我最近自学了一段时间爬虫,感觉挺有意思的,逛网页的时候,无意间发现了一个壁纸网站,我就萌生了一个想法,看能不能下下来,说干就干。
前言
目标网站:首先我们要知道我们的目标位置。
编程语言:python
环境使用
- python 3.9
- pycharm
模块使用
- requests
请求头
# python代码对于服务器发送请求 >>> 服务器接收之后(如果没有伪装)被识别出来, 是爬虫程序, >>> 不会给你返回数据
# 客户端(浏览器) 对于 服务器发送请求 >>> 服务器接收到请求之后 >>> 浏览器返回一个response响应数据
# headers 请求头 就是把python代码伪装成浏览器进行请求
# headers参数字段 是可以在开发者工具里面进行查询 复制
# 并不是所有的参数字段都是需要的
# user-agent: 浏览器的基本信息 (相当于披着羊皮的狼, 这样可以混进羊群里面)
# cookie: 用户信息 检测是否登录账号 (某些网站 是需要登录之后才能看到数据, B站一些数据内容)
# referer: 防盗链 请求你的网址 是从哪里跳转过来的 (B站视频内容 / 妹子图图片下载 / 唯品会商品数据)
# 根据不同的网站内容 具体情况 具体分析
下面就按照爬虫的思路,一步一步的进行。
一、发送请求
进入主页后,我们随便点击一个标签,我们已这个为例,其他的思路一样,后面,你会发现网址差不多,只要改部分内容即可。

import requests
url = 'https://wallhaven.cc/toplist' #toplist是可以改动的
