6、Kafka同步到Hive
6.1 建映射表
通过flink sql client 建Kafka topic的映射表
CREATE TABLE kafka_user_topic(
id int,
name string,
birth string,
gender string
) WITH (
'connector' = 'kafka',
'topic' = 'flink-cdc-user',
'properties.bootstrap.servers' = '192.168.0.4:6668',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);6.2 建hive表
建hive表
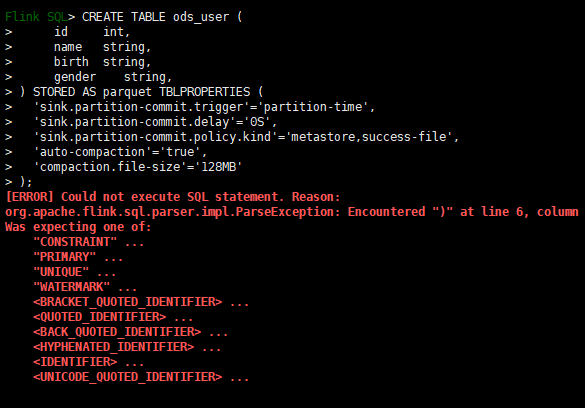
CREATE TABLE ods_user (
id int,
name string,
birth string,
gender string
) STORED AS parquet TBLPROPERTIES (
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='0S',
'sink.partition-commit.policy.kind'='metastore,success-file',
'auto-compaction'='true',
'compaction.file-size'='128MB'
);如果没有切换hive方言建hive表会报错
切换Hive方言
SET table.sql-dialect=hive;hive表
CREATE TABLE ods_user (
id int,
name string,
birth string,
gender string
) STORED AS parquet TBLPROPERTIES (
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='0S',
'sink.partition-commit.policy.kind'='metastore,success-file',
'auto-compaction'='true',
'compaction.file-size'='128MB'
);
6.3 生成作业
生成数据
insert into ods_user
select * from kafka_user_topic;
系列文章
Fink CDC数据同步(一)环境部署![]() https://blog.csdn.net/weixin_44586883/article/details/136017355?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_44586883/article/details/136017355?spm=1001.2014.3001.5502
Fink CDC数据同步(二)MySQL数据同步![]() https://blog.csdn.net/weixin_44586883/article/details/136017472?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136017472?spm=1001.2014.3001.5501
Fink CDC数据同步(三)Flink集成Hive![]() https://blog.csdn.net/weixin_44586883/article/details/136017571?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136017571?spm=1001.2014.3001.5501
Fink CDC数据同步(四)Mysql数据同步到Kafka![]() https://blog.csdn.net/weixin_44586883/article/details/136023747?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136023747?spm=1001.2014.3001.5501
Fink CDC数据同步(五)Kafka数据同步Hive![]() https://blog.csdn.net/weixin_44586883/article/details/136023837?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136023837?spm=1001.2014.3001.5501
Fink CDC数据同步(六)数据入湖Hudi![]() https://blog.csdn.net/weixin_44586883/article/details/136023939?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_44586883/article/details/136023939?spm=1001.2014.3001.5502