6.4.1 数据处理
IMDB电影评论数据集是一份关于电影评论的经典二分类数据集.IMDB 按照评分的高低筛选出了积极评论和消极评论,如果评分 ≥7≥7,则认为是积极评论;如果评分 ≤4≤4,则认为是消极评论.数据集包含训练集和测试集数据,数量各为 25000 条,每条数据都是一段用户关于某个电影的真实评价,以及观众对这个电影的情感倾向,其目录结构如下所示
├── train/
├── neg # 消极数据
├── pos # 积极数据
├── unsup # 无标签数据
├── test/
├── neg # 消极数据
├── pos # 积极数据6.4.1.1 数据加载
原始训练集和测试集数据分别25000条,本节将原始的测试集平均分为两份,分别作为验证集和测试集,存放于./dataset目录下。使用如下代码便可以将数据加载至内存:
import os # 加载数据集 def load_imdb_data(path): assert os.path.exists(path) trainset, devset, testset = [], [], [] with open(os.path.join(path, "C:\\Users\\hp\\Desktop\\IMDB\\train.txt"), "r",encoding="utf-8") as fr: for line in fr: sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1) trainset.append((sentence, sentence_label)) with open(os.path.join(path, "C:\\Users\\hp\\Desktop\\IMDB\\dev.txt"), "r",encoding="utf-8") as fr: for line in fr: sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1) devset.append((sentence, sentence_label)) with open(os.path.join(path, "C:\\Users\\hp\\Desktop\\IMDB\\test.txt"), "r",encoding="utf-8") as fr: for line in fr: sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1) testset.append((sentence, sentence_label)) return trainset, devset, testset # 加载IMDB数据集 train_data, dev_data, test_data = load_imdb_data("./dataset/") # 打印一下加载后的数据样式 print(train_data[4])("the premise of an african-american female scrooge in the modern, struggling city was inspired, but nothing else in this film is. here, ms. scrooge is a miserly banker who takes advantage of the employees and customers in the largely poor and black neighborhood it inhabits. there is no doubt about the good intentions of the people involved. part of the problem is that story's roots don't translate well into the urban setting of this film, and the script fails to make the update work. also, the constant message about sharing and giving is repeated so endlessly, the audience becomes tired of it well before the movie reaches its familiar end. this is a message film that doesn't know when to quit. in the title role, the talented cicely tyson gives an overly uptight performance, and at times lines are difficult to understand. the charles dickens novel has been adapted so many times, it's a struggle to adapt it in a way that makes it fresh and relevant, in spite of its very relevant message.", '0')
期末复习太紧张了,直接附上全部代码
