随着时代发展,电脑的核心数慢慢增多,在开发程序的过程中,是否选择使用多线程这是个比较大的问题,下面我通过一个程序去深入理解多线程对程序速度的影响到底有多大
计算亿级别个数的累加和:
单线程模型运行程序:
首先先生成随机数:
int rand(int *array)
{
for(long long i=0;i<N;i++)
{
array[i] = rand()%100;
}
}最简单版本的计算方法,直接在main函数里面去循环调用:
#include<iostream>
#include<time.h>
#define N 500000000
#define THREAD_NUM 15
int rand(int *array)
{
for(long long i=0;i<N;i++)
{
array[i] = rand()%100;
}
}
int main()
{
srand((unsigned)time(NULL));
int* array = new int[N];
rand(array);
clock_t start, finish;
double duration;
long long sum = 0;
start = clock();
for (int i = 0; i < N; ++i) {
sum += array[i];
}
finish = clock();
duration = (double)(finish - start) / CLOCKS_PER_SEC;
printf( "%f seconds\n", duration );
delete [] array;
printf("sum:%lld\n", sum);
}求出计算时间:
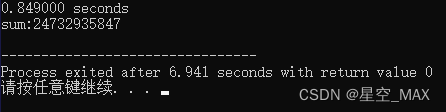
统计时间为:0.849000秒
多线程模型拆分计算:
然后就要用到多线程模型来计算,将500000000个数字进行拆分,拆成N份,然后在N的线程中分别求和,最后再累计它们的和:
这里要用到pthread库去完成计算:
首先建立线程池:
pthread_t threads[THREAD_NUM];建立结构体向线程中传入参数,这里注意,我们用的利用pthread的pthread_create函数去创建线程
struct Result
{
int *array;
long long start;
long long length;
long long result;
int index;
};array为要传入的数组,start和length为要计算的位置和需要计算的长度,最后result为要传回的值,index代表当前的线程号
pthread_create函数的第四个参数为向线程函数传入的参数,只能有一个参数,所以我们利用结构体去把四个参数传入到第四个参数内,并且根据线程数去依次创建线程:
for(int i=0;i<THREAD_NUM;i++)
{
result[i].array=array; // +i*N/THREAD_NUM;
result[i].start = i * length;
result[i].length = length;
result[i].result = 0;
result[i].index = i;
pthread_create(&threads[i],NULL,func,(void*)(&result[i]));
}
然后建立要执行的单线程函数:
void *func(void *result)
{
if (nullptr == result) {
return nullptr;
}
Result* source = static_cast<Result*>(result);
const long long end = source->start + source->length;
long long sum = 0;
const int *array = source->array;
for(long long i = source->start; i < end; ++i)
{
sum += array[i];
}
source->result = sum;
return nullptr;
}整体多线程全程序代码如下:
#include<iostream>
#include<time.h>
#include<pthread.h>
#define N 500000000
#define THREAD_NUM 1
struct Result
{
int *array;
long long start;
long long length;
long long result;
int index;
};
int rand(int *array)
{
for(long long i=0;i<N;i++)
{
array[i] = rand()%100;
}
}
void *func(void *result)
{
if (nullptr == result) {
return nullptr;
}
Result* source = static_cast<Result*>(result);
const long long end = source->start + source->length;
long long sum = 0;
const int *array = source->array;
for(long long i = source->start; i < end; ++i)
{
sum += array[i];
}
source->result = sum;
return nullptr;
}
int main()
{
srand((unsigned)time(NULL));
int* array = new int[N];
rand(array);
Result result[THREAD_NUM];
pthread_t threads[THREAD_NUM];
long long length = N/THREAD_NUM;
clock_t start, finish;
double duration;
start = clock();
for(int i=0;i<THREAD_NUM;i++)
{
result[i].array=array;
result[i].start = i * length;
result[i].length = length;
result[i].result = 0;
result[i].index = i;
pthread_create(&threads[i],NULL,func,(void*)(&result[i]));
}
for(long long i=0;i<THREAD_NUM;i++)
{
long long ret = pthread_join(threads[i],NULL);
}
long long sum = 0;
for (long long i = 0; i < THREAD_NUM; ++i) {
sum += result[i].result;
}
finish = clock();
duration = (double)(finish - start) / CLOCKS_PER_SEC;
printf( "%f seconds\n", duration );
delete [] array;
printf("sum:%lld\n", sum);
}其中宏定义如下:
#define N 500000000
#define THREAD_NUM 1其中N代表本次要处理的数据, THREAD_NUM代表要拆分的线程数
先运行一个线程的时候,求得运算时间:

时间为1.013000秒
将宏定义改为如下:
#define N 500000000
#define THREAD_NUM 2将计算拆分成两个线程来求得运行时间:

可以发现运行时间为0.510000秒,比单线程整整少了一半的时间
接着将计算拆分成四线程:
#define N 500000000
#define THREAD_NUM 4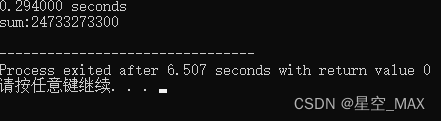
运行时间变为了0.294000秒!
