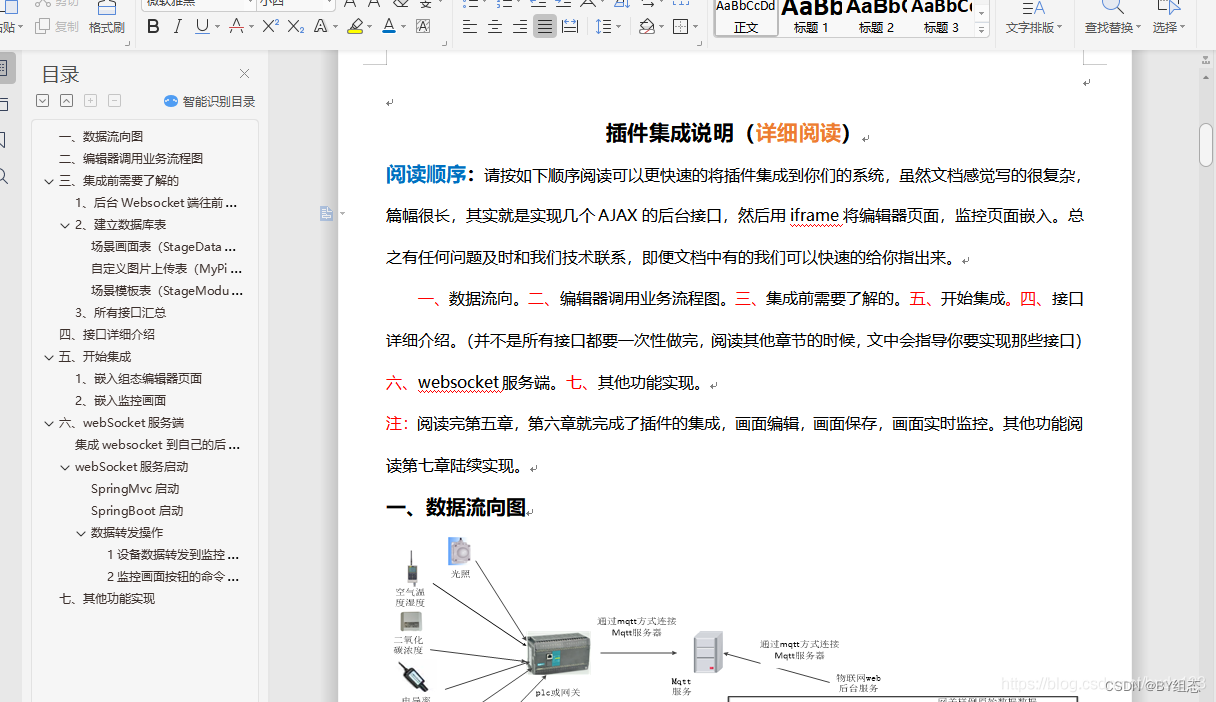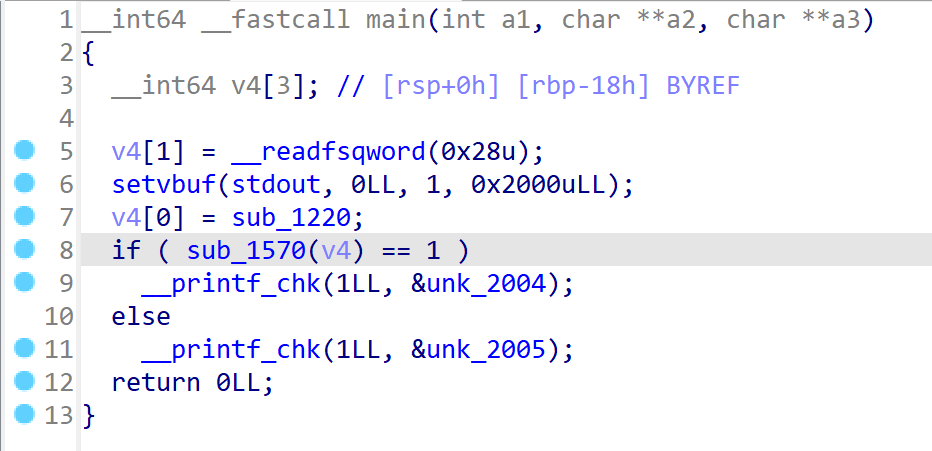
逻辑似乎很简单(个鬼啊)