import os import torch import torch.nn as nn from torch.utils.data import Dataset from functools import partial import time import random import numpy as np device = torch.device("cuda" if torch.cuda.is_available() else "cpu") def load_vocab(path): assert os.path.exists(path) words = [] with open(path, "r", encoding="utf-8") as f: words = f.readlines() words = [word.strip() for word in words if word.strip()] word2id = dict(zip(words, range(len(words)))) return word2id def load_imdb_data(path): assert os.path.exists(path) trainset, devset, testset = [], [], [] with open(os.path.join(path, "train.txt"), "r", encoding='utf-8') as fr: for line in fr: sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1) trainset.append((sentence, sentence_label)) with open(os.path.join(path, "dev.txt"), "r", encoding='utf-8') as fr: for line in fr: sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1) devset.append((sentence, sentence_label)) with open(os.path.join(path, "test.txt"), "r", encoding='utf-8') as fr: for line in fr: sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1) testset.append((sentence, sentence_label)) return trainset, devset, testset # 加载IMDB数据集 train_data, dev_data, test_data = load_imdb_data("./dataset/") # # 打印一下加载后的数据样式 print(train_data[4]) class IMDBDataset(Dataset): def __init__(self, examples, word2id_dict): super(IMDBDataset, self).__init__() # 词典,用于将单词转为字典索引的数字 self.word2id_dict = word2id_dict # 加载后的数据集 self.examples = self.words_to_id(examples) def words_to_id(self, examples): tmp_examples = [] for idx, example in enumerate(examples): seq, label = example # 将单词映射为字典索引的ID, 对于词典中没有的单词用[UNK]对应的ID进行替代 seq = [self.word2id_dict.get(word, self.word2id_dict['[UNK]']) for word in seq.split(" ")] label = int(label) tmp_examples.append([seq, label]) return tmp_examples def __getitem__(self, idx): seq, label = self.examples[idx] return seq, label def __len__(self): return len(self.examples) # 加载词表 word2id_dict = load_vocab("./dataset/vocab.txt") # 实例化Dataset train_set = IMDBDataset(train_data, word2id_dict) dev_set = IMDBDataset(dev_data, word2id_dict) test_set = IMDBDataset(test_data, word2id_dict) print('训练集样本数:', len(train_set)) print('样本示例:', train_set[4]) import os def load_vocab(path): assert os.path.exists(path) words = [] with open(path, "r", encoding="utf-8") as f: words = f.readlines() words = [word.strip() for word in words if word.strip()] word2id = dict(zip(words, range(len(words)))) return word2id def collate_fn(batch_data, pad_val=0, max_seq_len=256): seqs, seq_lens, labels = [], [], [] max_len = 0 for example in batch_data: seq, label = example # 对数据序列进行截断 seq = seq[:max_seq_len] # 对数据截断并保存于seqs中 seqs.append(seq) seq_lens.append(len(seq)) labels.append(label) # 保存序列最大长度 max_len = max(max_len, len(seq)) # 对数据序列进行填充至最大长度 for i in