【Scrapy】京东商品数据可视化
文章目录
- 【Scrapy】京东商品数据可视化
- 👉引言💎
- 一、爬取数据:
- 1.1 scrapy爬虫库简介:
- 1.2 技术实现:
- 1.2.1搭建框架结构
- 1.2.2 分析网页结构
- 二、数据保存:
- 三、数据读取以及分析:
- 四、数据可视化:
- 五、全部代码
- jd.py
- dealData.py
- items.py
- pipelines
👉引言💎
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。
热爱写作,愿意让自己成为更好的人…
…

| 铭记于心 | ||
|---|---|---|
| 🎉✨🎉我唯一知道的,便是我一无所知🎉✨🎉 |
一、爬取数据:
1.1 scrapy爬虫库简介:
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试.
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 后台也应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫.
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持.
1.2 技术实现:
1.2.1搭建框架结构
首先搭建scrapy库项目,运行如下代码生成代码框架:
scrapy startproject crawler
cmdline.execute('scrapy crawl jd'.split())
spiders文件夹中的py文件即为主要爬虫代码,当获取网页请求后,在该文件的主类中重写parse方法,即请求解析代码。
spiders上级目录下的items文件即为获取到的字段,也就是爬取的属性值,示例如下:
class CrawljingdongItem(scrapy.Item):
id=scrapy.Field()
comment=scrapy.Field()
productName=scrapy.Field()
storeName=scrapy.Field()
address=scrapy.Field()
price=scrapy.Field()
UserComments=scrapy.Field()
pass
1.2.2 分析网页结构
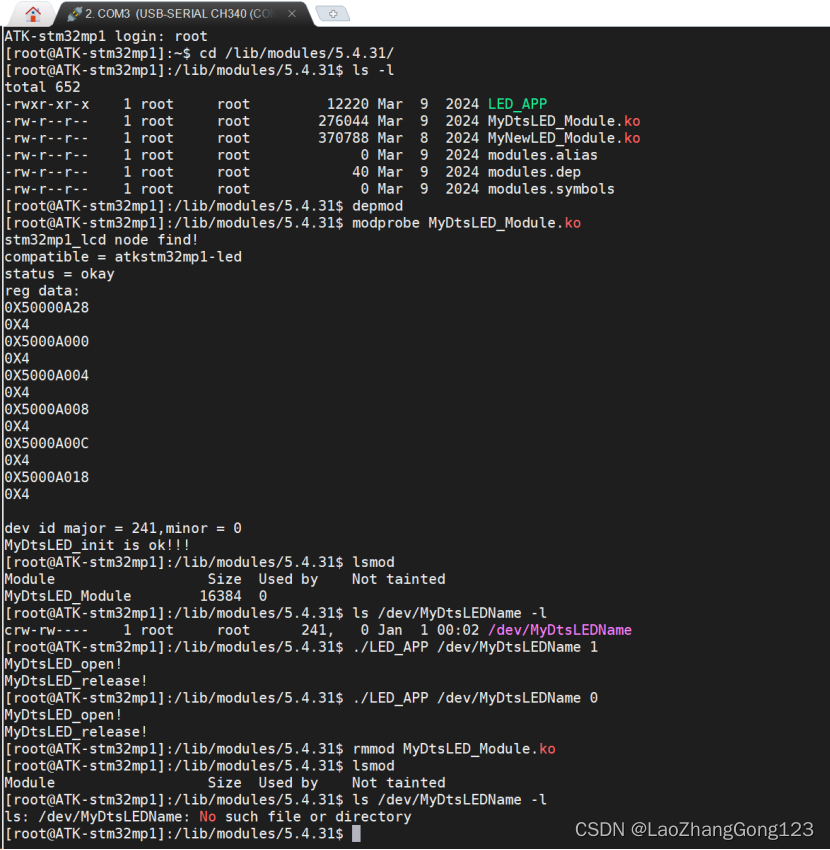
在重写parse请求时,首先需要对网页进行结构分析,这里以京东商品页面进行展示。
首先打开京东界面,得到网址,填入starturls中。然后使用xpath进行HTML的解析,此时可以获取静态页面中的所有内容
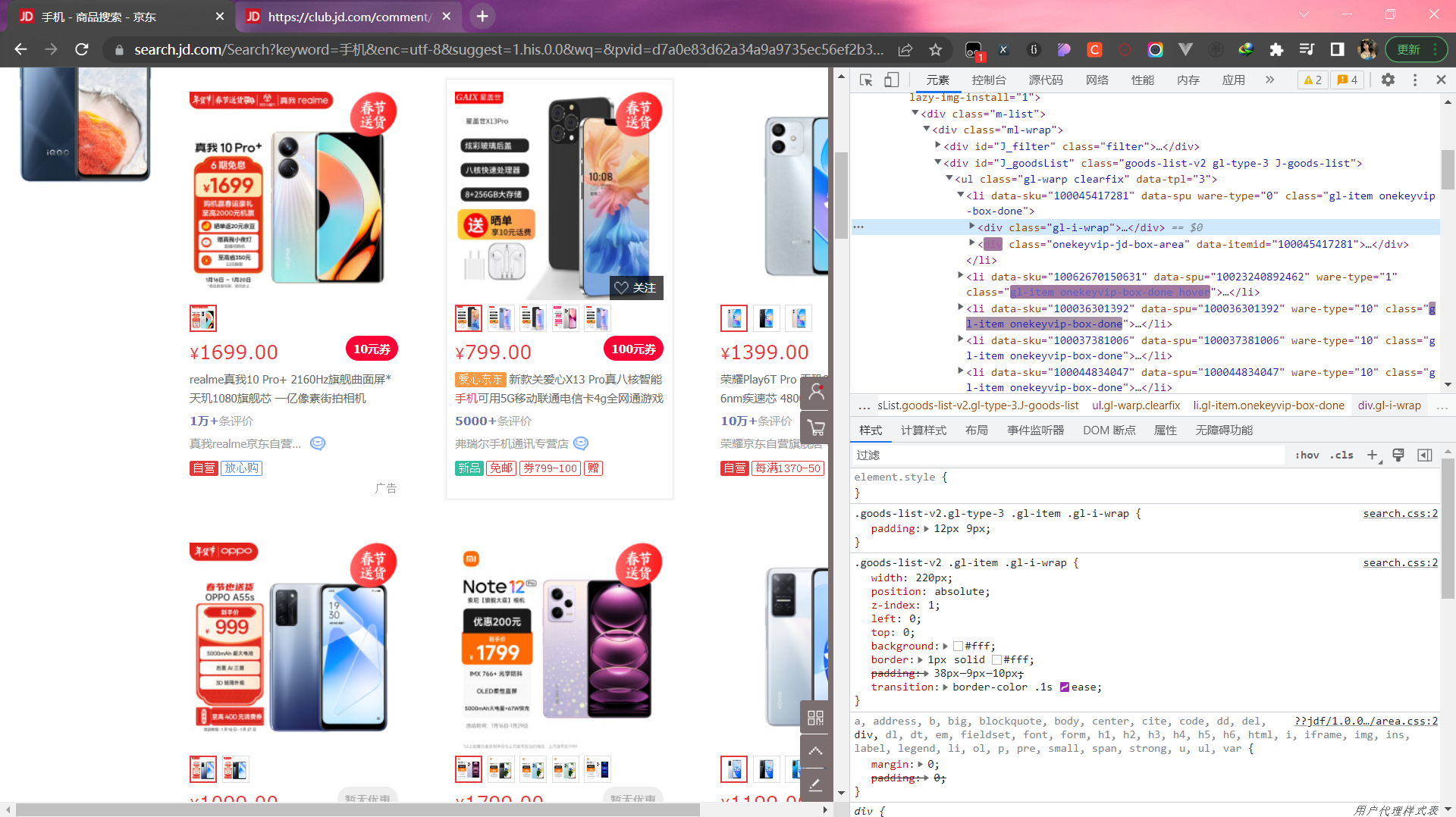