这个函数是把输入的字符转化为二进制并倒序存储
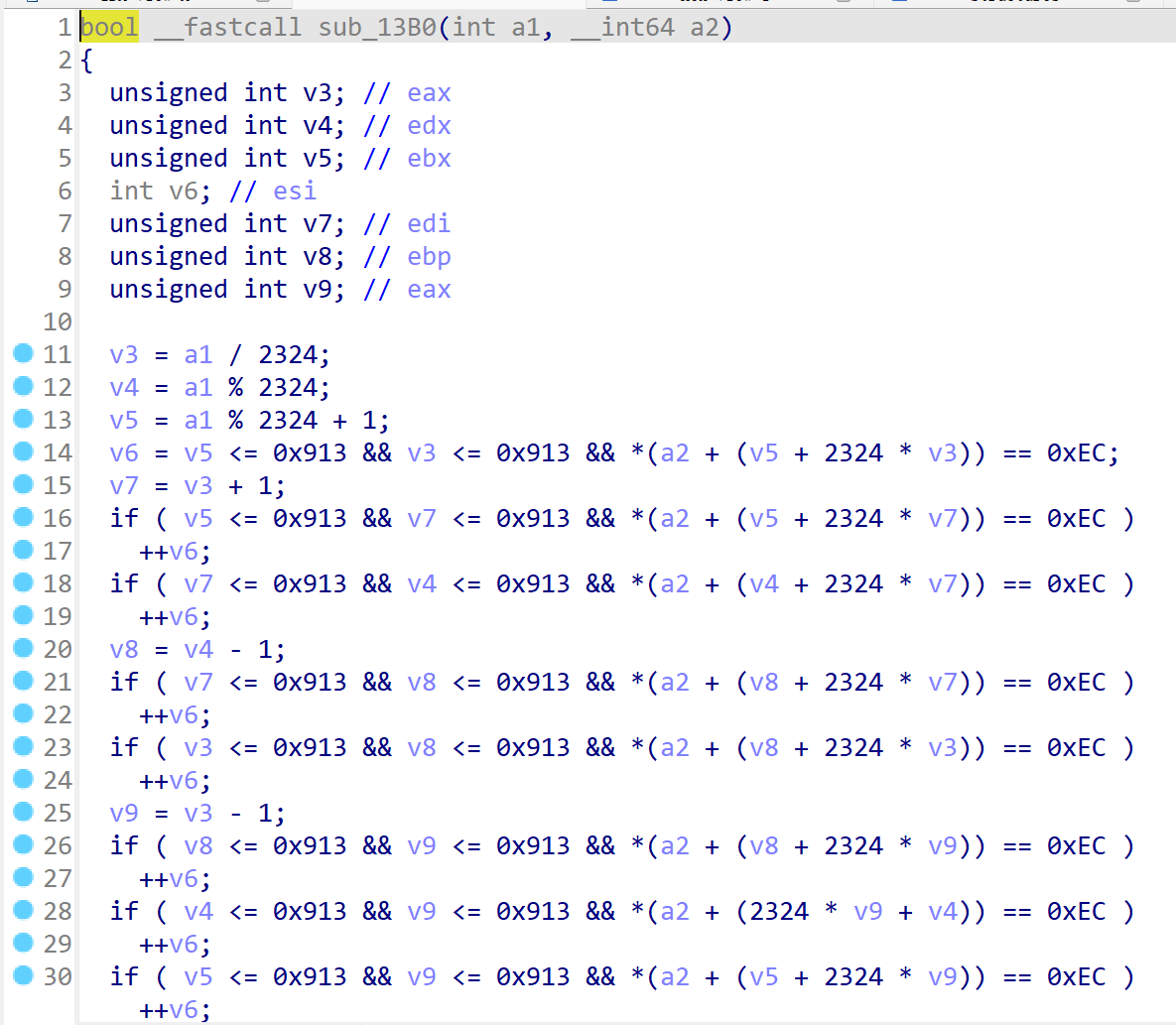
sub_1570太大了加载不出来,应该是加密的主逻辑,目的是需要输出1
可以通过删除栈的方法强行转化伪代码

首先删掉这部分
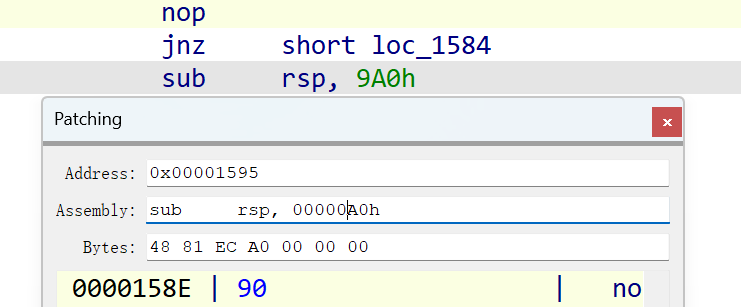
9A0改小点
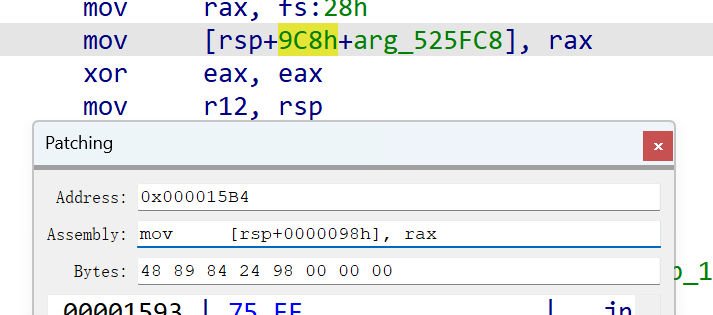
这个也是
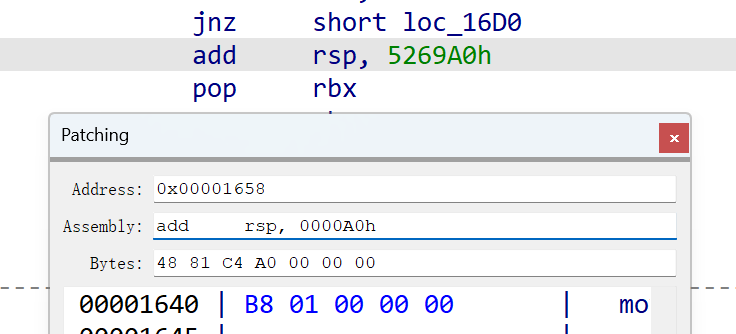

栈这里U一下再P



像是虚拟机的分发器,unk_4018是类似opcode的大坨数据
好像有几十万
实际上是一个2324*2324的像素图,在上面进行染色
cable management | /den/face0xff/writeups![]() https://ctf.0xff.re/2022/dicectf_2022/cable_management
https://ctf.0xff.re/2022/dicectf_2022/cable_management
【游戏框架系列】Wireworld元胞自动机 - 知乎【多图预警】本文含有大量图片写在前面这次实现的是Wireworld元胞自动机,相关资料如下: 维基:Wireworld - Wikipedia 介绍:WireworldFlash模拟:Wireworld Player (Flash) 如何实现简单的计算机:The Wireworld…![]() https://zhuanlan.zhihu.com/p/25593938
https://zhuanlan.zhihu.com/p/25593938
根据资料我才知道,这其实是在模拟Wireworld元胞自动机
组成:
- 空
- 导体
- 电子头
- 电子尾
每代变化:
- 空→空
- 电子头→电子尾
- 电子尾→导体
- 当仅有一个或仅有两个电子头的邻居是导体时,导体→电子头