range(len(seqs)): seqs[i] = seqs[i] + [pad_val] * (max_len - len(seqs[i])) # return (torch.tensor(seqs), torch.tensor(seq_lens)), torch.tensor(labels) return (torch.tensor(seqs).to(device), torch.tensor(seq_lens)), torch.tensor(labels).to(device) max_seq_len = 5 batch_data = [[[1, 2, 3, 4, 5, 6], 1], [[2, 4, 6], 0]] (seqs, seq_lens), labels = collate_fn(batch_data, pad_val=word2id_dict["[PAD]"], max_seq_len=max_seq_len) print("seqs: ", seqs) print("seq_lens: ", seq_lens) print("labels: ", labels) max_seq_len = 256 batch_size = 128 collate_fn = partial(collate_fn, pad_val=word2id_dict["[PAD]"], max_seq_len=max_seq_len) train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True, drop_last=False, collate_fn=collate_fn) dev_loader = torch.utils.data.DataLoader(dev_set, batch_size=batch_size, shuffle=False, drop_last=False, collate_fn=collate_fn) test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=False, drop_last=False, collate_fn=collate_fn) class AveragePooling(nn.Module): def __init__(self): super(AveragePooling, self).__init__() def forward(self, sequence_output, sequence_length): # 假设 sequence_length 是一个 PyTorch 张量 sequence_length = sequence_length.unsqueeze(-1).to(torch.float32) # 根据sequence_length生成mask矩阵,用于对Padding位置的信息进行mask max_len = sequence_output.shape[1] mask = torch.arange(max_len, device='cuda') < sequence_length.to('cuda') mask = mask.to(torch.float32).unsqueeze(-1) # 对序列中paddling部分进行mask sequence_output = torch.multiply(sequence_output, mask.to('cuda')) # 对序列中的向量取均值 batch_mean_hidden = torch.divide(torch.sum(sequence_output, dim=1), sequence_length.to('cuda')) return batch_mean_hidden class Model_BiLSTM_FC(nn.Module): def __init__(self, num_embeddings, input_size, hidden_size, num_classes=2): super(Model_BiLSTM_FC, self).__init__() # 词典大小 self.num_embeddings = num_embeddings # 单词向量的维度 self.input_size = input_size # LSTM隐藏单元数量 self.hidden_size = hidden_size # 情感分类类别数量 self.num_classes = num_classes # 实例化嵌入层 self.embedding_layer = nn.Embedding(num_embeddings, input_size, padding_idx=0) # 实例化LSTM层 self.lstm_layer = nn.LSTM(input_size, hidden_size, batch_first=True, bidirectional=True) # 实例化聚合层 self.average_layer = AveragePooling() # 实例化输出层 self.output_layer = nn.Linear(hidden_size * 2, num_classes) def forward(self, inputs): # 对模型输入拆分为序列数据和mask input_ids, sequence_length = inputs # 获取词向量 inputs_emb = self.embedding_layer(input_ids) packed_input = nn.utils.rnn.pack_padded_sequence(inputs_emb, sequence_length.cpu(), batch_first=True, enforce_sorted=False) # 使用lstm处理数据 packed_output, _ = self.lstm_layer(packed_input) # 解包输出 