于是使用data = ans_html.xpath("//*[@class='gl-warp clearfix']/li") 可以得到所有的列表标签,可以看到,里面存放了所有的单位商品信息。随后使用for循环遍历每个列表,对商品信息进行单独提取,并使用item类进行存储。
这里需要注意的是,对于评论等数据是无法直接从HTML中提取出来的,因为这些数据通常是基于ajax技术进行异步传输,即滑动时会进行加载(动态加载),所以必须找到保存评论信息的json文件。通过网页检查器,可以发现文件位置,根据该URL使用request库进行请求即可。
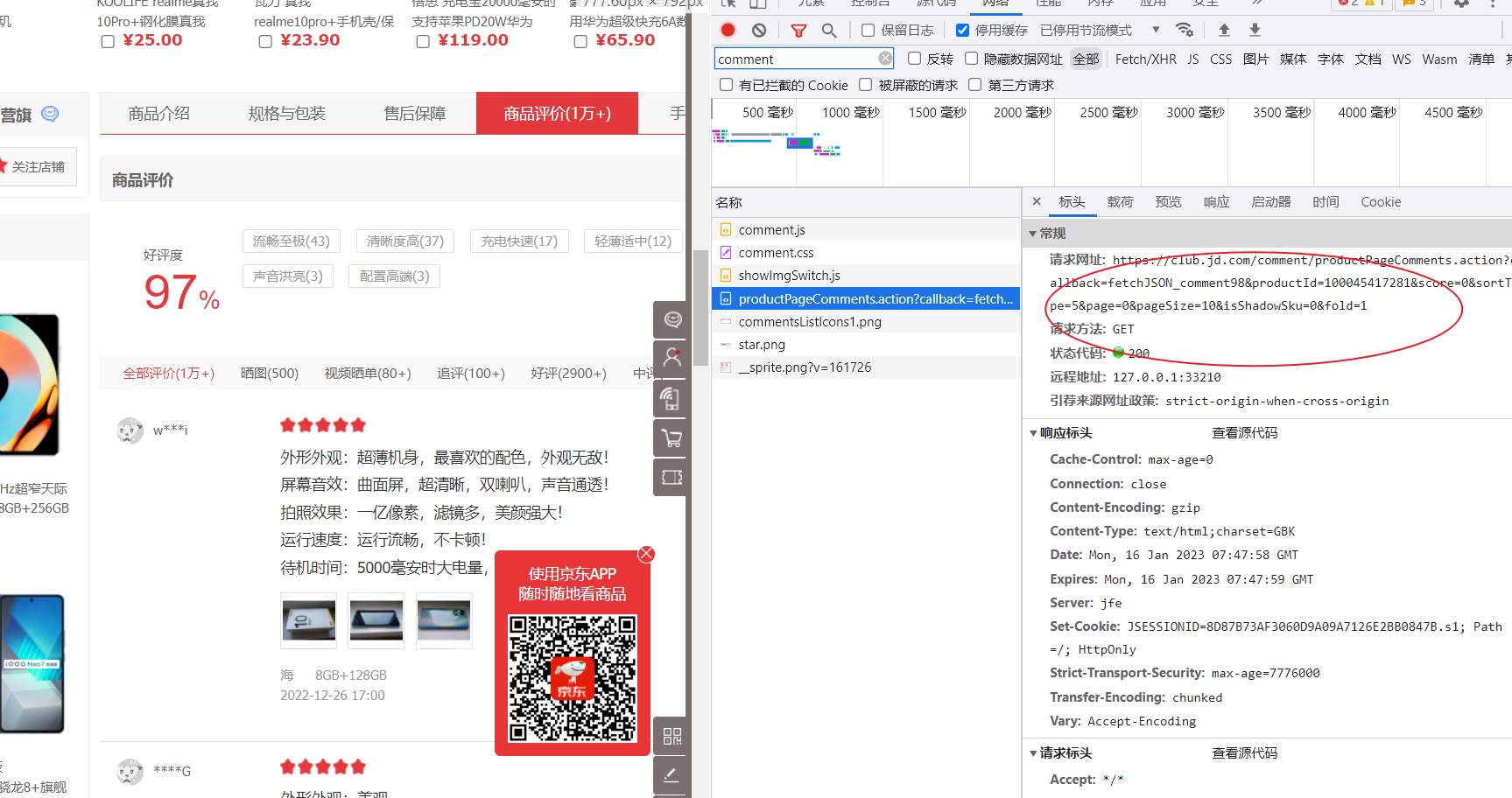
主要逻辑代码完成后,下一步会进入spiders上级目录下的pipelines文件中进行数据的存储级操作,这里使用mysql数据库进行数据的存储。
二、数据保存:
首先需要导入pymsql库,其次进行主要连接属性的配置
def dbHandle(self):
conn = pymysql.connect(
host="localhost",
user="root",
passwd="135157",
charset="utf8",
use_unicode=False
)
return conn
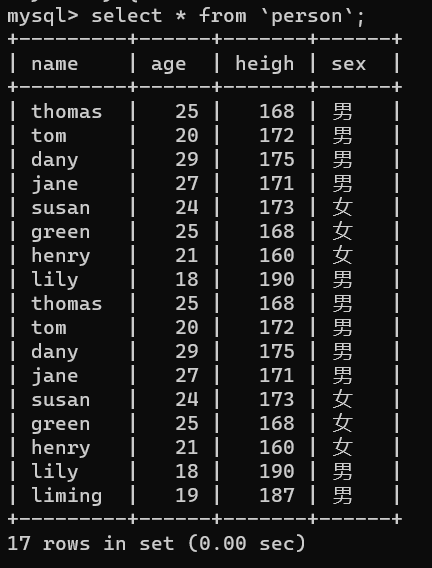
然后根据sql语法,使用pymysql的execute方法将查询语句传入到sql中进行查询,可以看到数据存储如下:
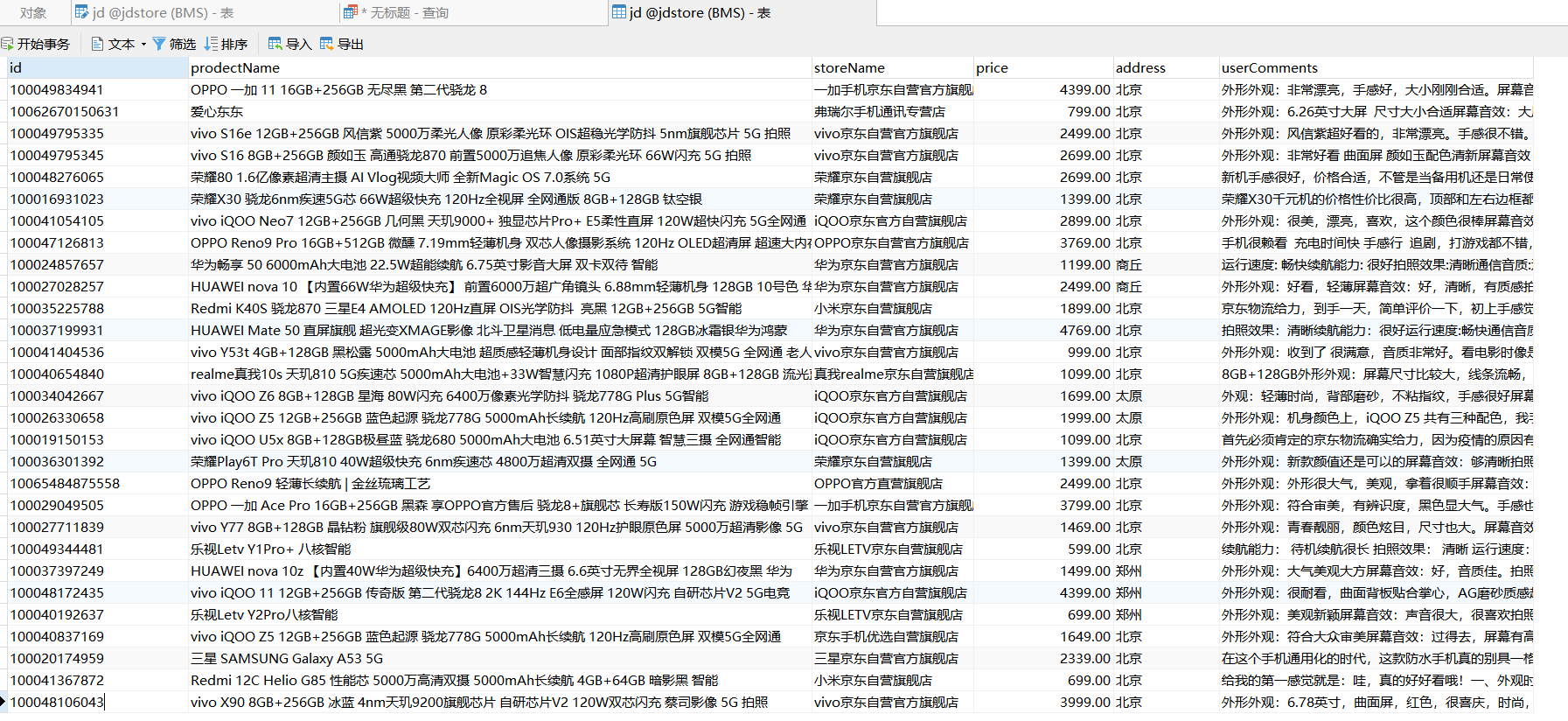
下一步使用pandas库的read_sql_query方法从mysql数据库中读取数据,同时进行分析以及处理。
三、数据读取以及分析:
将数据读取后得到一个DataFrame对象,然后分别进行数据处理,最终得到 商品价格区间的划分,不同价格区间范围内的商品数量,用户的评论集合,商品名称的集合等数据信息,进行下一步数据可视化。
四、数据可视化:
首先使用matplotlib的plot方法进行相关的操作。
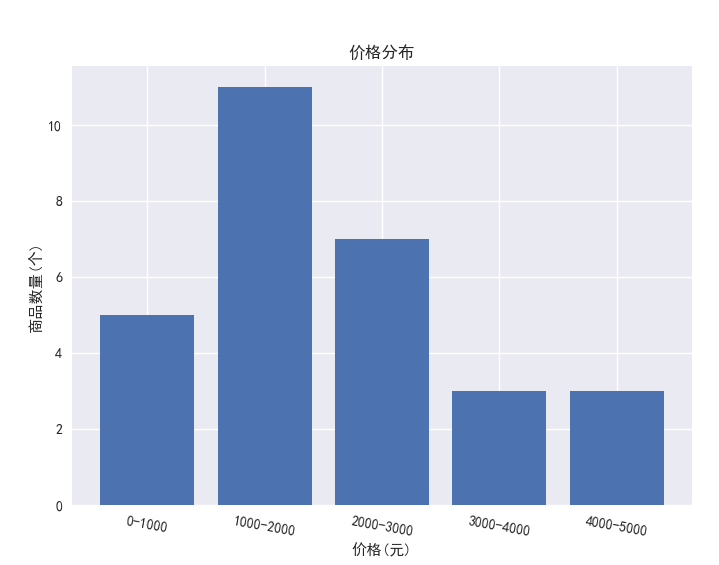
对商品价格区间内的商品数量使用条形图进行可视化:
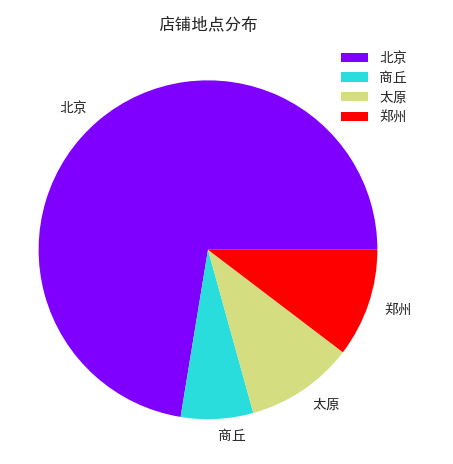
对店铺地址进行统计并使用饼图进行可视化:
将所有评论连接起来成一段文章,使用jieba中文分词库进行关键词提取,然后拼接起来调用WordCloud对象的wc.generate方法生成词云:

将所有商品名称连接起来成一段文章,使用jieba中文分词库进行关键词提取,然后拼接起来调用WordCloud对象的wc.generate方法生成词云:

五、全部代码
jd.py
import re