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
print(response)运行之后,会返回<Response [200]>,说明我们请求到了网页,接下来就是获取数据。
二、获取数据
我们用开发者工具,查找我们要的源代码。

这样,我们就找到了源地址,一个是小图(分辨率比较低),一个是图片真实的网址(高分辨率),这里我们用正则表达式去匹配它。
html_url = re.findall('class="preview" href="(.*?)"',response.text,re.S)通过观察我们发现,所有图片的源地址的位置都差不多。这样我们就获得了图片原网页的列表。

同理,我这里用图片地址的后缀来做图片的命名。
id = re.findall('data-wallpaper-id="(.*?)"', response.text, re.S)
html_data = zip(html_url,id)接下来,我们就接下来就是挨个访问,保存数据就可以了。
我们先用for遍历所有图片的地址,在发送请求。
for html_url,id in html_data:
html_spon = requests.get(html_url,headers=headers)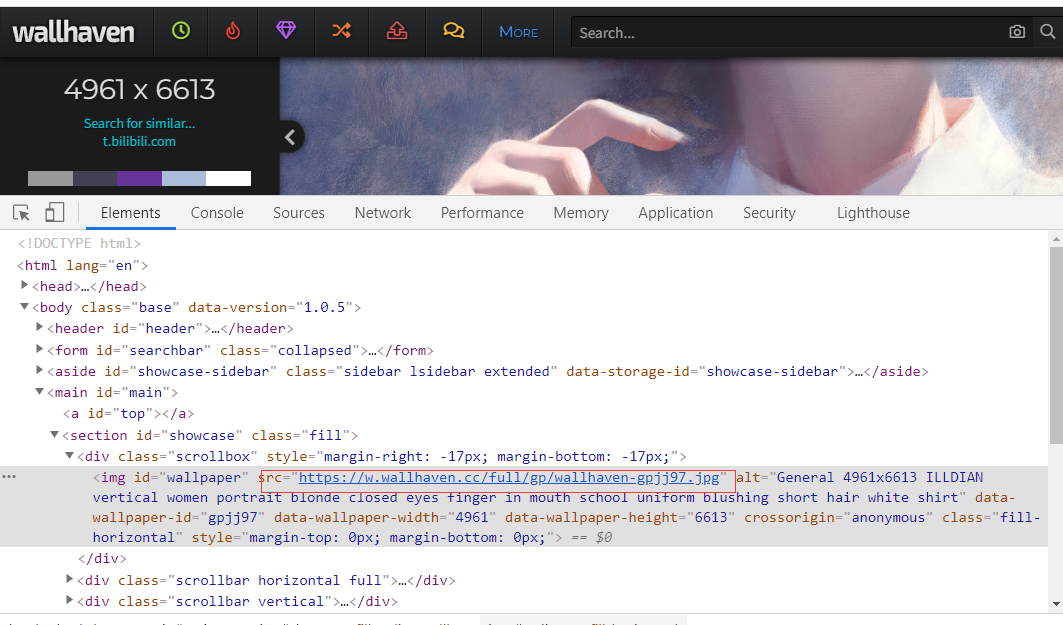
这个就是我们要的高清图的地址。我们还是用正则表达式去匹配。
