🔥博客主页: 【小扳_-CSDN博客】
❤感谢大家点赞👍收藏⭐评论✍


文章目录
1.0 二叉树的说明
1.1 二叉树的实现
2.0 二叉树的优先遍历说明
3.0 用递归方式实现二叉树遍历
3.1 用递归方式实现遍历 - 前序遍历
3.2 用递归方式实现遍历 - 中序遍历
3.3 用递归方式实现遍历 - 后序遍历
4.0 用非递归方式实现二叉树遍历
4.1 用非递归方式实现遍历 - 前序遍历
4.2 用非递归方式实现遍历 - 中序遍历
4.3 用非递归方式实现遍历 - 后序遍历
5.0 深度遍历的完整代码
1.0 二叉树的说明
二叉树是一种树形数据结构,其中每个节点最多有两个子节点,分别称为左子节点和右子节点。二叉树可以为空,或者包含一个根节点和两个指向左子树和右子树的指针。
1.1 二叉树的实现
二叉树可以是空的,也可以是具有以下特点的非空树:
- 每个节点最多有两个子节点,分别称为左子节点和右子节点。
- 左子树和右子树都是二叉树。
代码实现如下:
public class MyBinaryTree { //指向左子树 private MyBinaryTree left; //当前节点的值 private int val; //指向右子树 private MyBinaryTree right; //构造方法一:带一个值的参数 public MyBinaryTree(int val) { this.val = val; } //构造方法二:带三个参数 public MyBinaryTree(MyBinaryTree left, int val, MyBinaryTree right) { this.left = left; this.val = val; this.right = right; } }实现两个构造方法是为了创建二叉树的时候会比较方便一些。
二叉树的创建如下:
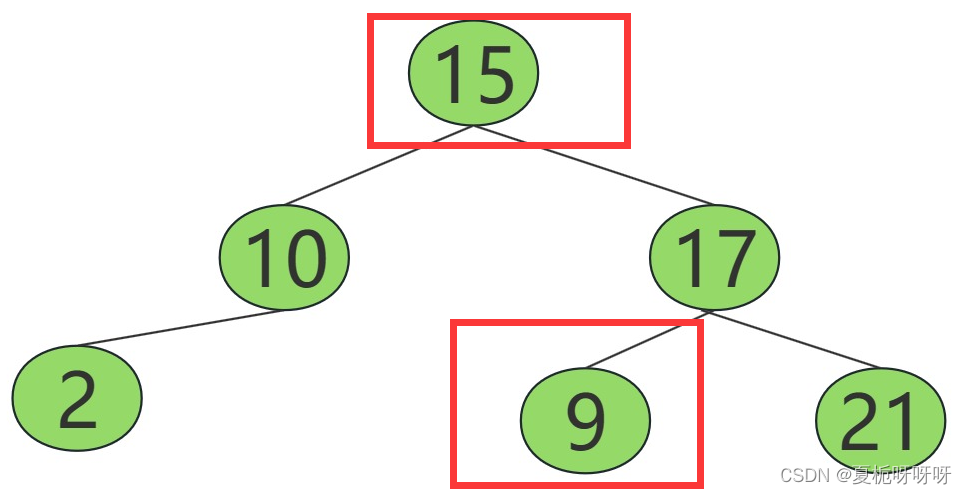
MyBinaryTree myBinaryTree = new MyBinaryTree(new MyBinaryTree(new MyBinaryTree(4),2,null), 1, new MyBinaryTree(new MyBinaryTree(5),3,new MyBinaryTree(6)));该二叉树的图片:

2.0 二叉树的优先遍历说明
二叉树的优先遍历是指按照一定顺序访问二叉树中的所有节点。常见的三种优先遍历方式包括:前序遍历、中序遍历和后序遍历。可以使用递归实现、非递归实现这三种遍历方式。
3.0 用递归方式实现二叉树遍历
递归实现前序遍历、中序遍历、后续遍历。用递归实现这三种遍历方式的区别就是对于数据什么时候处理,如打印。
- 前序遍历(Preorder Traversal):首先访问根节点,然后递归地遍历左子树,最后递归地遍历右子树。在前序遍历中,节点的访问顺序是“根-左-右”。
- 中序遍历(Inorder Traversal):首先递归地遍历左子树,然后访问根节点,最后递归地遍历右子树。在中序遍历中,节点的访问顺序是“左-根-右”。
- 后序遍历(Postorder Traversal):首先递归地遍历左子树,然后递归地遍历右子树,最后访问根节点。在后序遍历中,节点的访问顺序是“左-右-根”。
3.1 用递归方式实现遍历 - 前序遍历
具体思路为:在递出之前需要对当前节点的值访问,然后再接着向左子树递出,一直下去,每一次都需要先对当前节点的值访问,直到 node == null 时,左子树结束递出。当右子树此时也为 node == null 时,从叶子节点开始回归,回归到上一个节点的右子树。
代码实现如下:
假设该二叉树的图:
那么前序遍历打印的顺序为:124356
//使用递归实现前序遍历 public void preTraversalRecursion(MyBinaryTree node) { if (node == null) { return; } System.out.print(node.val + " "); preTraversalRecursion(node.left); preTraversalRecursion(node.right); }
3.2 用递归方式实现遍历 - 中序遍历
具体思路为:向左子树递出,一直下去,直到 node == null 时,左子树结束递出。再来对当前节点的值进行访问,接着继续向着右子树递出,当右子树此时也为 node == null 时,从叶子节点开始回归,回归到上一个节点的右子树前先对当前节点的值进行访问。
代码实现如下:
假设该二叉树的图:
中序遍历打印的顺序为:421563
