这里写目录标题
- 一. 需求分析
- 二. 从日志中抽取出指定字段,并切分为若干个子文件
- 三. 生成查询执行计划
- 四. 生成查询的SQL语句
- 五. 检查并执行
一. 需求分析
有如下日志文件,假设日志文件中有10000条数据,要求将全部的TRANSACTIONID抽取出来,进行查询。
- 可以使用
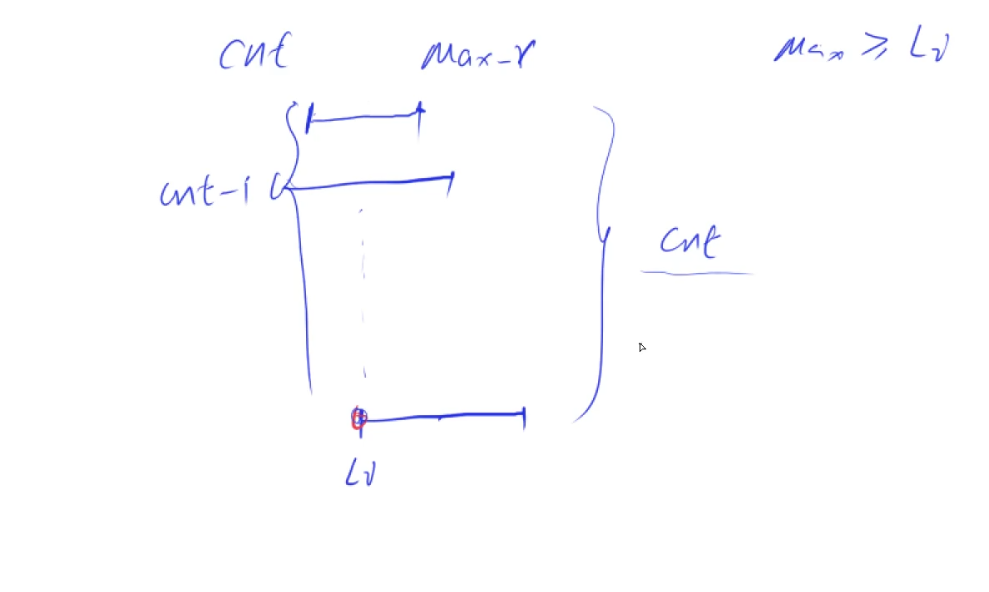
grep -o将全部的TRANSACTIONID获取到,然后使用WHERE 字段名 IN()的方式来获取。 - 但是在SQL中,如果
IN()条件内的元素过多,会导致查询失败,一般最多为800个左右。 - 我们可以将查询到的TRANSACTIONID分为若干个子文件,每个子文件内有800个元素,然后在通过Linux命令生成若干个SELECT语句,然后放到一个
.sql文件中,最后通过SQL的命令行工具执行.sql语句,然后进行查询。
📄info.log
...省略若干条...
no=112 TRANSACTIONID=^ad342Uh result=2
no=345 TRANSACTIONID=tkafsjhg result=1
no=324 TRANSACTIONID=(eorg9er result=2
no=455 TRANSACTIONID=&woeihrd result=2
no=156 TRANSACTIONID=#woeif09 result=1
no=087 TRANSACTIONID=98IHzkje result=2
...省略若干条...
二. 从日志中抽取出指定字段,并切分为若干个子文件
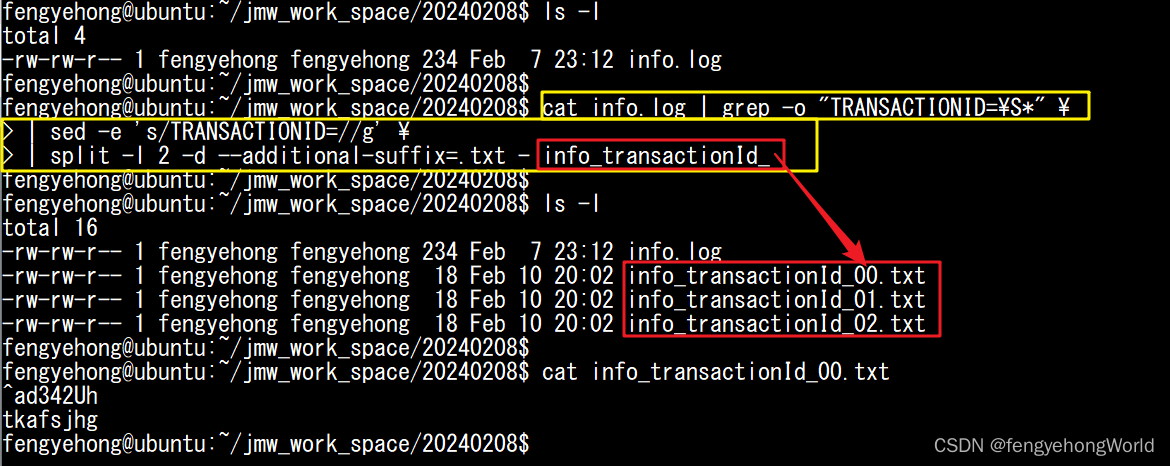
grep -o "TRANSACTIONID=\S*":只把TRANSACTIONID字段抽取出来sed -e 's/TRANSACTIONID=//g':把TRANSACTIONID去掉,只留下值split -l 2 -d --additional-suffix=.txt - info_transactionId_:-l 