import sys
import json
import scrapy
from crawlJingDong import items
import requests as rq
from lxml import etree
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'}
class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['jd.com']
start_urls = ['https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&wq=%E6%89%8B%E6%9C%BA']
def parse(self, response):
rep = response.text
ans_html = etree.HTML(rep)
data = ans_html.xpath("//*[@class='gl-warp clearfix']/li")
for it in data:
item = items.CrawljingdongItem()
id = it.attrib["data-sku"]
# e=it.xpath("*[@class='onekeyvip-jd-box-area xh-highlight']")
price = float(it.xpath("./div/div[3]//i//text()")[0])
prodectName = it.xpath("./div/div[4]//em//text()")[0]
comment = it.xpath("./div/div[5]//a/@href")[0]
storeName = it.xpath("./div/div[7]//a/text()")[0]
address = it.xpath("./div/div[9]")[0].attrib["data-province"]
# 变字典
item["id"] = id
item["price"] = price
item["productName"] = prodectName
item["comment"] = comment
item["storeName"] = storeName
item["address"] = address
"""由于评论数据是ajax异步加载的,所以在一开始获取的界面中是无法得到评论数据的,但是根据网页分析可以知道,
评论数据都在js中存放,拿京东来说,找到productPageComments文件,根据url进行获取,就能得到json格式的评论数据
"""