//使用递归实现中序遍历 public void middleTraversalRecursion(MyBinaryTree node) { if (node == null) { return; } middleTraversalRecursion(node.left); System.out.print(node.val + " "); middleTraversalRecursion(node.right); }相对于前序遍历,中序遍历就是将对节点的值的访问进行换了一下位置。先进行左子树递归,再来访问值,最后再右子树递归。
3.3 用递归方式实现遍历 - 后序遍历
具体思路为:向左子树递出,一直下去,直到 node == null 时,左子树结束递出。再接着继续向着右子树递出,再来对当前节点的值进行访问,当右子树此时也为 node == null 时,从叶子节点开始回归,回归到对当前节点的值进行访问。
代码实现如下:
假设该二叉树的图:
后续遍历打印顺序为:425631
//使用递归实现后续遍历 public void postTraversalRecursion(MyBinaryTree node) { if (node == null) { return; } postTraversalRecursion(node.left); postTraversalRecursion(node.right); System.out.print(node.val + " "); }
4.0 用非递归方式实现二叉树遍历
非递归实现前序遍历、中序遍历、后续遍历。用非递归实现这三种遍历方式的区别是访问的顺序不同,而前中后序它们所走的路线是一致的。
假设该树的图片:
具体思路为:先定义一个当前节点 curr 一开始指向根节点,还需要有一个栈的数据结构来存储数据。从根节点开始往后先左子树一直遍历下去 curr = curr.left ,每次都需要存储当前节点到栈中,直到 curr == null 时,说明了左子树已经遍历完毕了。此时需要栈弹出节点,来寻找 “来时的路”,弹出来的节点就是离当前节点最近的节点,在原路返回的时候,还要判断当前节点是否还有右子树,将弹出栈的节点的右子树赋值给 curr = tp.right 。如果右子树不为 null ,就会继续对当前节点的左子树遍历,且把当前节点压入栈中,方便记住 “来时的路”,;如果右子树不为 null ,继续把栈中的节点弹出,直到栈中没有了节点且 curr == null 时,因此整个二叉树就遍历结束了。
4.1 用非递归方式实现遍历 - 前序遍历
对于前序遍历来说,就是在来到下一个节点之前对当前节点的值先访问了。
代码如下:
//非递归实现前序遍历 public void preTraversal(MyBinaryTree node) { MyBinaryTree curr = node; LinkedList<MyBinaryTree> stack = new LinkedList<>(); while (curr != null || !stack.isEmpty()) { if (curr != null) { System.out.print(curr.val + " "); stack.push(curr); curr = curr.left; }else { MyBinaryTree tp = stack.pop(); curr = tp.right; } } System.out.println(); }
4.2 用非递归方式实现遍历 - 中序遍历
对于中序遍历来说,在栈弹出节点后,对弹出的节点进行访问。
代码如下:
//非递归实现中序遍历 public void middleTraversal(MyBinaryTree node) { MyBinaryTree curr = node; LinkedList<MyBinaryTree> stack = new LinkedList<>(); while ( curr != null || !stack.isEmpty()) { if (curr != null) { stack.push(curr); curr = curr.left; }else { MyBinaryTree tp = stack.pop(); System.out.print(tp.val + " "); curr = tp.right; } } System.out.println(); }
4.3 用非递归方式实现遍历 - 后序遍历
相比前面两种前中后序遍历,后序遍历会多了一个判断,由于先访问完当前节点的左子树和右子树后,才能对当前节点的值进行访问,所以不能访问完左子树后,立马将当前节点弹出栈,还需要保留该节点,先对该节点的右节点进行访问完毕之后,再来访问该节点的值,最后就可以弹出栈了。需要先判断,当前节点的右子树为 null 时,可以弹出当前节点或者已经对当前节点的右节点访问完毕之后,也可以将当前节点弹出。
那么如何来判断是否访问完毕当前节点的右子树了?