2:表示将文件按照行分割, 每个分割出来的文件最多包含2行-d:表示使用数字作为分割后的文件名后缀,而不是默认的字母后缀--additional-suffix=.txt:指定切分后的文件名的后缀-:表示从标准输入读取数据,充当占位符,表示从管道传递来的数据info_transactionId_:表示切分后生成文件名的规则
\: 连接符,当命令行折行不在一行上的时候用\来连接
cat info.log | grep -o "TRANSACTIONID=\S*" \
| sed -e 's/TRANSACTIONID=//g' \
| split -l 2 -d --additional-suffix=.txt - info_transactionId_
三. 生成查询执行计划
-
sed "s/$/'/; s/^/'/; s/$/,/;s/$/'/;:对每一行的行尾($ 表示行尾)进行替换操作,将每行的行尾(即每行的最后一个字符)替换为单引号 。s/^/'/;:对每一行的行首(^ 表示行首)进行替换操作,将每行的行首(即每行的第一个字符)替换为单引号 。s/$/,/;:对每一行的行尾($ 表示行尾)进行替换操作,将每行的行尾(即每行的最后一个字符)替换为逗号 。
-
1s/^/EXPLAIN PLAN FOR SELECT ...:对文本的第一行进行操作,在其首行(^ 表示行首)插入指定的内容 -
sed '$ s/.$/);/':在文本的最后一行的末尾删除最后一个字符,并添加上);.表示最后一个字符$表示行尾
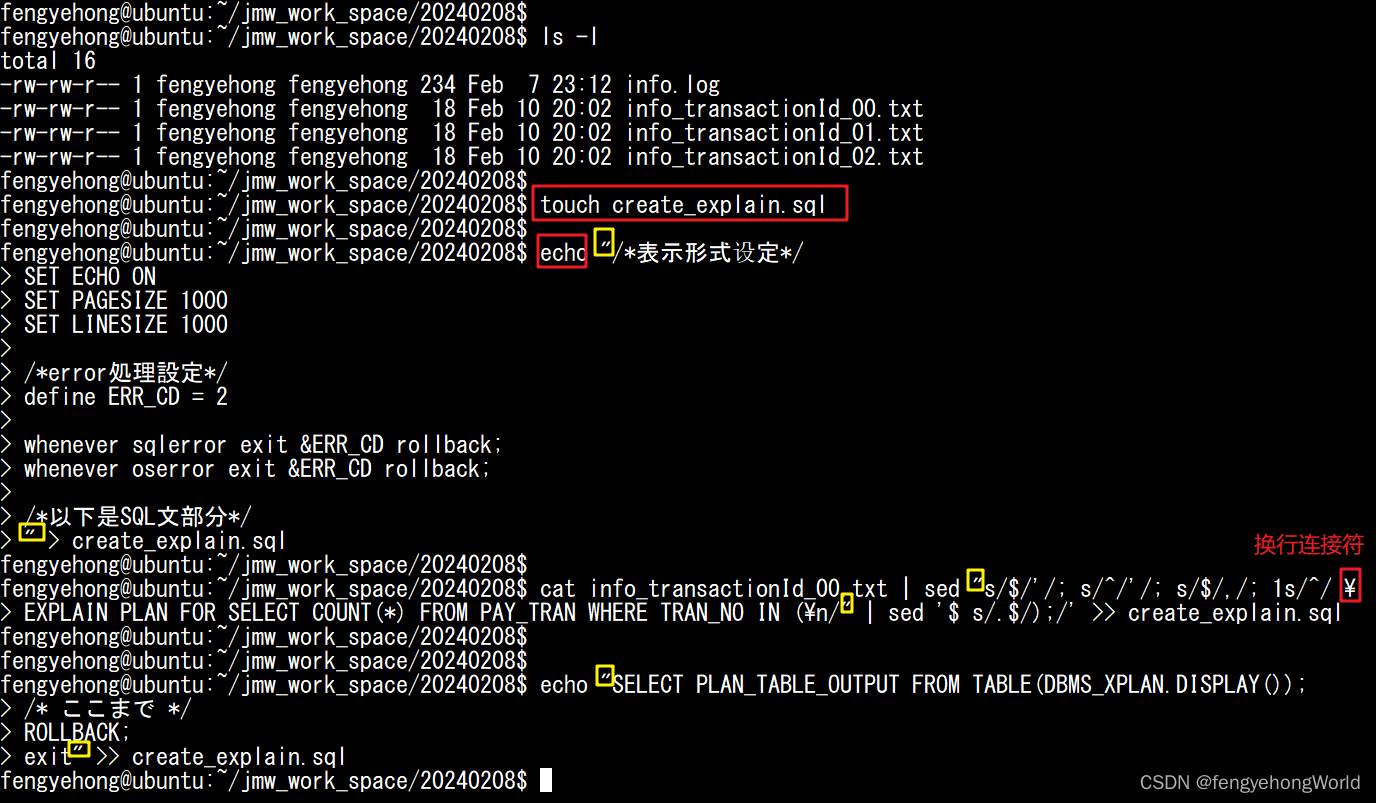
# 创建存放查询执行计划的sql文件
touch create_explain.sql
# 通过 echo 命令将sql写入文本文件
echo "/*表示形式设定*/
SET ECHO ON
SET PAGESIZE 1000
SET LINESIZE 1000
/*error処理設定*/
define ERR_CD = 2
whenever sqlerror exit &ERR_CD rollback;