sequence_output, _ = nn.utils.rnn.pad_packed_sequence(packed_output, batch_first=True) # 使用聚合层聚合sequence_output batch_mean_hidden = self.average_layer(sequence_output, sequence_length) # 输出文本分类logits logits = self.output_layer(batch_mean_hidden) return logits import torch import matplotlib.pyplot as plt class RunnerV3(object): def __init__(self, model, optimizer, loss_fn, metric, **kwargs): self.model = model self.optimizer = optimizer self.loss_fn = loss_fn self.metric = metric # 只用于计算评价指标 # 记录训练过程中的评价指标变化情况 self.dev_scores = [] # 记录训练过程中的损失函数变化情况 self.train_epoch_losses = [] # 一个epoch记录一次loss self.train_step_losses = [] # 一个step记录一次loss self.dev_losses = [] # 记录全局最优指标 self.best_score = 0 def train(self, train_loader, dev_loader=None, **kwargs): # 将模型切换为训练模式 self.model.train() # 传入训练轮数,如果没有传入值则默认为0 num_epochs = kwargs.get("num_epochs", 0) # 传入log打印频率,如果没有传入值则默认为100 log_steps = kwargs.get("log_steps", 100) # 评价频率 eval_steps = kwargs.get("eval_steps", 0) # 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams" save_path = kwargs.get("save_path", "best_model.pdparams") custom_print_log = kwargs.get("custom_print_log", None) # 训练总的步数 num_training_steps = num_epochs * len(train_loader) if eval_steps: if self.metric is None: raise RuntimeError('Error: Metric can not be None!') if dev_loader is None: raise RuntimeError('Error: dev_loader can not be None!') # 运行的step数目 global_step = 0 total_acces = [] total_losses = [] Iters = [] # 进行num_epochs轮训练 for epoch in range(num_epochs): # 用于统计训练集的损失 total_loss = 0 for step, data in enumerate(train_loader): X, y = data # 获取模型预测 # 计算logits logits = self.model(X) # 将y转换为和logits相同的形状 acc_y = y.view(-1, 1) # 计算准确率 probs = torch.softmax(logits, dim=1) pred = torch.argmax(probs, dim=1) correct = (pred == acc_y).sum().item() total = acc_y.size(0) acc = correct / total total_acces.append(acc) # print(acc.numpy()[0]) loss = self.loss_fn(logits, y) # 默认求mean total_loss += loss total_losses.append(loss.item()) Iters.append(global_step) # 训练过程中,每个step的loss进行保存 self.train_step_losses.append((global_step, loss.item())) if log_steps and global_step % log_steps == 0: print( f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}") # 梯度反向传播,计算每个参数的梯度值 loss.backward() if custom_print_log: custom_print_log(self) # 小批量梯度下降进行参数更新 self.optimizer.step() # 梯度归零 self.optimizer.zero_grad() # 判断是否需要评价 if eval_steps > 0 and global_step != 0 and \ (global_step % eval_steps == 0 or global_step == (num_training_steps - 1)): dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step) print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}") # 