Flink版本:flink1.14
最近有【FULL OUTER JOIN】场景的实时数据开发需求,想要的结果是,左右表来了数据都下发数据;左表存在的数据,右表进来可以关联下发(同样,右表存在的数据,左表进来也可以关联下发)。但在实际应用中遇到一些问题。
FlinkSQL demo
CREATE TABLE waybill_extend_kafka (
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map<string,string>,
cur map<string,string>,
cus map<string,string>,
_proc as proctime()
) WITH (
'connector' = 'kafka',
'topic' = 't1',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'properties.group.id' = 'g1',
'scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset
'format' = 'json'
);
CREATE TABLE package_state_kafka (
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map<string,string>,
cur map<string,string>,
cus map<string,string>,
_proc as proctime()
) WITH (
'connector' = 'kafka',
'topic' = 't2',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'properties.group.id' = 'g1',
'scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset
'format' = 'json'
);
CREATE TABLE es_dim(
id STRING,
ts STRING,
waybill_code STRING,
pin STRING,
operater_ts STRING,
operater_type STRING,
is_enable STRING,
batch_no STRING,
activity_key STRING,
p_type STRING,
p_name STRING,
version STRING,
update_time STRING
)
with (
'connector' = 'elasticsearch-6',
'index' = 'es_dim',
'document-type' = 'es_dim',
'hosts' = 'http://xxx:9200',
'format' = 'json'
);
CREATE TABLE es_sink(
waybill_code STRING
,first_order STRING -- 新客1,非新客0
,extend_update_time STRING
,state STRING -- 妥投150
,package_update_time STRING
,pin STRING
,coupon_use_time STRING
,operater_type STRING
,is_enable STRING
,batch_no STRING
,update_time STRING
,PRIMARY KEY (waybill_code) NOT ENFORCED
)
with (
'connector' = 'elasticsearch-6',
'index' = 'es_sink',
'document-type' = 'es_sink',
'hosts' = 'http://xxx:9200',
'format' = 'json',
'filter.null-value'='true',
'sink.bulk-flush.max-actions' = '1000',
'sink.bulk-flush.max-size' = '10mb'
);
CREATE TABLE kafka_sink (
waybill_code STRING
,first_order STRING
,extend_update_time STRING
,state STRING -- 妥投150
,package_update_time STRING
,pin STRING
,coupon_use_time STRING
,operater_type STRING
,is_enable STRING
,batch_no STRING
,update_time STRING
,PRIMARY KEY (waybill_code) NOT ENFORCED --注意 确保在 DDL 中定义主键。
) WITH (
'connector' = 'upsert-kafka',
'topic' = 't3',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'key.format' = 'json',
'value.format' = 'json'
);
--新客
CREATE view waybill_extend_temp as
select
IF(cur['waybill_code'] IS NOT NULL , cur['waybill_code'], src ['waybill_code']) AS waybill_code,
IF(cur['data_key'] IS NOT NULL , cur['data_key'], src ['data_key']) AS data_key,
IF(cur['create_time'] IS NOT NULL , cur['create_time'], src ['create_time']) AS create_time,
opt,
_proc
FROM waybill_extend_kafka
where UPPER(opt) = 'DELETE' OR UPPER(opt) = 'INSERT';
CREATE view waybill_extend_temp_handle as
SELECT
waybill_code,
case when UPPER(opt) = 'INSERT' then '1'
when UPPER(opt) = 'DELETE' then '0'