comJson = rq.get(f"https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={id}&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1",
headers= header)
#由于直接得到的text并不是json格式(有jquery这些),所以需要先转换成json(就是字典格式)
str = comJson.text.strip()
loads = json.loads(re.findall('\{.*\}',str)[0])
UserComment=[]
list(map(lambda x:UserComment.append((x['content'])), loads['comments']))
item['UserComments']=UserComment
yield item
dealData.py
import jieba
import jieba.analyse
import pandas as pd
import pymysql as pl
from matplotlib import pyplot as plt
from wordcloud import WordCloud
plt.style.use('seaborn')
plt.rcParams['font.sans-serif'] = 'SimHei'
conn = pl.connect(host='localhost', user='root', password='135157', db='JDstore', port=3306)
query = "SELECT * FROM `jdstore`.`jd` LIMIT 0,1000"
data = pd.read_sql_query(query, conn)
sumDes = data.describe()
print(f'数据信息的描述统计:\n{sumDes}')
# 得到价格区间
end, sta = int(sumDes.loc['max', 'price'] // 1000), int(sumDes.loc['min', 'price'] // 1000)
label = list(map(lambda x: str(x * 1000) + '-' + str((x + 1) * 1000), range(sta, end + 1)))
# 将商品价格划分到区间中
data['pStage'] = data['price'].apply(lambda x: int(x // 1000))
# 对商品价格区间内的商品数量使用条形图进行可视化
dataByP = data.groupby('pStage').count()['prodectName']
plt.bar(range(5),dataByP)