whenever oserror exit &ERR_CD rollback;
/*以下是SQL文部分*/
" > create_explain.sql
# 读取transactionId文本内容,生成查询计划的SQL,写入文件
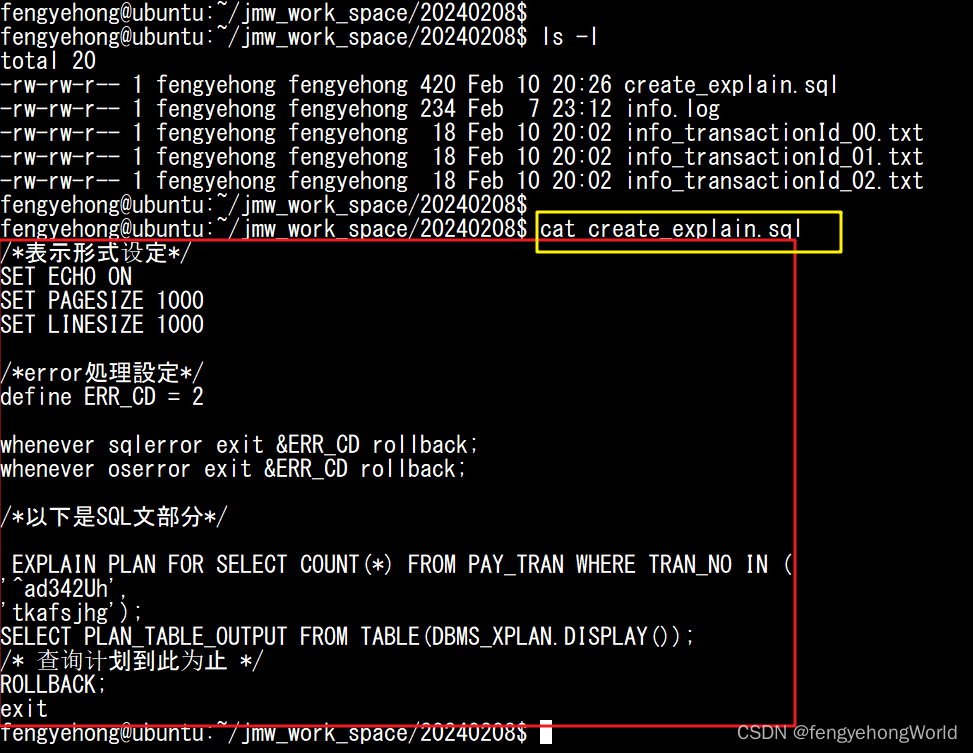
cat info_transactionId_00.txt | sed "s/$/'/; s/^/'/; s/$/,/; 1s/^/ \
EXPLAIN PLAN FOR SELECT COUNT(*) FROM PAY_TRAN WHERE TRAN_NO IN (\n/" | sed '$ s/.$/);/' >> create_explain.sql
echo "SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());
/* 查询计划到此为止 */
ROLLBACK;
exit" >> create_explain.sql
四. 生成查询的SQL语句
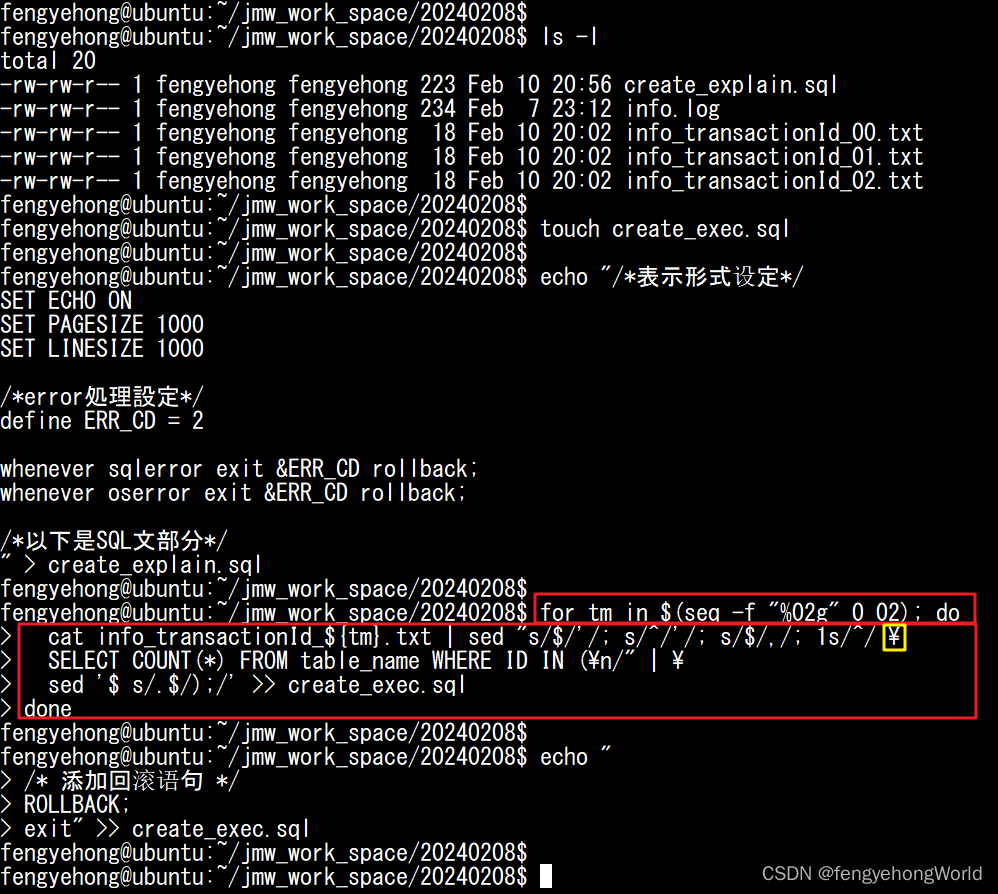
seq -f "%02g" 0 02:使用seq工具生成0到2的数字序列,%02g用来指定输出格式的选项,表示输出的数字用两位数的形式表示。for tm in $(seq -f "%02g" 0 02); do cat info_transactionId_${tm} | .....:依次打开切分后的所有info_transactionId_文件,将transactionId写入收到SQL的IN条件中。
# 创建查询SQL文件
touch create_exec.sql
echo "/*表示形式设定*/
SET ECHO ON
SET PAGESIZE 1000
SET LINESIZE 1000
/*error処理設定*/
define ERR_CD = 2
whenever sqlerror exit &ERR_CD rollback;
whenever oserror exit &ERR_CD rollback;
/*以下是SQL文部分*/