接着尝试将计算拆分为了更多线程,然后得到下表:
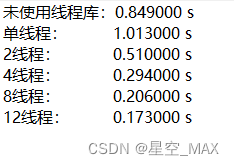
由于我的电脑CPU为12线程的,所以统计到12线程,可以发现使用了多线程加速计算后,程序效率大大提升
但是当线程突破CPU最大线程限制之后会怎么样呢,我们接着完善这个表:
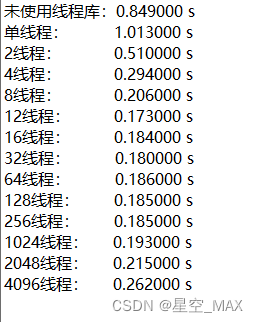
可以发现随着线程数量的增大,计算效率反而降低了,这是什么原因造成的呢?
上下文切换:
当每一个线程分配到CPU的一个逻辑处理单元处理的时候,每个线程都能充分计算,但是线程大于逻辑处理单元的时候,基于要有两个线程去共享一个逻辑单元
在线程切换的时候,会保存上一个线程的现场,加载下一个线程的状态,这一过程叫上下文切换,频繁切换这个过程开销不小,所以线程越多,切换越频繁,反而程序效率会更低了
多线程的最大效率:
根据以上数据可以发现:
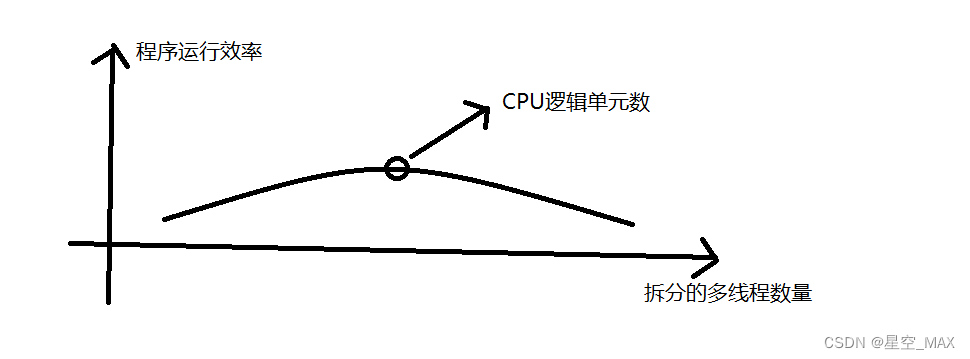
当线程数量接近于CPU核心数量的时候,程序的运行效率最大
优化的坑:
在拆分多线程函数的时候,如果处理不好,反而造成的资源浪费更大:
我举个例子:
在同样8线程的条件下:
线程函数这么写:
void *func(void *result)
{
if (nullptr == result) {
return nullptr;
}
Result* source = static_cast<Result*>(result);
const long long end = source->start + source->length;
long long sum = 0;
const int *array = source->array;
for(long long i = source->start; i < end; ++i)
{
sum += array[i];
}
source->result = sum;
return nullptr;
}
运行时间如下:
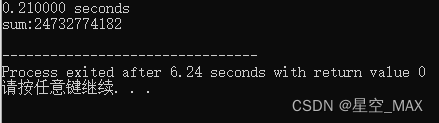
但是当写成如下格式的时候:
void *func(void *result)
{
if (nullptr == result) {
return nullptr;
}
Result* source = static_cast<Result*>(result);
const long long end = source->start + source->length;
long long sum = 0;
const int *array = source->array;
for(long long i = source->start; i < end; ++i)
{
source->result += array[i];
}
return nullptr;
}运行时间为:

仅仅把
for(long long i = source->start; i < end; ++i)
{
sum += array[i];
}
source->result = sum; 改为:
for(long long i = source->start; i < end; ++i)
{
source->result += array[i];
}运行效率大大降低
可以看前者和后者的汇编代码:
前者

后者:
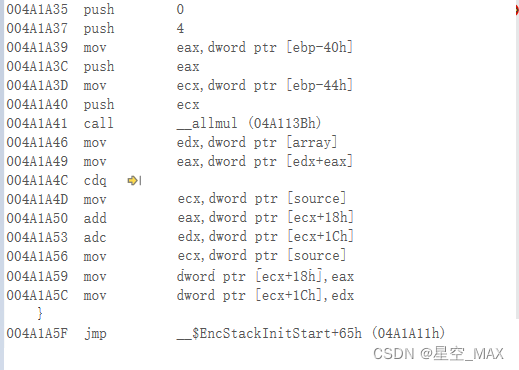
主要是后者比前者多了几次寻址操作
可见多线程如果使用不当的情况下,还不如使用单线程
完整测试程序:
#include<iostream>
#include<time.h>
#include<pthread.h>
#define N 500000000
#define THREAD_NUM 4
