文章目录
- 一、domain adaptation领域适应
- domain shift
- domain adversarial training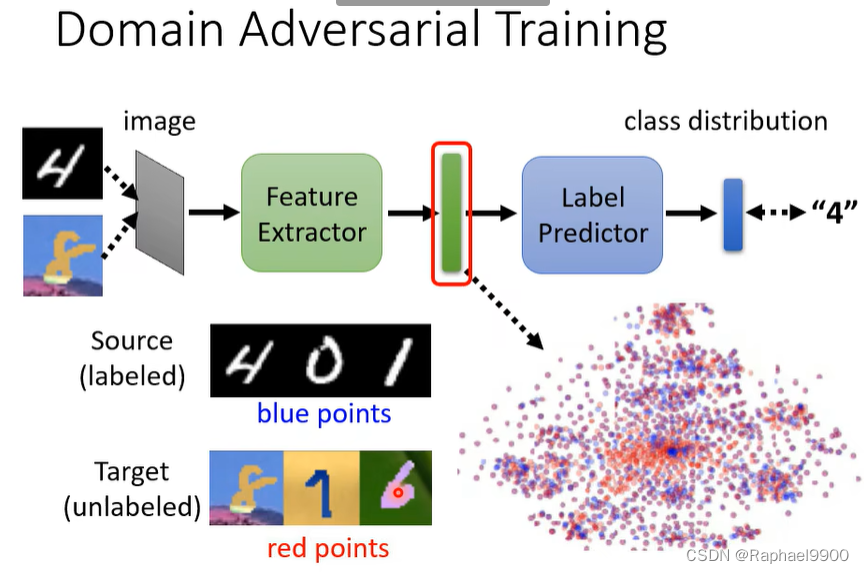
- domain generalization
- 二、自监督学习
- 多语言BERT的跨语言能力
- 交叉学科能力
- 用人工数据进行预训练
一、domain adaptation领域适应

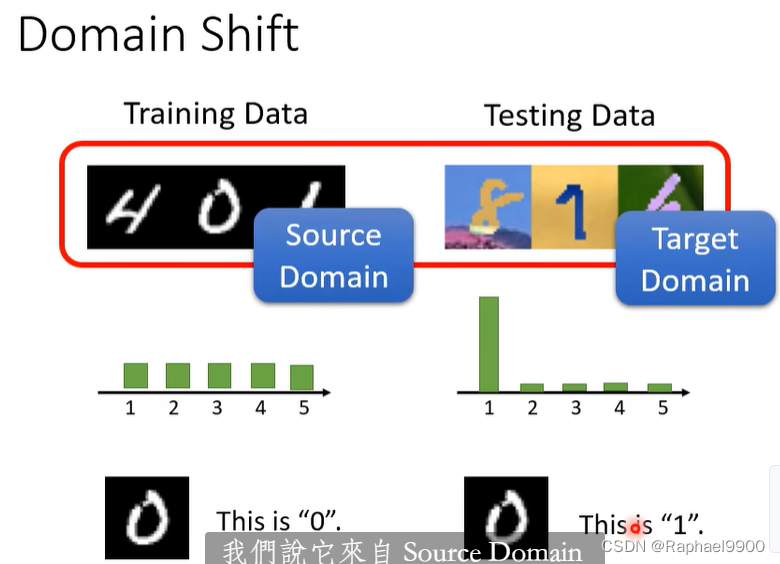