对应着理解,0xCD就是导线

0xEA就是电子尾,0xEC是电子头

0x11是数据注入点

0x80相当于空/消除信号

1就是终点,到达就返回1
由此根据数据绘图分析,这实际上是利用wireworld高度抽象的虚拟机
数据量太大,这里用脚本提取
#data_extract
import idaapi
import idautils
# 设置你要读取数据的起始和结束地址
START_ADDR = 0x4018 # 替换为你的起始地址
END_ADDR = 0x535D93 # 替换为你的结束地址
BYTES_PER_LINE = 16 # 每行显示的字节数
# 打开一个文件用于写入,如果文件不存在则创建它
with open('output.txt', 'w') as f:
# 用于记录当前行已经写入了多少字节
bytes_written = 0
# 遍历指定地址范围内的每个地址
for ea in range(START_ADDR, END_ADDR + 1):
# 读取当前地址的一个字节
byte_value = idaapi.get_byte(ea)
# 将字节转换为十六进制字符串
hex_string = '0x{:02X}'.format(byte_value)
# 写入文件,并在需要时添加逗号
if bytes_written > 0 and bytes_written % BYTES_PER_LINE != 0:
f.write(',')
f.write(hex_string)
bytes_written += 1
# 如果当前行已经写入了足够的字节数,则换行
if bytes_written % BYTES_PER_LINE == 0:
f.write(',\n')
# 文件会在脚本执行完毕后自动关闭
print("Data has been written to output.txt")然后绘图(来自孤恒师傅的脚本)
from PIL import Image
s = [...]
img = Image.new('RGB', (0x914, 0x914), (255, 255, 255))
pixels = img.load()
for i in range(len(s)):
if s[i] == 0x1:
i_row = i // 0x914
i_col = i % 0x914
#print("0x01_row:"+f"{i_row:X}" + " 0x01_col:"+f"{i_col:X}")
pixels[i_row, i_col] = (255, 0, 0)
elif s[i] == 0xEC:
i_row = i // 0x914
i_col = i % 0x914
#print("0xEC_row:"+f"{i_row:X}" + " 0xEC_col:"+f"{i_col:X}")
pixels[i_row, i_col] = (0, 0, 255)
elif s[i] == 0x11:
i_row = i // 0x914
i_col = i % 0x914
#print("0x11_row:"+f"{i_row:X}" + " 0x11_col:"+f"{i_col:X}"
pixels[i_row, i_col] = (0, 255, 0)
elif s[i] == 0xCD:
i_row = i // 0x914
i_col = i % 0x914
#print("0xCD:"+f"{i:X}")
pixels[i_row, i_col] = (0, 0, 0)
elif s[i] == 0x80:
i_row = i // 0x914
i_col = i % 0x914
#print("0xCD:"+f"{i:X}")
pixels[i_row, i_col] = (255, 255, 0)
elif s[i] == 0xEA:
i_row = i // 0x914
i_col = i % 0x914
#print("0xCD:"+f"{i:X}")
pixels[i_row, i_col] = (0, 255, 255)
img.save('D:\\下载\\CTF附件\\nk\\image.png')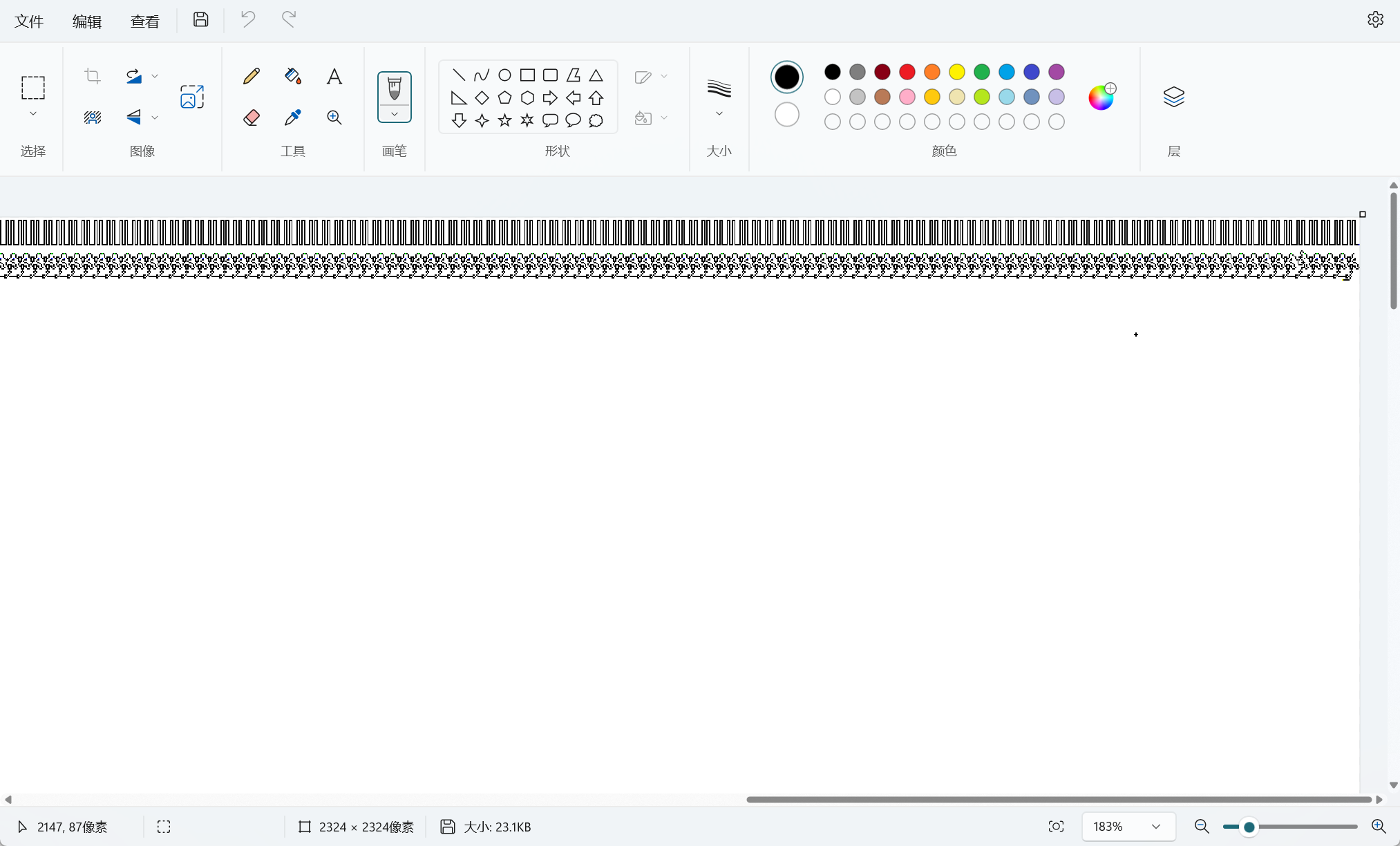
有大量重复的图案,我们放大进行分析