struct Result
{
int *array;
long long start;
long long length;
long long result;
int index;
};
int rand(int *array)
{
for(long long i=0;i<N;i++)
{
array[i] = rand()%100;
}
}
void *func(void *result)
{
if (nullptr == result) {
return nullptr;
}
Result* source = static_cast<Result*>(result);
const long long end = source->start + source->length;
long long sum = 0;
const int *array = source->array;
for(long long i = source->start; i < end; ++i)
{
sum += array[i];
//((Result*)result)->result+=(((Result*)result)->array)[N/THREAD_NUM];
}
source->result = sum;
return nullptr;
}
int main()
{
srand((unsigned)time(NULL));
int* array = new int[N];
rand(array);
#if 1
Result result[THREAD_NUM];
pthread_t threads[THREAD_NUM];
long long length = N/THREAD_NUM;
clock_t start, finish;
double duration;
start = clock();
for(int i=0;i<THREAD_NUM;i++)
{
result[i].array=array; // +i*N/THREAD_NUM;
result[i].start = i * length;
result[i].length = length;
result[i].result = 0;
result[i].index = i;
pthread_create(&threads[i],NULL,func,(void*)(&result[i]));
}
for(long long i=0;i<THREAD_NUM;i++)
{
//void* resout = nullptr;
long long ret = pthread_join(threads[i],NULL);
printf("%d\n",result[i].result);
}
long long sum = 0;
for (long long i = 0; i < THREAD_NUM; ++i) {
sum += result[i].result;
}
finish = clock();
duration = (double)(finish - start) / CLOCKS_PER_SEC;
printf( "%f seconds\n", duration );
#else
clock_t start, finish;
double duration;
start = clock();
long long sum = 0;
for (int i = 0; i < N; ++i) {
sum += array[i];
}
finish = clock();
duration = (double)(finish - start)
printf( "%f seconds\n", duration );
#endif
delete [] array;
printf("sum:%lld\n", sum);
}