pic_url = re.findall('id="wallpaper" src="(.*?)"', html_spon.text, re.S)[0] # 图片地址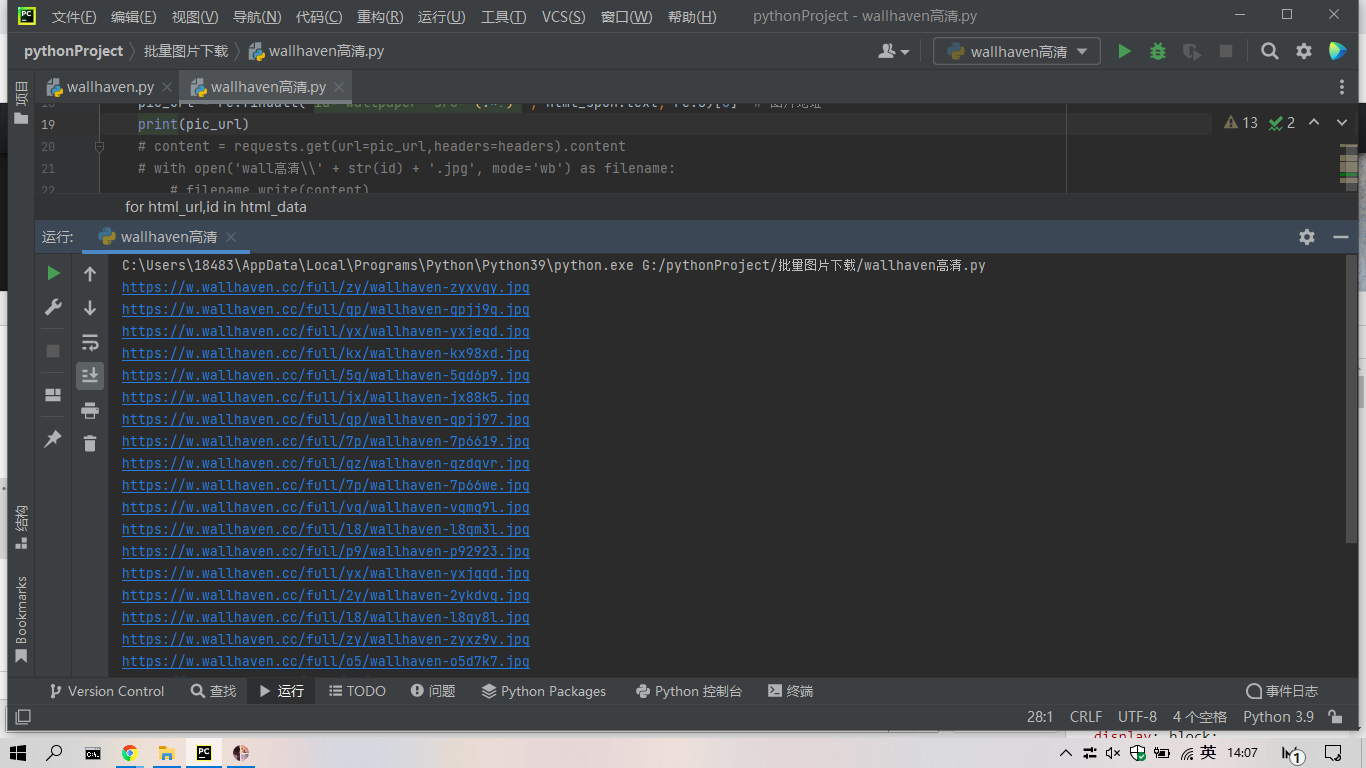
下面就是获取高清图的数据
content = requests.get(url=pic_url,headers=headers).content三、保存数据
with open('wall高清\\' + str(id) + '.jpg', mode='wb') as filename:
filename.write(content)
print(id, "successful")我们来看看保存之后的效果吧。
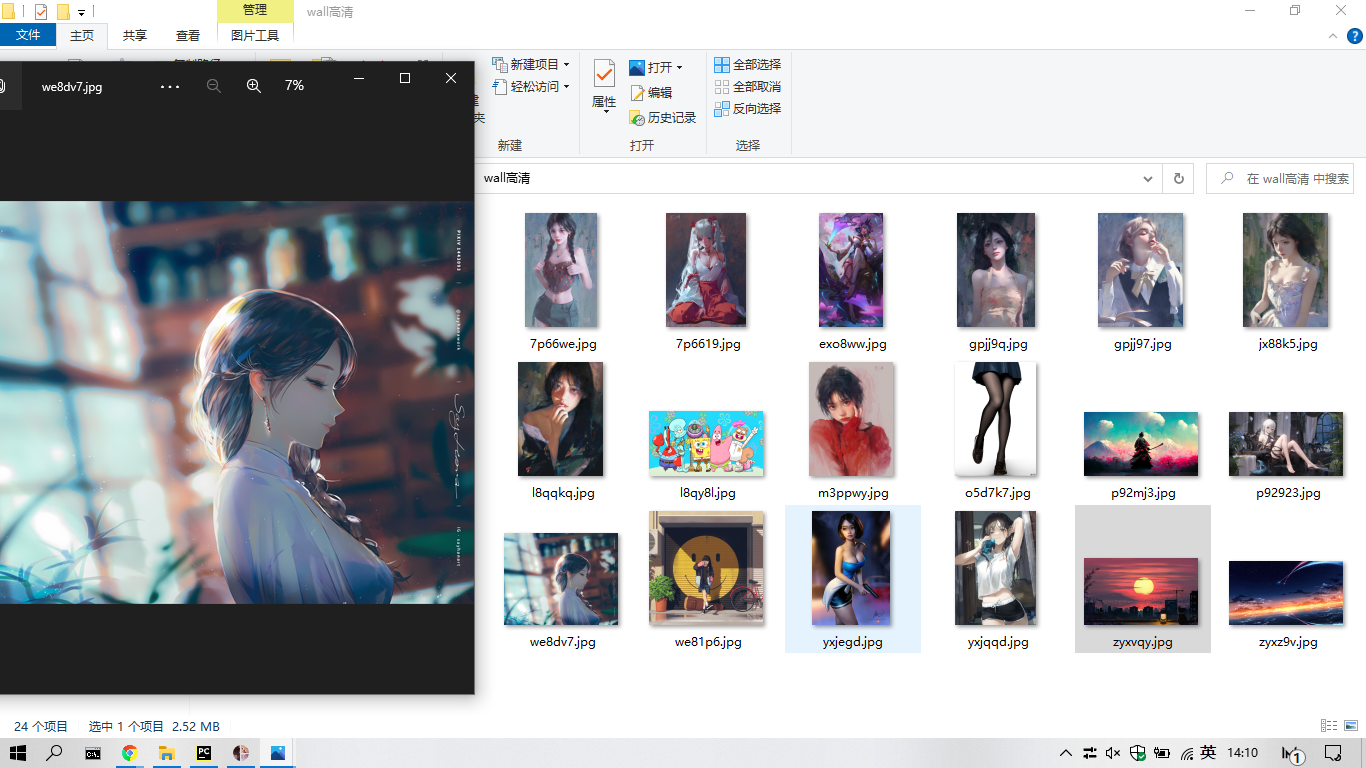
说明:
- 我们会发现,随着我们鼠标的滚动,网址发生了一些变化,http://***/page=2,只是page后面的数字不一样,我们只要遍历page就可以实现多页爬取。
- 我们发现选择其他类型的时候,toplist变了,在这里我们只要改动这里,同样是可以运行的。
- 我们还可以尝试从键盘接收类型,page去爬取,还是直接通过网页获取,都是可以的。
- 大家可以设置sleep,防止请求频繁,被封IP。
- 还有就是,os文件处理问题,这里就不赘述,自己手动建立一个wall高清文件夹。
到这里,大体程序就写完了,是可以执行的。





![[附源码]计算机毕业设计JAVA航空售票管理系统](https://img-blog.csdnimg.cn/8854c5c55627409b8f372d0306cacfc4.png)