训练资料和测试资料分布不一样。
域转移domain shift:训练和测试数据有不同的分布。

domain shift
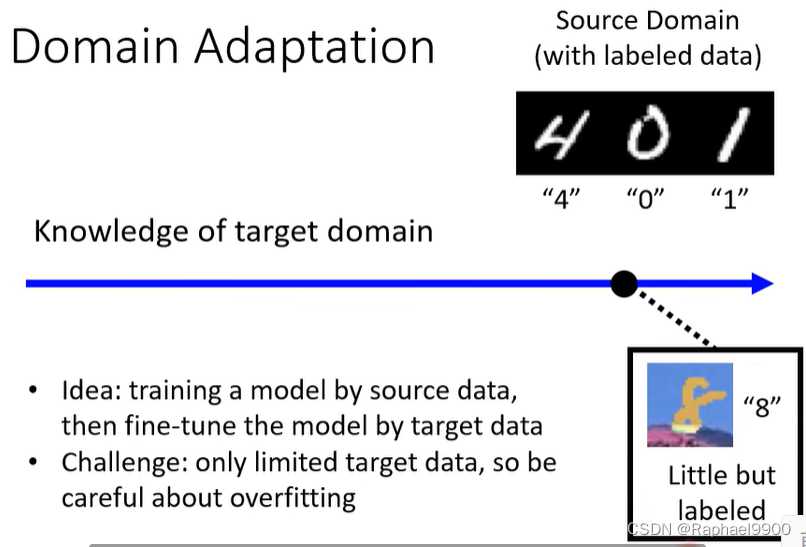
想法:通过源数据训练模型,然后通过目标数据微调模型
挑战:只有有限的目标数据,所以要小心过度拟合
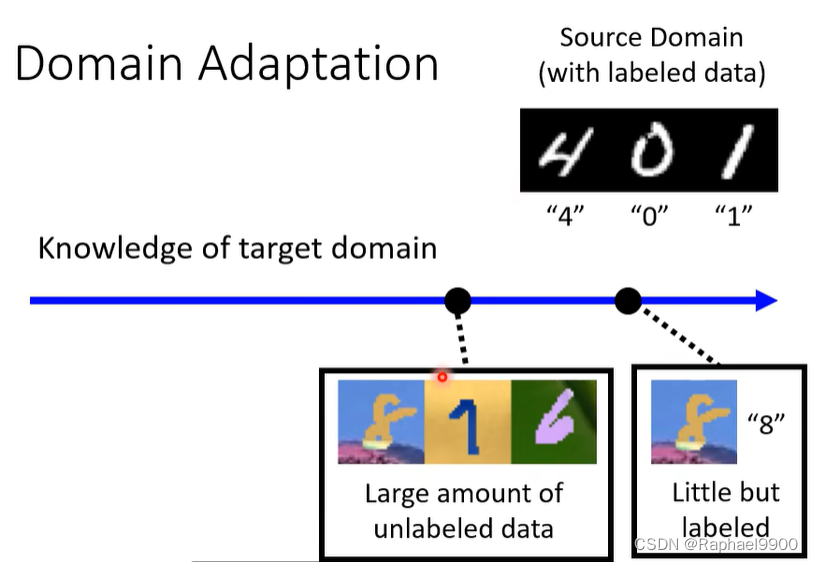

domain adversarial training
希望他们的分布没有差异