乍一看难以理解,结合wireworld的规则,我们可以分析出图案蕴藏的含义

最上面就是一条畅通无阻的电线

下面很复杂,先看重复度最高的这部分,注意到不断重复的这个模块

我们用网站模拟
Wireworld Simulator![]() https://danprince.github.io/wireworld/
https://danprince.github.io/wireworld/
只有一侧输入信号(即一侧1,一侧0)时,电子头会正常向下传导

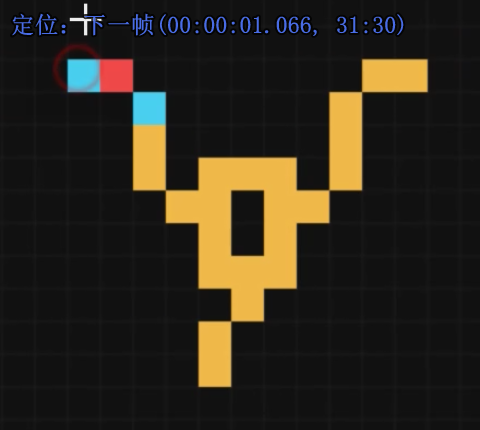

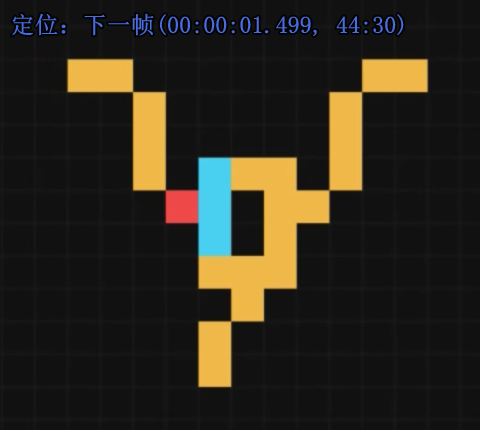


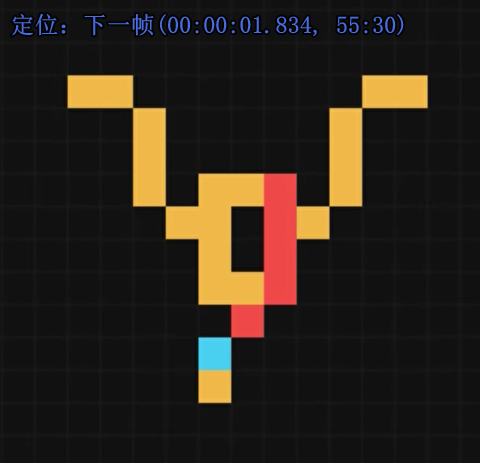

但如果两边都有
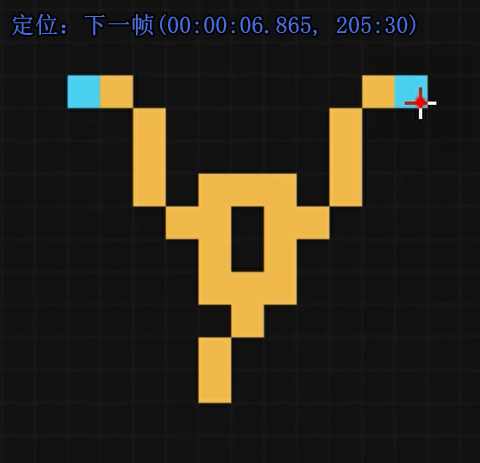



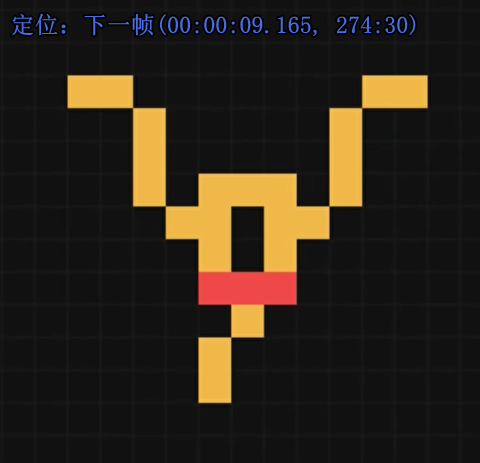

信号就会消失
所以这其实是在模拟异或(逻辑门),原理是在这里
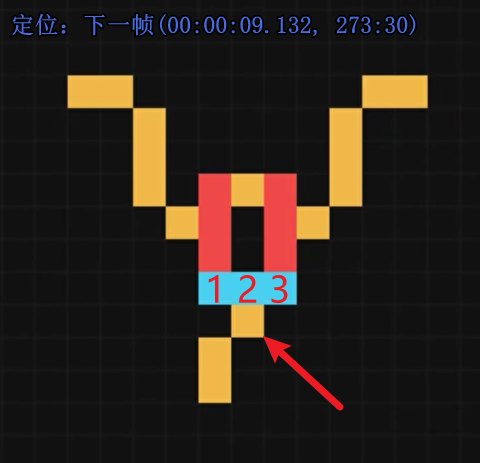
箭头所指的导线周围有三个电子头,但我们的规则是当仅有一个或仅有两个电子头的邻居是导体时,导体→电子头
因此就达到了异或的效果
图中除了大量的异或,还有别的图形