plt.title('价格分布')
plt.xticks(range(5),label,rotation=-10)
plt.yticks( rotation=-10)
plt.xlabel('价格(元)')
plt.ylabel('商品数量(个)')
plt.show(block=True)
# 对店铺地址进行统计并使用饼图进行可视化
dataByA = data.groupby('address').count()['storeName']
dataByA.plot(kind='pie',ylabel='',title='店铺地点分布',legend=True,cmap='rainbow')
plt.show(block=True)
# 将所有评论连接起来成一段文章
comStr = "".join(list(data['prodectName'])).replace('\n', ' ')
# 直接进行关键词分析
wordFlag = jieba.analyse.extract_tags(comStr)
print('\n开始制作词云……') # 提示当前状态
wc = WordCloud(
font_path='C:/Windows/Fonts/SimHei.ttf', # 设置字体(这里选择“仿宋”)
background_color='white', # 背景颜色
# mask=mask, # 文字颜色+形状(有mask参数再设定宽高是无效的)
# max_font_size=150 # 最大字号
)
wc.generate(' '.join(wordFlag))
plt.imshow(wc) # 处理词云
plt.axis('off')
plt.show(block=True)
# 同上,不过操作对象是商品名称
comStr = "".join(list(data['userComments'])).replace('\n', ' ')
# 直接进行关键词分析
wordFlag = jieba.analyse.extract_tags(comStr)
print('\n开始制作词云……') # 提示当前状态
wc = WordCloud(
font_path='C:/Windows/Fonts/SimHei.ttf', # 设置字体(这里选择“仿宋”)
background_color='white', # 背景颜色
# mask=mask, # 文字颜色+形状(有mask参数再设定宽高是无效的)
# max_font_size=150 # 最大字号
)
wc.generate(' '.join(wordFlag)) # 从字典生成词云
plt.imshow(wc) # 处理词云
plt.axis('off')
plt.show(block=True)