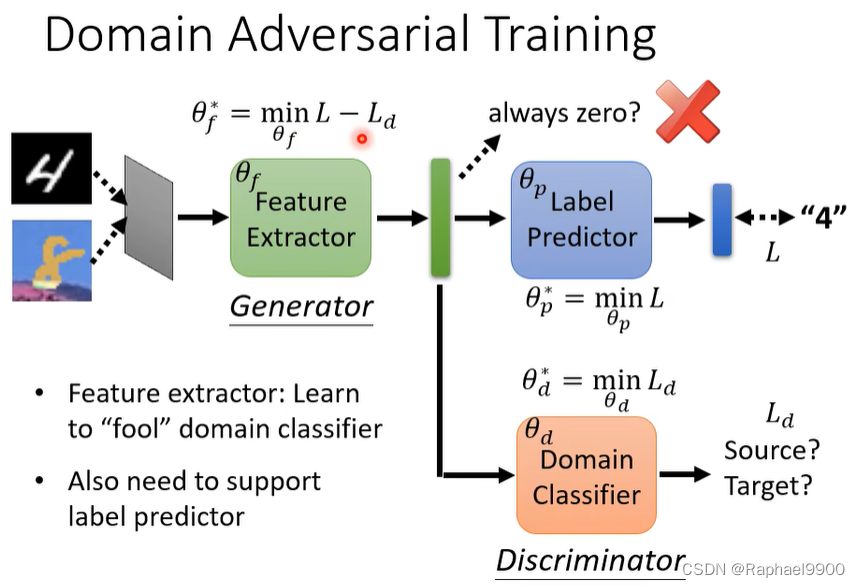
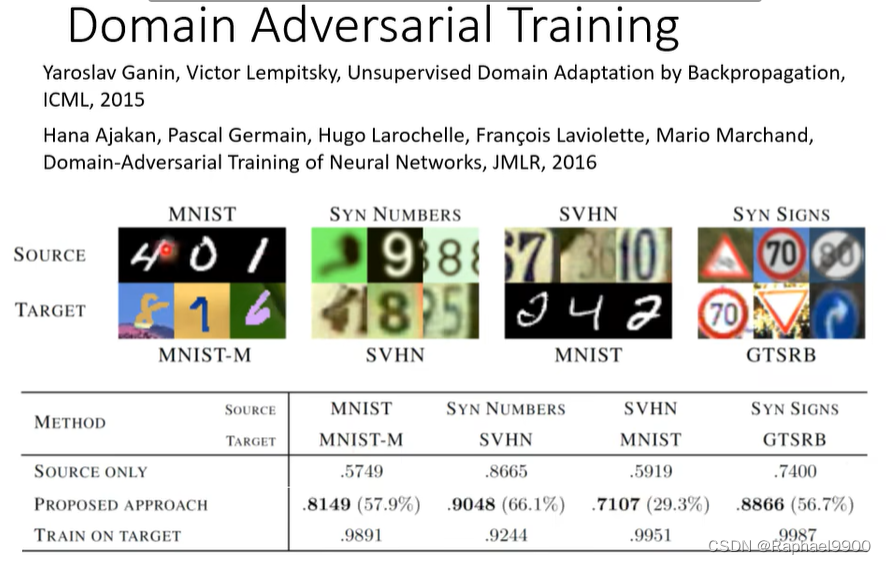
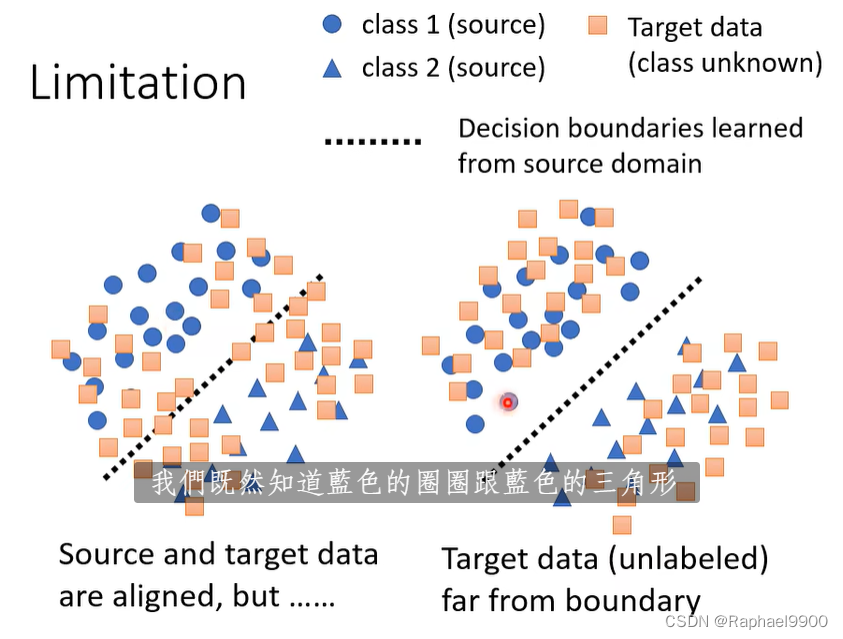
右边的好一点,可以让他们远离界限,下面就是这种做法
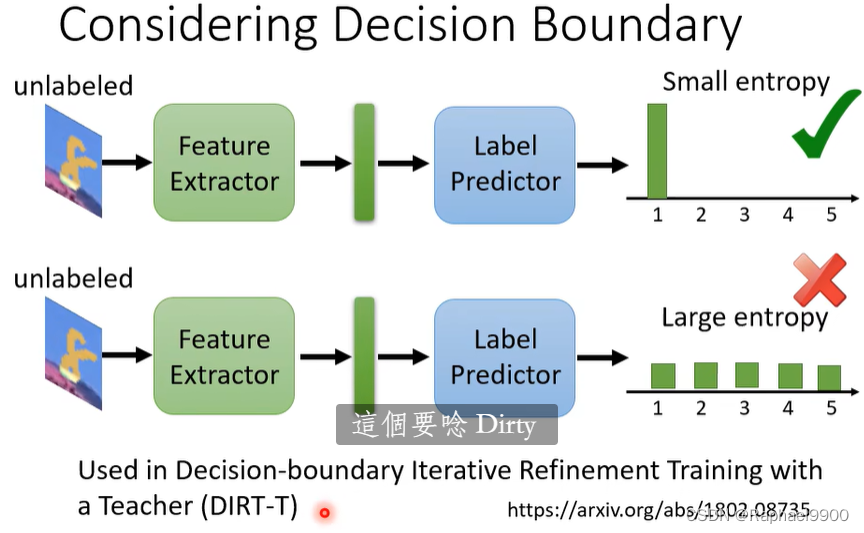


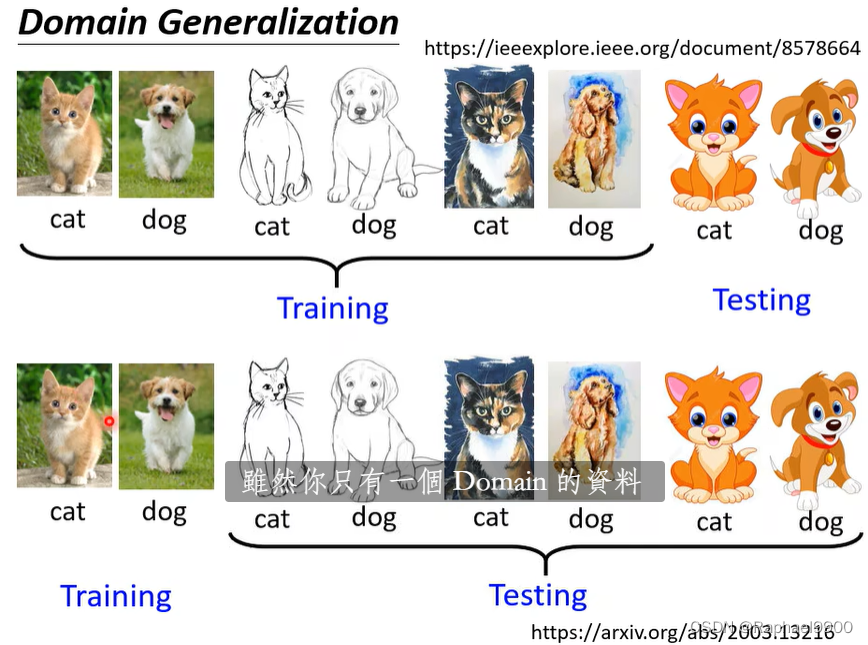
domain generalization