将模型切换为训练模式 self.model.train() # 如果当前指标为最优指标,保存该模型 if dev_score > self.best_score: self.save_model(save_path) print( f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}") self.best_score = dev_score global_step += 1 # 当前epoch 训练loss累计值 trn_loss = (total_loss / len(train_loader)).item() # epoch粒度的训练loss保存 self.train_epoch_losses.append(trn_loss) draw_process("trainning acc", "green", Iters, total_acces, "trainning acc") print("total_acc:") print(total_acces) print("total_loss:") print(total_losses) print("[Train] Training done!") # 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度 @torch.no_grad() def evaluate(self, dev_loader, **kwargs): assert self.metric is not None # 将模型设置为评估模式 self.model.eval() global_step = kwargs.get("global_step", -1) # 用于统计训练集的损失 total_loss = 0 # 重置评价 self.metric.reset() # 遍历验证集每个批次 for batch_id, data in enumerate(dev_loader): X, y = data # 计算模型输出 logits = self.model(X) # 计算损失函数 loss = self.loss_fn(logits, y).item() # 累积损失 total_loss += loss # 累积评价 self.metric.update(logits, y) dev_loss = (total_loss / len(dev_loader)) self.dev_losses.append((global_step, dev_loss)) dev_score = self.metric.accumulate() self.dev_scores.append(dev_score) return dev_score, dev_loss # 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度 @torch.no_grad() def predict(self, x, **kwargs): # 将模型设置为评估模式 self.model.eval() # 运行模型前向计算,得到预测值 logits = self.model(x) return logits def save_model(self, save_path): torch.save(self.model.state_dict(), save_path) def load_model(self, model_path): model_state_dict = torch.load(model_path) self.model.load_state_dict(model_state_dict) class Accuracy(): def __init__(self, is_logist=True): # 用于统计正确的样本个数 self.num_correct = 0 # 用于统计样本的总数 self.num_count = 0 self.is_logist = is_logist def update(self, outputs, labels): # 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务 if outputs.shape[1] == 1: # 二分类 outputs = torch.squeeze(outputs, dim=-1) if self.is_logist: # logist判断是否大于0 preds = torch.tensor((outputs >= 0), dtype=torch.float32) else: # 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0 preds = torch.tensor((outputs >= 0.5), dtype=torch.float32) else: # 多分类时,使用'torch.argmax'计算最大元素索引作为类别 preds = torch.argmax(outputs, dim=1) # 获取本批数据中预测正确的样本个数 labels = torch.squeeze(labels, dim=-1) batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).cpu().numpy() batch_count = len(labels) # 更新num_correct 和 num_count self.num_correct += batch_correct self.num_count += batch_count def accumulate(self): # 使用累计的数据,计算总的指标 if self.num_count == 0: return 0 