可以用相同的方法分析出这个是与


这个是或
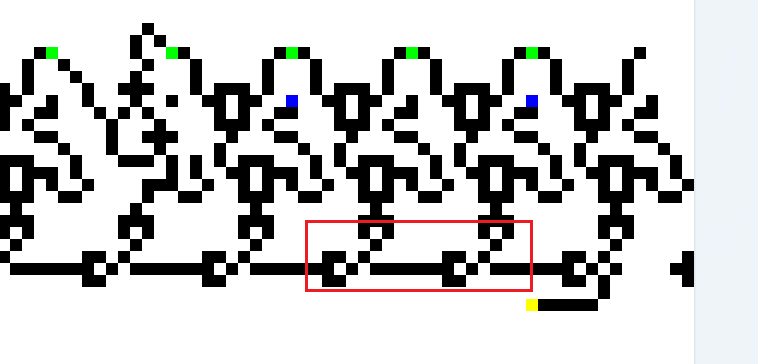

这个则是一个二极管,像神经突触一样,只会从“突触前模”向“突触后膜”单向传导
我们可以根据这些特征把整个图分割开,由于每个输入的字符都转化为8位二进制注入(绿色就是注入点),所以我每八个循环分割一次,最后得到29块,对应29个输入的字符
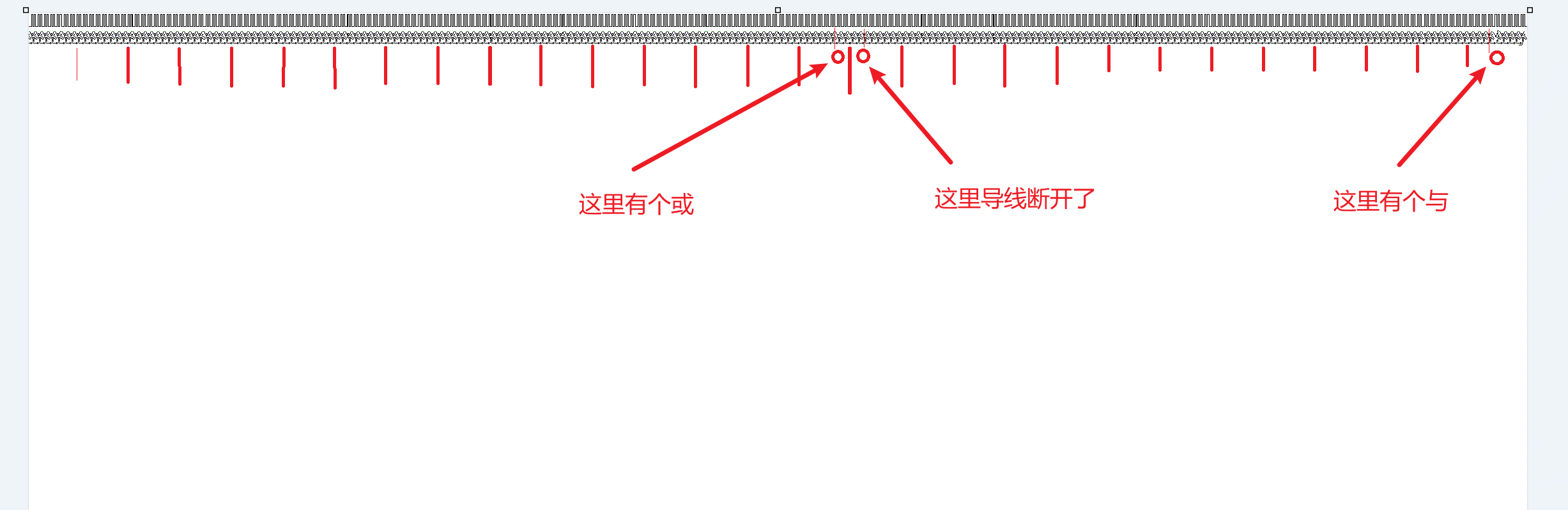
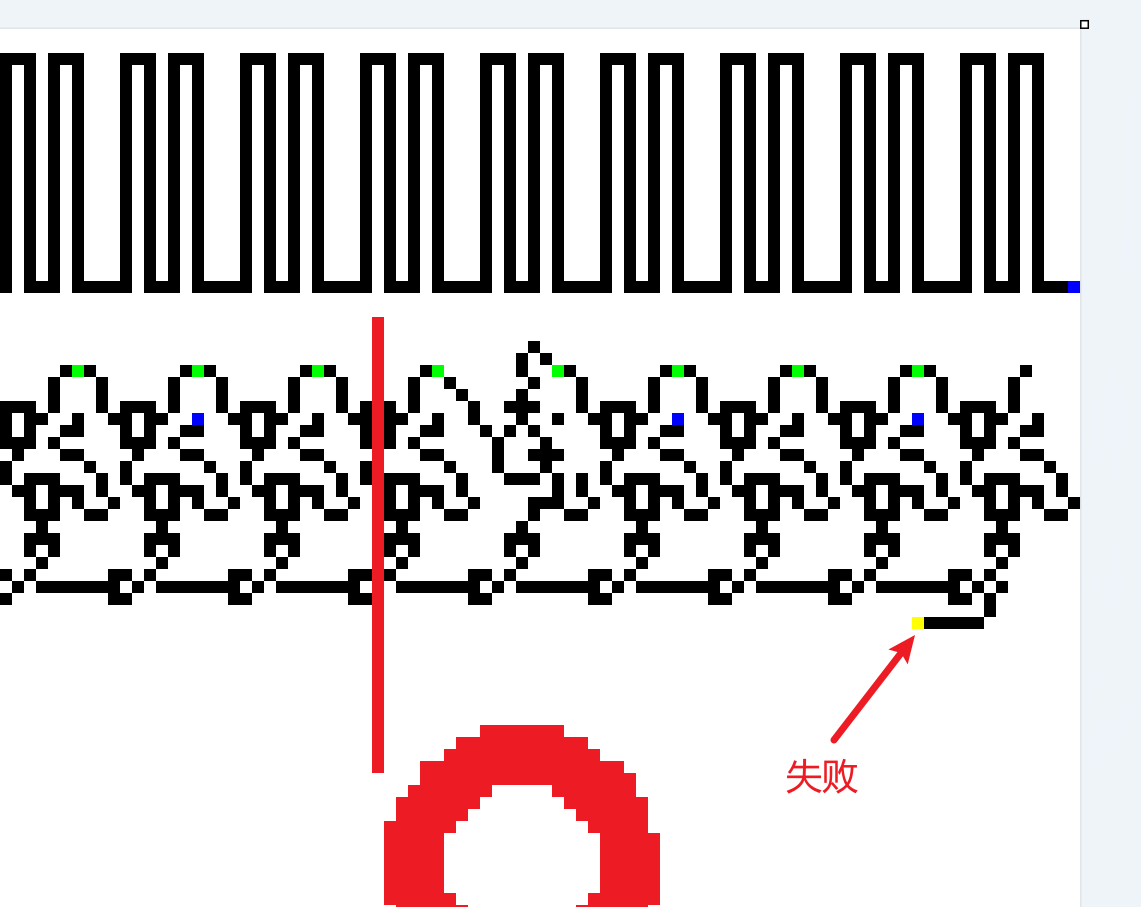
输入的字符究竟是如何处理的呢?可以看到,每个绿色注入点激活的电子头会向左右两边传导,经过一个异或(输入的字符转化为倒序二进制数,这个数的每相邻两位异或)之后,与蓝色点激活的电子头再次异或,之后得到的信号就会输入下面的向右的二极管结构
也就是说,只要有一个异或结果是1(有电),电子头就会向右传导到失败点。所以我们的目标就是消除所有产生的电子头,使得上面那一条完整的电线上的电子头平安到达左侧的终点
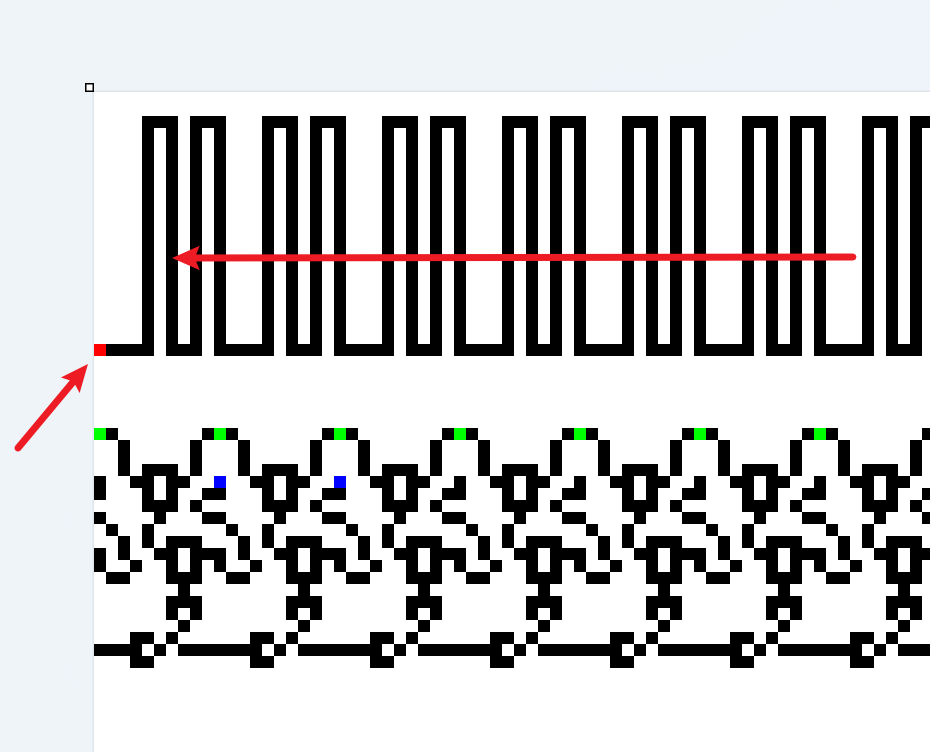
可以看到,蓝色电子头总是在循环结构相同的位置上,代表着这个位置上电信号的1和0,将他们连接在一起就相当于组成了一个由0、1组成的key(可以脚本取key,我嫌麻烦就直接手敲了)
我们要求的flag是上面一排注入点的0/1状态,加密过程就是我之前说的一系列异或,我们期望得到的结果就是全0
由此我们可以写出解密的函数,将key与全0序列异或逆序转化成字符串
def decode(key):
key_string = long_to_bytes(int("".join([str(i) for i in key]), 2))
#print(key_string)
res = [0]
for i in range(len(key)-1):
tmp = res[i]^key[i]
res.append(tmp)
#print(res)
flag = long_to_bytes(int("".join([str(i) for i in res]), 2))
print(flag)但我们并不能把整段key直接放进去解密,因为整个wireworld结构被中段分割成了两半,右边(相当于前面一半)是插入了与的部分