没有未知领域的资料
二、自监督学习
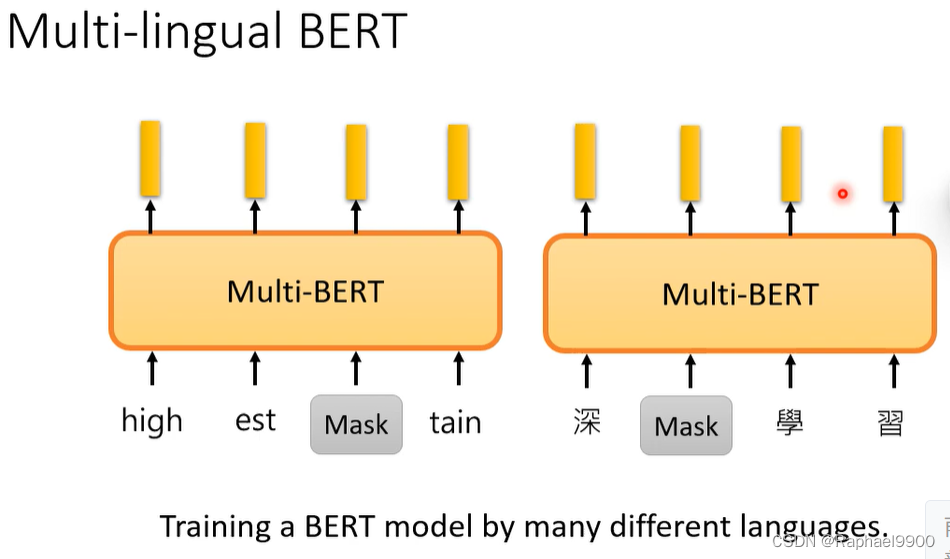
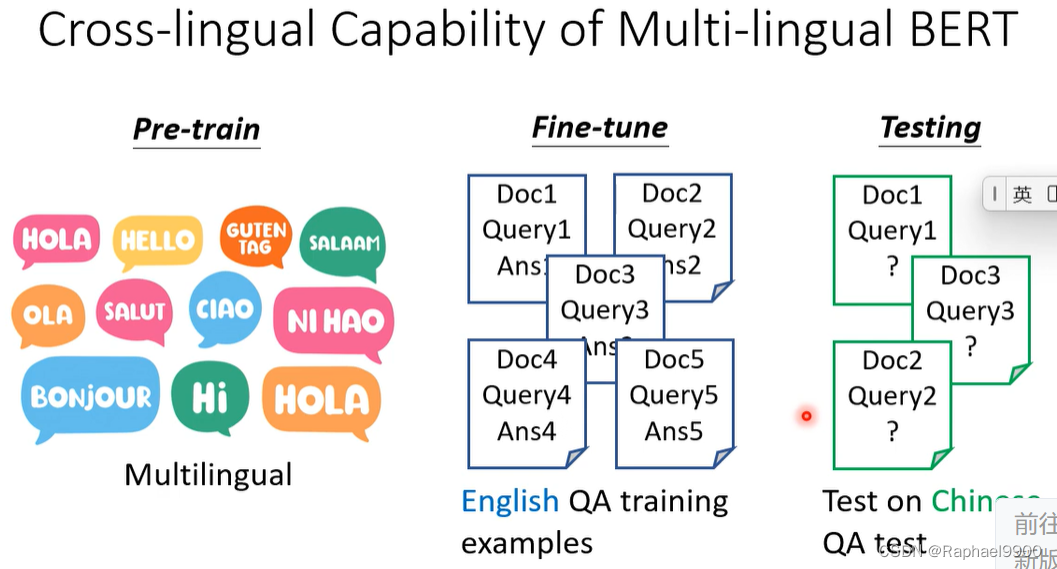
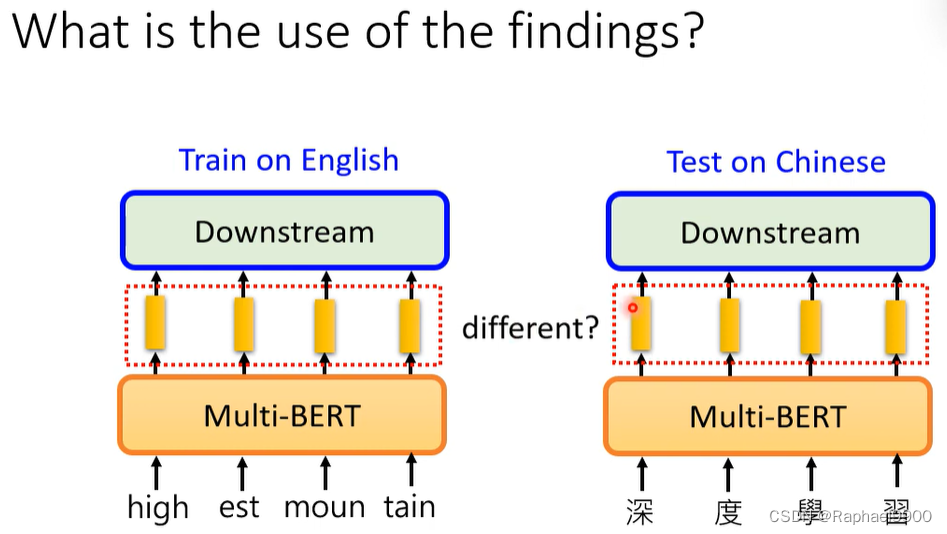
多语言BERT的跨语言能力

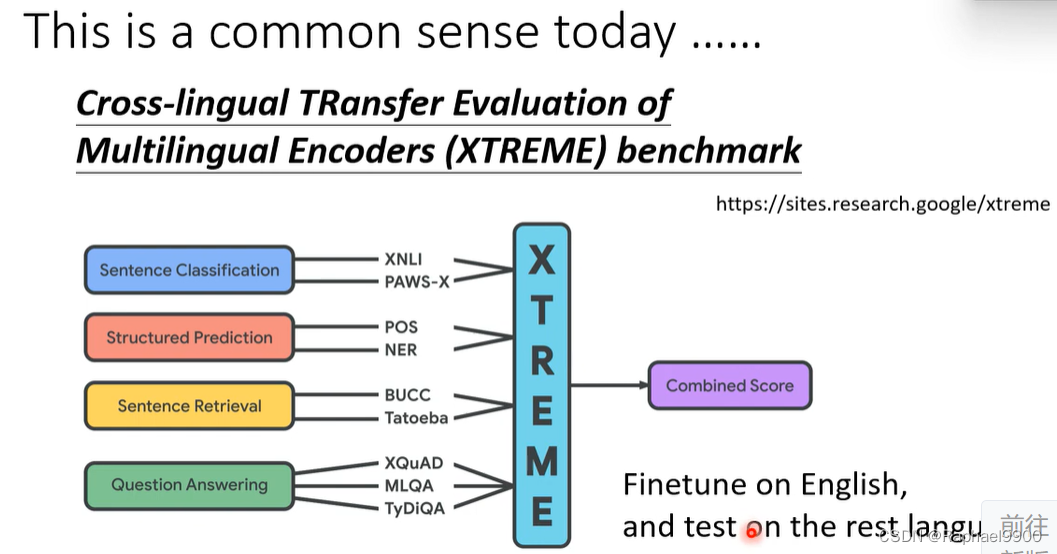
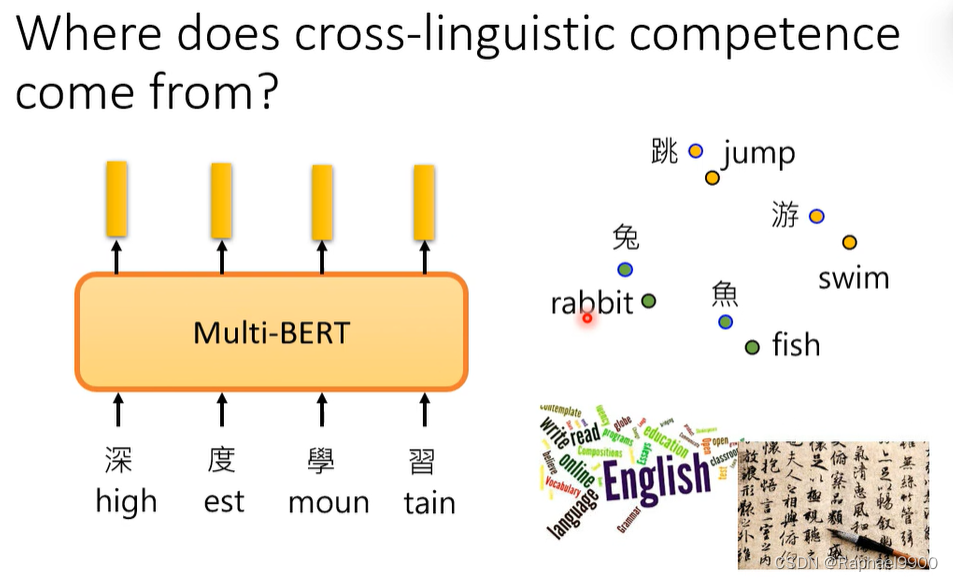