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class CrawljingdongItem(scrapy.Item):
id=scrapy.Field()
comment=scrapy.Field()
productName=scrapy.Field()
storeName=scrapy.Field()
address=scrapy.Field()
price=scrapy.Field()
UserComments=scrapy.Field()
pass
pipelines
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
# useful for handling different item types with a single interface
class CrawljingdongPipeline:
# def open_spider(self, spider):
# self.file = open('coments.txt', 'w+')
#
# def close_spider(self, spider):
# self.file.close()
def dbHandle(self):
conn = pymysql.connect(
host="localhost",
user="root",
passwd="135157",
charset="utf8",
use_unicode=False
)
return conn
def process_item(self, item, spider):
dbObject = self.dbHandle()
cursor = dbObject.cursor()
cursor.execute("USE JDstore")
str = '\n'.join(item['UserComments'])
sql = "INSERT INTO jd(`id`, `prodectName`, `storeName`, `price`, `address`, `userComments`) VALUES ('%s','%s','%s',%f,'%s','%s')"
try:
cursor.execute(sql%(item['id'], item['productName'], item['storeName'], item['price'],item['address'],str))
cursor.connection.commit()
except BaseException as e:
print("错误在这里>>>>>>>>>>>>>", e, "<<<<<<<<<<<<<错误在这里")
dbObject.rollback()
return item