左边是插入了或的部分


先看前半部分,与的前面有四个注入点,key第四位相当于缺失的

但反正就0和1两种情况,拿出前八位二进制试一下就会发现这一位为1的时候可以得到n(就是nkctf的开头),否则会得到a

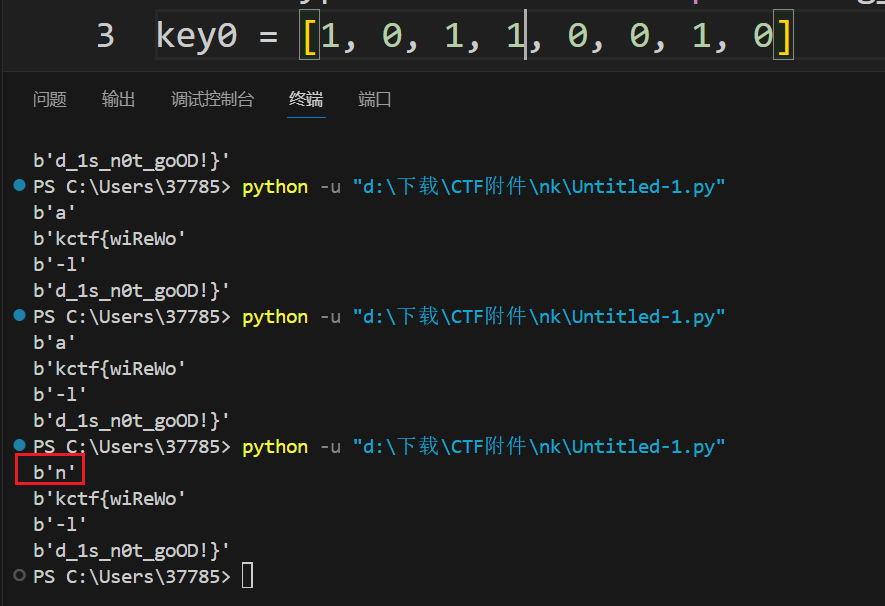
然后第9位一直到断点前面都是连续的,可以得到第二段flag

中间这个位置比较尴尬,这四位右边是断开的,左边是个或,只要有一个满足1就能激活

中间四位排列组合一下就能凑出有意义字符
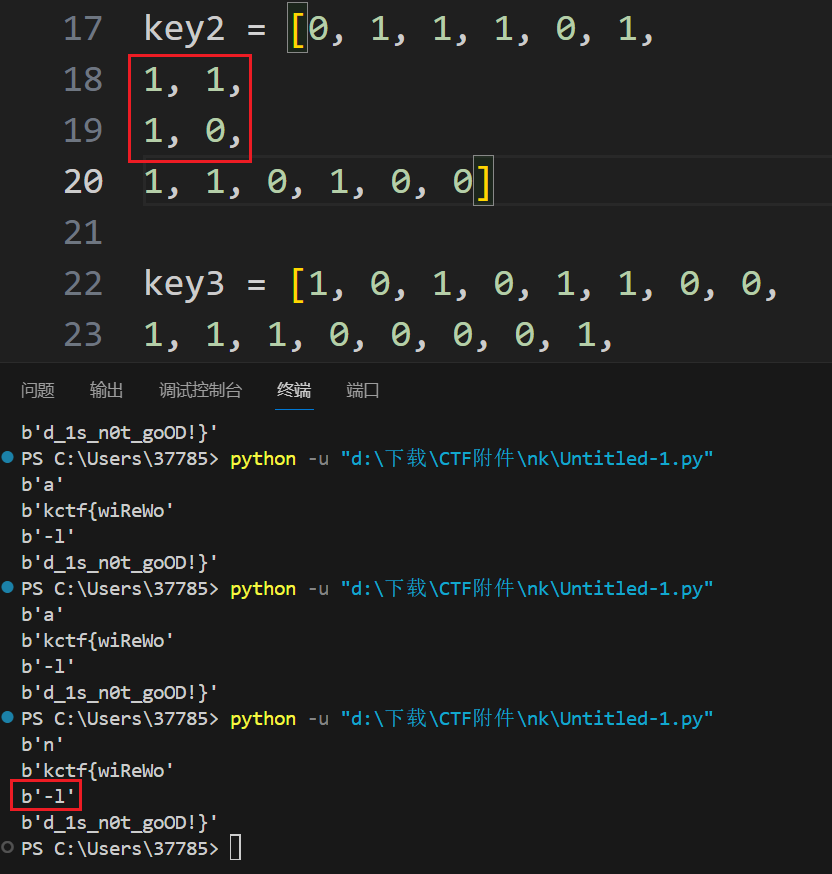
剩下的直接输入
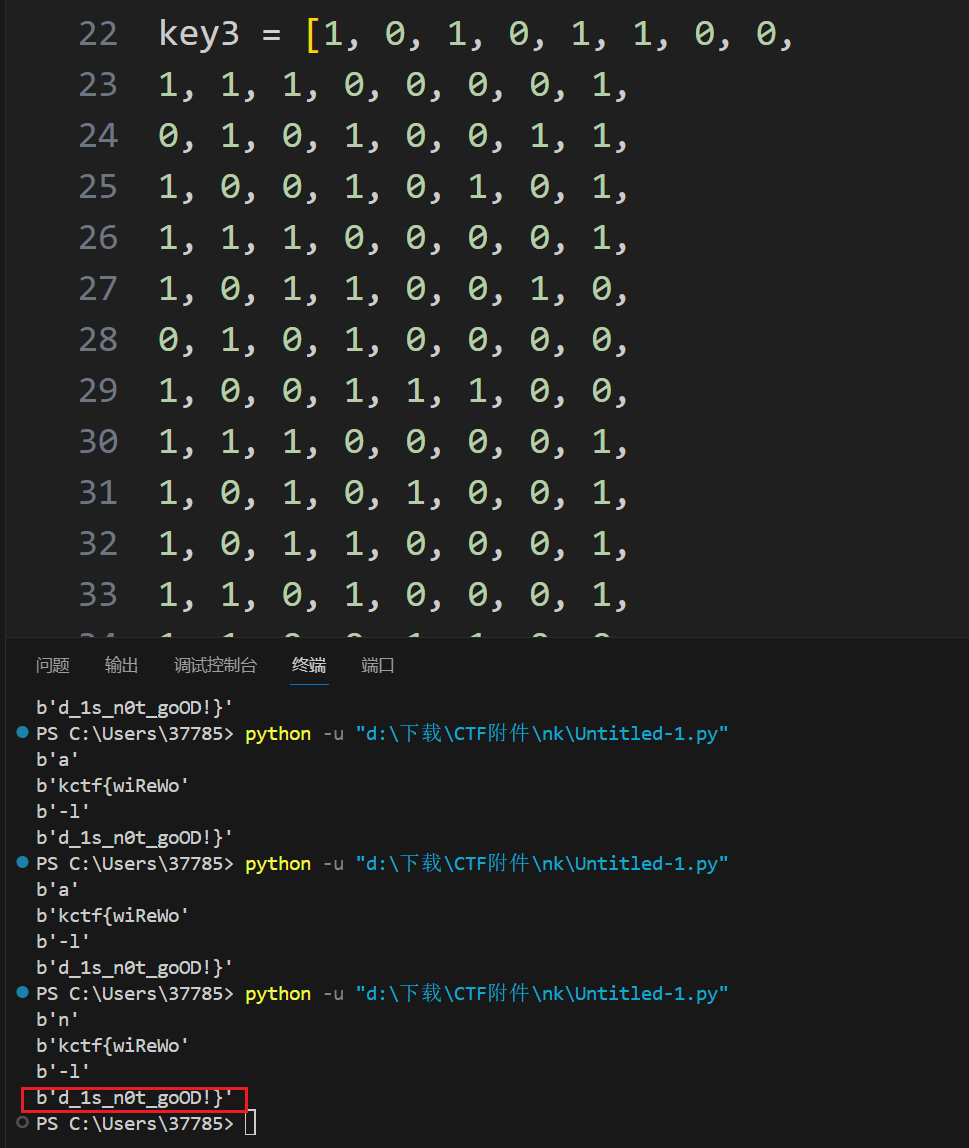
就可以得到完整的flag了
#VM?VM!
from Crypto.Util.number import long_to_bytes
key0 = [1, 0, 1, 1, 0, 0, 1, 0]
key1 = [1, 0, 1, 1, 1, 1, 0, 1,
1, 0, 1, 0, 0, 1, 0, 1,
1, 0, 0, 1, 1, 1, 0, 0,
1, 0, 1, 0, 1, 0, 1, 0,
1, 0, 0, 0, 1, 1, 0, 1,
1, 0, 0, 1, 1, 0, 0, 1,
1, 0, 1, 1, 1, 0, 1, 1,
1, 1, 1, 1, 0, 1, 1, 0,
1, 0, 1, 0, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 0, 1,
1, 0, 1, 1, 0, 0, 0, 1]
key2 = [0, 1, 1, 1, 0, 1,