end as first_order,
create_time,
_proc
from waybill_extend_temp
where data_key = 'firstOrder';
--妥投
CREATE view package_state_temp as
select
IF(cur['WAYBILL_CODE'] IS NOT NULL , cur['WAYBILL_CODE'], src ['WAYBILL_CODE']) AS waybill_code,
IF(cur['STATE'] IS NOT NULL , cur['STATE'], src ['STATE']) AS state,
IF(cur['CREATE_TIME'] IS NOT NULL , cur['CREATE_TIME'], src ['CREATE_TIME']) AS create_time,
opt,
_proc
FROM package_state_kafka
where UPPER(opt) = 'INSERT';
CREATE view package_state_temp_handle as
SELECT
waybill_code,
max(state) as state,
min(create_time) as package_update_time,
proctime() as _proc
from package_state_temp
where state = '150'
group by waybill_code;
--full join
-- flink1.14 注意:flinksql里面的FULL OUTER JOIN 只是分别下发左右数据,中间状态不关联下发,在流处理场景下相当于union all
CREATE view waybill_extend_package_state as
SELECT
COALESCE(a.waybill_code, b.waybill_code) as waybill_code,
a.first_order,
a.create_time as extend_update_time,
b.state,
b.package_update_time,
COALESCE(a._proc, b._proc) as _proc
from waybill_extend_temp_handle as a
FULL OUTER JOIN package_state_temp_handle b
on a.waybill_code=b.waybill_code;
--result
CREATE VIEW res_view AS
SELECT
a.waybill_code
,a.first_order
,a.extend_update_time
,a.state
,a.package_update_time
,b.pin
,b.operater_ts
,b.operater_type
,b.is_enable
,b.batch_no
,CAST(CAST(a._proc AS TIMESTAMP(3)) AS STRING) as update_time
,row_number() over(partition by a.waybill_code order by b.operater_ts desc) as rn
from waybill_extend_package_state as a
JOIN es_dim FOR SYSTEM_TIME AS OF a._proc as b
on a.waybill_code=b.waybill_code;
INSERT INTO es_sink
SELECT
waybill_code
,first_order
,extend_update_time
,state
,package_update_time
,pin
,operater_ts
,operater_type
,is_enable
,batch_no
,update_time
FROM res_view
where rn =1;
INSERT INTO kafka_sink
SELECT
waybill_code
,first_order
,extend_update_time
,state
,package_update_time
,pin
,operater_ts
,operater_type
,is_enable
,batch_no
,update_time
FROM res_view
where rn =1;
es_sink mapping:
POST es_sink/es_sink/_mapping
{
"es_sink": {
"properties": {
"waybill_code": {
"type": "keyword"
},
"pin": {
"type": "keyword"
},
"operater_ts": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"operater_type": {
"type": "keyword"
},
"is_enable": {
"type": "keyword"
},
"batch_no": {
"type": "keyword"
},
"first_order": {
"type": "keyword"
},
"extend_update_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"state": {
"type": "keyword"
},
"package_update_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"update_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
结果分析
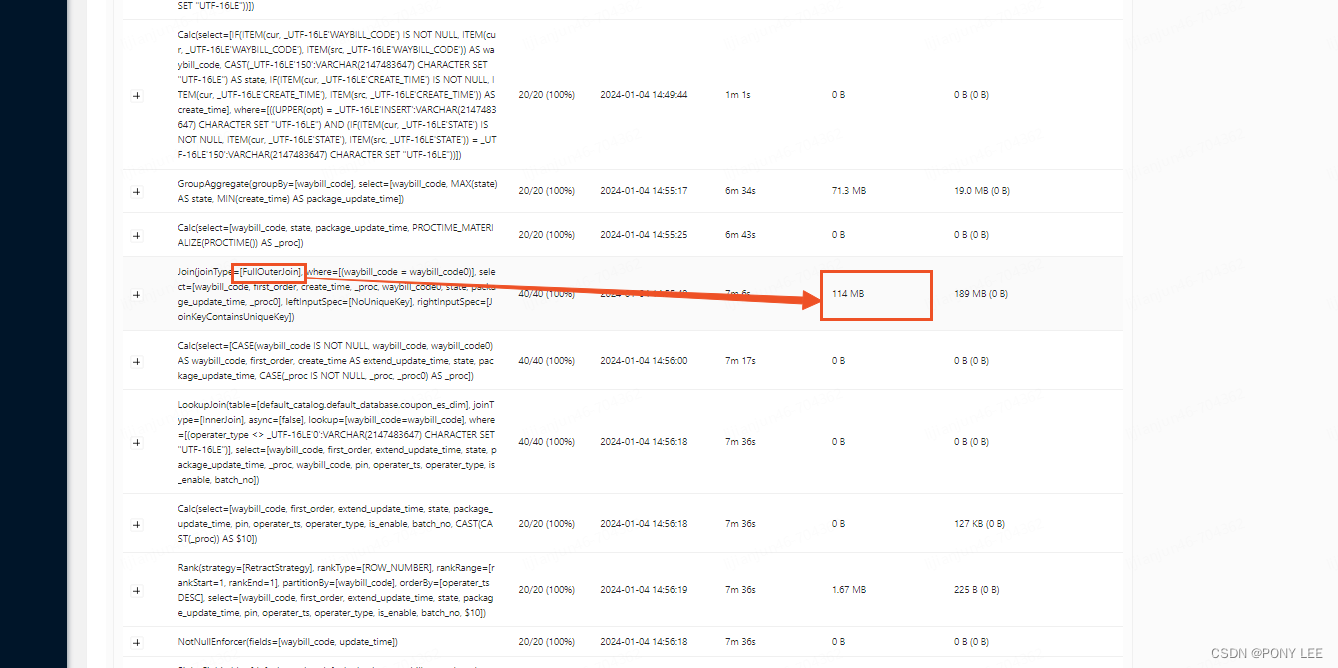
从sink_es和sink_kafka获取数据都是同样的结果,部分结果如下:

但从结果中可以看出,FlinkSQL里面的【FULL OUTER JOIN】 只是分别下发左右数据,中间状态(从FlinkUI中可以看到【FULL OUTER JOIN】状态也做了保存)不关联下发,在流处理场景下相当于【UNION ALL】,不知是否是FlinkSQL的bug。
【FULL OUTER JOIN】状态数据,如下:
此次用例分析只是针对于Flink1.14,对于其他版本尚不清楚。