leader的数据,负责高可用(Kafka在2.4之后,Kafka提供了读写分离,Follower也可以提供读取),当Leader出现故障时会从Follower中选取一个成为新的Leader。那么当一个消息发送到Leader分区之后,Kafka提供了一个acks的参数,Producer可以设置这个参数,去结合broker的Partition机制来共同保障数据的可靠性,这个参数的值有三个0,表示Producer不需要等待broker的响应,就认为消息发送成功了(可能存在数据丢失)1,表示Leader收到消息之后,不等待其他的Follower的同步就给Producer发一个确认,如果Leader和Partition挂了就可能存在数据丢失-1,表示Leader收到消息之后还会等待ISR列表(与Leader保持正常连接的Follwer节点列表)中的Follower同步完成,再给Producer返回一个确认,也就是所有分区节点都确认收到消息,保证数据不丢失
-
Consumer确认消费消息
当Producer确定发送消息成功并且Broker成功保存消息之后,基本上Consumer就肯定能消费到消息。Kafka在消费者消费时有一个offset机制,代表了当前消费者消费到了Partition的哪一条消息。kafka的Consumer的配置中,默认的enable.auto.commit = true,表示在Consumer通过poll方法 获取到消息以后,每过5秒(通过配置项可修改)会自动获取poll中得到的最大的offset, 提交给Partition中的offset_consumer(存储 offset 的特定topic)。如果enable.auto.commit = false时,则关闭了自动提交,需要手动的通过应用程序代码进行提交。
所以在Consumer消费消息时,丢失消息的可能会有两种,比如开启了offset自动提交,但是消息消费失败;或者没有开启自动提交offset,但是在消费消息之前提交了offset。针对这两种情况,可以设置在消息消费完成后手动提交offset。总之Consumer端确认消息消费成功后再提交offset即可保证消息正常消费。
六. Kafka的offset机制
Kafka中的每个Partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到Partition中。Partition中的每个消息都有一个连续的序号,用于Partition唯一标识一条消息。