一、下载训练集
导包
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
ToTensor()函数:
把图像[heigh x width x channels] 转换为 [channels x height x width]

Normalize() 数据标准化函数:
最后一行是标准化数值计算公式

transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)参数解释:
root='./data':数据集下载的路径,我下载到当前目录下的data文件夹,下载完成后会自动创建
train=True:当前为训练集
download=True:下载数据集时设置为True,下载完成后改为False
transform=transform :设置对图像进行预处理的函数
运行下载数据集结果为:

下载完成后生成了data文件夹

二、导入训练集
# 导入训练集
trainloader = torch.utils.data.DataLoader(trainset, batch_size=36,
shuffle=True, num_workers=0)参数解释:
trainset:把刚刚下载的数据导入进来
batch_size=36:一批数据的大小
shuffle=True:训练集中的数据是否打乱(一般默认打乱)
num_workers=0:载入数据的现成数,在lunix操作系统下,可以设置为别的参数,在windows操作系统系统下,默认为0.
三、下载测试集
# 10000张测试图片
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=10000,
shuffle=False, num_workers=0)
test_data_iter = iter(testloader)
test_image, test_lable = test_data_iter.next()
classes = ('plane', 'car', 'bird', 'cat', # 数据集中的分类,设置为元组,不可变类
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')参数解释:
test_data_iter = iter(testloader):通过iter()函数把testloader转化成可迭代的迭代器
test_image, test_lable = test_data_iter.next():通过next()方法可以获得测试的图像和图像对应的标签值。
四、查看导入的图片
在中间过程打印图片进行查看,后续会注释掉
def imshow(img):
img = img / 2 + 0.5
nping = img.numpy()
plt.imshow(np.transpose(nping, (1, 2, 0)))
plt.show()
# print labels
print(' '.join('%5s' % classes[test_lable[j]] for j in range(4)))
# show images
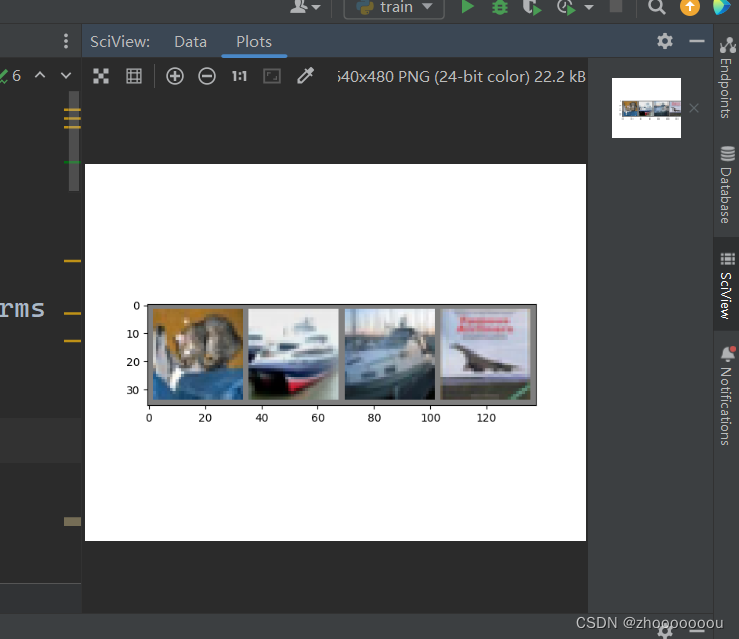
imshow(torchvision.utils.make_grid(test_image))运行结果

图片很模糊,因为像素很低。
上面识别出来的结果都对了。
我遇到的问题:
一开始有结果但是没有图片,我以为时matplotlib的问题,我重新安装并且更新了版本,但是我再运行后报错更多了,报错提示我 AttributeError: module 'numpy' has no attribute 'bool',我就知道是numpy的问题了,我重新安装并且更新了版本结果还是不行,我百度了一下,发现不是越新的版本越好,我重新下载了1.23.2这个版本的numpy,下载完成后运行就出来结果了。
pip install numpy==1.23.2这个也只是中间过程,后续会注释或者删了。
五、将创建的模型实例化
创建模型请看PyTorch搭建LeNet神经网络-CSDN博客
# 将创建的模型实例化
net = LeNet() # 实例化
loss_fuction = nn.CrossEntropyLoss() # 定义损失函数
# 通过优化器将所有可训练的参数都进行训练,lr是learningrate学习率
optimizer = optim.Adam(net.parameters(), lr=0.001)
#通过for循环实现训练过程,循环几次就是将训练集迭代多少次
for epoch in range(5):
running_loss = 0.0 # 用来累加在学习过程中的损失
for step, data in enumerate(trainloader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad() # 历时损失梯度清零。
# forward + backward + optimize
outputs = net(inputs)
loss = loss_fuction(outputs, labels) # 计算神经网络的预测值和真实标签之间的损失
loss.backward()
optimizer.step() # step()函数实现参数更新
# print statistics 打印数据的过程
running_loss += loss.item()
if step % 500 == 499: # 每隔500步打印一次数据的信息
with torch.no_grad(): # 上下文管理器
outputs = net(test_image)
predict_y = torch.max(outputs, dim=1)[1]
accuracy = (predict_y == test_lable).sum().item() / test_lable.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
# 将模型保存到文件夹中
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
详细解释:
比较重点的单独解释了,其他的在注释中。
optimizer.zero_grad() # 历时损失梯度清零。? 为什么每计算一个batch,就要调用一次 optimizer.zero_grad()函数
=> 通过清楚历史梯度,就会对计算的历史梯度进行累加。通过这个特性,能变相的实现一个很大的batch数值的训练(因为batch数值越大,训练效果越好)
with torch.no_grad(): # 上下文管理器上下文管理器: 在接下来的计算过程中,不再去计算每个节点的误差损失梯度。
如果不调用这个函数,将会在测试过程中占用更多的算力,消耗更多的资源和占用更多的内存资源,导致内存容易崩。
print函数中打印参数解释:
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))epoch + 1:迭代到第几轮了
step + 1:某一轮的第几步
running_loss / 500:训练过程中500步平均训练误差
accuracy:准确率
运行结果