return self.num_correct / self.num_count def reset(self): # 重置正确的数目和总数 self.num_correct = 0 self.num_count = 0 def name(self): return "Accuracy" def draw_process(title, color, iters, data, label): plt.title(title, fontsize=24) plt.xlabel("iter", fontsize=20) plt.ylabel(label, fontsize=20) plt.plot(iters, data, color=color, label=label) plt.legend() plt.grid() print(plt.show()) np.random.seed(0) random.seed(0) torch.seed() # 指定训练轮次 num_epochs = 3 # 指定学习率 learning_rate = 0.001 # 指定embedding的数量为词表长度 num_embeddings = len(word2id_dict) # embedding向量的维度 input_size = 256 # LSTM网络隐状态向量的维度 hidden_size = 256 # 实例化模型 model = Model_BiLSTM_FC(num_embeddings, input_size, hidden_size).to(device) # 指定优化器 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, betas=(0.9, 0.999)) # 指定损失函数 loss_fn = nn.CrossEntropyLoss() # 指定评估指标 metric = Accuracy() # 实例化Runner runner = RunnerV3(model, optimizer, loss_fn, metric) # 模型训练 start_time = time.time() runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=10, log_steps=10, save_path="./checkpoints/best.pdparams") end_time = time.time() print("time: ", (end_time - start_time)) from nndl4.tools import plot_training_loss_acc # 图像名字 fig_name = "./images/6.16.pdf" # sample_step: 训练损失的采样step,即每隔多少个点选择1个点绘制 # loss_legend_loc: loss 图像的图例放置位置 # acc_legend_loc: acc 图像的图例放置位置 plot_training_loss_acc(runner, fig_name, fig_size=(16, 6), sample_step=10, loss_legend_loc="lower left", acc_legend_loc="lower right") model_path = "./checkpoints/best.pdparams" runner.load_model(model_path) accuracy, _ = runner.evaluate(test_loader) print(f"Evaluate on test set, Accuracy: {accuracy:.5f}") id2label = {0: "消极情绪", 1: "积极情绪"} text = "this movie is so great. I watched it three times already" # 处理单条文本 sentence = text.split(" ") words = [word2id_dict[word] if word in word2id_dict else word2id_dict['[UNK]'] for word in sentence] words = words[:max_seq_len] sequence_length = torch.tensor([len(words)], dtype=torch.int64) words = torch.tensor(words, dtype=torch.int64).unsqueeze(0) # 使用模型进行预测 logits = runner.predict((words.to(device), sequence_length.to(device))) max_label_id = torch.argmax(logits, dim=-1).cpu().numpy()[0] pred_label = id2label[max_label_id] print("Label: ", pred_label)
结果:

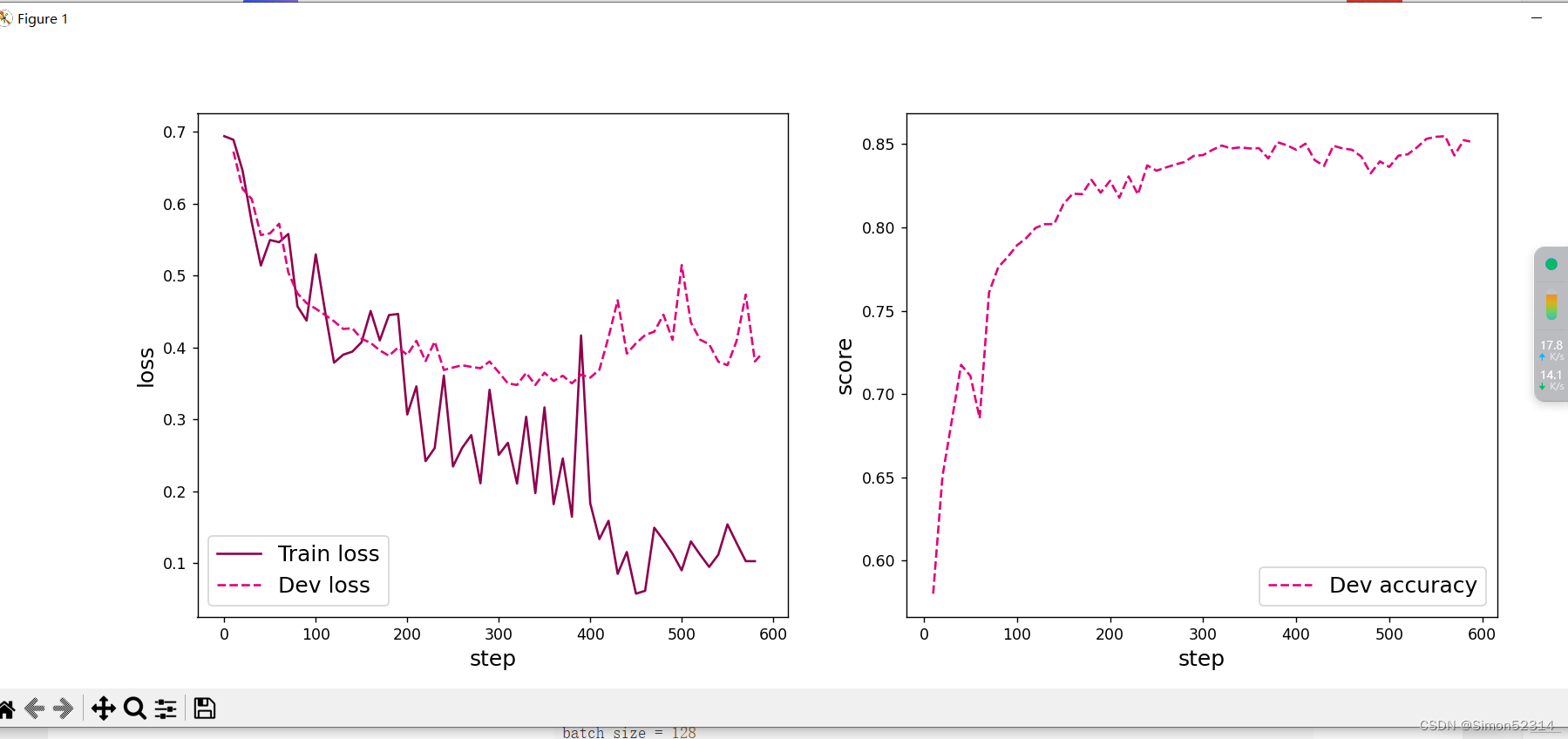

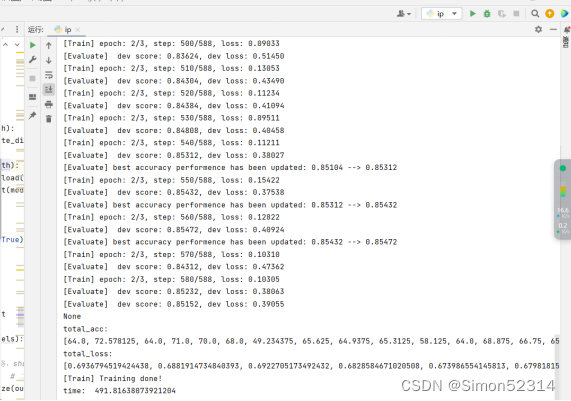


总结:
1、一开始运行代码遇见了一些错误,我看不懂
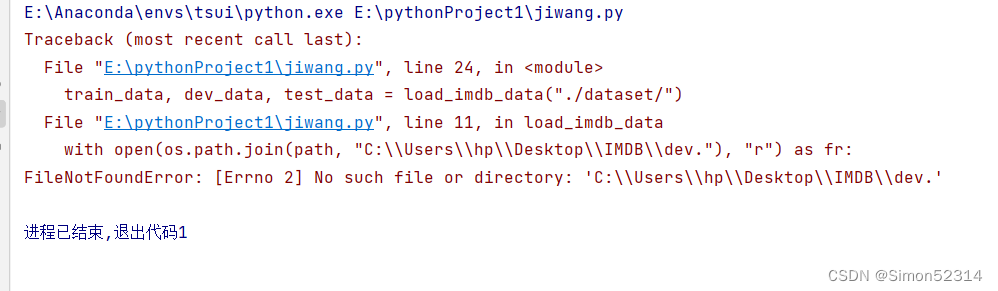
经过我查阅发现
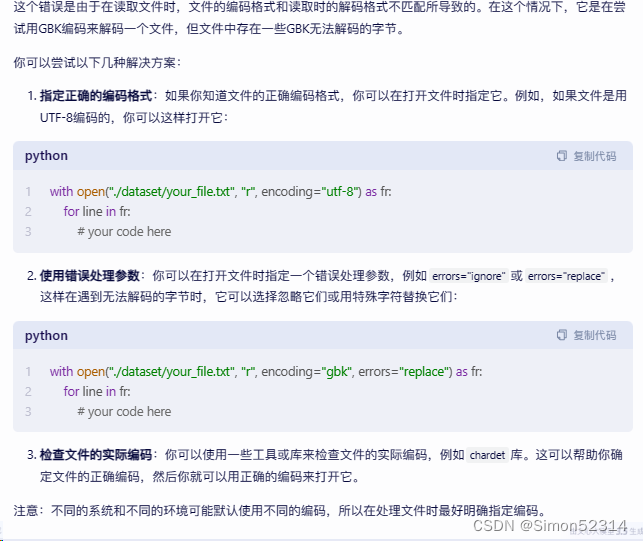
于是我修改在代码改成
with open(os.path.join(path, "C:\\Users\\hp\\Desktop\\IMDB\\train.txt"), "r",encoding="utf-8") as fr:
成功解决了问题。
然后只知道utf-8是一种编码方式,所以查了查