" > create_explain.sql
# 折行式写法
for tm in $(seq -f "%02g" 0 分隔后的文件的最大的ID); do
cat info_transactionId_${tm}.txt | sed "s/$/'/; s/^/'/; s/$/,/; 1s/^/ \
SELECT COUNT(*) FROM table_name WHERE ID IN (\n/" | \
sed '$ s/.$/);/' >> create_exec.sql
done
# 非折行式写法,在本案例中分隔后的文件的最大的ID为 02
for tm in $(seq -f "%02g" 0 02); do
cat info_transactionId_${tm}.txt | sed "s/$/'/; s/^/'/; s/$/,/; 1s/^/SELECT COUNT(*) FROM table_name WHERE ID IN (\n/" | sed '$ s/.$/);/' >> create_exec.sql
done
echo "
/* 添加回滚语句 */
ROLLBACK;
exit" >> create_exec.sql

五. 检查并执行
这个命令使用了 SQL*Plus 工具来执行一个 SQL 脚本,并将执行结果输出到名为 result.log 的日志文件中。
- 本案例中的数据库是ORACLE
sqlplus:启动 SQL*Plus 工具ccuser/cc_user01@C2RDU1_CCPDB2:连接到 Oracle 数据库的凭据信息- ccuser:用户名
- cc_user01:密码
- C2RDU1_CCPDB2:要连接到的数据库
# 检查生成的SQL文,理论上生成的SQL没有错的话,grep文检索不到任何信息
grep $'\t' /sql文所在路径/*.sql
grep ' ' /sql文所在路径/*.sql
# 执行sql
sqlplus ccuser/cc_user01@C2RDU1_CCPDB2 @create_exec.sql > result.log