无视不同语言的差别,了解语义。

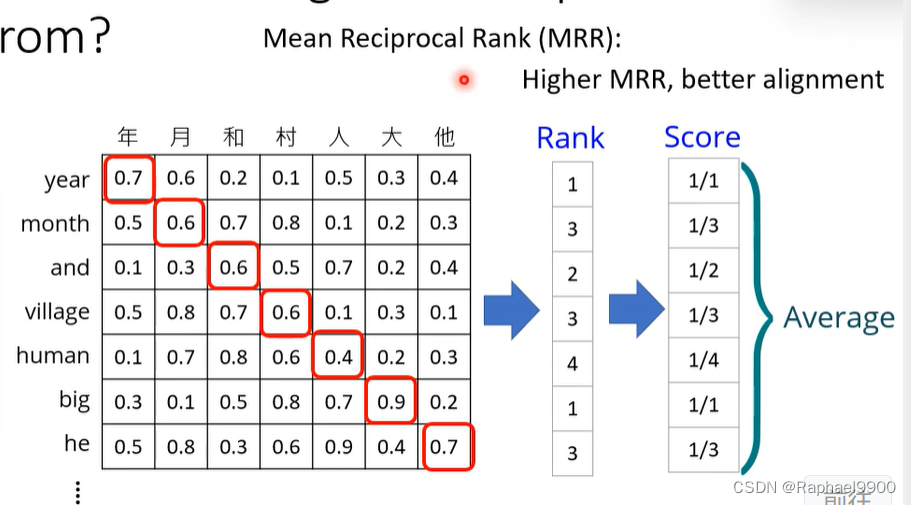
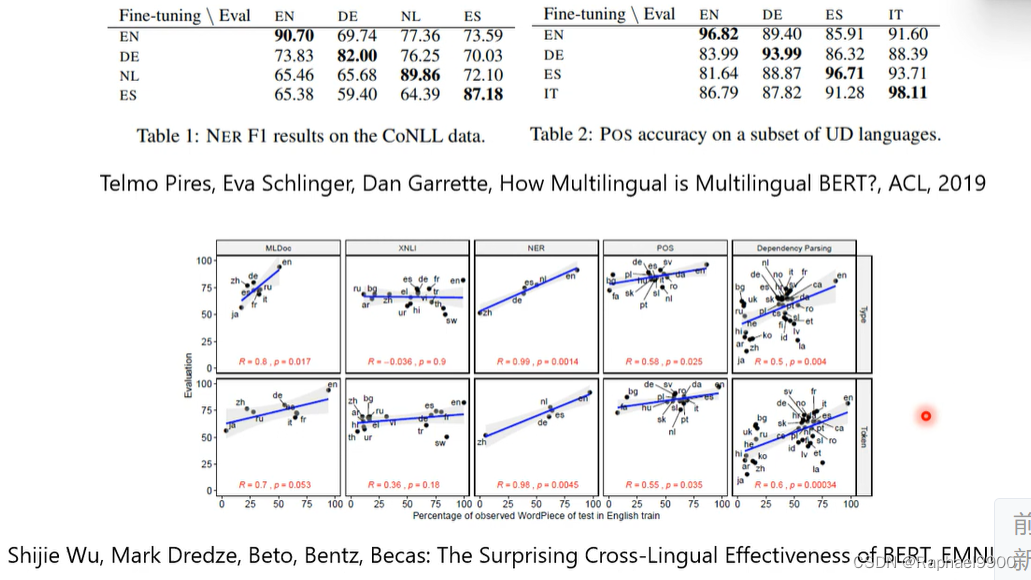
MRR分数越高越好

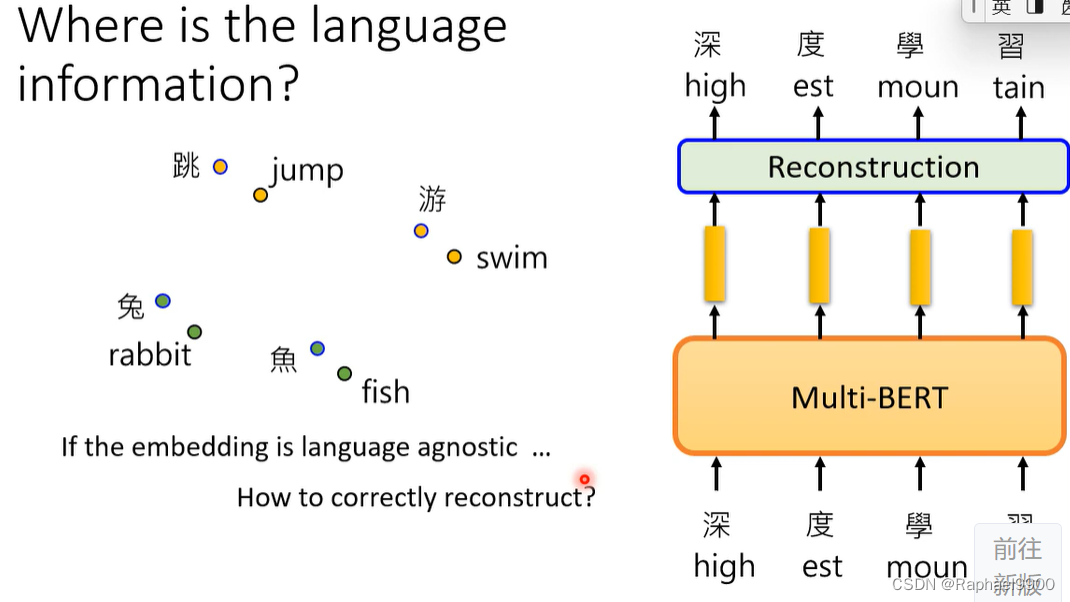
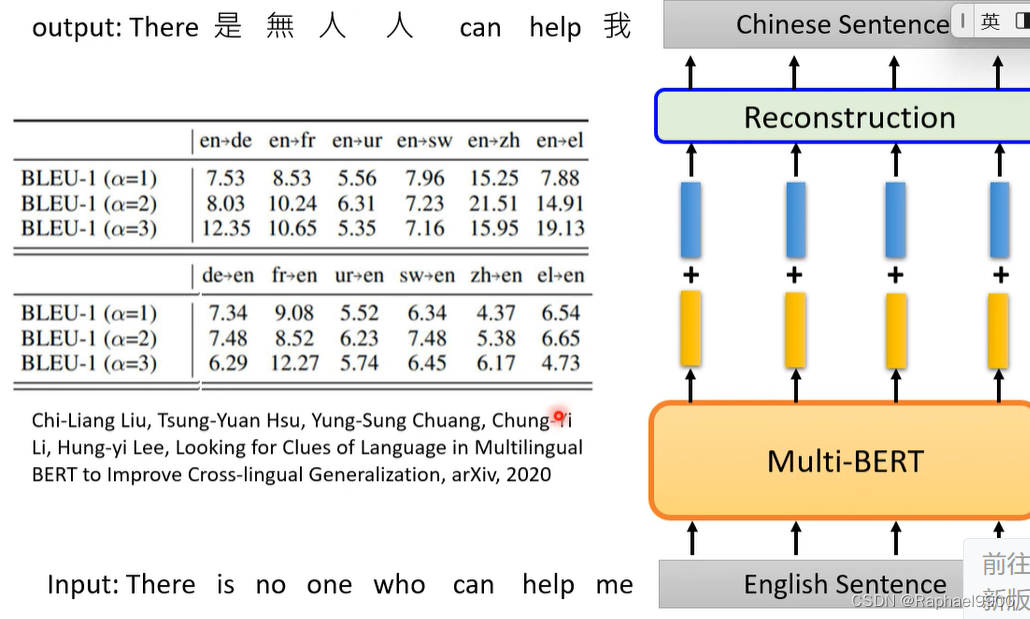
实际上BERT在做QA的时候用的是同一种语言,可以看出语言之间是有差异的,只是没找到。

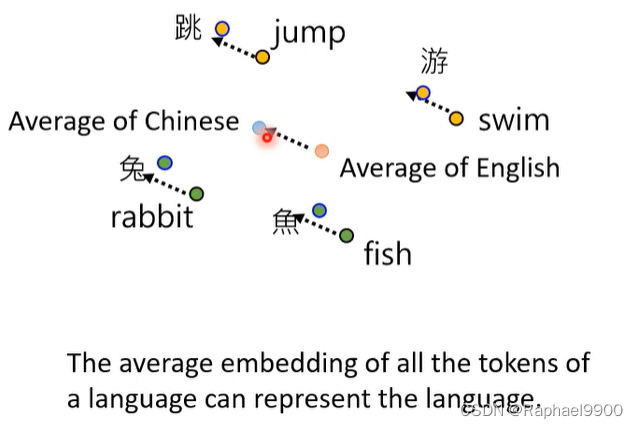
我们找到英文和中文符号之间的平均之后,得到差距,就能互换了
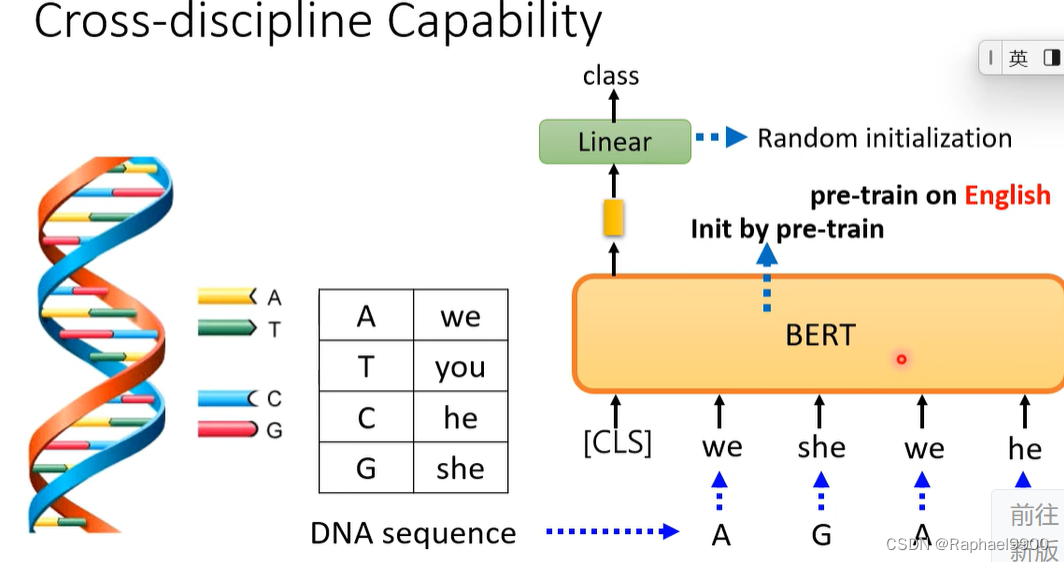
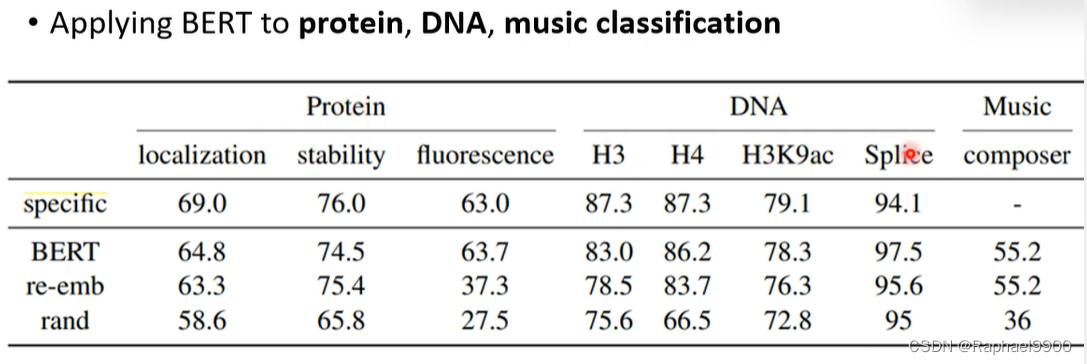
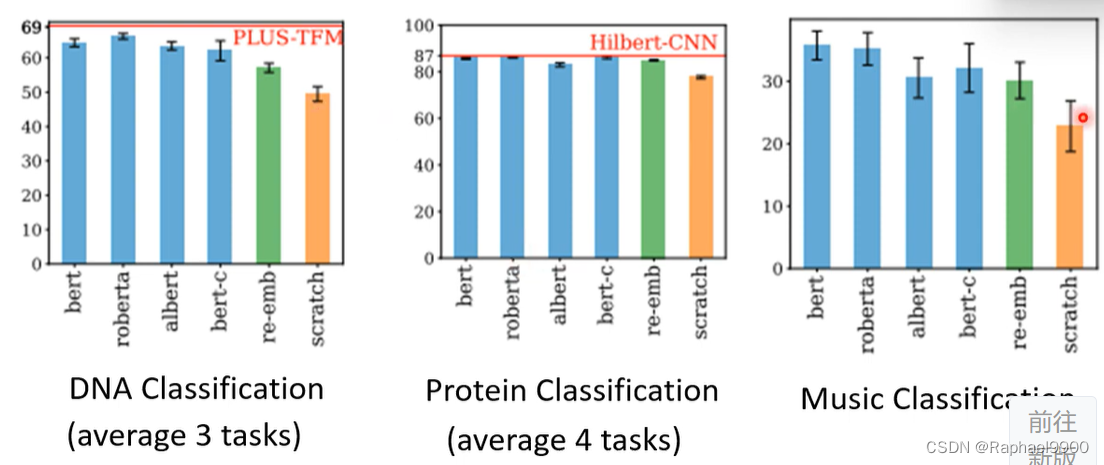
交叉学科能力
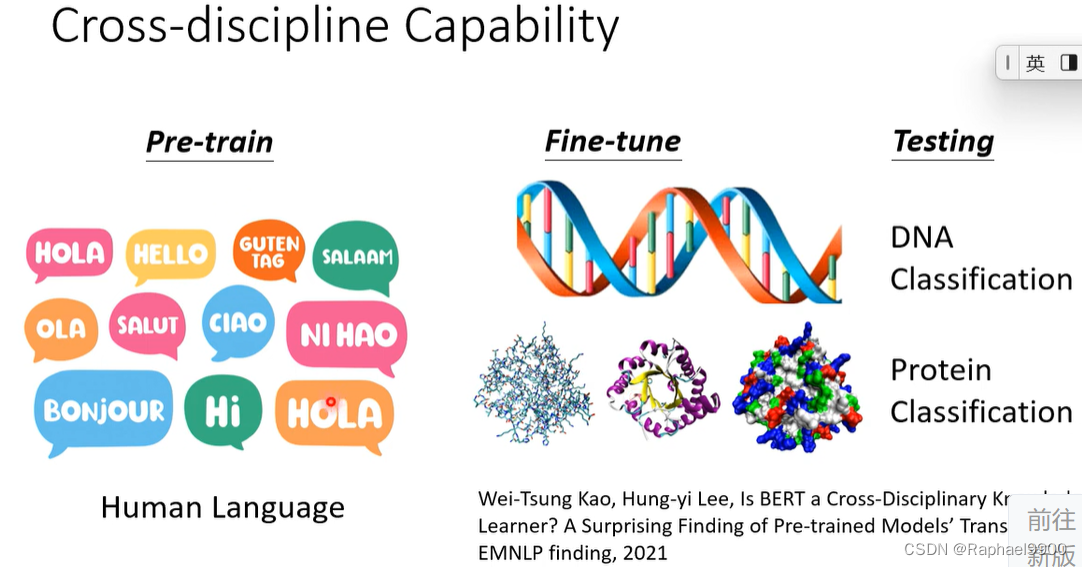
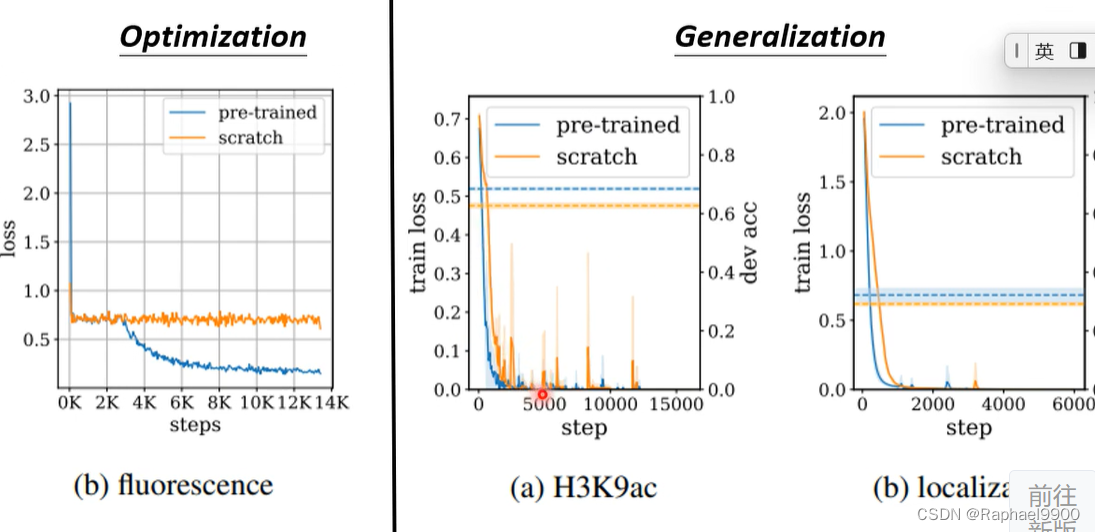
BERT在优化和generalization上都做的好

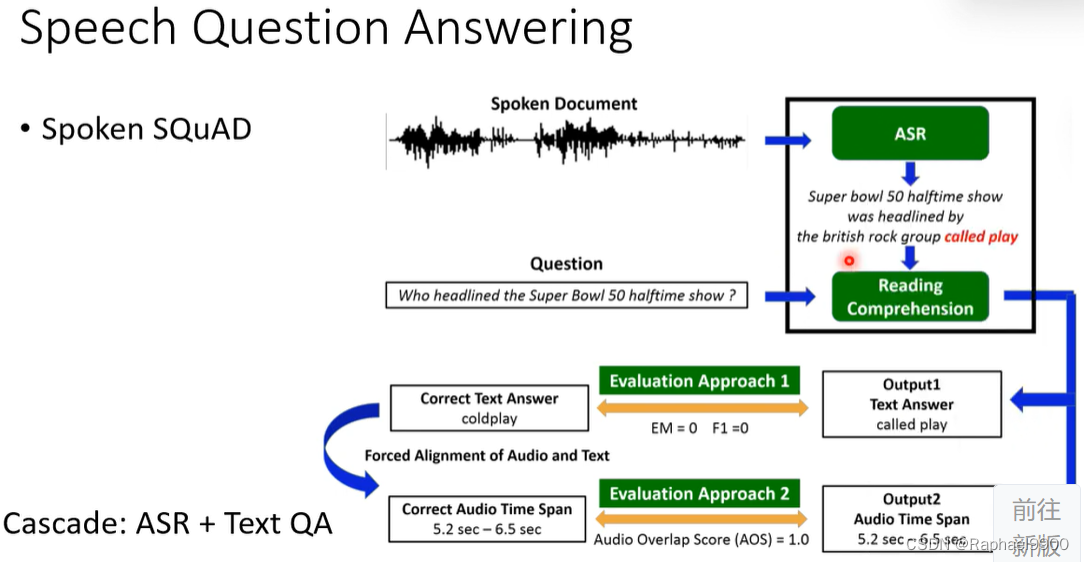
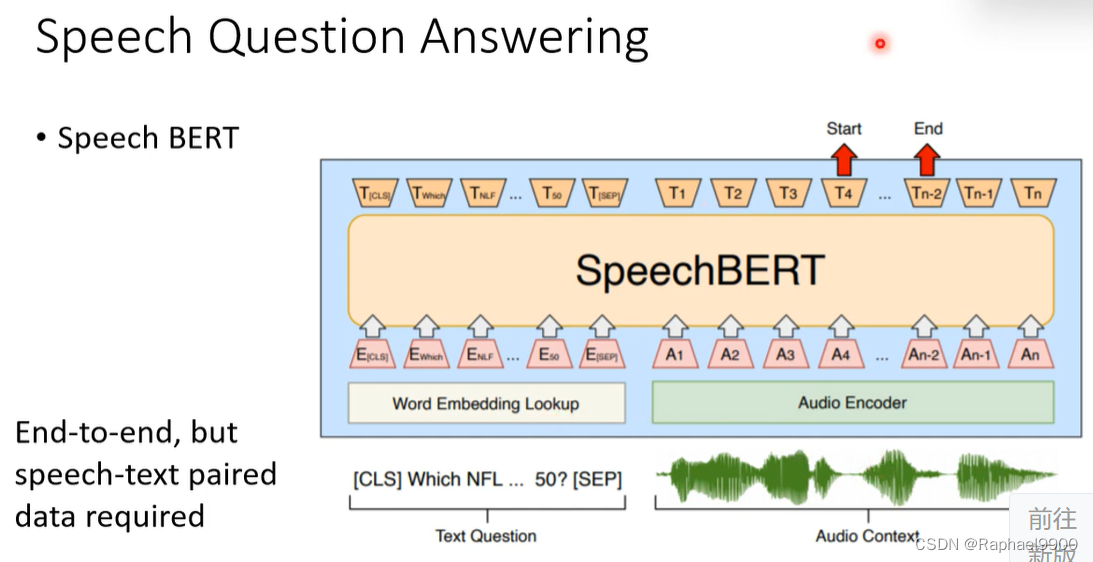
但是还是要有文字语音对应的资料
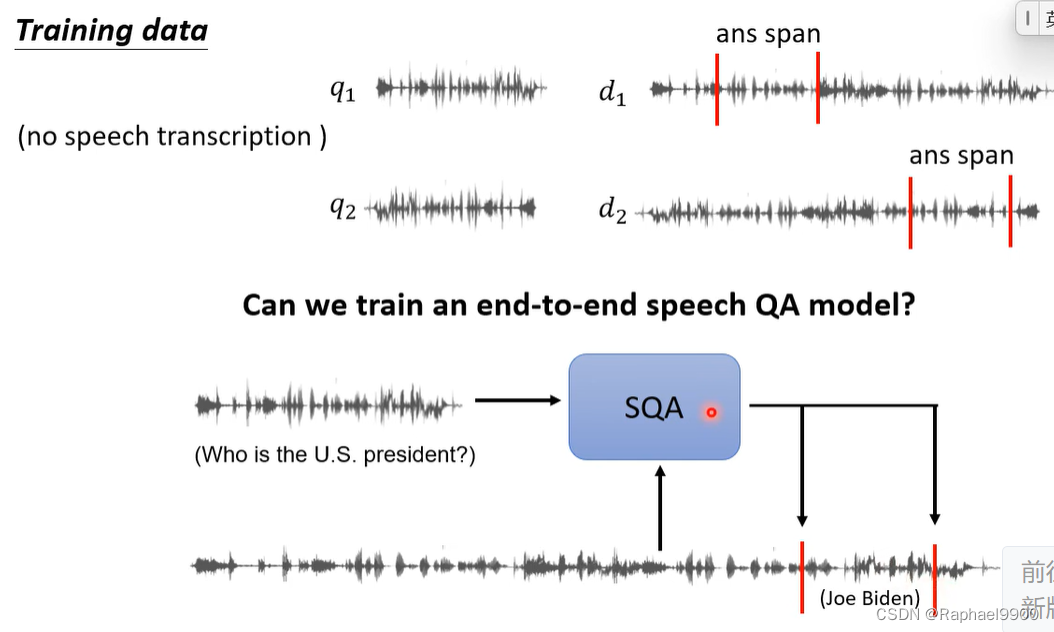
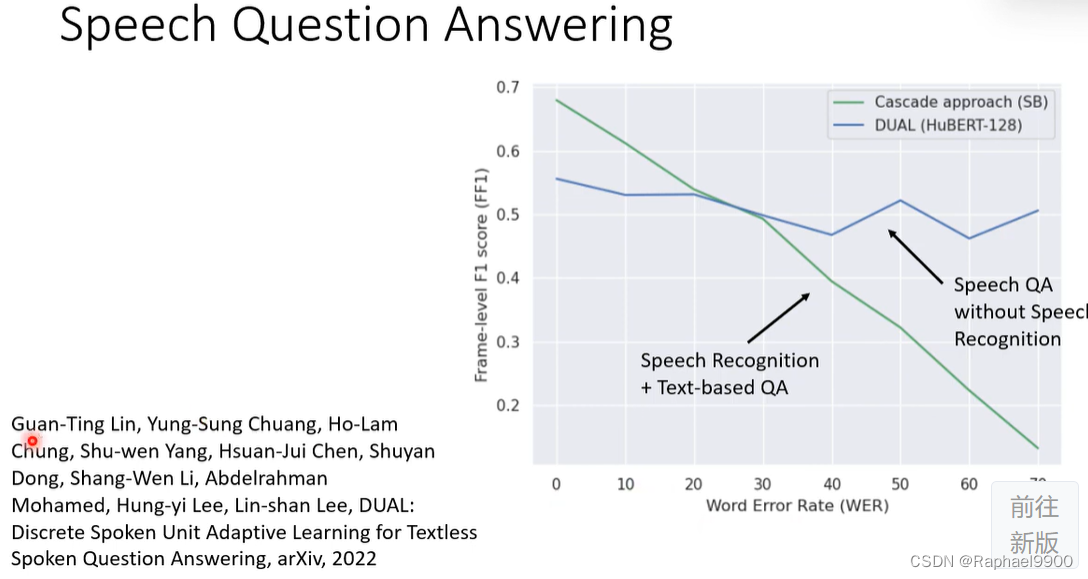
有没有可能只有语音资料呢?

训不了
把VQ进行离散化,加入自注意,不行:
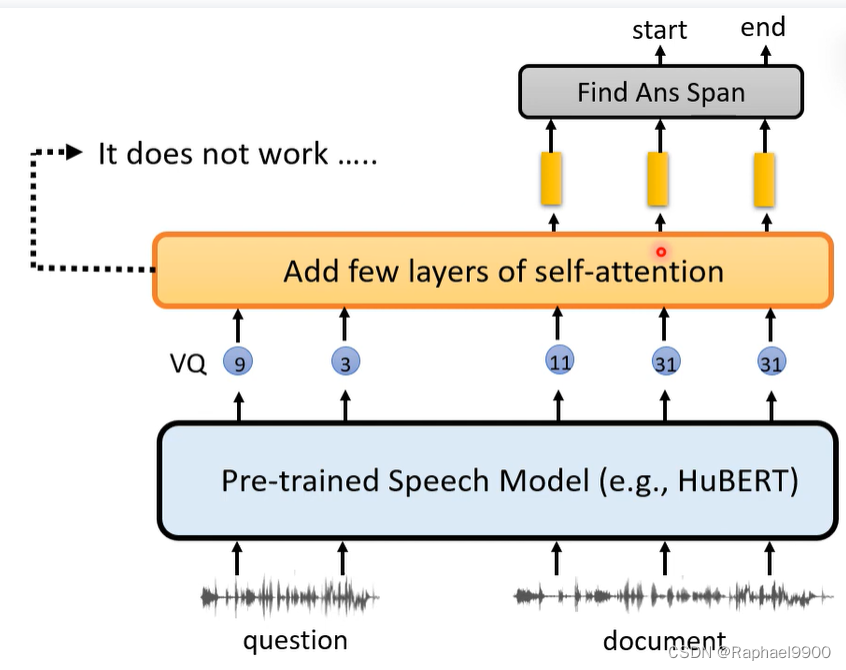
把这些符号换成文字,可以实现:

用人工数据进行预训练
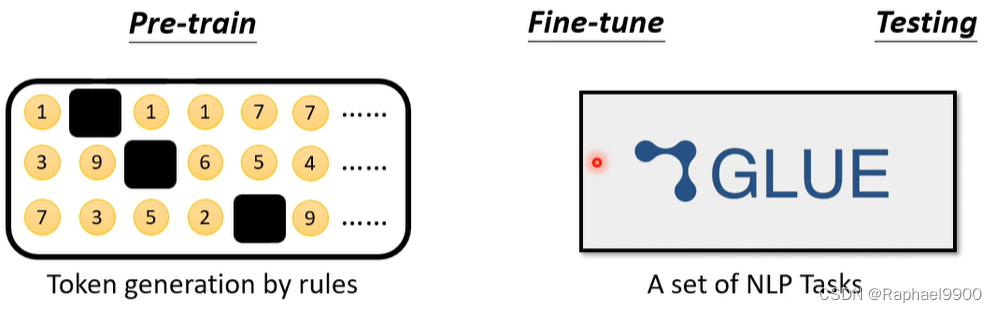
通过生成不同规则的人工数据,可以知道前期训练成功的关键因素是什么。

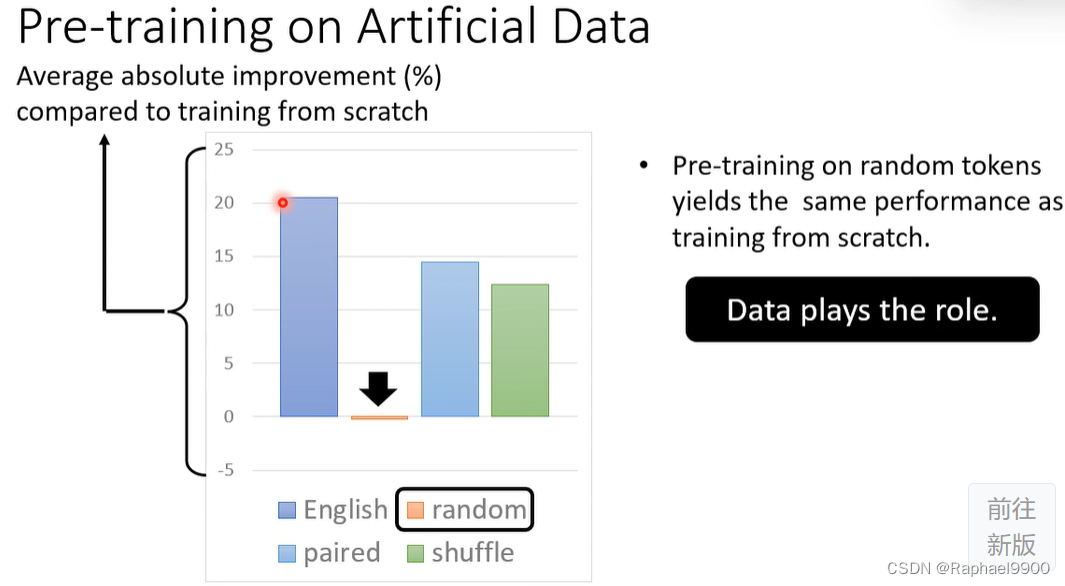
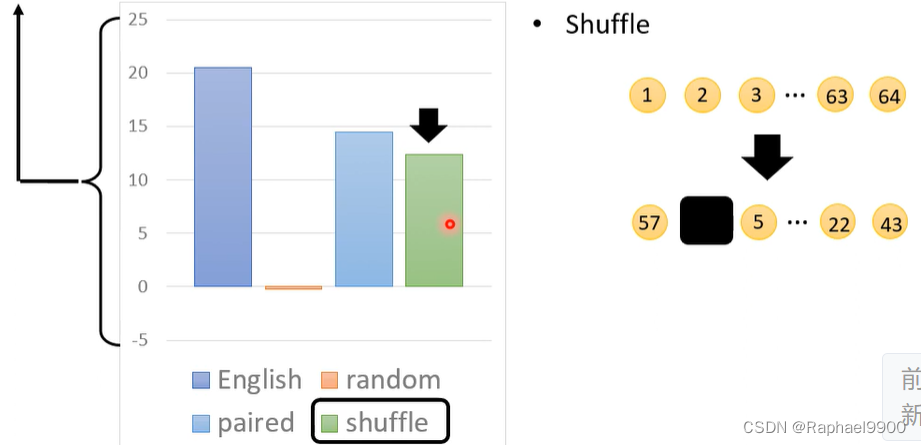
人工数据的预培训:与从头开始培训相比,平均绝对改进(%)
随机令牌上的预训练产生与从头开始训练相同的性能,没有用
成对资料有用:
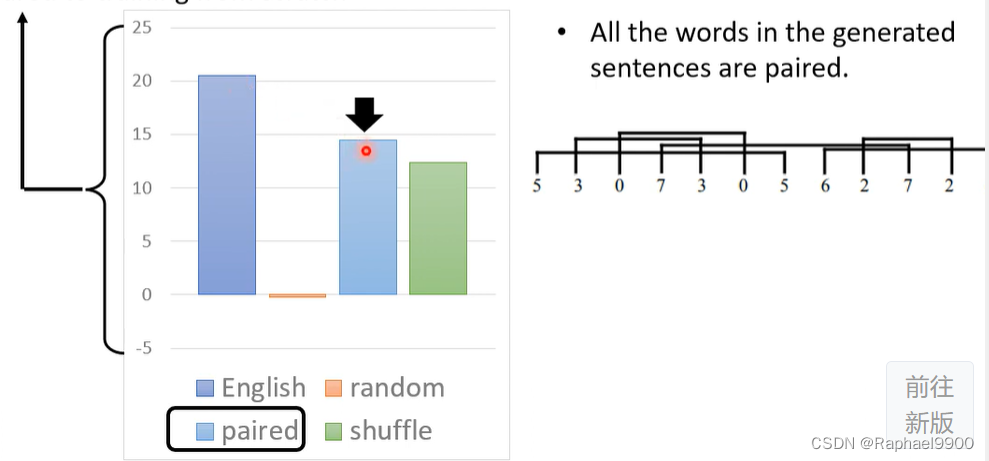
产生连续编号的序列,打乱之后掩码,做的也比较好。
到底什么能力对NLP任务是有用的呢?
与从头开始培训相比,平均绝对改进(%):

长序列对于任务是有用的。