1, 1,
1, 0,
1, 1, 0, 1, 0, 0]
key3 = [1, 0, 1, 0, 1, 1, 0, 0,
1, 1, 1, 0, 0, 0, 0, 1,
0, 1, 0, 1, 0, 0, 1, 1,
1, 0, 0, 1, 0, 1, 0, 1,
1, 1, 1, 0, 0, 0, 0, 1,
1, 0, 1, 1, 0, 0, 1, 0,
0, 1, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 1, 1, 0, 0,
1, 1, 1, 0, 0, 0, 0, 1,
1, 0, 1, 0, 1, 0, 0, 1,
1, 0, 1, 1, 0, 0, 0, 1,
1, 1, 0, 1, 0, 0, 0, 1,
1, 1, 0, 0, 1, 1, 0, 0,
0, 1, 1, 0, 0, 0, 1, 1,
1, 0, 0, 0, 0, 1, 1, 0]
def decode(key):
key_string = long_to_bytes(int("".join([str(i) for i in key]), 2))
#print(key_string)
res = [0]
for i in range(len(key)-1):
tmp = res[i]^key[i]
res.append(tmp)
#print(res)
flag = long_to_bytes(int("".join([str(i) for i in res]), 2))
print(flag)
decode(key0)
decode(key1)
decode(key2)
decode(key3)