可以用一个变量来标记,只需要判断最近弹出栈的节点是否为当前节点的右子树节点即可。
代码如下:
//非递归实现后序遍历 public void postTraversal(MyBinaryTree node) { MyBinaryTree crr = node; LinkedList<MyBinaryTree> stack = new LinkedList<>(); MyBinaryTree pop = null;//最后一次弹栈元素 while ( crr != null || !stack.isEmpty()) { if (crr != null) { stack.push(crr); crr = crr.left; }else { MyBinaryTree tp = stack.peek(); if ( tp.right == null || tp.right == pop ) { pop = stack.pop(); System.out.print(pop.val + " "); }else { crr = tp.right; } } } }
5.0 深度遍历的完整代码
import java.util.LinkedList; public class MyBinaryTree { //指向左子树 private MyBinaryTree left; //当前节点的值 private int val; //指向右子树 private MyBinaryTree right; //构造方法一:带一个值的参数 public MyBinaryTree(int val) { this.val = val; } //构造方法二:带三个参数 public MyBinaryTree(MyBinaryTree left, int val, MyBinaryTree right) { this.left = left; this.val = val; this.right = right; } //使用递归实现前序遍历 public void preTraversalRecursion(MyBinaryTree node) { if (node == null) { return; } System.out.print(node.val + " "); preTraversalRecursion(node.left); preTraversalRecursion(node.right); } //使用递归实现中序遍历 public void middleTraversalRecursion(MyBinaryTree node) { if (node == null) { return; } middleTraversalRecursion(node.left); System.out.print(node.val + " "); middleTraversalRecursion(node.right); } //使用递归实现后续遍历 public void postTraversalRecursion(MyBinaryTree node) { if (node == null) { return; } postTraversalRecursion(node.left); postTraversalRecursion(node.right); System.out.print(node.val + " "); } //非递归实现前序遍历 public void preTraversal(MyBinaryTree node) { MyBinaryTree curr = node; LinkedList<MyBinaryTree> stack = new LinkedList<>(); while (curr != null || !stack.isEmpty()) { if (curr != null) { System.out.print(curr.val + " "); stack.push(curr); curr = curr.left; }else { MyBinaryTree tp = stack.pop(); curr = tp.right; } } System.out.println(); } //非递归实现中序遍历 public void middleTraversal(MyBinaryTree node) { MyBinaryTree curr = node; LinkedList<MyBinaryTree> stack = new LinkedList<>(); while ( curr != null || !stack.isEmpty()) { if (curr != null) { stack.push(curr); curr = curr.left; }else { MyBinaryTree tp = stack.pop(); System.out.print(tp.val + " "); curr = tp.right; } } System.out.println(); } //非递归实现后序遍历 public void postTraversal(MyBinaryTree node) { MyBinaryTree crr = node; LinkedList<MyBinaryTree> stack = new LinkedList<>(); MyBinaryTree pop = null;//最后一次弹栈元素 while ( crr != null || !stack.isEmpty()) { if (crr != null) { stack.push(crr); crr = crr.left; }else { MyBinaryTree tp = stack.peek(); if ( tp.right == null || tp.right == pop ) { pop = stack.pop(); System.out.print(pop.val + " "); }else { crr = tp.right; } } } } }



![LeetCode [中等]全排列(回溯算法)](https://img-blog.csdnimg.cn/direct/851755e8324449e7825ef1d18c43c454.png)