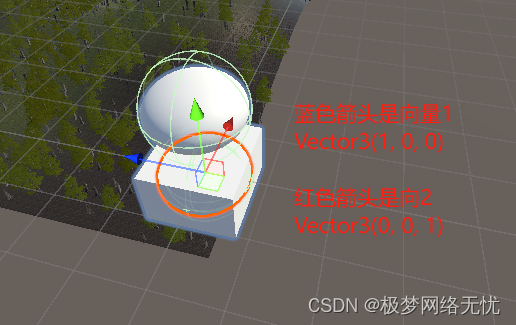
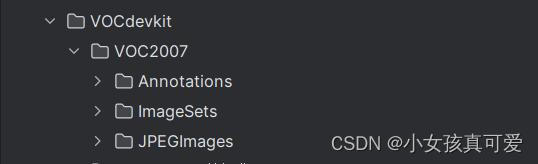
数据集存放格式:(Annotations文件夹放标注的xml文件,JPEGImages文件夹放标注的图片)
运行代码:
import os
import random
import xml.etree.ElementTree as ET
import numpy as np
def get_classes(classes_path):
with open(classes_path, encoding='utf-8') as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names, len(class_names)
annotation_mode = 0
classes_path = ["person", "cat"] # 对应类别名称
trainval_percent = 0.9
train_percent = 0.9
VOCdevkit_path = 'VOCdevkit'
VOCdevkit_sets = [('2007', 'train'), ('2007', 'val')]
classes, _ = get_classes(classes_path)
photo_nums = np.zeros(len(VOCdevkit_sets))
nums = np.zeros(len(classes))
def convert_annotation(year, image_id, list_file):
in_file = open(os.path.join(VOCdevkit_path, 'VOC%s/Annotations/%s.xml' % (year, image_id)), encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = 0
if obj.find('difficult') != None:
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)),
int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
nums[classes.index(cls)] = nums[classes.index(cls)] + 1
if __name__ == "__main__":
random.seed(0)
if " " in os.path.abspath(VOCdevkit_path):
raise ValueError("数据集存放的文件夹路径与图片名称中不可以存在空格,否则会影响正常的模型训练,请注意修改。")
if annotation_mode == 0 or annotation_mode == 1:
print("Generate txt in ImageSets.")
xmlfilepath = os.path.join(VOCdevkit_path, 'VOC2007/Annotations')
saveBasePath = os.path.join(VOCdevkit_path, 'VOC2007/ImageSets/Main')
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("train size", tr)
ftrainval = open(os.path.join(saveBasePath, 'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath, 'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath, 'train.txt'), 'w')
fval = open(os.path.join(saveBasePath, 'val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("Generate txt in ImageSets done.")
if annotation_mode == 0 or annotation_mode == 2:
print("Generate 2007_train.txt and 2007_val.txt for train.")
type_index = 0
for year, image_set in VOCdevkit_sets:
image_ids = open(os.path.join(VOCdevkit_path, 'VOC%s/ImageSets/Main/%s.txt' % (year, image_set)),
encoding='utf-8').read().strip().split()
list_file = open('%s_%s.txt' % (year, image_set), 'w', encoding='utf-8')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg' % (os.path.abspath(VOCdevkit_path), year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
photo_nums[type_index] = len(image_ids)
type_index += 1
list_file.close()
print("Generate 2007_train.txt and 2007_val.txt for train done.")
def printTable(List1, List2):
for i in range(len(List1[0])):
print("|", end=' ')
for j in range(len(List1)):
print(List1[j][i].rjust(int(List2[j])), end=' ')
print("|", end=' ')
print()
str_nums = [str(int(x)) for x in nums]
tableData = [
classes, str_nums
]
colWidths = [0] * len(tableData)
len1 = 0
for i in range(len(tableData)):
for j in range(len(tableData[i])):
if len(tableData[i][j]) > colWidths[i]:
colWidths[i] = len(tableData[i][j])
printTable(tableData, colWidths)
if photo_nums[0] <= 500:
print("训练集数量小于500,属于较小的数据量,请注意设置较大的训练世代(Epoch)以满足足够的梯度下降次数(Step)。")
if np.sum(nums) == 0:
print(
"在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")
print(
"在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")
print(
"在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")
print("(重要的事情说三遍)。")
生成的txt文件格式: